【期中复习】深度学习
文章目录
- 机器(深度)学习的四大核心要素
- 为什么深度学习,不增加网络宽度
- 黑盒模型的问题
- 计算图
- 线性神经网络
- 梯度下降
- 学习率
- 优化方法
- softmax函数用于多分类
- 交叉熵
- 线性回归与softmax回归的对比
- 为什么需要非线性激活函数
- 感知机
- 线性回归、softmax回归、感知机和支持向量机的比较
- sigmoid激活函数
- 双曲正切(tanh)激活函数
- 线性(ReLU)修正函数
- MLP
- K折交叉验证
- 估计模型的复杂度
- 数据复杂度
- 欠拟合和过拟合
- 欠拟合和过拟合的原因
- 正则化
- Dropout
- 梯度爆炸和梯度消失
- 权重初始化
- 参数初始化
机器(深度)学习的四大核心要素
数据、模型、性能度量(目标函数)、优化方法
为什么深度学习,不增加网络宽度
- 增加深度使得学习高层次、抽象特征成为可能
- 相比于增加宽度,增加深度的学习效率更高。比如对于一些要学习的多项式函数,浅层网络需要指数增长的神经元个数,其拟合效果才能匹配上多项式增长的深层网络
宽度的优点:增加宽度会增加模型的记忆能力
黑盒模型的问题
数据安全隐患、输出不可信、模型改进局限、模型应用局限
计算图

线性神经网络
-
模型

-
性能度量
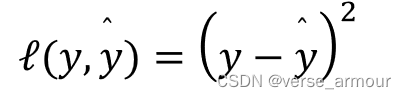
-
优化方法

梯度下降
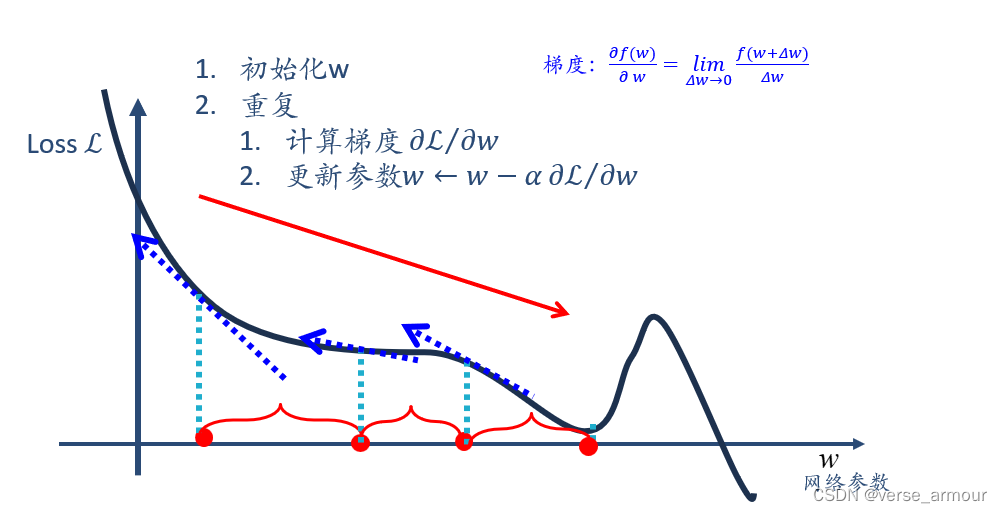
学习率
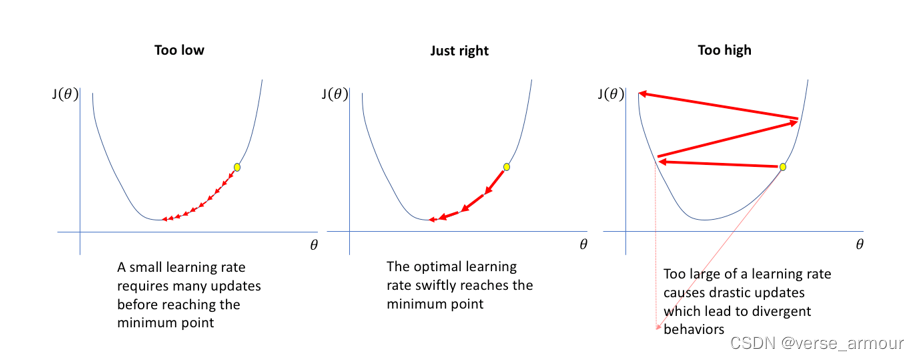
优化方法

