MiniCPM-V: A GPT-4V Level MLLM on Your Phone
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
研究背景和动机
现有的MLLM通常需要大量的参数和计算资源,限制了其在实际应用中的范围。大部分MLLM需要部署在高性能云服务器上,这种高成本和高能耗的特点,阻碍了其在移动设备、离线和隐私保护场景中的应用。
文章主要贡献:
提出了MiniCPM-V系列模型,能在移动端设备上部署的MLLM。
- 性能优越:在OpenCompass的11个热门基准测试上,表现优于GPT-4V-1106、Gemini Pro和Claude 3。
- 强大的OCR能力:支持1.8M像素高分辨率图像感知,可处理多种纵横比。
- 值得信赖的行为:具有较低的幻觉率(hallucination rate)。
- 多语言支持:支持超过30种语言。
- 高效的端侧部署:通过一系列端侧优化技术,实现了在移动设备上的高效部署。
Introduction
引入了Moore’s Law of MLLMs

模型架构

模型架构设计
- 视觉编码器(Visual Encoder):采用SigLIP SoViT-400m/14模型来处理图像输入。
- 压缩层(Compression Layer):使用感知器重采样结构(Perceiver Resampler)进行视觉特征的压缩,采用一层交叉注意力来实现。
- 大语言模型(LLM):压缩后的视觉特征和文本输入共同被送入LLM进行条件文本生成。MiniCPM-V 2.5版本使用了Llama3-Instruct 8B作为基础模型。
