全方位揭秘!大数据从0到1的完美落地之运行流程和分片机制

一个完整的MapReduce程序在分布式运行时有三类实例进程:
- MRAppMaster: 负责整个程序的过程调度及状态协调
- MapTask: 负责Map阶段的整个数据处理流程
- ReduceTask: 负责Reduce阶段的整个数据处理流程
当一个作业提交后(mr程序启动),大概流程如下:
- 一个mr程序启动的时候,会先启动一个进程Application Master,它的主类是MRAppMaster
- ApplicationMaster启动之后会根据本次job的描述信息,计算出inputSplit的数据,也就是MapTask的数量
- ApplicationMaster然后向ResourceManager来申请对应数量的Container来执行MapTask进程。
- MapTask进程启动之后,根据对应的inputSplit来进行数据处理,处理流程如下
- 利用客户指定的inputformat来获取recordReader读取数据,形成kv键值对。
- 将kv传递给客户定义的Mapper类的map方法,做逻辑运算,并将map方法的输出kv收集到缓存。
- 将缓存中的kv数据按照k分区排序后不断的溢出到磁盘文件
- ApplicationMaster监控mapTask进程完成之后,会根据用户指定的参数来启动相应的reduceTask进程,并告知reduceTask需要处理的数据范围
- ReduceTask启动之后,根据ApplicationMaster告知的待处理的数据位置,从若干的已经存到磁盘的数据中拿到数据,并在本地进行一个归并排序,然后,再按照相同的key的kv为一组,调用客户自定义的reduce方法,并收集输出结果kv,然后按照用户指定的outputFormat将结果存储到外部设备。
MapReduce分片机制
分片的概念
MapReduce在进行作业提交时,会预先对将要分析的原始数据进行划分处理,形成一个个等长的逻辑数据对象,称之为输入分片(inputSplit),简称“分片”。MapReduce为每一个分片构建一个单独的MapTask,并由该任务来运行用户自定义的map方法,从而处理分片中的每一条记录。
分片是一个逻辑概念,分块是一个物理概念。
HDFS上数据是按照块为单位进行存储的,我们是能够实实在在的看到每一个数据块的。而分片则不然,是一个逻辑概念,用来描述一个MapTask处理的数据是属于哪个文件的,从什么字节位置开始处理,处理多少个字节的数据等等信息。
分片的大小选择
每一个MapTask处理一个分片的数据,因此分片的数量就决定了MapTask的数量。拥有多个分片,就意味着会有多个MapTask并发执行处理数据集。那么一个MapTask处理多大的数据呢?这也是由分片的大小来决定的。
如果分片设置的太小,那么管理分片的时间和构建MapTask的总时间将在整个作业的时间占比较大,影响程序的执行效率。例如: 一个分片设置为1KB的大小,计算分片、构建MapTask耗时10ms的时间,处理数据耗时10ms的时间,那这样的程序的效率是非常低下的。我们更加乐意让一个任务初始化的时间在整个任务中的时间占比尽可能低。
如果分片设置的太大,那么分片所描述的数据可能会在两个数据块中存储,那就有可能会造成网络IO的产生,需要将数据移动到一个节点上进行处理,效率更低。
因此,最佳分片大小应该和HDFS的块大小一致。
分片源码解读
FileSplit
public class FileSplit extends InputSplit implements Writable {
private Path file; // 描述文件的路径信息
private long start; // 描述这个分片需要处理的数据起点
private long length; // 描述这个分片需要处理的数据长度
private String[] hosts; // 描述这个分片对应的数据块在哪些节点
private SplitLocationInfo[] hostInfos;
public FileSplit() {
}
public FileSplit(Path file, long start, long length, String[] hosts) {
this.file = file;
this.start = start;
this.length = length;
this.hosts = hosts;
}
...
}
复制代码FileInputFormat
public abstract class FileInputFormat<K, V> extends InputFormat<K, V> {
// ...
// 定义了一个1.1倍的溢出值
private static final double SPLIT_SLOP = 1.1D;
// ...
