扩展 Calcite 中的 SQL 解析语法
Calcite中 JavaCC 的使用方法
Calcite 默认采用 JavaCC 来生成词法分析器和语法分析器。
1)使用 JavaCC 解析器
Calcite中,JavaCC 的依赖已经被封装到 calcite-core 模块当中,如果使用 Maven 作为依赖管理工具,只需要添加对应的calcite-core模块坐标即可。
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.26.0</version>
</dependency>
在代码中,可以直接使用 Calcite 的 SqlParser 接口调用对应的语法解析流程,对相关的 SQL 语句进行解析。
解析流程:
// SQL语句
String sql = "select * from t_user where id = 1";
// 解析配置
SqlParser.Config mysqlConfig = SqlParser.config().withLex(Lex.MYSQL);
// 创建解析器
SqlParser parser = SqlParser.create(sql, mysqlConfig);
// 解析SQL语句
SqlNode sqlNode = parser.parseQuery();
System.out.println(sqlNode.toString());
2)自定义语法
有时需要扩展一些新的语法操作,以数仓的操作——Load作为例子,介绍如何自定义语法。
Load操作时将数据从一种数据源导入另一种数据源中,Load操作采用的语法模板如下。
LOAD sourceType:obj TO targetType:obj
(fromCol toCol (,fromCol toCol)*)
[SEPARATOR '\t']
其中,sourceType 和 targetType 表示数据源类型,obj表示这些数据源的数据对象,(fromCol toCol)表示字段名映射,文件里面的第一行是表头,分隔符默认是制表符。
Load语句示例:
LOAD hdfs:'/data/user.txt' TO mysql:'db.t_user' (name name,age age) SEPARATOR ',';
在真正实现时,有两种选择。
一种是直接修改Calcite的源码,在其本身的模板文件(Parser.jj)内部添加对应的语法逻辑,然后重新编译。
但是这种方式的弊端非常明显,即对Calcite本身的源码侵入性太强。
另一种利用模板引擎来扩展语法文件,模板引擎可将扩展的语法提取到模板文件外面,以达到程序解耦的目的。
在实现层面,Calcite用到了FreeMarker,它是一个模板引擎,按照FreeMarker定义的模板语法,可以通过其提供的 Java API 设置值来替换模板中的占位符。
如下展示了 Calcite 通过模板引擎添加语法逻辑相关的文件结构,其源码将 Parser.jj 这个语法文件定义为模板,将 includes 目录下的.ftl文件作为扩展文件,最后统一通过config.fmpp来配置。
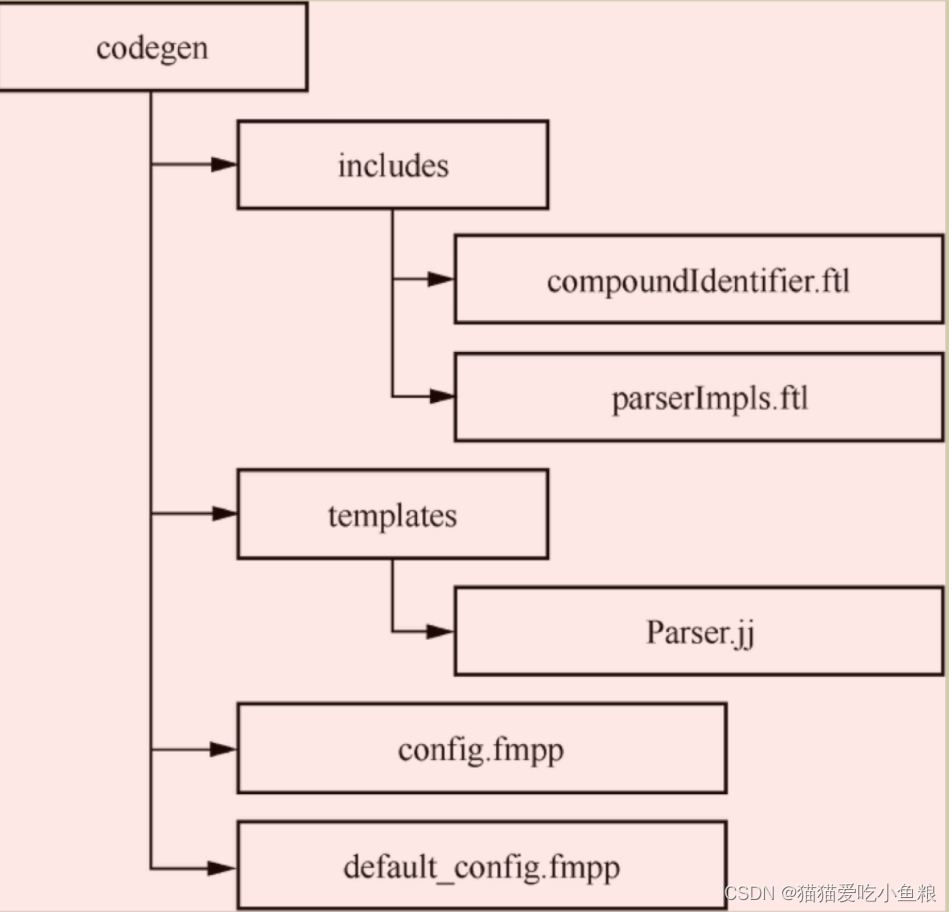
具体添加语法的操作可以分为3个步骤:
编写新的 JavaCC 语法文件;
修改config.fmpp文件,配置自定义语法;
编译模板文件和语法文件。
1.编写新的 JavaCC 语法文件
不需要修改Parser.jj文件,只需要修改includes目录下的.ftl文件,对于前文提出的Load操作,只需要在parserImpls.ftl文件里增加Load对应的语法。
在编写语法文件之前,先要从代码的角度,用面向对象的思想将最终结果定下来,也就是最后希望得到的一个SqlNode节点。
抽象Load语句内容并封装后,得到SqlLoad,继承SqlCall,表示一个操作,Load操作里的数据源和目标源是同样的结构,所以封装SqlLoadSource,而字段映射可以用一个列表来封装,SqlColMapping仅仅包含一堆列映射,SqlNodeList代表节点列表。
扩展SqlLoad的代码实现:
// 扩展SqlLoad的代码实现
public class SqlLoad extends SqlCall {