自适应视觉编码(Adaptive Visual Encoding)——参考LLaVA-UHD,为了有效的OCR同时高效
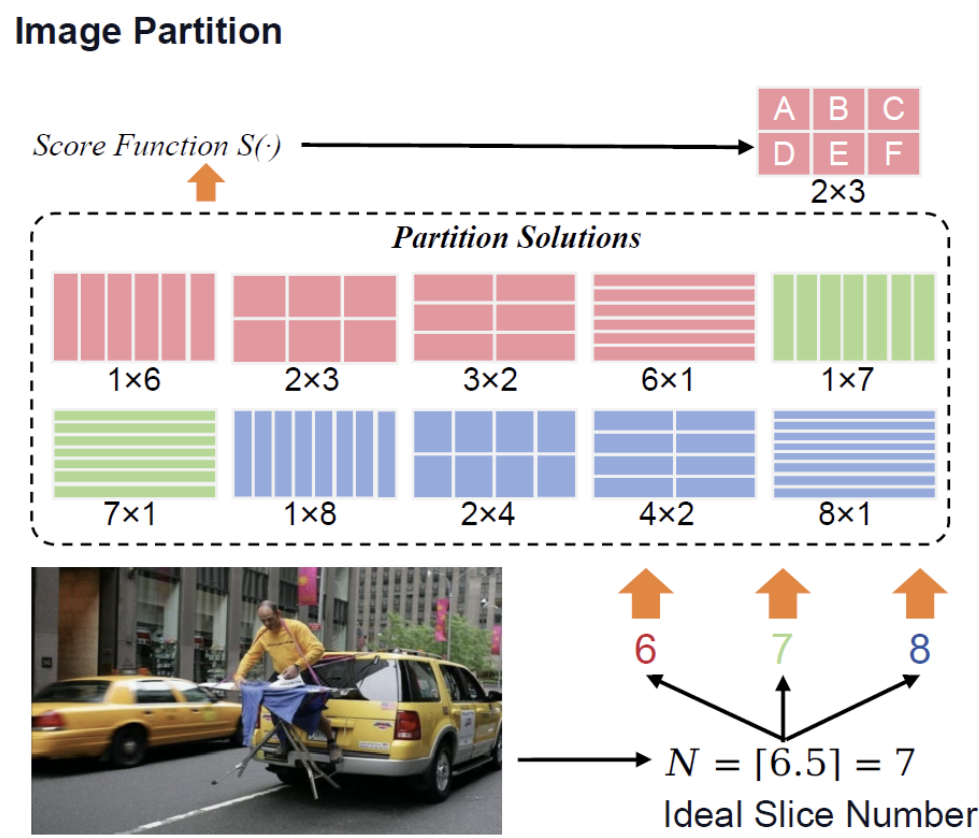
- 图像划分(Image Partition):为了适配不同纵横比的高分辨率图像,首先将图像划分成多个子块,每个子块与 ViT 的预训练设置相匹配。划分过程包括计算理想的子块数量,选择最佳的行数和列数组合以最大化评分函数值,确保划分后的子块与ViT的预训练设置一致。
切割数量: N = ⌊ W I × H I W v × H v ⌋ N = \left\lfloor \frac{W_I \times H_I}{W_v \times H_v} \right\rfloor N=⌊Wv×HvWI×HI⌋
m
×
n
=
N
m \times n = N
m×n=N
评估切割效果:
S
(
m
,
n
)
=
−
∣
log
W
I
/
m
H
I
/
n
−
log
W
v
H
v
∣
S(m, n) = - \left| \log \frac{W_I / m}{H_I / n} - \log \frac{W_v}{H_v} \right|
S(m,n)=−
logHI/nWI/m−logHvWv
选择:
m
∗
,
n
∗
=
arg
max
(
m
,
n
)
∈
C
‾
S
(
m
,
n
)
m^*, n^* = \arg \max_{(m, n) \in \overline{C}} S(m, n)
m∗,n∗=arg(m,n)∈CmaxS(m,n)
对应:
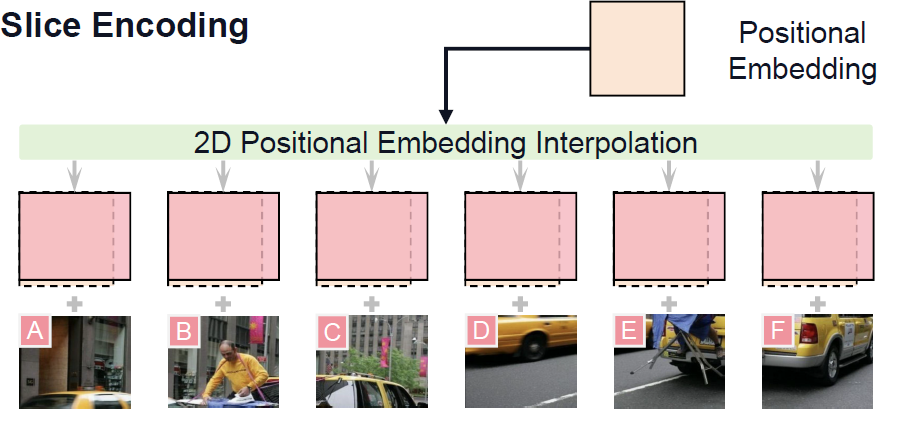