// 创建一个分片对象,设置这个分片需要处理的数据位置、起点、长度、hosts等信息
protected FileSplit makeSplit(Path file, long start, long length, String[] hosts) {
return new FileSplit(file, start, length, hosts);
}
// ...
// 最重要的方法: 获取文件所有的分片信息
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = (new StopWatch()).start();
long minSize = Math.max(this.getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
List<InputSplit> splits = new ArrayList();
List<FileStatus> files = this.listStatus(job);
boolean ignoreDirs = !getInputDirRecursive(job) && job.getConfiguration().getBoolean("mapreduce.input.fileinputformat.input.dir.nonrecursive.ignore.subdirs", false);
Iterator var10 = files.iterator();
while(true) {
while(true) {
while(true) {
FileStatus file;
do {
if (!var10.hasNext()) {
job.getConfiguration().setLong("mapreduce.input.fileinputformat.numinputfiles", (long)files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size() + ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
file = (FileStatus)var10.next();
} while(ignoreDirs && file.isDirectory());
// 重要逻辑在这里!!!
// 获取到文件的路径描述信息
Path path = file.getPath();
// 获取到文件的大小
long length = file.getLen();
// 如果文件的大小不等于0
if (length != 0L) {
// 获取数据块的分布信息
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus)file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0L, length);
}
// 如果文件可以分片(有些文件是不可以分片的)
if (this.isSplitable(job, path)) {
// 获取一个Block的大小
long blockSize = file.getBlockSize();
// 计算分片的大小(块大小, 配置文件中设置的最小分片大小,最大分片大小的中间值)
long splitSize = this.computeSplitSize(blockSize, minSize, maxSize);
// 用来记录来剩多少字节的数据没有分片
long bytesRemaining;
int blkIndex;
// 循环分片开始了!
// 注意: 循环的条件,并不是剩余数量不足分片大小! 有一个1.1倍的溢出的值的!
for(bytesRemaining = length; (double)bytesRemaining / (double)splitSize > 1.1D; bytesRemaining -= splitSize) {
blkIndex = this.getBlockIndex(blkLocations, length - bytesRemaining);
// 创建一个分片!添加到分片集合中!
splits.add(this.makeSplit(path, length - bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts()));
}
// 循环走完后,创建一个分片来描述剩余的数据
if (bytesRemaining != 0L) {
blkIndex = this.getBlockIndex(blkLocations, length - bytesRemaining);
splits.add(this.makeSplit(path, length - bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts()));
}
} else {
if (LOG.isDebugEnabled() && length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization is possible: " + file.getPath());
}
splits.add(this.makeSplit(path, 0L, length, blkLocations[0].getHosts(), blkLocations[0].getCachedHosts()));
}
} else {
splits.add(this.makeSplit(path, 0L, length, new String[0]));
}
}
}
}
}
// 计算分片大小
protected long computeSplitSize(long blockSize, long minSize, long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
}
复制代码分片总结
-
分片大小参数
通过分析源码,在FileInputFormat中,计算分片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 分片主要由这几个值来运算决定
参数 默认值 属性 minSize 1 mapreduce.input.fileinputformat.split.minsize maxSize Long.MAX_VALUE mapreduce.input.fileinputformat.split.maxsize blockSize 128M dfs.blocksize 通过计算的逻辑分析可以得出,分片大小的计算,是取这三个值的中间值的,因此:
- 如果需要增大分片的大小: 调整minSize大于blockSize即可
- 如果需要减小分片的大小: 调整maxSize小于blockSize即可
-
分片创建过程总结
1. 获取文件大小及位置 2. 判断文件是否可以分片(压缩格式有的可以进行分片,有的不可以) 3. 获取分片的大小 4. 剩余文件的大小/分片大小>1.1时,循环执行封装分片信息的方法,具体如下: 封装一个分片信息(包含文件的路径,分片的起始偏移量,要处理的大小,分片包含的块的信息,分片中包含的块存在哪儿些机器上) 5. 剩余文件的大小/分片大小<=1.1且不等于0时,封装一个分片信息(包含文件的路径,分片的起始偏移量,要处理 的大小,分片包含的块的信息,分片中包含的块存在哪儿些机器上)复制代码注意事项: 1.1倍的冗余
一个260M的文件,分几块?分几片?