softmax函数用于多分类
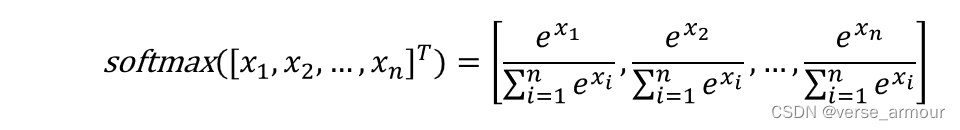
- 可用:量化样本间的相对大小(等比例缩放不变)
- 概率:每个样本取值范围[0,1],总和等于1
- 可训练:可微分
交叉熵

线性回归与softmax回归的对比

为什么需要非线性激活函数

因为是线性的,神经网络虽然引入了隐藏层,却依然等价于一个单层神经网络
感知机


线性回归、softmax回归、感知机和支持向量机的比较

sigmoid激活函数
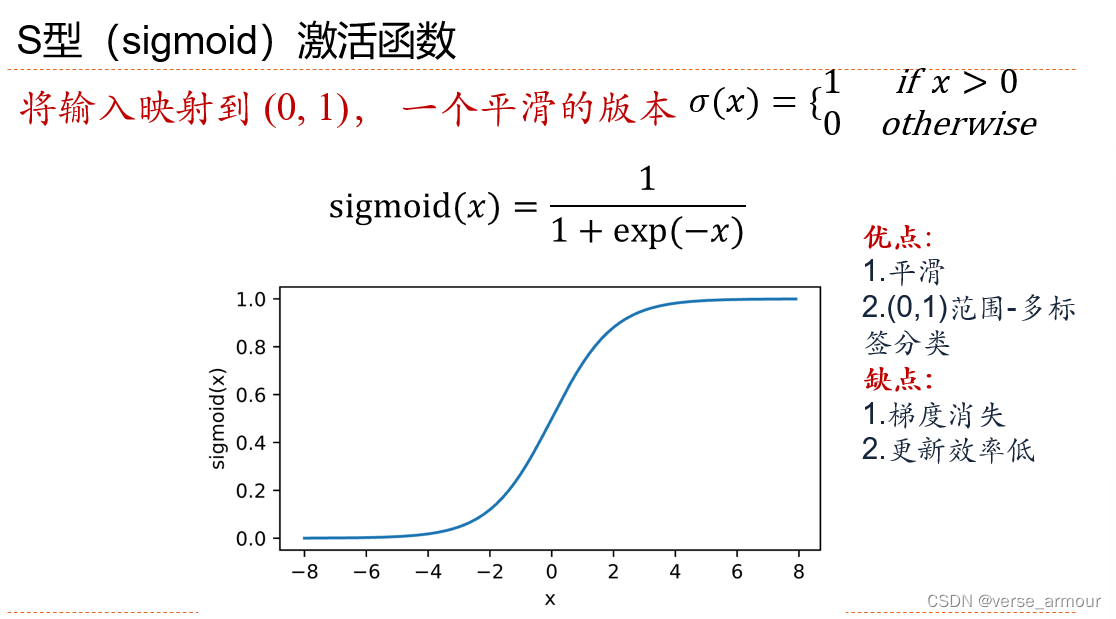
- 优点
(0-1),平滑、多标签分类 - 缺点
梯度消失、更新效率低
双曲正切(tanh)激活函数