- 切片编码(Slice Encoding):每个子块在输入ViT之前需要调整大小,使其与ViT的预训练区域大小匹配。随后,对ViT的位置嵌入进行插值,以适应每个子块的纵横比。为了表示每个切片相对于整个图像的位置,还引入了一个Spatial Schema,即用两个特殊的标记包装每个切片的标记<slice>和<\slice>,然后使用一个“\n”将片从不同的行中分离出来。
- 令牌压缩(Token Compression):视觉编码之后,每个子块被编码为1024个令牌。为了管理高数量的令牌,作者使用了一个包含一层交叉注意力的压缩模块,将视觉令牌压缩为更少的查询数量(如,64或96个queries)。为提升效率efficiency。
Training
主要包括三个阶段:预训练阶段(Pre-training Phase)、监督微调阶段(Supervised Fine-tuning Phase, SFT)和基于AI反馈的强化学习阶段(RLAIF-V Phase)。
1. Pre-training——又分为三部分
预训练阶段的主要目标是将视觉模块(视觉编码器和压缩层)与大语言模型(LLM)的输入空间进行对齐,并学习基础的多模态知识。这个阶段分为三个子阶段:
阶段1:压缩层的预热训练
- 目标:主要训练视觉编码器和LLM之间的压缩层,使其能够有效地连接视觉输入和语言输出。
- 可训练模块:在这个阶段,压缩层被随机初始化并进行训练,而其他模块的参数保持冻结状态。视觉编码器的分辨率设置为224×224,这与其预训练时的设置相同。
- 数据:从图像描述数据(Image Captioning)集中随机选择200M数据用于训练。为了保证数据质量,对数据进行清洗,去除不相关或格式错误的图像-文本对。

阶段2:扩展视觉编码器的输入分辨率