// 来源信息
private SqlLoadSource source;
// 终点信息
private SqlLoadSource target;
// 列映射关系
private SqlNodeList colMapping;
// 分隔符
private String separator;
// 构造方法
public SqlLoad(SqlParserPos pos) {
super(pos);
}
// 扩展的构造方法
public SqlLoad(SqlParserPos pos,
SqlLoadSource source,
SqlLoadSource target,
SqlNodeList colMapping,
String separator) {
super(pos);
this.source = source;
this.target = target;
this.colMapping = colMapping;
this.separator = separator;
}
}
由于Load操作涉及两个数据源,因此也需要对数据源进行定义。
Load语句中数据源的定义类:
/**
* 定义Load语句中的数据源信息
*/
@Data
@AllArgsConstructor
public class SqlLoadSource {
private SqlIdentifier type;
private String obj;
}
Load语句中出现的字段映射关系也需要定义。
对Load语句中的字段映射关系进行定义:
// 对Load语句中的字段映射关系进行定义
public class SqlColMapping extends SqlCall {
// 操作类型
protected static final SqlOperator OPERATOR =
new SqlSpecialOperator("SqlColMapping", SqlKind.OTHER);
private SqlIdentifier fromCol;
private SqlIdentifier toCol;
public SqlColMapping(SqlParserPos pos) {
super(pos);
}
// 构造方法
public SqlColMapping(SqlParserPos pos,
SqlIdentifier fromCol,
SqlIdentifier toCol) {
super(pos);
this.fromCol = fromCol;
this.toCol = toCol;
}
}
为了输出SQL语句,还需要重写unparse方法。
unparse方法定义:
/**
* 定义unparse方法
*/
@Override
public void unparse(SqlWriter writer, int leftPrec, int rightPrec) {
writer.keyword("LOAD");
source.getType().unparse(writer, leftPrec, rightPrec);
writer.keyword(":");
writer.print("'" + source.getObj() + "' ");
writer.keyword("TO");
target.getType().unparse(writer, leftPrec, rightPrec);
writer.keyword(":");
writer.print("'" + target.getObj() + "' ");
final SqlWriter.Frame frame = writer.startList("(", ")");
for (SqlNode n : colMapping.getList()) {
writer.newlineAndIndent();
writer.sep(",", false);
n.unparse(writer, leftPrec, rightPrec);
}
writer.endList(frame);
writer.keyword("SEPARATOR");
writer.print("'" + separator + "'");