- 分块是物理概念: 128M + 128M + 4M,因此一共有3个分块。
- 分片是逻辑概念:
- 第一个分片: 260M/128M > 1.1,因此第一个分片大小128M,剩余132M数据未分片。
- 第二个分片: 132M/128M < 1.1,因此第二个分片大小132M
- 因此这个文件有2个分片。
-
多分片文件读取
数据文件被分了多个分片,那么我们不能保证分片是正好按照行分开的,极大的可能性是一行的数据被分到了两个分片中。因此,我们在进行多个分片的数据读取的时候:
- 第一个分片读到末尾再多读一行 - 既不是第一个分片也不是最后一个分片第一行数据舍弃,末尾多读一行 - 最后一个分片舍弃第一行,末尾多读一行复制代码
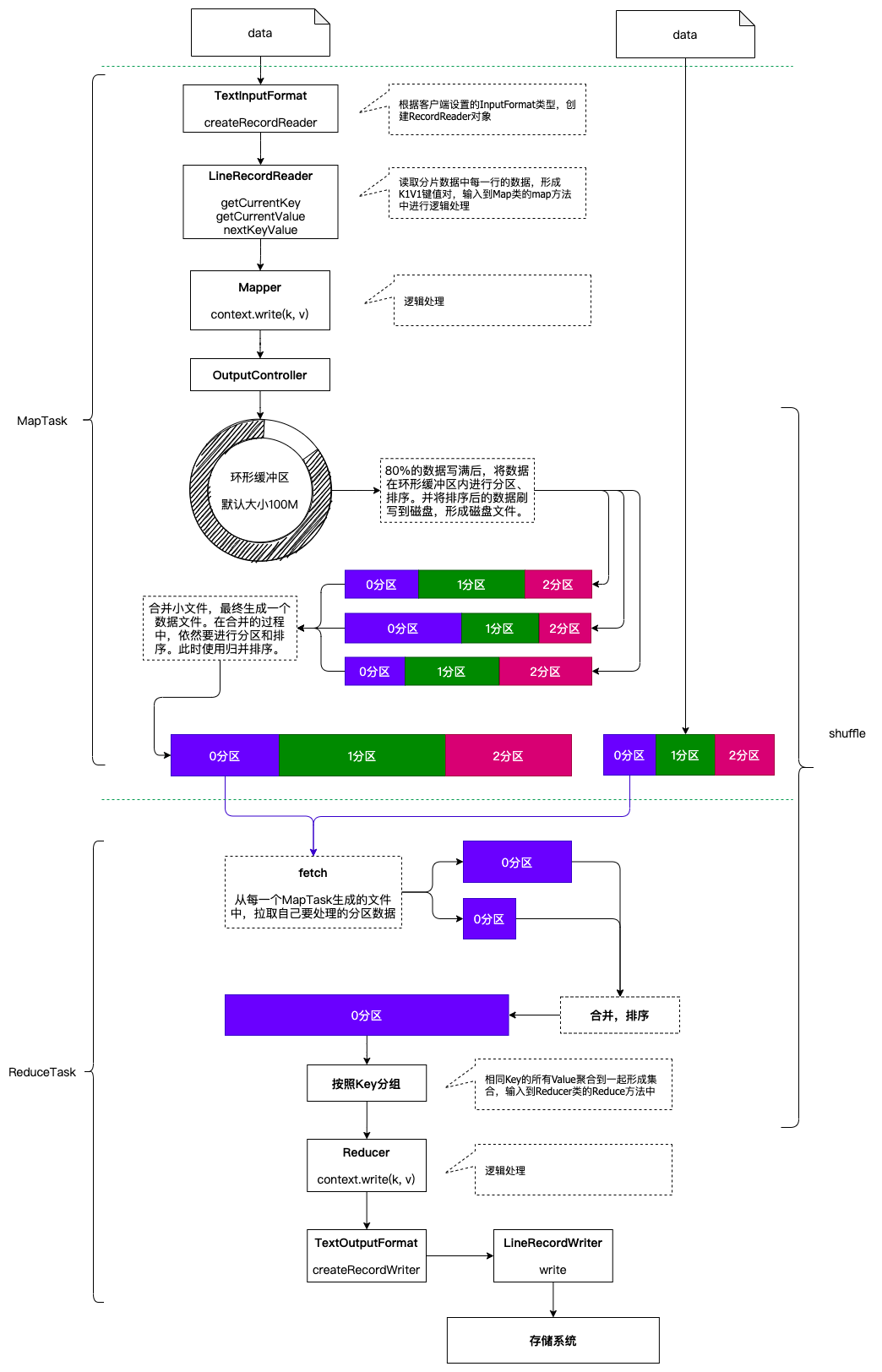
运行流程之MapTask
1. maptask调用FileInputFormat的getRecordReader读取分片数据
2. 每行数据读取一次,返回一个(K,V)对,K是offset,V是一行数据
3. 将k-v对交给MapTask处理
4. 每对k-v调用一次map(K,V,context)方法,然后context.write(k,v)
5. 写出的数据交给收集器OutputCollector.collector()处理
6. 将数据写入环形缓冲区,并记录写入的起始偏移量,终止偏移量,环形缓冲区默认大小100M
7. 默认写到80%的时候要溢写到磁盘,溢写磁盘的过程中数据继续写入剩余20%
8. 溢写磁盘之前要先进行分区然后分区内进行排序
9. 默认的分区规则是hashpatitioner,即key的hash%reduceNum
10. 默认的排序规则是key的字典顺序,使用的是快速排序
11. 溢写会形成多个文件,在maptask读取完一个分片数据后,先将环形缓冲区数据刷写到磁盘
12. 将数据多个溢写文件进行合并,分区内排序(外部排序 => 归并排序)
复制代码 MapTask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度.那么,MapTask并行实例是否越多越好呢?其并行度又是如何决定呢?
1. 如果硬件配置为2*12core + 64G,恰当的map并行度是大约每个节点20-100个map,最好每个map的执行时间至少一分钟。