- 目标:扩展预训练视觉编码器的输入分辨率,以适应更高分辨率的图像输入。
- 可训练模块:在此阶段,图像分辨率从224×224扩展到448×448,整个视觉编码器被训练,而其他模块的参数保持冻结。
- 数据:为了适应扩展后的分辨率,额外从图像描述数据集中选择200M数据。
阶段3:自适应视觉编码训练
- 目标:进一步训练视觉模块,使其能够处理任意纵横比的高分辨率输入,并提高其OCR能力。
- 可训练模块:在阶段3训练中,压缩层和视觉编码器都进行训练,以适应语言模型的嵌入空间。为了避免低质量预训练数据对语言模型的干扰,LLM保持冻结状态。
- 数据:除了之前使用的图像描述数据外,在高分辨率预训练阶段还引入了OCR数据,以增强视觉编码器的OCR能力。
训练过程遇到三个问题及解决方案:
- Caption Rewriting:低质量数据导致训练不稳定,因此引入辅助模型重写这些低质数据。(The rewriting model takes the raw caption as input and is asked to convert it into a question-answer pair. The answer from this process is adopted as the updated caption. In practice, we leverage GPT-4 [14] to annotate a small number of seed samples, which are then used to fine-tune an LLM for the rewriting task.
- Data Packing:different data sources usually have different lengths,可能造成out-of-memory (OOM) errors。解决:打包多个样本为一个固定长度序列,并截断最后一个样本。(Meanwhile,
we modify the position ids and attention masks to avoid interference between different samples. In our experiments, the data packing strategy can bring 2~3 times acceleration in the pre-training phase.) - Multilingual Generalization:解决多语言能力:Fortunately, recent findings from
VisCPM [41] have shown that the multimodal capabilities can be efficiently generalized across
languages via a strong multilingual LLM pivot. In practice, we only pre-train our model on English and Chinese multimodal data, and then perform a lightweight but high-quality multilingual supervised fine-tuning to align to the target languages.
2. 监督微调阶段(Supervised Fine-tuning Phase, SFT)