}
当需要的 SqlNode 节点类定义好后,就可以开始编写语法文件了,Load语法没有多余分支结构,只有列映射用到了循环,可能有多个列。
parserImpls.ftl文件中添加语法逻辑的代码示例:
// 节点定义,返回我们定义的节点
SqlNode SqlLoad() :
{
SqlParserPos pos; // 解析定位
SqlIdentifier sourceType; // 源类型用一个标识符节点表示
String sourceObj; // 源路径表示为一个字符串,比如“/path/xxx”
SqlIdentifier targetType;
String targetObj;
SqlParserPos mapPos;
SqlNodeList colMapping;
SqlColMapping colMap;
String separator = "\t";
}
{
// LOAD语法没有多余分支结构,“一条线下去”,获取相应位置的内容并保存到变量中
<LOAD>
{
pos = getPos();
}
sourceType = CompoundIdentifier()
<COLON> // 冒号和圆括号在Calcite原生的解析文件里已经定义,我们也能使用
sourceObj = StringLiteralValue()
<TO>
targetType = CompoundIdentifier()
<COLON>
targetObj = StringLiteralValue()
{
mapPos = getPos();
}
<LPAREN>
{
colMapping = new SqlNodeList(mapPos);
colMapping.add(readOneColMapping());
}
(
<COMMA>
{
colMapping.add(readOneColMapping());
}
)*
<RPAREN>
[<SEPARATOR> separator=StringLiteralValue()]
// 最后构造SqlLoad对象并返回
{
return new SqlLoad(pos, new SqlLoadSource(sourceType, sourceObj),
new SqlLoadSource(targetType, targetObj), colMapping, separator);
}
}
// 提取出字符串节点的内容函数
JAVACODE String StringLiteralValue() {
SqlNode sqlNode = StringLiteral();
return ((NlsString) SqlLiteral.value(sqlNode)).getValue();
}
SqlNode readOneColMapping():
{
SqlIdentifier fromCol;
SqlIdentifier toCol;
SqlParserPos pos;
}
{
{ pos = getPos();}
fromCol = SimpleIdentifier()
toCol = SimpleIdentifier()
{
return new SqlColMapping(pos, fromCol, toCol);
}
}
2.修改config.fmpp文件,配置自定义语法
需要将 Calcite 源码中的 config.fmpp 文件复制到项目的 src/main/codegen 目录下,然后修改里面的内容,来声明扩展的部分。
config.fmpp文件的定义示例:
data: {
parser: {
# 生成的解析器包路径
package: "cn.com.ptpress.cdm.parser.extend",
# 解析器名称
class: "CdmSqlParserImpl",
# 引入的依赖类
imports: [
"cn.com.ptpress.cdm.parser.load.SqlLoad",
"cn.com.ptpress.cdm.parser.load.SqlLoadSource"
"cn.com.ptpress.cdm.parser.load.SqlColMapping"
]
# 新的关键字
keywords: [
"LOAD",