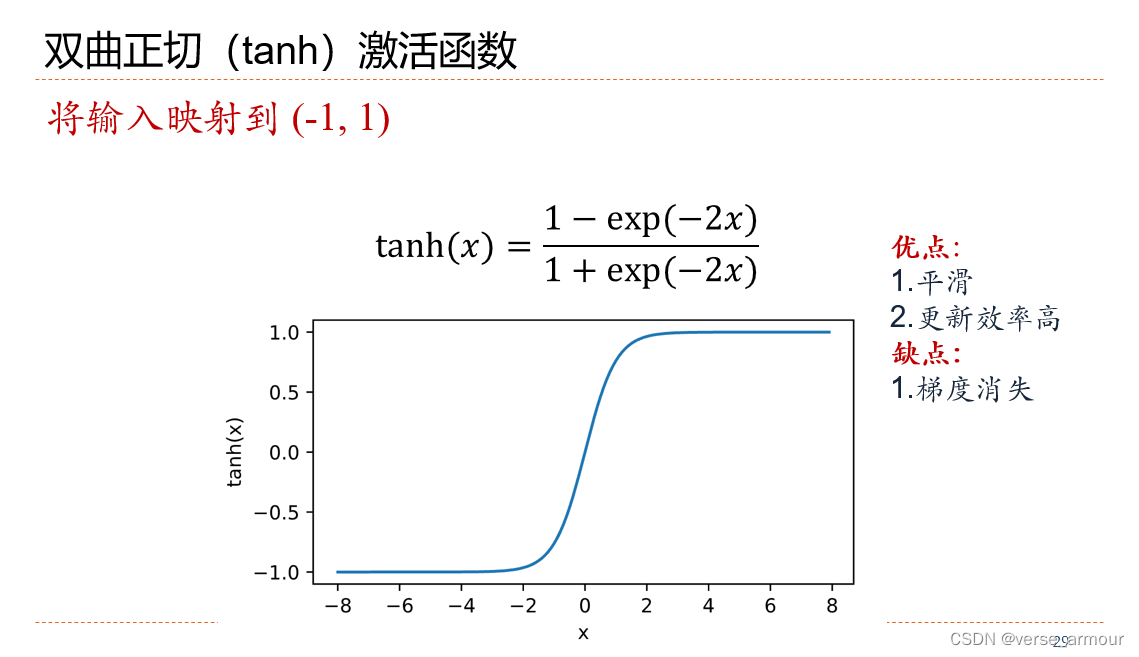
- 优点
(-1,1),平滑,更新效率高 - 缺点
梯度消失
线性(ReLU)修正函数
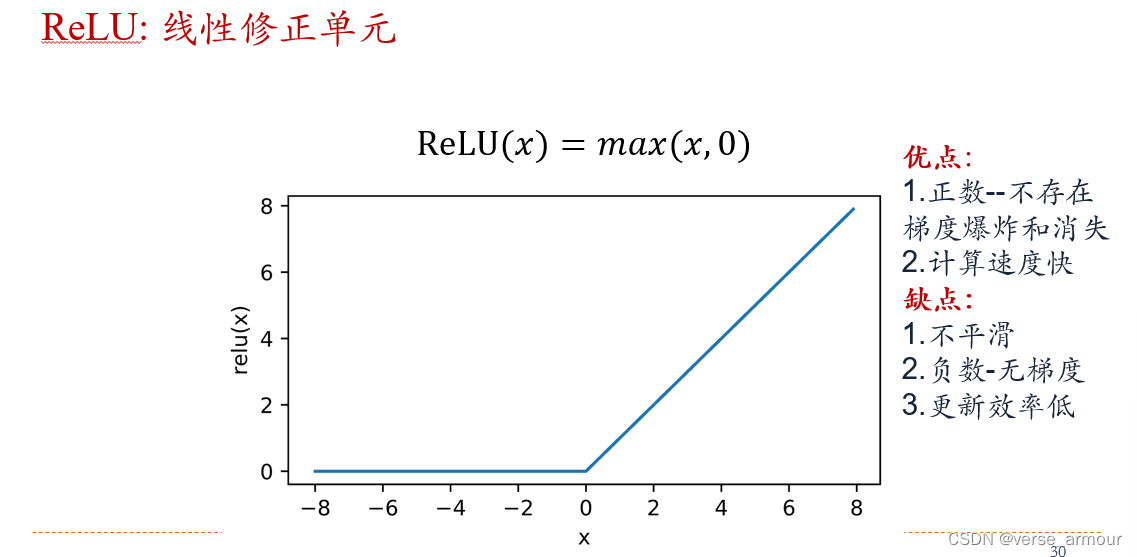
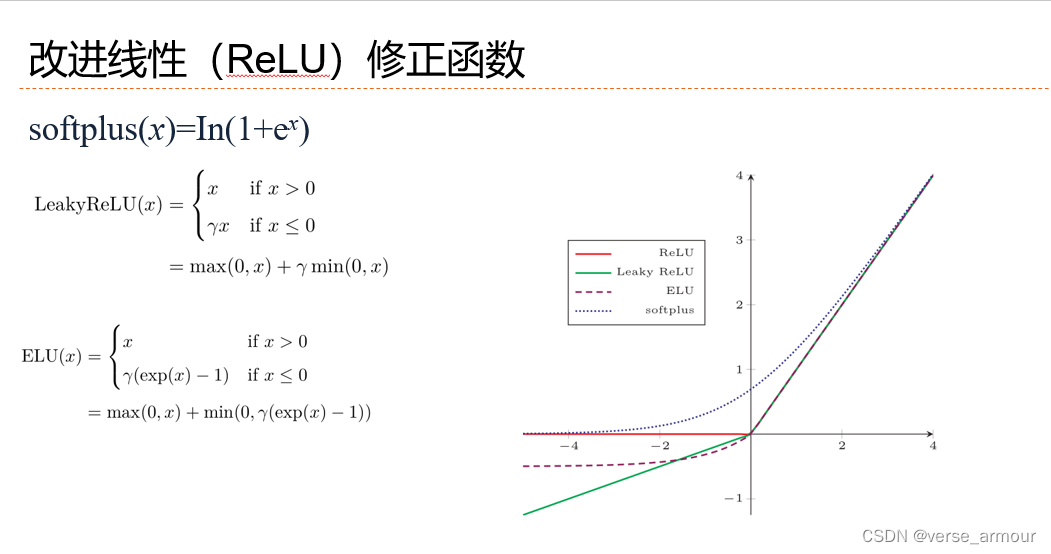
MLP