在预训练阶段学习了基础能力后,接下来进行监督微调,以进一步通过人类标注的数据集学习知识和交互能力。
-
可训练模块:与预训练阶段主要使用抓取自网络的数据不同,SFT阶段主要利用由人类标注的高质量数据集。因此,在SFT阶段,所有模型参数都被解锁,以更好地利用数据并学习丰富的知识。
-
数据:根据近期研究,训练后期更容易塑造模型能力和响应风格。所以SFT数据分为两部分:
- 第一部分(Part-1):专注于增强模型的基础识别能力,包含传统的QA/描述数据集,这些数据集的响应长度相对较短。
- 第二部分(Part-2):旨在增强模型在生成详细响应和遵循人类指令方面的能力,包含长响应和复杂交互的数据集。SFT过程中,这两部分数据串联后依次输入模型进行训练。
3. 基于AI反馈的强化学习阶段(RLAIF-V Phase)
多模态大语言模型(MLLMs)通常容易出现幻觉问题,即生成的响应与输入图像不符。为了解决这个问题,作者采用了最近提出的RLAIF-V方法,其关键在于通过开源模型获得高质量的反馈进行直接偏好优化(DPO)。
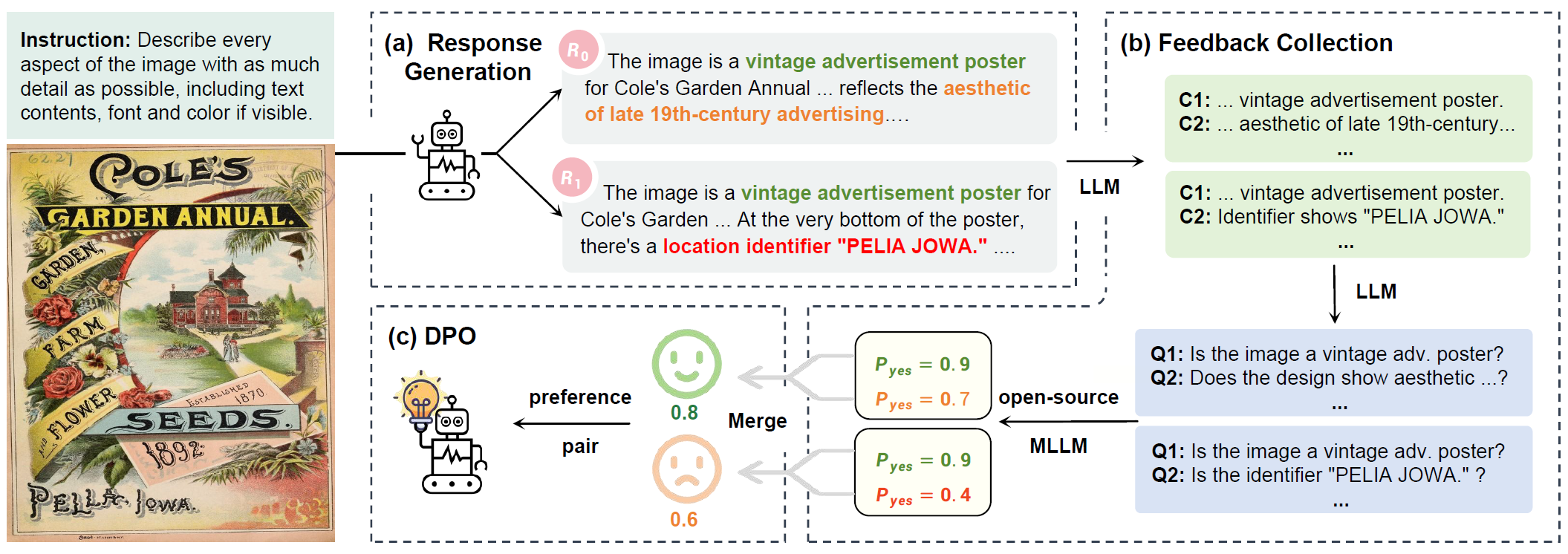
RLAIF-V方法流程:
-
响应生成(Response Generation):首先使用策略模型生成多个给定指令的响应。具体来说,给定一个等待对齐的模型,作者从模型中采样生成10个响应。这种生成方法有助于更专注于可信度,因为可以避免来自不同MLLM的文本风格差异,同时反馈学习更高效,因为偏好直接在策略模型的分布上收集。
-