"SEPARATOR"
]
# 新增的语法解析方法
statementParserMethods: [
"SqlLoad()"
]
# 包含的扩展语法文件
implementationFiles: [
"parserImpls.ftl"
]
}
}
# 扩展文件的目录
freemarkerLinks: {
includes: includes/
}
3.编译模板文件和语法文件
在这个过程当中,需要将模板Parser.jj文件编译成真正的Parser.jj文件,然后根据Parser.jj文件生成语法解析代码。
利用Maven插件来完成这个任务,具体操作可以分为2个阶段:初始化和编译。
初始化阶段通过resources插件将codegen目录加入编译资源,然后通过dependency插件把calcite-core包里的Parser.jj文件提取到构建目录中。
编译所需插件的配置方式:
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<executions>
<execution>
<phase>initialize</phase>
<goals>
<goal>copy-resources</goal>
</goals>
</execution>
</executions>
<configuration>
<outputDirectory>${basedir}/target/codegen</outputDirectory>
<resources>
<resource>
<directory>src/main/codegen</directory>
<filtering>false</filtering>
</resource>
</resources>
</configuration>
</plugin>
<plugin>
<!--从calcite-core.jar提取解析器语法模板,并放入FreeMarker模板所在的目录-->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>2.8</version>
<executions>
<execution>
<id>unpack-parser-template</id>
<phase>initialize</phase>
<goals>
<goal>unpack</goal>
</goals>
<configuration>
<artifactItems>
<artifactItem>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.26.0</version>
<type>jar</type>
<overWrite>true</overWrite>
<outputDirectory>${project.build.directory}/</outputDirectory>
<includes>**/Parser.jj</includes>
</artifactItem>
</artifactItems>
</configuration>
</execution>
</executions>
</plugin>
这2个插件可以通过“mvn initialize”命令进行测试。
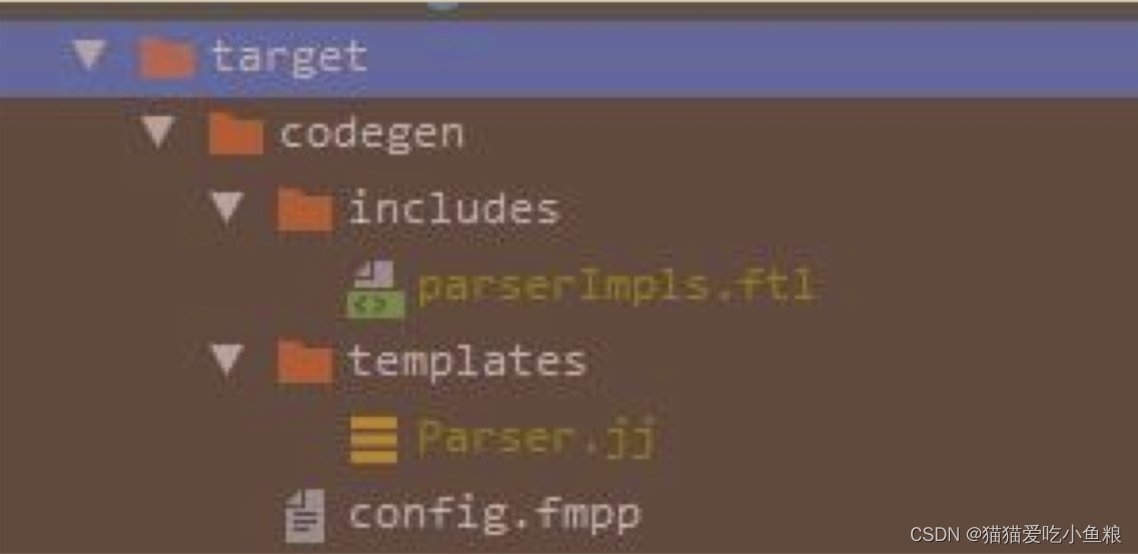
运行成功后可以看到target目录下有了codegen目录,并且多了本没有编写的Parser.jj文件。
然后就是编译阶段,利用FreeMarker模板提供的插件,根据config.fmpp编译Parser.jj模板,声明config.fmpp文件路径模板和输出目录,在Maven的generate-resources阶段运行该插件。
FreeMarker在pom.xml文件中的配置方式:
<plugin>
<configuration>
<cfgFile>${project.build.directory}/codegen/config.fmpp</cfgFile>
<outputDirectory>target/generated-sources</outputDirectory>
<templateDirectory>
