python爬虫request和BeautifulSoup使用
request使用
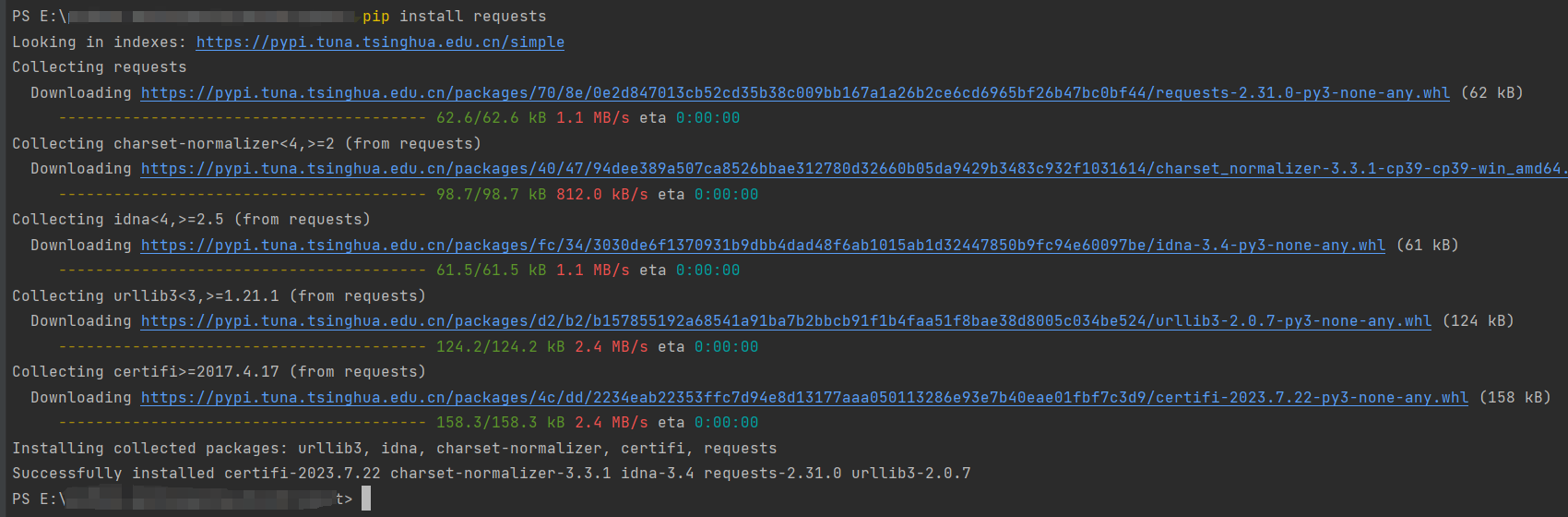
1.安装request
pip install request
2.引入库
import requests
3.编写代码
发送请求
我们通过以下代码可以打开豆瓣top250的网站
response = requests.get(f"https://movie.douban.com/top250")
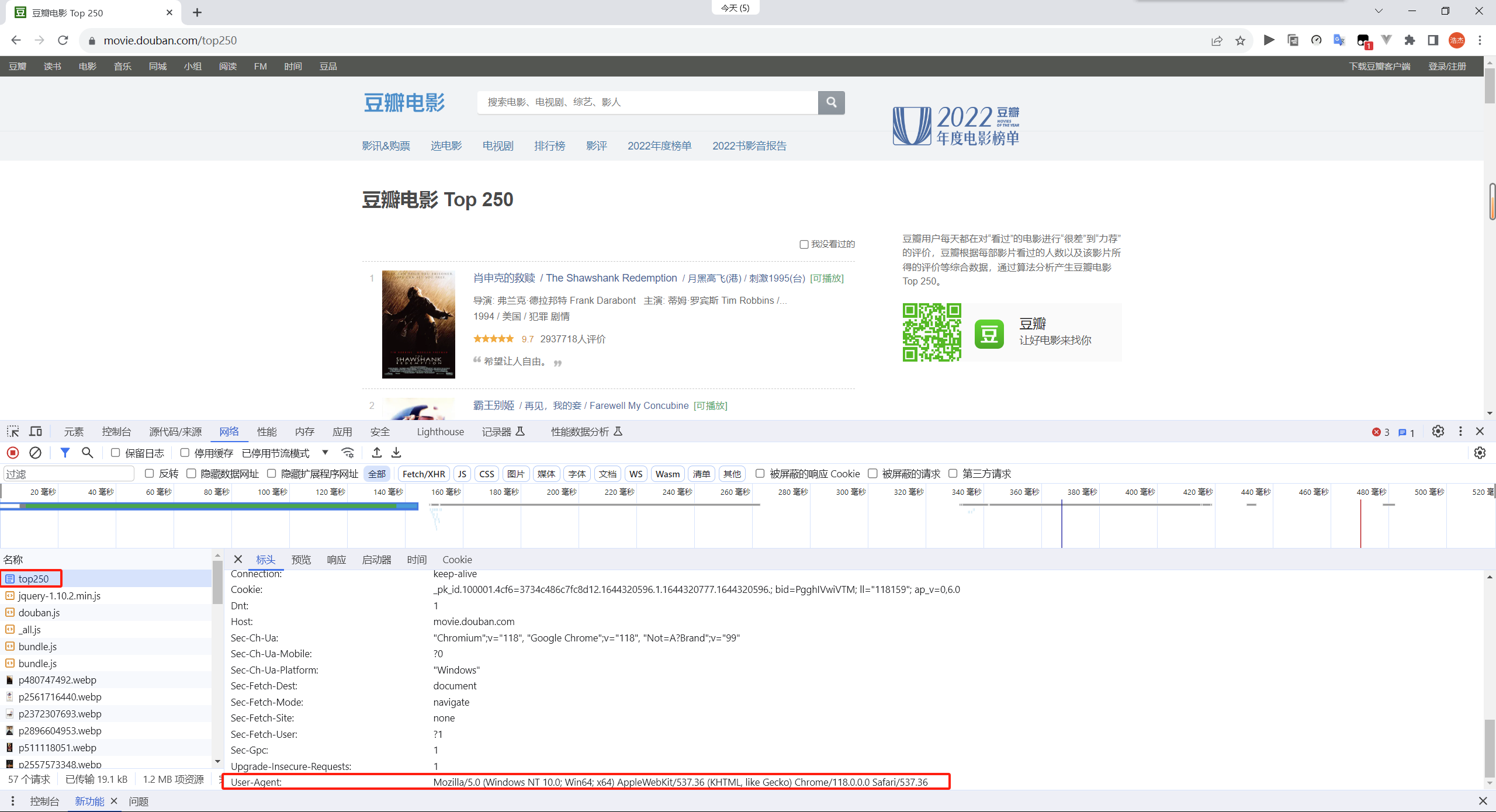
但因为该网站加入了反爬机制,所以我们需要在我们的请求报文的头部加入User-Agent的信息
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(f"https://movie.douban.com/top250",headers=headers)
User-Agent可以通过访问网站时按f12查看获取
我们可以通过response的ok属性判断是否请求成功
import requests
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:
print("请求成功!")
else:
print("请求失败!")
此时如果请求成功,控制台就会打印请求成功!

