【大厂AI课学习笔记】【1.5 AI技术领域】(8)文本分类
8,9,10,将分别讨论自然语言处理领域的3个重要场景。
自然语言处理,Natual Language Processing,NLP,包括自然语言识别和自然语言生成。
用途是从非结构化的文本数据中,发掘洞见,并访问这些信息,生成新的理解。
由于语言是人类思维的证明,因此自然语言处理是人工智能的最高境界,被誉为“人工智能皇冠上的明珠”。
文本分类,Text Categorization,将文本按照一定的分类体系或者标准自动的分类打标签。
应用场景主要有:
- 新闻分类
- 邮件自动回复
- 内容审核之广告过滤
- 内容审核之不当言论过滤
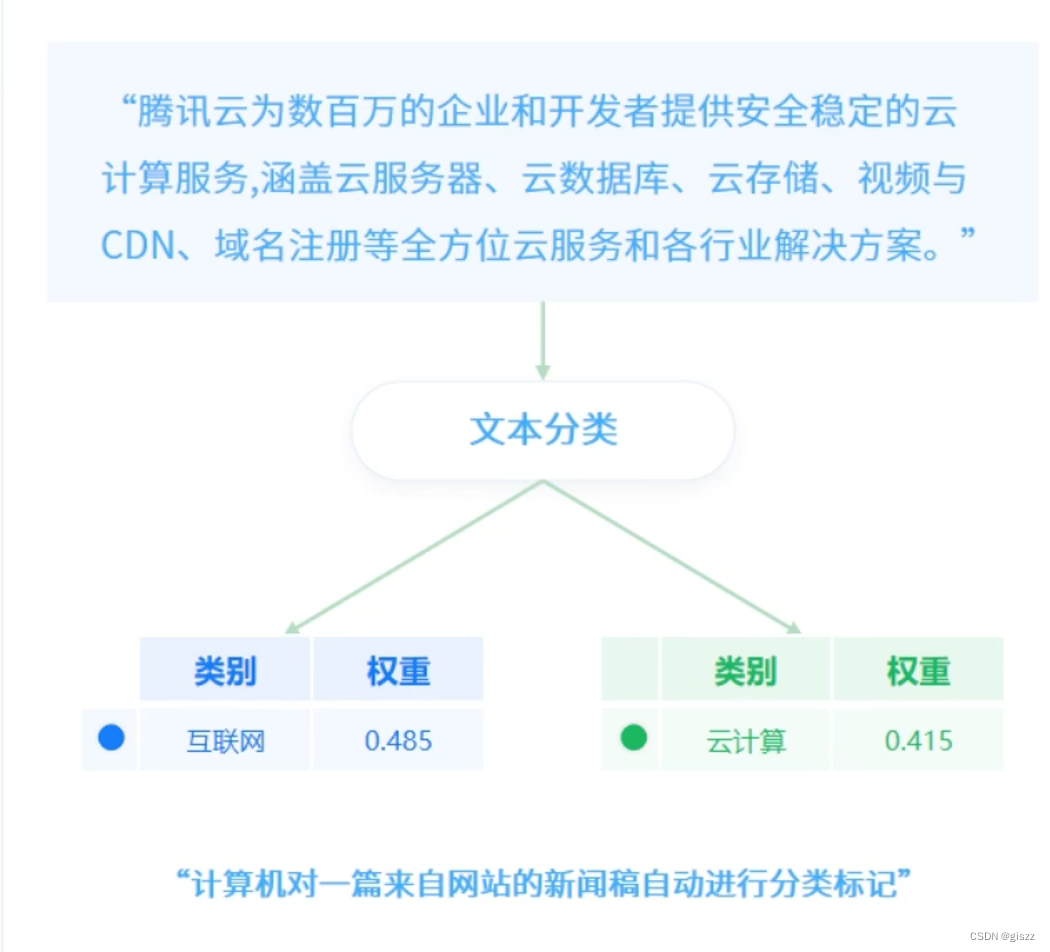
下面我们来了解更多关于文本分类的知识:
文本分类是自然语言处理(NLP)领域中的一个重要任务,它指的是将文本数据自动分配到预定义的类别中的过程。这些类别可以是新闻的主题、评论的情感倾向、邮件的垃圾/非垃圾标记等。文本分类的目的是为了组织和理解大量的文本数据,以便进行信息检索、情感分析、主题识别等后续任务。
关键技术
-
特征提取:将文本转换为计算机能够理解的数值形式。传统的特征提取方法包括词袋模型(Bag of Words)、TF-IDF等。近年来,基于深度学习的方法如词嵌入(Word Embeddings,如Word2Vec、GloVe)、上下文嵌入(Contextual Embeddings,如BERT、GPT等)成为主流。
-
文本表示:将提取的特征转换成适合机器学习模型的输入形式。这可以通过向量空间模型(VSM)、稀疏表示、密集表示(如神经网络中的嵌入层)等方式实现。
-
分类算法:应用机器学习或深度学习算法对文本进行分类。常见的机器学习算法包括朴素贝叶斯、逻辑回归、支持向量机(SVM)、决策树等。深度学习算法则包括卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)、Transformer等。
-
模型评估与优化:使用准确率、精确率、召回率、F1分数等指标对分类模型进行评估,并通过调整模型参数、采用更复杂的网络结构、引入正则化等技术进行优化。
-
预训练与迁移学习:在大规模语料库上预训练模型,然后将其迁移到特定任务的文本分类中,以提高性能并减少对数据量的依赖。
-
多模态融合:在文本分类中结合其他模态的信息,如图像、音频等,以提高分类的准确性。
应用场景
-
情感分析:分析评论、社交媒体帖子等的情感倾向(正面、负面、中性)。
-
垃圾邮件检测:自动识别和过滤垃圾邮件。
-
主题分类:对新闻文章、博客帖子等进行主题分类,如体育、政治、娱乐等。
-
语言翻译:在机器翻译中确定源文本所属的领域或主题,以便选择更合适的翻译模型。
-
问答系统:在问答系统中确定问题的类型,以便更准确地检索答案。
-
文本推荐:根据用户的历史阅读和偏好,推荐相关主题的文本内容。
-
社交媒体监控:监控社交媒体上的不当言论、恶意行为等。