K折交叉验证
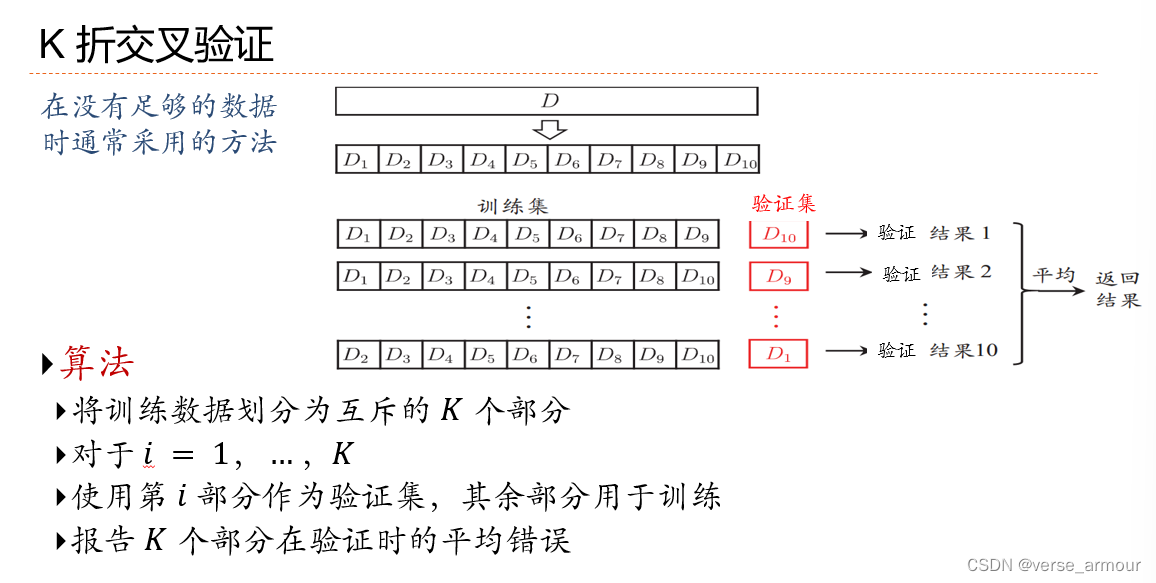

估计模型的复杂度

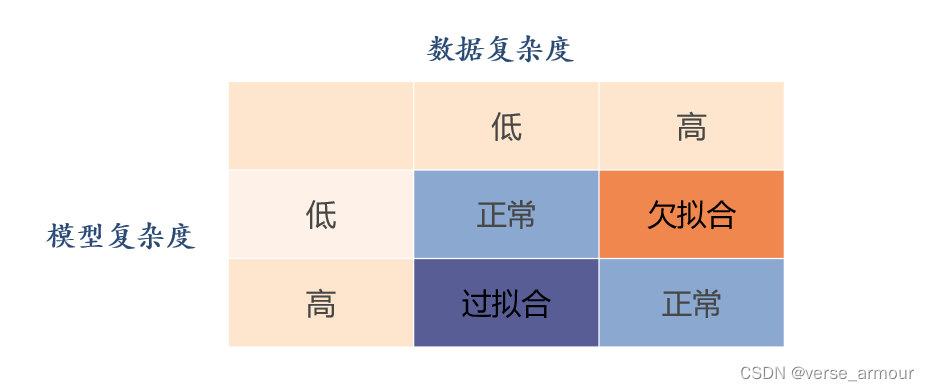
数据复杂度

欠拟合和过拟合
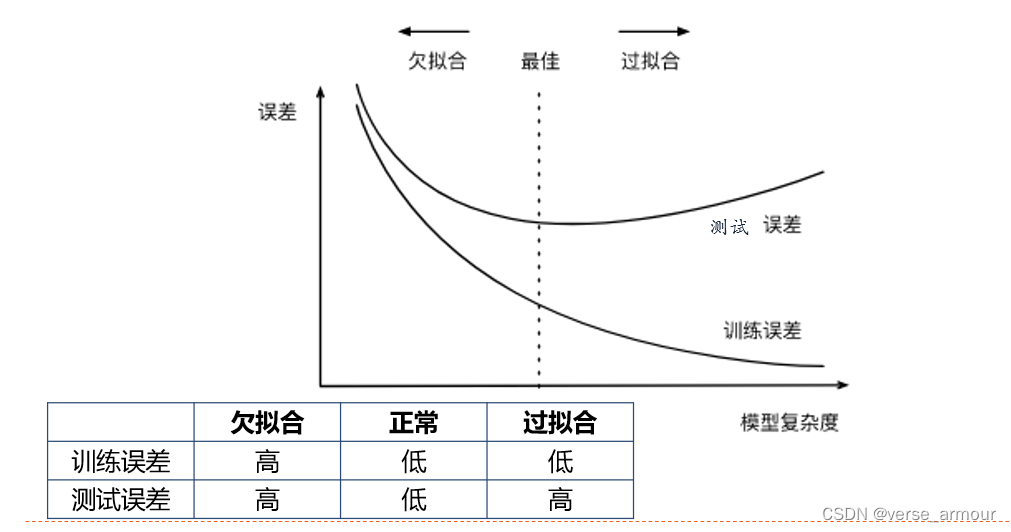