获取网页的html
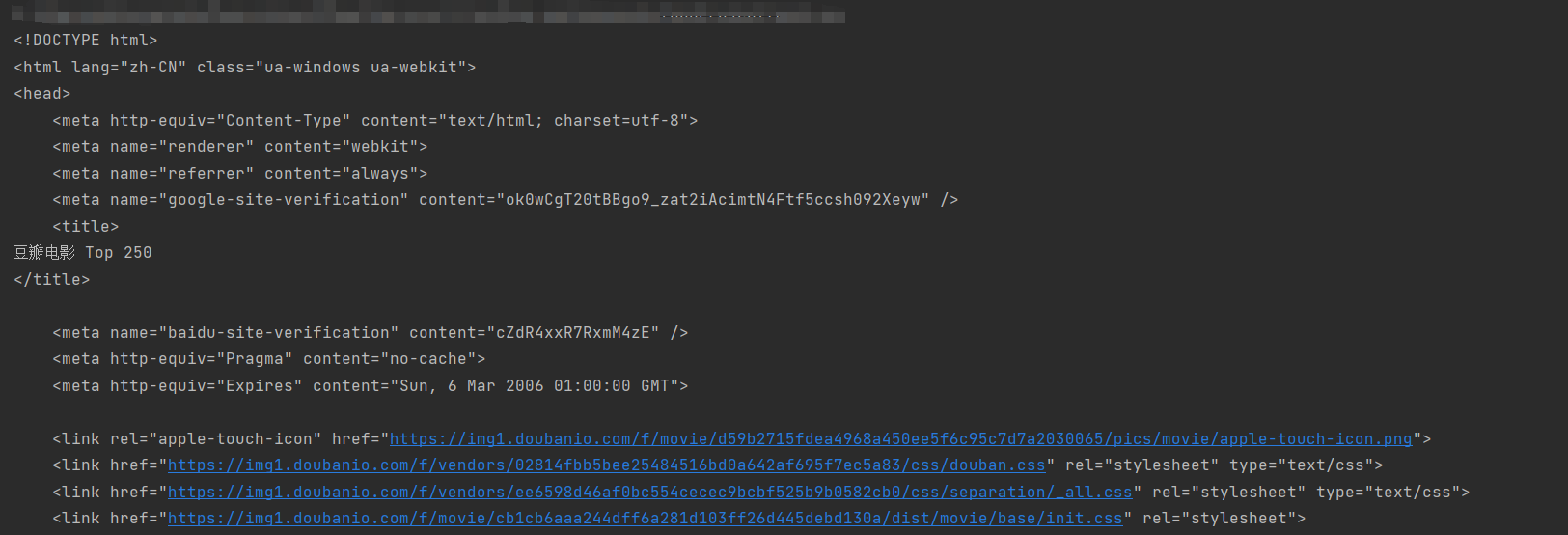
我们可以通过response的text的属性来获取网页的html
import requests
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:
html = response.text
print(html)
else:
print("请求失败!")
此时请求成功就会打印页面的html了
BeautifulSoup使用
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
简单的说,我们可以拿他来解析html页面,来获取html的元素
1.安装BeautifulSoup
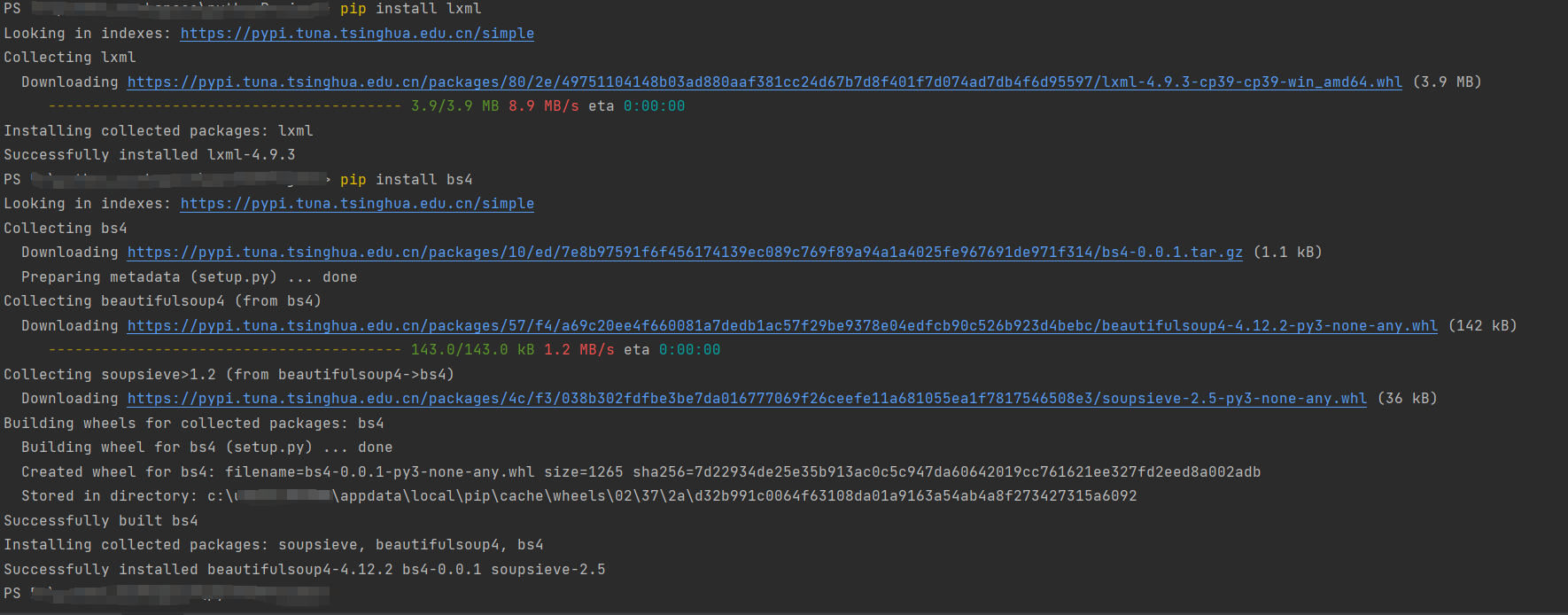
要使用BeautifulSoup4需要先安装lxml,再安装bs4
pip install bs4
pip install bs4
2.引入库
from bs4 import BeautifulSoup
3.编写代码
获取元素
我们通过BeautifulSoup()就可以得到解析后的soup对象
soup = BeautifulSoup(html, "html.parser")
使用findAll函数就可以找到我们想要的元素,例如:我们想找到span标签中,class为title的元素
all_titls = soup.findAll("span", attrs={"class": "title"})
此时我们代码如下
from bs4 import BeautifulSoup
import requests
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:
html = response.text
soup = BeautifulSoup(html, "html.parser")
all_titls = soup.findAll("span", attrs={"class": "title"})
print(all_titls)
else:
