pytorch 入门 (四)案例二:人脸表情识别-VGG16实现
实战教案二:人脸表情识别-VGG16实现
本文为🔗小白入门Pytorch内部限免文章
参考本文所写记录性文章,请在文章开头注明以下内容,复制粘贴即可
- 🍨 本文为🔗小白入门Pytorch中的学习记录博客
- 🍦 参考文章:【小白入门Pytorch】人脸表情识别-VGG16实现
- 🍖 原作者:K同学啊
数据集下载:
链接:https://pan.baidu.com/s/1RvlpOx8v6MudY65Oi78-kQ?pwd=zhfo
提取码:zhfo
–来自百度网盘超级会员V4的分享
目录
- 实战教案二:人脸表情识别-VGG16实现
- 一、导入数据
- 二、VGG-16算法模型
- 1. 优化器与损失函数
- 2. 模型的训练
- 三、可视化
一、导入数据
from torchvision.datasets import CIFAR10 # CIFAR10是一个用于计算机视觉的经典数据集,其中包含60000张32x32的彩色图像,分为10个类别,每个类别有6000张图像。
from torchvision.transforms import transforms # 这是一个常用的模块,用于图像的预处理和增强。
from torch.utils.data import DataLoader # 可以将数据集转化为迭代器的工具,方便在训练循环中加载数据。
from torchvision import datasets # 导入了torchvision下的所有数据集,但实际上这与前面导入CIFAR10是重复的,可能是不必要的。
from torch.optim import Adam # 导入了Adam优化器。Adam是一个常用的、表现良好的深度学习优化器。
import torchvision.models as models # 这个模块提供了各种预训练模型,例如ResNet、VGG、DenseNet等。
import torch.nn.functional as F # 提供了各种激活函数、损失函数和其他的功能函数。
import torch.nn as nn # 这个模块提供了构建神经网络所需的各种工具,如层、损失函数等。
import torch,torchvision # torch是PyTorch的核心库,提供了基础的张量操作;torchvision则是与计算机视觉相关的库,提供了数据集、预处理方法和预训练模型。
train_datadir = '/home/mw/input/kzb324321357/2-Emotion_Images/2-Emotion_Images/train'
test_datadir = '/home/mw/input/kzb324321357/2-Emotion_Images/2-Emotion_Images/test'
train_transforms = transforms.Compose([
transforms.Resize([48, 48]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transforms = transforms.Compose([
transforms.Resize([48, 48]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
# 使用 datasets.ImageFolder 加载训练数据集和测试数据集
# ImageFolder假定所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类别的名字。
# 同时,为加载的数据应用了之前定义的预处理流程。
train_data = datasets.ImageFolder(train_datadir, transform=train_transforms)
test_data = datasets.ImageFolder(test_datadir, transform=test_transforms)
⭐ torch.utils.data.DataLoader详解
torch.utils.data.DataLoader是Pytorch自带的一个数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。
函数原型:
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False, pin_memory_device=‘’)
参数说明:
- dataset(string) :加载的数据集
- batch_size (int,optional) :每批加载的样本大小(默认值:1)
- shuffle(bool,optional) : 如果为
True,每个epoch重新排列数据。 - sampler (Sampler or iterable, optional) : 定义从数据集中抽取样本的策略。 可以是任何实现了 len 的 Iterable。 如果指定,则不得指定 shuffle 。
- batch_sampler (Sampler or iterable, optional) : 类似于sampler,但一次返回一批索引。与 batch_size、shuffle、sampler 和 drop_last 互斥。
- num_workers(int,optional) : 用于数据加载的子进程数。 0 表示数据将在主进程中加载(默认值:0)。
- pin_memory (bool,optional) : 如果为 True,数据加载器将在返回之前将张量复制到设备/CUDA 固定内存中。 如果数据元素是自定义类型,或者collate_fn返回一个自定义类型的批次。
- drop_last(bool,optional) : 如果数据集大小不能被批次大小整除,则设置为 True 以删除最后一个不完整的批次。 如果 False 并且数据集的大小不能被批大小整除,则最后一批将保留。 (默认值:False)
