MySQL之数据类型
目录
一 数值类型
1 int类型,以tinyint为例
范围:
越界问题:
验证:
2 bit(位)
应用:
显示问题:
3 小数
1 float[(M,D)] [unsigned]
范围:
2 decimal
精度问题
二 文本、二进制类型
1 char(L)
对一个字符的理解:
对固定长度的理解:
对于空串:
示例
2 varchar
变长:
L:
三 时间日期
四 String
存储
示例
插入
查询
对enum:
对set查询

前置理解:
MySQL中有非常多的数据类型。之所以会有这么多的数据类型,是因为我们会根据实际的应用场景去选择合适的结构类型。
比如说对于性别的选择,只有男女这样的选项的话,就可以设置成bit(1)。
不同的数据类型会有不同的特性,对于空间或者效率上的利用各有特色。因此我们学习数据类型,结合实际的应用场景,选择最适合应用场景的数据类型进行数据的存储。
存储数据的时候,数据类型的精细化,可以帮助我们更合理地使用文件空间。
我们分别从整形,浮点型,文本二进制类型,时间类型,String类型进行理解。
一 数值类型
1 int类型,以tinyint为例
范围:
由于默认是有符号的,所以在没有指定无符号的情况下,范围是-128——127.
但是如果是有符号的话,默认范围就是0——255
越界问题:
(默认是有符号类型进行创建)我们先插入几条在数据范围内的数据,发现可以被成功插入;我们插入在数据范围之外的数据,发现就会告警,不允许进行插入。


其实这时候我们就可以发现,MySQL对于越界问题的一个处理方式是直接告警,不能进行插入。这和我们之前学习语言的时候不太相同,为什么会发生这样的情况呢?
这和数据的存储和数据库的要求有关:数据库要求数据的存储具有可信度的。而数据在底层是以二进制的方式进行存储,如果超出了对应的存储范围,仍然要进行存储的话,就会发生截断。如果截断的话,数据的可信度就不高了。因此对于越界行为的处理,MySQL是直接进行警告不允许插入的。直接就终止了对应的操作。
也就是说:在MySQL中,只有符合数据范围的数据才会进行插入,否则就不能。
其实这样设计可以倒逼程序员去遵循对应的数据的规则,谨慎选择对应的数据类型,这也是约束的一种体现。约束程序员规范存储数据。
好处:MySQL有了这样的约束之后,就保证了数据库内部存储的数据都是可以预期的。(我们可以根据数据类型推测出存储的数据的一些性质)
总而言之,除了对功能性的基本需求之外,MySQL还有对非功能性的规范。数据类型的本质就是一种约束,约束程序员去规范输入,保证数据库内部存储的数据都是可以预期的
验证:
用无符号类型的数据类型再来验证上述的结论

我们也能得到这样的结论。
其实我们声明unsigned的时候,除了对数据范围的一个声明,也声明了语义。比如人的年龄,身高,体重等不可能是负数,就可以用unsigned来存储。
我们存储的时候,使用tinyint存储不下的数据,tinyint unsigned可能也存储不下,这时候我们优先考虑的应该是是否能正确存放数据,对非功能性的要求就没有那么严格了,可以将tinyint提升为int或者bigint。
tinyint,int,bigint等都是类似的,只不过范围不同
2 bit(位)
声明bit的时候是这样声明的:
bit[(M)]
[]标识里面的内容可以省略,如果省略的话,默认就是1.里面的M标识位数,范围是从1——64
应用:
如果非常注重空间的话,就可以使用bit来存储。比如标识男女,是否是会员……
显示问题:
我们分别设定int和bit(8)的插入同一个数据,观察相应的产生的影响:存储的时候是可以存进去的,但是取的时候不太相同

我们分别对不同的类型插入相同的数字,会发现插入的时候是没有问题的,但是筛选的时候结果却不一致?
这和bit类型的数据存储有关:
相比于int,存的时候存的是int,取得是int。因此存取数据是一样的
但是bit的话,存的时候是按二进制存的,取得时候会以二进制的代码显示(ASCII码)。又因为数据库不让我进行截断,因此导致的一个影响是bit的有一些数据不可显。
但是对于这一部分不可显的数据仍然是存储在表中的,我们也可以通过条件筛选进行筛选出来

3 小数
1 float[(M,D)] [unsigned]
M标识显示的长度,D是小数点后的位数
实际存储位数和显示位数:我们之前格式化输出的时候指定位数,就是一个指定的显示长度。但是这个数据实际上存储的位数和显示的有区别的
范围:
如果我们是 float(4,2)的话,范围是-99.99——99.99 如果是float(4,1)的话,范围是-999.9——999.9以此类推
MySQL的小数是支持无符号的,这影响了数据范围,直接将负数的一部分舍去。