print("请求失败!")
运行结果
元素处理
我们虽然找到了span标签中,class为title的元素,但我们不需要span标签中的内容,所以我们需要对他进行处理
首先我们发现,all_titls其实是一个数组,所以我们可以遍历他,这样就可以得到每一个span元素,通过string的属性就可以得到span标签中间的内容
from bs4 import BeautifulSoup
import requests
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:
html = response.text
soup = BeautifulSoup(html, "html.parser")
all_titls = soup.findAll("span", attrs={"class": "title"})
for title in all_titls:
title_string = title.string
print(title_string)
else:
print("请求失败!")
此时我们发现,我们虽然得到span标签中间的内容,但其中含有电影名字的英文名这是我们不需要的
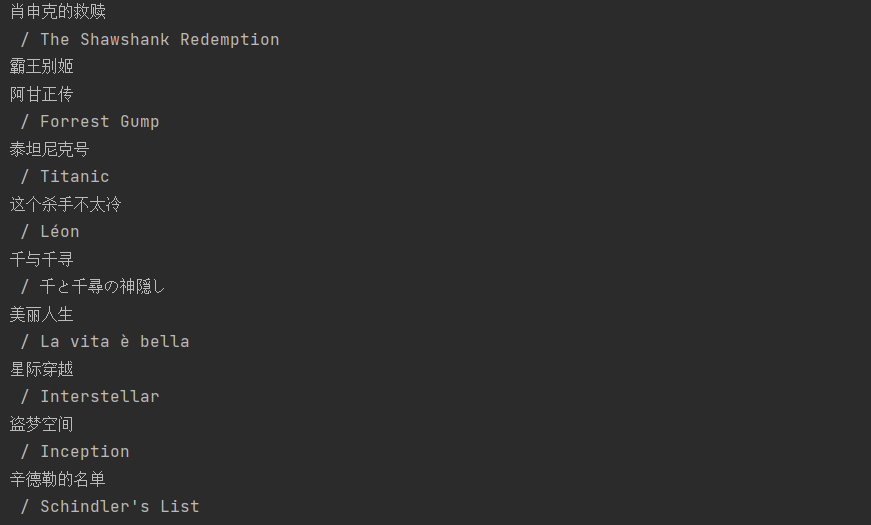
通过观察我们发现,每个英文名前都是带有/的,所以我们可以判断其是否含有"/"来进行过滤
from bs4 import BeautifulSoup
import requests
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:
html = response.text
soup = BeautifulSoup(html, "html.parser")
all_titls = soup.findAll("span", attrs={"class": "title"})
for title in all_titls:
title_string = title.string
if "/" not in title_string:
print(title_string)
else:
print("请求失败!")