- timeout(numeric,optional) : 设置数据读取的超时时间 , 超过这个时间还没读取到数据的话就会报错。(默认值:0)
- worker_init_fn(callable,optional) : 如果不是 None,这将在步长之后和数据加载之前在每个工作子进程上调用,并使用工作 id([0,num_workers - 1] 中的一个 int)的顺序逐个导入。 (默认:None)
# 创建训练数据加载器(data loader),用于将数据分成小批次进行训练
train_loader = torch.utils.data.DataLoader(train_data,
batch_size=16, # 每个批次包含的图像数量
shuffle=True, # 随机打乱数据
num_workers=4) # 使用多少个子进程来加载数据
# 创建测试数据加载器(data loader),用于将测试数据分成小批次进行测试
test_loader = torch.utils.data.DataLoader(test_data,
batch_size=16, # 每个批次包含的图像数量
shuffle=True, # 随机打乱数据
num_workers=4) # 使用多少个子进程来加载数据
# 打印数据集的信息
# 请注意,这里使用len(train_loader) * 16来计算图像总数是基于批次大小为16的假设。
# 实际上,最后一个批次的图像数量可能少于16。
print("The number of images in a training set is: ", len(train_loader) * 16) # 计算训练集中的图像总数
print("The number of images in a test set is: ", len(test_loader) * 16) # 计算测试集中的图像总数
print("The number of batches per epoch is: ", len(train_loader)) # 计算每个 epoch 中的批次数
# 定义数据集的类别标签
classes = ('Angry', 'Fear', 'Happy', 'Surprise')
The number of images in a training set is: 18480
The number of images in a test set is: 2320
The number of batches per epoch is: 1155
二、VGG-16算法模型
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
# 直接调用官方封装好的VGG16模型
model = models.vgg16(pretrained = True)
model
Using cuda device
Downloading: "https://download.pytorch.org/models/vgg16-397923af.pth" to /home/mw/.cache/torch/hub/checkpoints/vgg16-397923af.pth
HBox(children=(FloatProgress(value=0.0, max=553433881.0), HTML(value='')))
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
1. 优化器与损失函数
optimizer = Adam(model.parameters(),lr = 0.0001,weight_decay = 0.0001)
loss_model = nn.CrossEntropyLoss()
import torch
from torch.autograd import Variable
# 定义训练函数
def train(model,train_loader,loss_model,optimizer):
# 将模型移动到指定设备(如:GPU)
model = model.to(device)
# 将模型设置为训练模式(启用梯度计算)
model.train()
for i,(images,labels) in enumerate(train_loader,0):
# 将输入数据和标签移动到指定设备
images = Variable(images.to(device))
labels = Variable(labels.to(device))
# 梯度清零
optimizer.zero_grad()
# 前向传播得到模型输出
outputs = model(images)
# 计算损失
loss = loss_model(outputs,labels)
# 反向传播
loss.backward()
# 更新模型参数
optimizer.step()
# 每隔1000个批次输出一次损失
if i%1000 == 0:
print('[%5d] loss: %.3f' % (i,loss))
# 定义测试函数
def test(model,test_loader,loss_model):
# 获取测试数据集大小
size = len(test_loader.dataset)
# 获取测试数据批次数
num_batches = len(test_loader)
# 将模型设置为评估模式(不进行梯度计算)
model.eval()
test_loss,correct = 0,0
# 在不计算梯度的上下文中执行测试
with torch.no_grad():
for X,y in test_loader:
X,y = X.to(device),y.to(device)
# 使用模型进行前向传播得到预测
pred = model(X)
# 计算损失值,并将其累积到test_loss中
test_loss += loss_model(pred,y).item()
# 计算正确预测的数量
correct += (pred.argmax(1)==y).type(torch.float).sum().item()