我们可以看到对于浮点数会进行四舍存储,也就是即使超出了最后一个精度范围的位置我们依然可以填入数据。但是最后的结果是一样的。
(虽然不是取整,但是对比零向取整的思想是差不多的)
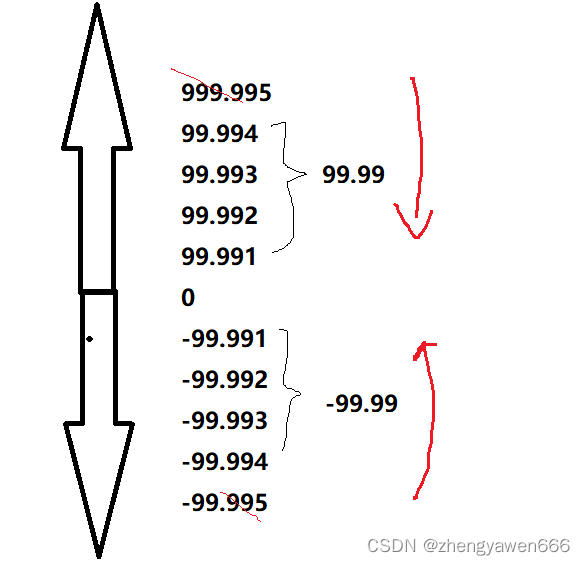
2 decimal
decimal使用的时候和float等是差不多的,只不过精度上更精确
decimal[(m,d)] [unsigned]
m指定长度,d表示小数点的位数
精度问题
为什么存储更精确?
浮点数的存储肯定会有精度损失的问题的。整数部分的规则/2取余数,小数点部分*2取整,小数点可能无法取整完毕。
float表示的精度大约是7位,
decimal m最大是65,d最大是30.如果被省略,m默认是10,d默认是0.
如果我们期望浮点数的精度更高,推荐使用decimal
二 文本、二进制类型
1 char(L)
是一个固定长度的字符串,L表示可以存储的长度,单位是字符,最大是255
对一个字符的理解:
在MySQL中,一个字符既可以代表一个英文字母,又可以代表一个汉字(这与语言中有所区别,语言中一个汉字可能是多个区别)
对固定长度的理解:
不管有没有用到对应的长度,该定长字符串都会用长度L的字符空间来存储
对于空串:
这里我们插入的时候可能会有空串,这是在筛选的时候不显示的。但是实际上又有数据
示例
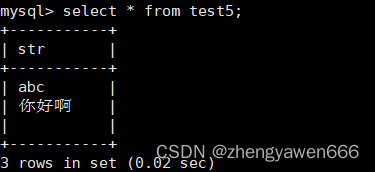
最后一行是空串
2 varchar
varchar(L)
和char的理解差不多,不过他是一个可变长度的字符串,L标识字符长度,最大可以是65535个字节。
变长:
<=的意思。如果超过规定的范围仍然是不允许插入的。变长的话最后存储的时候会根据实际存储的数据改变长度,起到节省空间的效果(同等的,会牺牲一部分的效率)
L:
他有两部分:1——3个字节用来记录数据大小,有效字节:65532。
因为要是变长的,肯定会有对应的部分记录数据的大小,会根据有效存储的数据的长度决定使用多少个字节数保存。
除去这一部分,剩下的都是我们可以用来保存数据的空间。需要注意的是,如果我们使用utf8编码的话,对于L最大只能写21844 。(utf编码一个字符3个字节),同理对于gbk,L最大是32766

对比char和varchar类型
定长可能会造成空间的浪费,但是效率比较高
变长节省了磁盘空间,但是相应的效率比较低
因此我们应该根据实际的需求进行选择
三 时间日期
常用的有以下三类
date 'yyyy-mm-dd' ,占用三字节
datetime 'yyyy-mm-dd HH:ii:ss' 占用8字节
timestamp:时间戳 格式和datetime完全一致,占用四字节

创建三列分别用来存储对应的类型,timestamp比较特殊,不为空并且默认值是当前的时间戳。我们利用这个类型的时候,会自动更新插入对应数据的时间。是由系统自动获取的
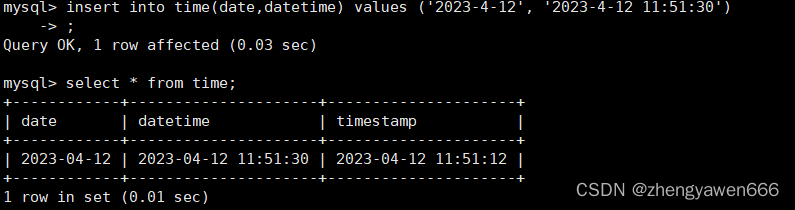
四 String
Stirng有enum和set两个类型,
enum:枚举,单选类型
set:集合,多选类型
存储
enum的存储:
该类型提供了若干选项的值,但是实际存储的时候只是存储了一个值,并且实际是按照数据进行存储的。对应正常的数组下标。
约束性更强,只能在枚举的选项中进行选择,如果超出对应的选项就会报错。
set的话,数据存储也是在底层存储的数字。但是存储的时候,实际上是利用了位图这样的结构进行存储的(在之前的Linux选项的章节中介绍过,这里不介绍)
示例
插入



0,1标识有无,具体的数据标识具体的值
查询
对enum:
既可以利用下标又可以利用对应的选项进行查找

对set查询
由于set的底层是位图,所以我们只用=查找的话,只能筛选出只有的,而非包含的。如果要筛选出包含的话,应该用对应的函数进行查找
find_in_set
mysql> select * from person where find_in_set('代码',hobby);
find_in_set的第一个参数是标识需要查找的对应的条件,第二个是在哪里查找。比如上述的语句就是在hobby里查找包含代码的数据