整合
虽然此时我们打印出了我们想要的数据,但这只是其中一页的,且只是打印,并没有存入数据库或者某个文件里
打印所有页
通过观察第二页的路径,我们发现在点击第二页时系统会传一个start的属性,这个属性除以25在加1就是我们需要的页数,反过来就是 (页数-1)*25 = start
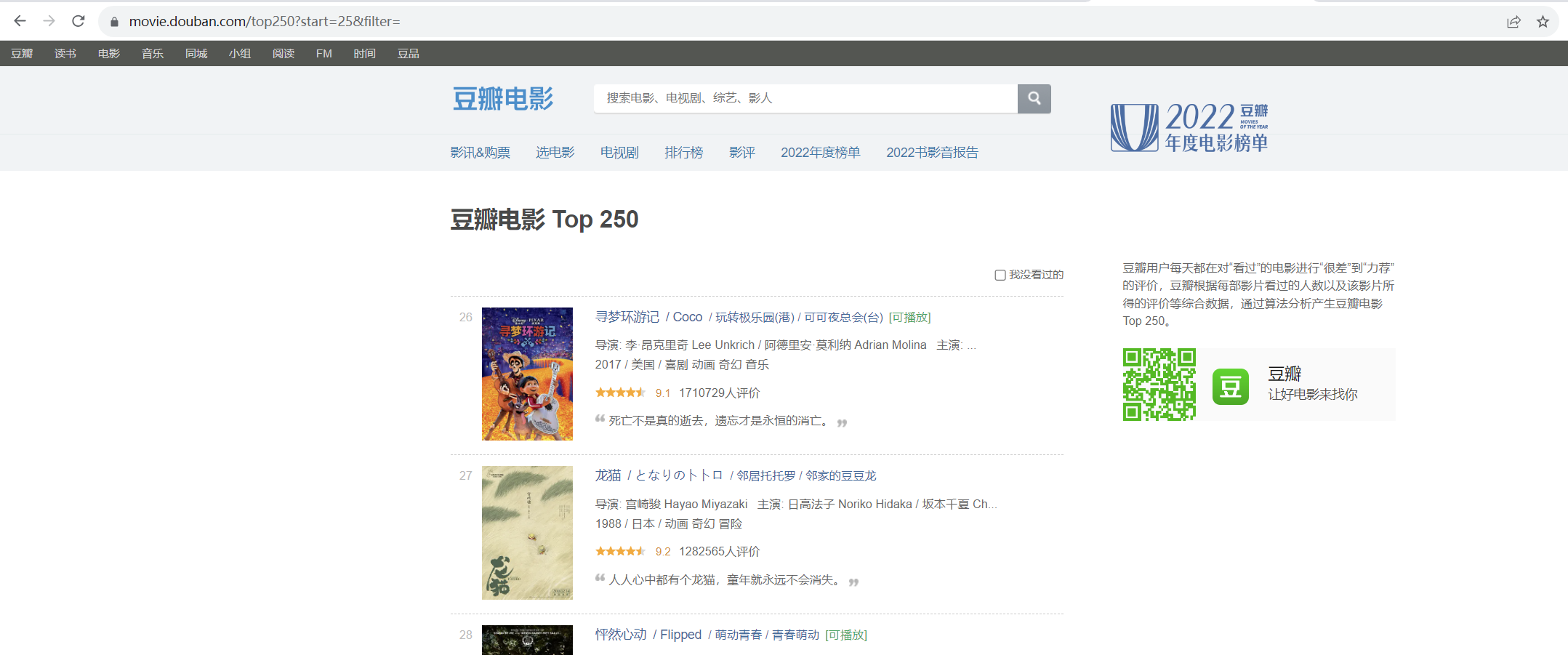
所以我们可以通过for循环,依次传入0,25,50…
from bs4 import BeautifulSoup
import requests
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
for start_num in range(0,250,25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)
if response.ok:
html = response.text
soup = BeautifulSoup(html,"html.parser")
all_titls = soup.findAll("span",attrs={"class":"title"})
for title in all_titls:
title_string = title.string
if "/" not in title_string:
print(title_string)
else:
print("请求失败!")