反馈收集(Feedback Collection):由于开放源代码MLLM的能力通常较弱,直接收集高质量反馈是具有挑战性的。为解决这一问题,RLAIF-V采用了分而治之的策略对响应进行评分。每个响应被分解为原子陈述,然后将每个陈述转换为是/否问题,使用开放源代码的MLLM对其评分。最终的响应评分由无效原子陈述的数量决定。
-
直接偏好优化(Direct Preference Optimization, DPO):在收集到高质量的AI反馈后,进行偏好学习。DPO算法要求在偏好对上进行训练,其中一个样本优于另一个样本。最终构建了一个偏好数据集,用于偏好学习。
End-side Deployment
**End-side Deployment(端侧部署)**部分重点讨论了MiniCPM-V模型在移动设备等端侧设备上的高效部署方法和优化策略。
1. 挑战
- 内存限制
- CPU/GPU速度限制
2. 基础部署实践
为了降低模型在端侧设备上的内存消耗和计算成本,作者采用了以下基础优化方法:
- 量化(Quantization):采用4位量化策略(Q4_K_M模式)来压缩模型的参数,从而将内存需求从16-17GB减少到约5GB,使得模型更适合在移动设备上运行。
- 部署框架(Deployment Framework):作者使用
llama.cpp框架结合量化策略,在Xiaomi 14 Pro(Snapdragon 8 Gen 3)上进行部署,并测量了编码延迟和解码速度。虽然基础优化方法已经降低了一些计算开销,但效果仍有改进空间。
3. 高级部署优化
为进一步提高用户体验,作者采用了一系列高级优化技术:
- 内存使用优化(Memory Usage Optimization):通过顺序加载视觉编码器和大语言模型来减少内存占用,避免频繁的分页(paging),从而提高效率。