${project.build.directory}/codegen/templates
</templateDirectory>
</configuration>
<groupId>com.googlecode.fmpp-maven-plugin</groupId>
<artifactId>fmpp-maven-plugin</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.28</version>
</dependency>
</dependencies>
<executions>
<execution>
<id>generate-fmpp-sources</id>
<phase>generate-sources</phase>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
</plugin>
运行“mvn generate-resources”命令就可以生成真正的Parser.jj文件。
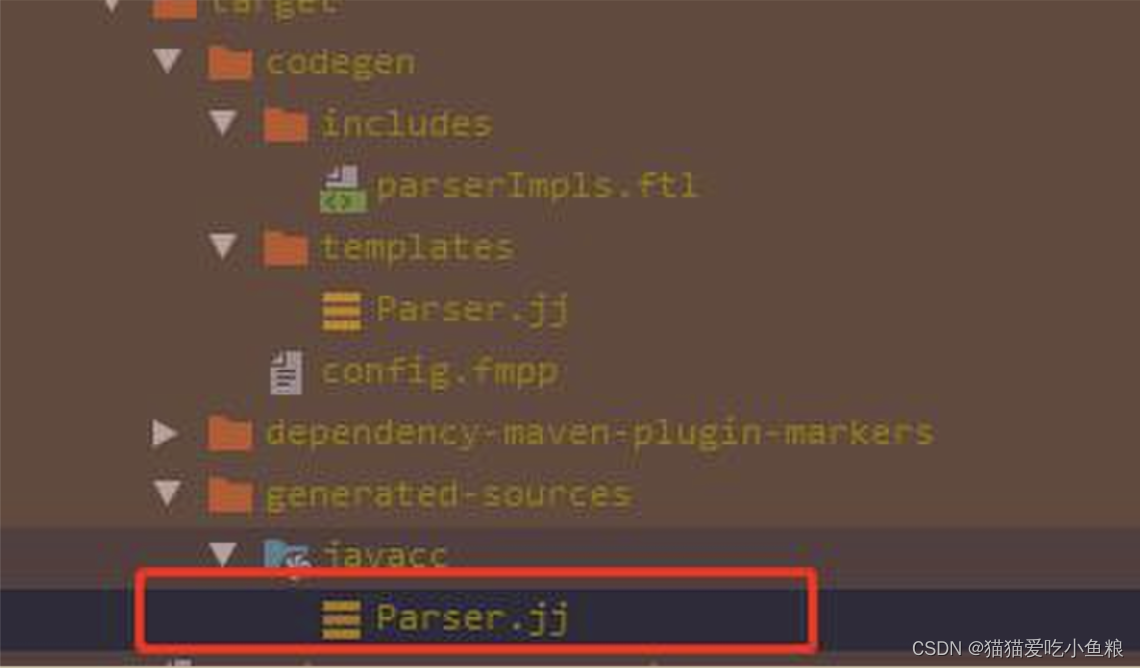
最后一步就是编译语法文件,使用JavaCC插件即可完成。
JavaCC插件配置方式:
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>javacc-maven-plugin</artifactId>
<version>2.6</version>
<executions>
<execution>
<phase>generate-sources</phase>
<id>javacc</id>
<goals>
<goal>javacc</goal>
</goals>
<configuration>
<sourceDirectory>
${basedir}/target/generated-sources/
</sourceDirectory>
<includes>
<include>**/Parser.jj</include>
</includes>
<lookAhead>2</lookAhead>
<isStatic>false</isStatic>
<outputDirectory>${basedir}/src/main/java</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
注意这里的I/O目录,直接将生成的代码放在了项目里。
看起来上面每个阶段用了好几个命令,其实只需要一个Maven命令即可完成所有步骤,即“mvn generate-resources”,该命令包含以上2个操作,4个插件都会被执行。
完成编译后,就可以测试新语法,在测试代码里配置生成的解析器类,然后写一条简单的Load语句。
4.测试Load语句的示例代码
String sql = "LOAD hdfs:'/data/user.txt' TO mysql:'db.t_user' (c1 c2,c3 c4) SEPARATOR ','";
// 解析配置
SqlParser.Config mysqlConfig = SqlParser.config()
// 使用解析器类
.withParserFactory(CdmSqlParserImpl.FACTORY)
.withLex(Lex.MYSQL);
SqlParser parser = SqlParser.create(sql, mysqlConfig);
SqlNode sqlNode = parser.parseQuery();
System.out.println(sqlNode.toString());
输出的结果正是重写的unparse方法所输出的。
通过unparse方法输出的结果:
LOAD 'hdfs': '/data/user.txt' TO 'mysql': 'db.t_user'
('c1' 'c2', 'c3' 'c4')
SEPARATOR ','
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.kler.cn/a/105818.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!