这样我们就得到了所有的电影名
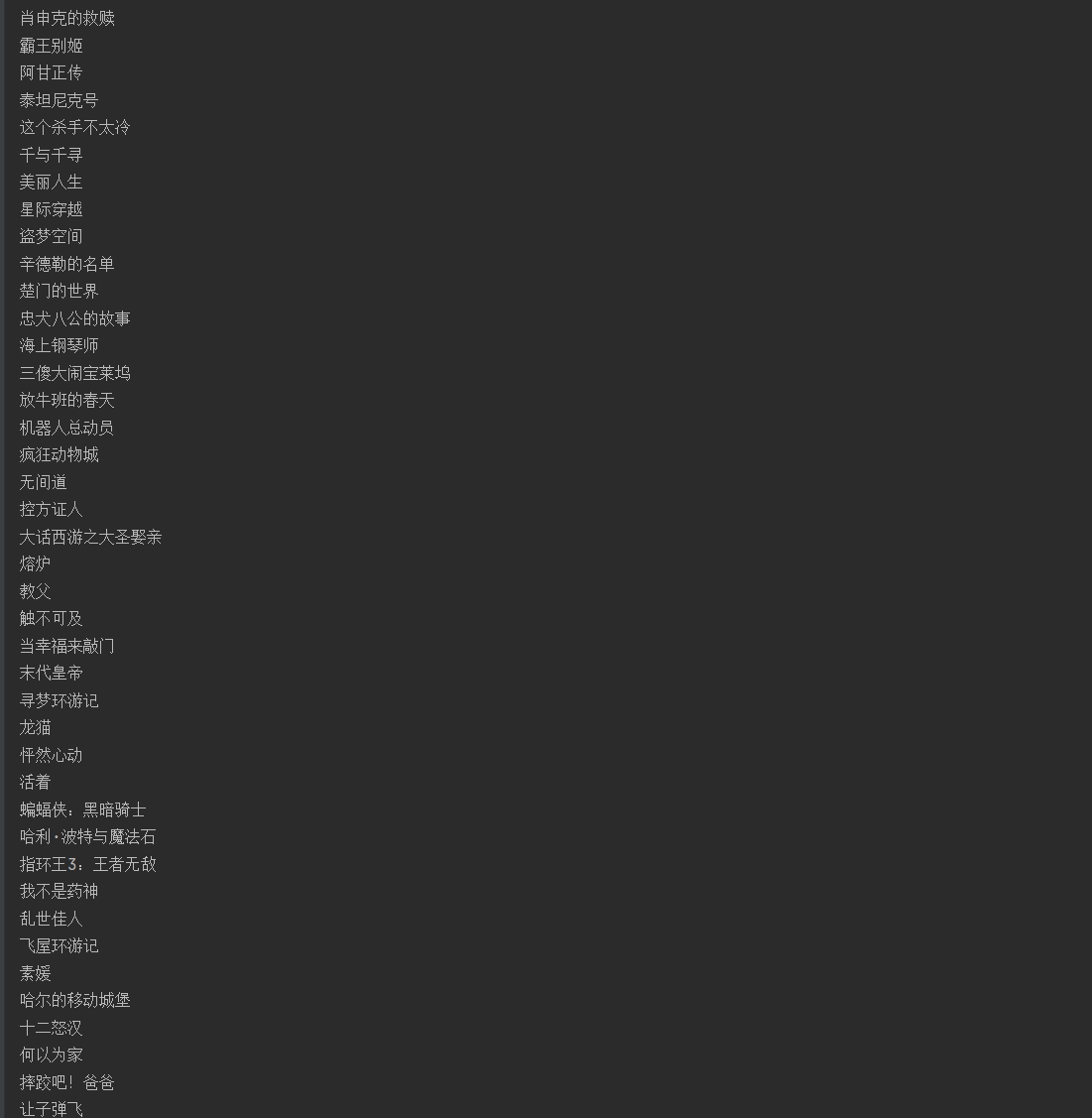
存入txt
这里我们演示将数据存入记事本中,我们定义个数组,将所有电影的名字存入该数组,最后遍历数组写入txt文件即可
from bs4 import BeautifulSoup
import requests
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
titles = []
for start_num in range(0,250,25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)
if response.ok:
html = response.text
soup = BeautifulSoup(html,"html.parser")
all_titls = soup.findAll("span",attrs={"class":"title"})
for title in all_titls:
title_string = title.string
if "/" not in title_string:
titles.append(title_string)
else:
print("请求失败!")
with open(r'豆瓣top250.txt', 'w') as f:
for i in titles:
f.write(i + '\n')
