MySQL调优笔记——慢SQL优化记录(1)
上周,项目出现线上问题,在这家公司做的是一个SAAS平台,总用户量大约10万人;
经过排查,发现是SQL问题,导致数据库响应慢,进而拖垮了整体服务;
通常,查询耗时较长的SQL涉及到的一些常见原因包括但不限于:数据量过大,查询未使用索引等
于是我们组开始全面摸牌对数据库查询性能影响较大的SQL,一些步骤记录如下:
1. 分析大数据库表
SELECT
TABLE_NAME '表名',
DATA_LENGTH '数据长度',
INDEX_LENGTH '索引长度',
(DATA_LENGTH + INDEX_LENGTH) AS '总长度',
TABLE_ROWS '行数',
CONCAT(ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024,
3),
'MB') AS '占用空间'
FROM
information_schema.TABLES
WHERE
TABLE_SCHEMA = '${你的数据库名称}'
ORDER BY (DATA_LENGTH + INDEX_LENGTH) DESC;使用以上SQL可以查询出数据库的数据表统计信息,这个数据不是最新的但是接近最新,可以做一个大致的数据量参考,执行结果大致如下:
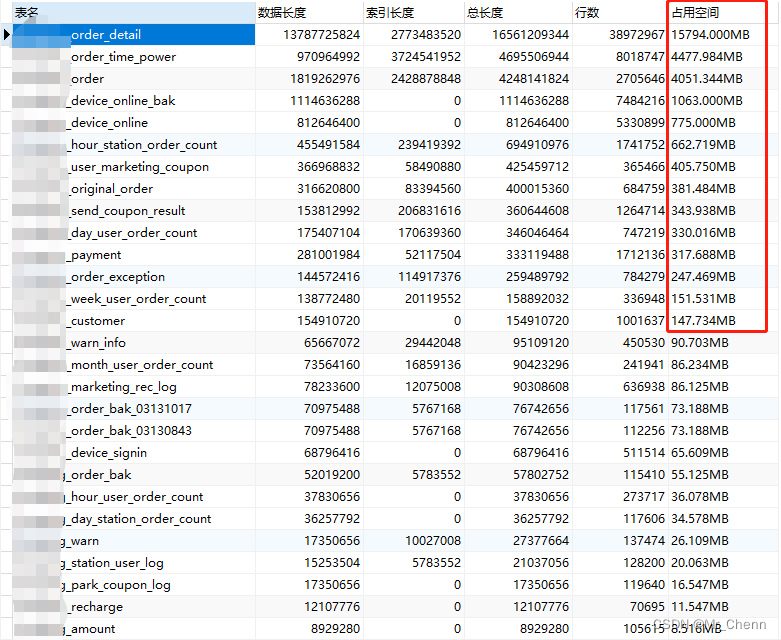
基本上看占用空间或者数据行数,总量排名靠前的表是重点关注对象。
2. 查看阿里云数据库运行监控
通过阿里云的云数据库监控工具导出了一份SQL的执行监控,用过阿里巴巴druid连接池的都知道,主要就是用来分析SQL的执行时长和执行频率的;

这是一份2分钟执行记录的数据库执行记录,重点关注执行次数、执行时长,针对性优化
3. SQL优化
通过阿里云的数据库运行监控导出的监控记录,一条条优化,这里列举一条
SELECT * FROM device_p350_real_time_data a WHERE record_time = (SELECT max(record_time) FROM device_p350_real_time_data WHERE project_id = '32641235' ) AND project_id = '32641235' ORDER BY record_time desc这条SQL在监控中显示,平均执行 2秒,执行次数146秒;
3.1 EXPLAIN分析一下执行计划

可以看到,这个子查询 ( select max(record_time) from xxx) 扫描了接近300万行数据,造成了巨大的性能消耗;
3.2 分析一下SQL对应的业务
我这里的SQL是要获取当前物联网数据表中最新的一批数据,于是使用了where record time = max(record_time) 这样的写法,虽然record_time增加了索引,但是聚合函数没有用到索引,因此造成了全表扫描,子查询严重拖累了速度;
于是将这里的子查询逻辑稍作修改,将 where record_time = (select max(record_time) from xxx) 变成 where record_time = (select record_time from xxx order by record_time desc limit 1)
这样之后,由于MySQL对索引字段是使用的B+排序树,所以子查询只扫描一行数据;
再次EXPLAIN:

执行耗时:0.371s
至此,一个最小单位的SQL优化已经结束,对1和2步骤扫描出来的 大表、执行耗时长的SQL重复进行类似3步骤的针对性调优,最终可以把整个系统的慢SQL都降下来,提高服务稳定性;
总结的话,就是尽量用到索引,编写查询语句的逻辑尽量使用更少的数据行扫描,不要对索引字段使用函数;