主流的商业化产品
-
Google Cloud Natural Language API:提供情感分析、实体识别、语法分析等功能,支持多种语言。
-
Amazon Comprehend:亚马逊提供的NLP服务,包括文本分类、情感分析、主题建模等。
-
IBM Watson Natural Language Understanding:IBM的NLP产品,提供文本分类、情感分析、关键词提取等功能。
-
Microsoft Azure Cognitive Service for Language:微软提供的语言理解服务,包括文本分类、命名实体识别、语言翻译等。
-
Spacy:开源的NLP库,提供多种语言的文本处理功能,包括文本分类。
-
Hugging Face Transformers:开源的预训练模型库,包括BERT、GPT等,可用于文本分类任务。
文本分类的进一步分类
文本分类可以根据不同的标准进一步细分为多个子任务。以下是一些常见的分类及其定义、区别和关键技术实现路径:
情感分类
定义:情感分类旨在识别文本中所表达的情感倾向,如正面、负面或中性。它广泛应用于产品评论、社交媒体分析和市场调研等领域。
关键技术:情感词典、情感特征提取(如基于规则的方法、基于监督学习的方法)、深度学习模型(如CNN、RNN、LSTM等)、迁移学习。
实现路径:首先,收集并标注情感倾向的文本数据。然后,提取情感特征,可以使用基于规则的方法(如情感词典匹配)或监督学习方法(如SVM、朴素贝叶斯等)。最后,训练一个分类器来识别新文本的情感倾向。近年来,深度学习模型在情感分类任务上取得了显著成果,特别是基于Transformer的模型如BERT和GPT。
主题分类
定义:主题分类旨在将文本分配给预定义的主题类别,如新闻分类(体育、政治、娱乐等)或学术论文分类(计算机科学、物理学、生物学等)。
关键技术:主题模型(如潜在狄利克雷分布LDA)、关键词提取、文本聚类、深度学习分类模型。
实现路径:首先,确定主题类别的数量和范围。然后,使用主题模型或关键词提取方法来识别文本中的主题相关特征。接下来,可以选择使用传统的文本聚类方法(如K-means、层次聚类等)或深度学习分类模型(如CNN、RNN等)来训练分类器。在训练过程中,可以使用诸如TF-IDF等特征加权技术来提高性能。最后,评估模型的性能并进行优化。
多标签分类
定义:多标签分类是指一个文本实例可以同时属于多个类别。与单标签分类不同,多标签分类需要考虑类别之间的相关性和依赖性。
关键技术:标签相关性建模、多标签分类算法(如二元关联、分类器链等)、深度学习模型(如多标签CNN、RNN等)。
实现路径:首先,收集并标注具有多个类别的文本数据。然后,提取文本特征并使用多标签分类算法或深度学习模型来训练分类器。在训练过程中,需要特别注意标签之间的相关性建模,以避免标签之间的冗余和冲突。最后,评估模型的性能并进行优化,可以使用诸如汉明损失、微平均/宏平均F1分数等指标来衡量多标签分类的性能。