# 计算平均测试损失和准确率
test_loss /= num_batches
correct /= size
print(f"Test Error:\n Accuracy:{(100*correct):>0.1f}%,Avg loss:{test_loss:>8f} \n")
return correct,test_loss
提问:梯度清零有三种放置方法吗,放到循环最前面或者最后面,或者反向传播之前
是的,您理解得很准确。在PyTorch中,optimizer.zero_grad()的位置有一定的灵活性。以下是这三种常见的放置方法:
- 循环开始时:在每次迭代的最开始,即前向传播之前,清零梯度。
- 反向传播之前:在前向传播之后、反向传播之前,清零梯度。这也是您提供的代码中使用的方法。
- 循环结束时:在每次迭代的最后,即更新参数之后,清零梯度。
这三种方法在大多数情况下都是等效的,因为关键是确保在进行下一次反向传播之前梯度是清零的。
但是,如果您在一个迭代中进行多次反向传播(例如,当您想要累加梯度时),那么您必须在每次反向传播之前清零梯度。在这种特定情境中,第二种方法(反向传播之前)是最合适的。
对于大多数常规的训练循环,选择哪种方法主要是根据个人偏好或代码的可读性来决定的。
2. 模型的训练
# 创建一个空列表用于存储每个epoch的测试集准确率
test_acc_list = []
# 定义训练的总论数
epochs = 10
# 开始训练循环,每个epoch 都会执行一下操作
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
# 在训练数据上训练模型
train(model,train_loader,loss_model,optimizer)
# 在测试数据集上测试模型的性能,并获取测试准确率和测试损失
test_acc,test_loss = test(model,test_loader,loss_model)
# 将测试准确率添加到列表中,以便后续分析
test_acc_list.append(test_acc)
# 所有epoch完成后打印完成消息
print("Done!")
Epoch 1
-------------------------------
[ 0] loss: 0.129
[ 1000] loss: 0.005
Test Error:
Accuracy:77.4%,Avg loss:1.069592
Epoch 2
-------------------------------
[ 0] loss: 0.028
[ 1000] loss: 0.055
Test Error:
Accuracy:78.7%,Avg loss:0.976879
Epoch 3
-------------------------------
[ 0] loss: 0.033
[ 1000] loss: 0.050
Test Error:
Accuracy:77.9%,Avg loss:1.202651
Epoch 4
-------------------------------
[ 0] loss: 0.051
[ 1000] loss: 0.356
Test Error:
Accuracy:79.0%,Avg loss:1.080943
Epoch 5
-------------------------------
[ 0] loss: 0.001
[ 1000] loss: 0.183
Test Error:
Accuracy:78.7%,Avg loss:1.248081
Epoch 6
-------------------------------
[ 0] loss: 0.003
[ 1000] loss: 0.127
Test Error:
Accuracy:78.4%,Avg loss:1.129110
Epoch 7
-------------------------------
[ 0] loss: 0.003
[ 1000] loss: 0.076
Test Error:
Accuracy:77.6%,Avg loss:1.200314
Epoch 8
-------------------------------
[ 0] loss: 0.042
[ 1000] loss: 0.071
Test Error:
Accuracy:78.0%,Avg loss:1.149877
Epoch 9
-------------------------------
[ 0] loss: 0.002
[ 1000] loss: 0.212
Test Error:
Accuracy:78.0%,Avg loss:1.353625
Epoch 10
-------------------------------
[ 0] loss: 0.001
[ 1000] loss: 0.001
Test Error:
Accuracy:78.5%,Avg loss:1.249242
Done!
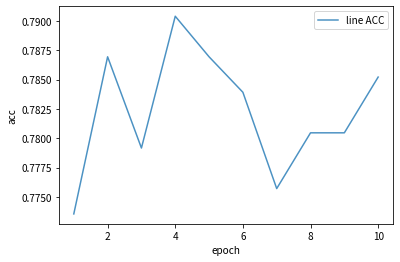
test_acc_list
[0.773552290406223,
0.7869490060501296,
0.7791702679343129,
0.7904062229904927,
0.7869490060501296,
0.783923941227312,
0.7757130509939498,
0.780466724286949,
0.780466724286949,
0.7852203975799481]
三、可视化
import numpy as np
import matplotlib.pyplot as plt
x = [i for i in range(1,11)]
plt.plot(x,test_acc_list,label="line ACC",alpha = 0.8)
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()