2. 如果job的每个map或者 reduce task的运行时间都只有30-40秒钟,那么就减少该job的map或者reduce数,每一个task(map|reduce)的setup和加入到调度器中进行调度,这个中间的过程可能都要花费几秒钟,所以如果每个task都非常快就跑完了,就会在task的开始和结束的时候浪费太多的时间。
3. 配置task的JVM重用可以改善该问题:
(mapred.job.reuse.jvm.num.tasks,默认是1,表示一个JVM上最多可以顺序执行的task数目(属于同一个Job)是1。也就是说一个task启一个JVM)
4. 如果input的文件非常的大,比如1TB,可以考虑将hdfs上的每个block size设大,比如设成256MB或者512MB
复制代码运行流程之ReduceTask
1. 数据按照分区规则发送到reducetask
2. reducetask将来自多个maptask的数据进行合并,排序(外部排序===》归并排序)
3. 按照key相同分组()
4. 一组数据调用一次reduce(k,iterable<v>values,context)
5. 处理后的数据交由reducetask
6. reducetask调用FileOutputFormat组件
7. FileOutputFormat组件中的write方法将数据写出
复制代码Reduce Task的并行度同样影响整个job的执行并发度和执行效率,但与Map Task的并发数由切片数决定不同,Reduc Task数量的决定是可以直接手动设置:默认值是1,手动设置为4
设置方法:job.setNumReduceTasks(4);
复制代码如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: Reduce Task数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个Reduce Task。尽量不要运行太多的Reduce Task。对大多数job来说,最好reduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小。这个对于小集群而言,尤其重要。