- 编译优化(Compilation Optimization):在目标设备上直接编译模型,以充分利用设备的指令集架构,提高编码延迟和解码吞吐量。
- 配置优化(Configuration Optimization):设计自动参数搜索算法,动态调整计算资源分配,提高推理速度。
- NPU加速(NPU Acceleration):利用智能手机上的NPU(神经处理单元)来加速视觉编码部分(如使用QNN框架),显著减少视觉编码时间。
4. 结果与讨论
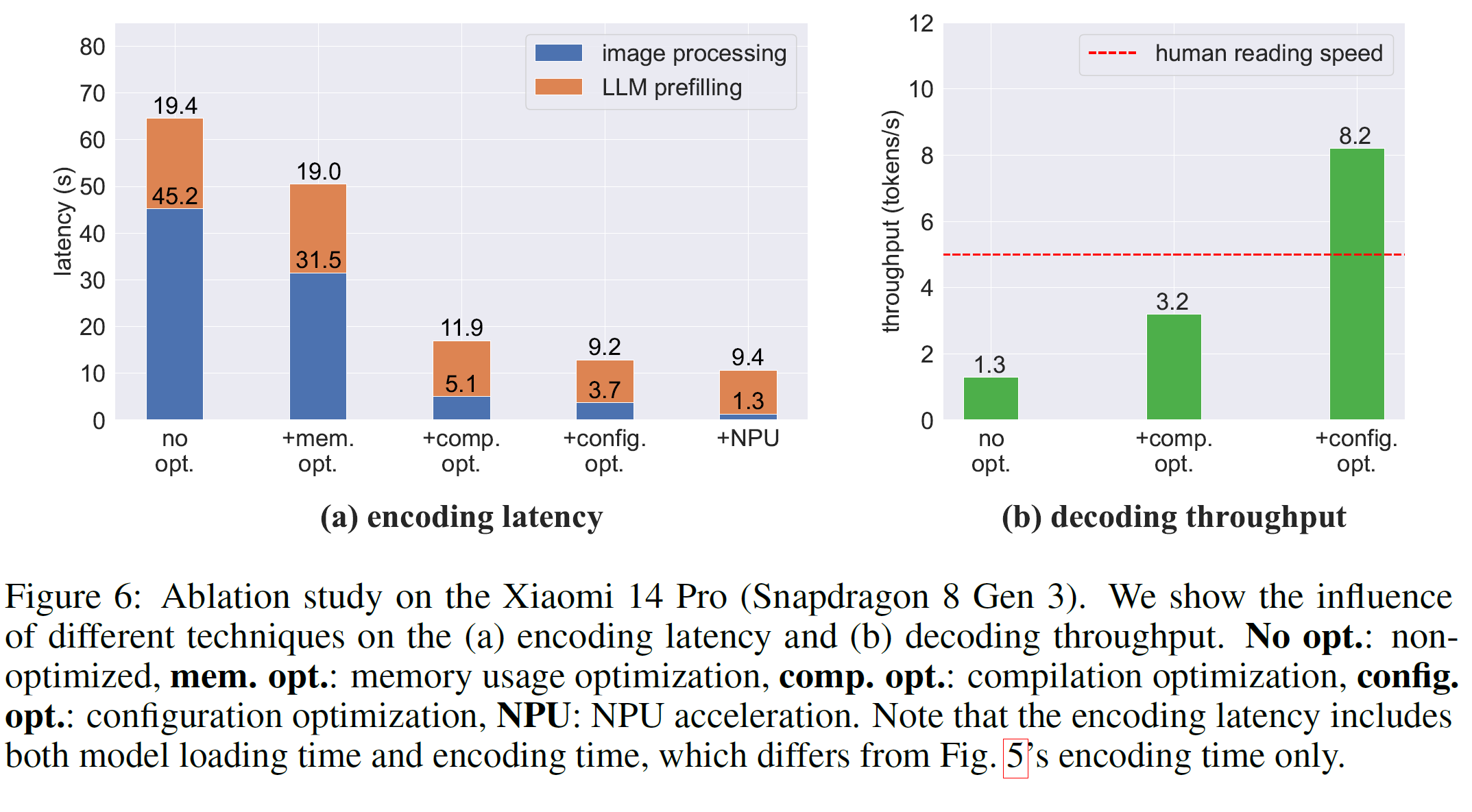
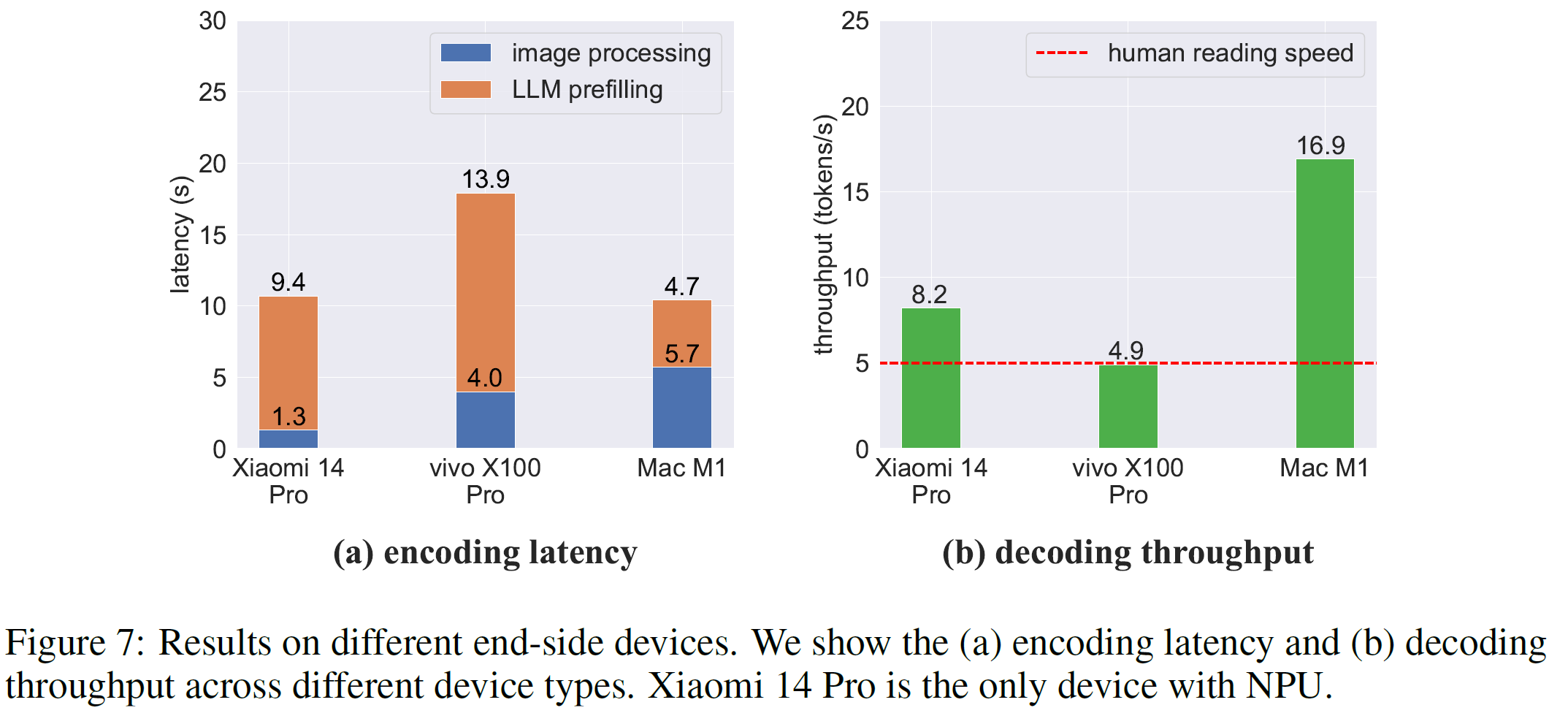
- 通过这些优化技术,MiniCPM-Llama3-V 2.5模型能够在多种端侧设备上实现高效运行,如Xiaomi 14 Pro(Snapdragon 8 Gen 3)、vivo X100 Pro(Mediatek Dimensity 9300)和MacBook Pro(M1),并表现出接近甚至超过人类阅读速度的解码吞吐量。
- 当前的计算瓶颈主要来自于LLM的预填充(prefilling)阶段。未来的研究方向包括开发更高效的视觉编码方法以及更好地利用GPU/NPU加速来进行LLM编码。
实验结果
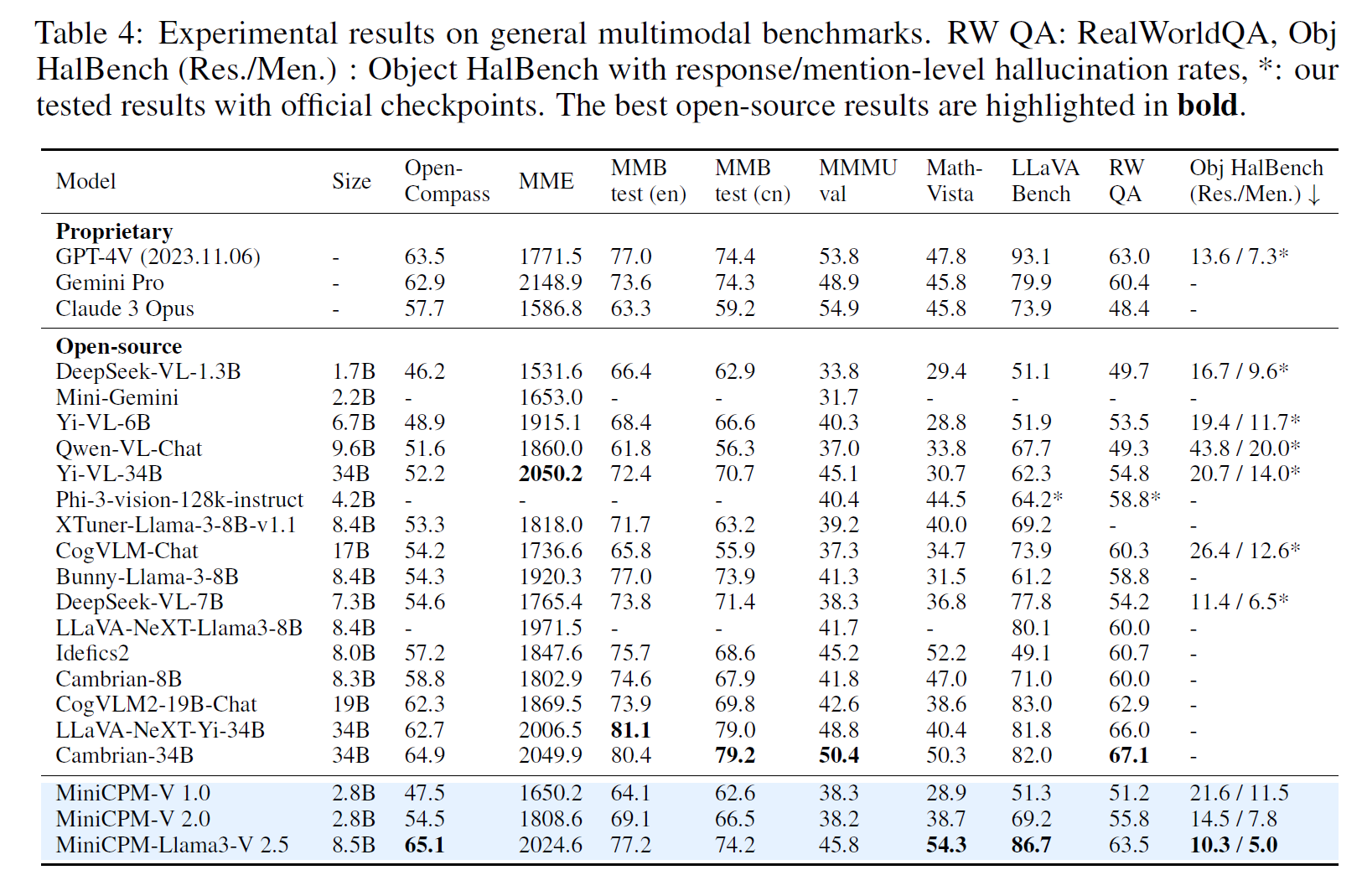
General Multimodal Benchmarks
OCR Benchmarks

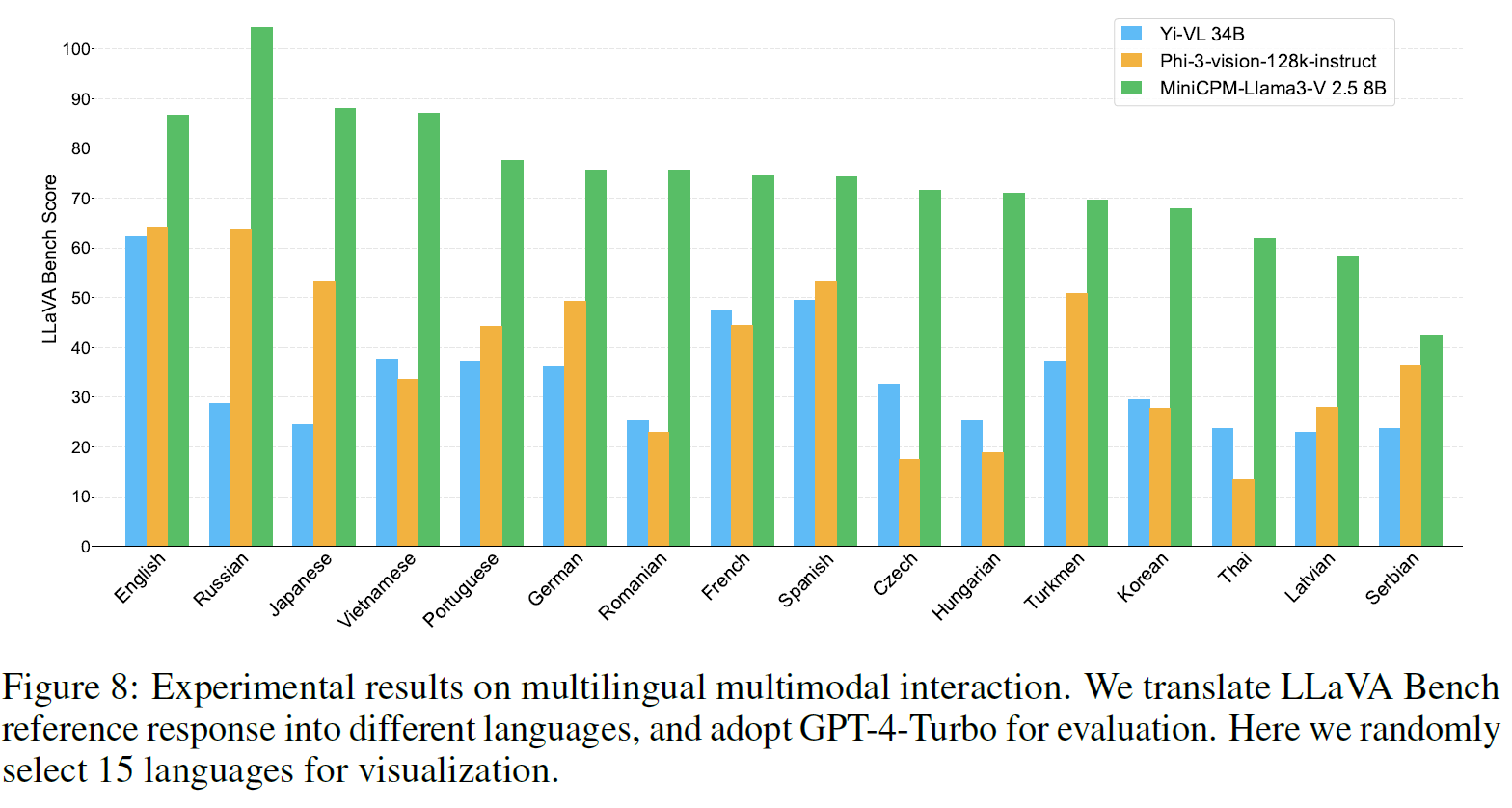
Multilingual Multimodal Capability
消融实验
Influence of RLAIF-V

Multilingual Generalization