欠拟合和过拟合的原因
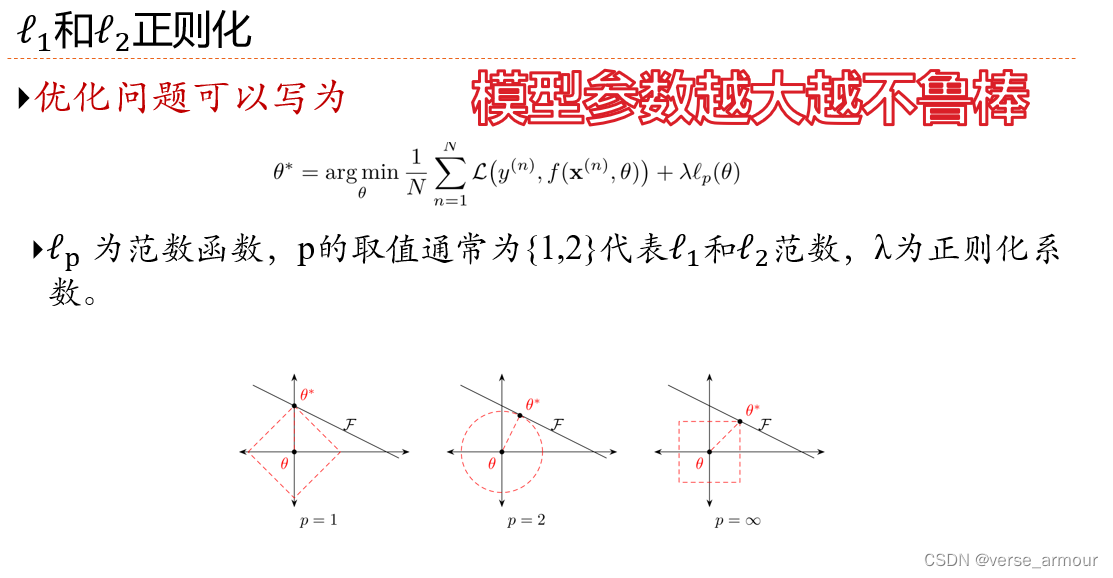
正则化
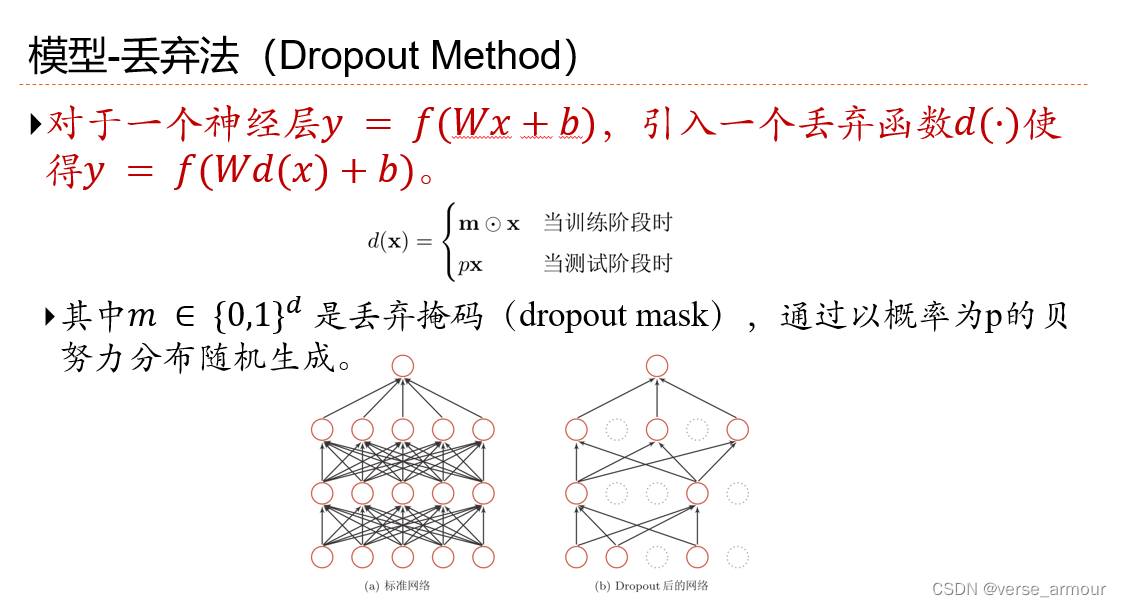
Dropout
梯度爆炸和梯度消失


权重初始化

参数初始化

