基础课13——数据异常处理
数据异常是指数据不符合预期或不符合常识的情况。数据异常可能会导致数据分析结果不准确,甚至是错误,因此在进行数据分析之前需要对数据进行清洗和验证。
常见的数据异常包括缺失值、重复值、异常值等。
- 缺失值是指数据中存在未知值或未定义的值,这可能会导致数据分析结果不准确。
- 重复值是指数据中存在多个相同的值,这可能会导致数据分析结果错误。
- 异常值是指数据中存在不符合常识的值,例如异常高的销售额、异常低的温度等,这些值可能会对数据分析结果产生负面影响。
1.数据异常类型
1.1语法类异常


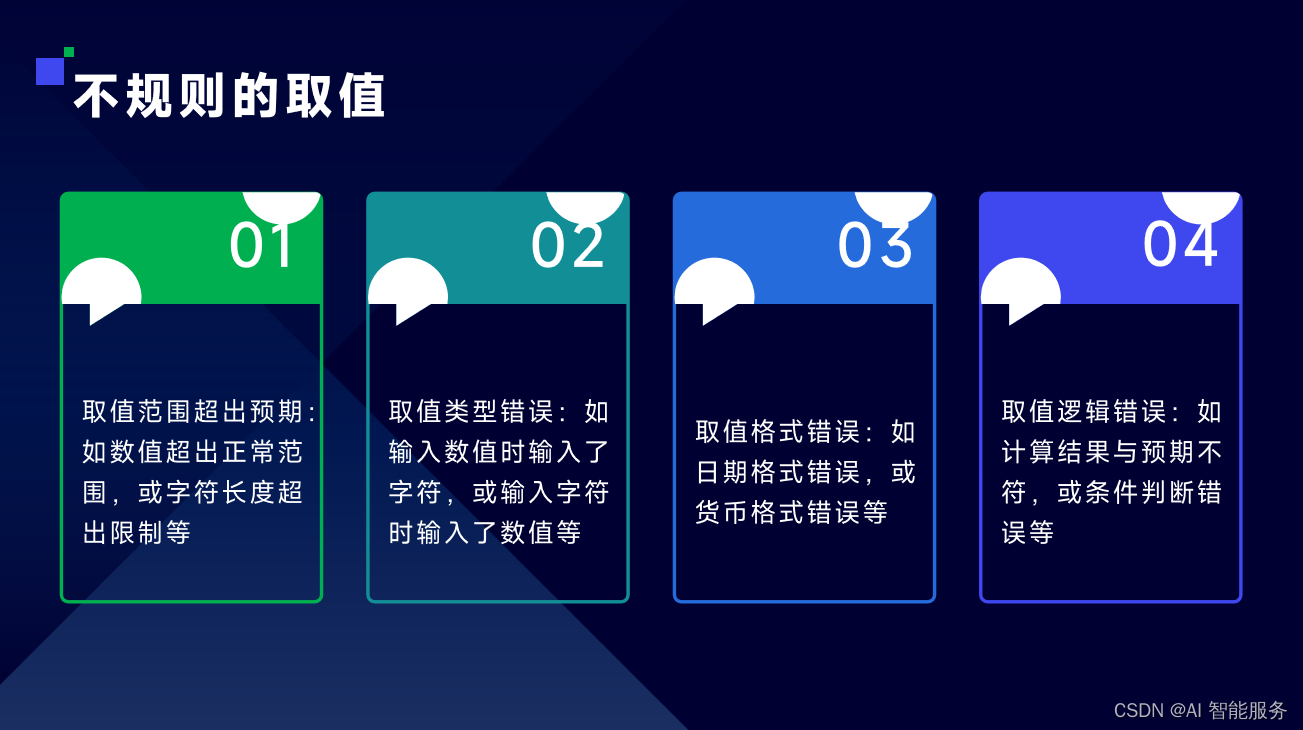
1.2语义类异常
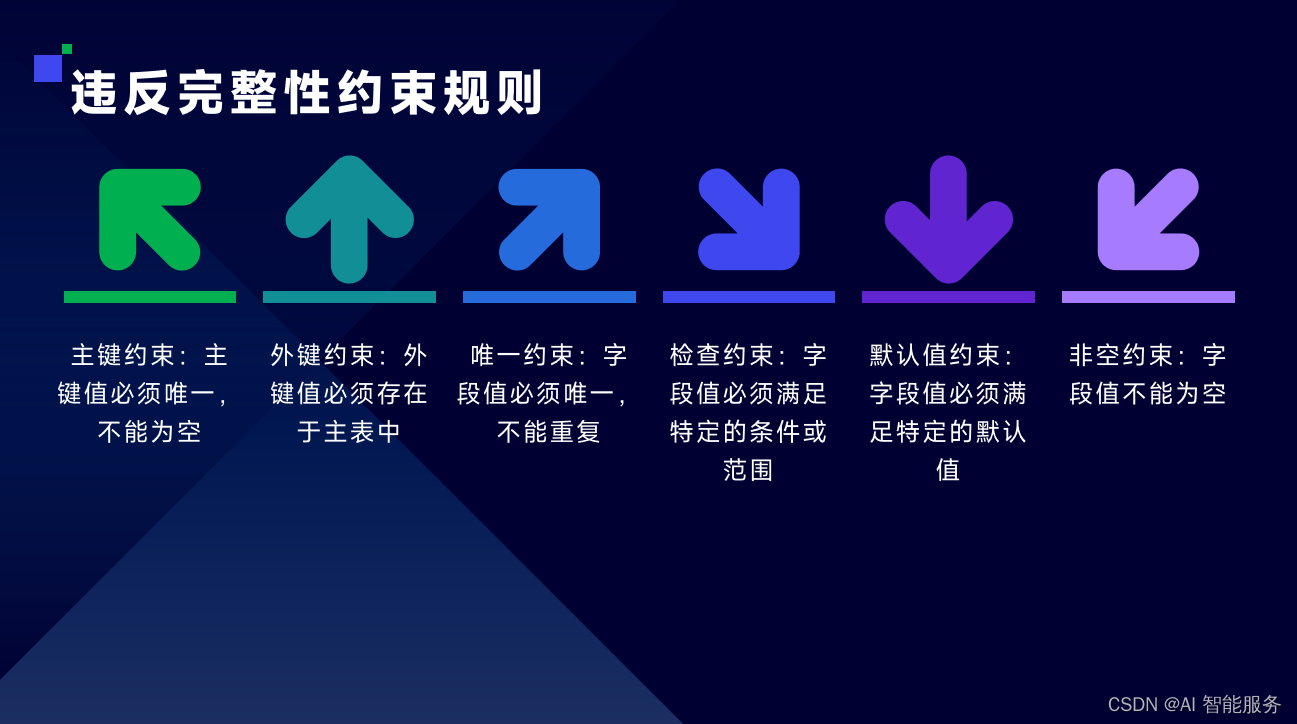


1.3缺失类异常


2.数据异常的识别
数据异常中的异常值可以通过以下几种方法进行识别:
- 箱线图法:箱线图可以展示一组数据的分布情况,包括最小值、下四分位数(Q1)、中位数(Q2)、上四分位数(Q3)、最大值。在箱线图上,超出上界或下界的数值被视为异常值。
- 标准差检测法:当数据服从正态分布时,99%的数值与均值的距离应在3个标准差之内,95%的数值与均值的距离应在2个标准差之内。如果某个数值与均值的距离超过2个标准差,则可视为异常值。
- DBSCAN聚类法:DBSCAN是一种基于密度的聚类算法,可以用于检测异常值。在DBSCAN中,某个样本点如果不在以eps为单位的聚类簇圆内,则此样本点很有可能为异常点。
- 孤立森林模型法:孤立森林是一种无监督学习算法,可以用于识别异常值。其判断逻辑的前提是异常值与正常值的属性差异较大,且异常值类别的样本数量较少。
3.数据异常处理
3.1缺失数据处理
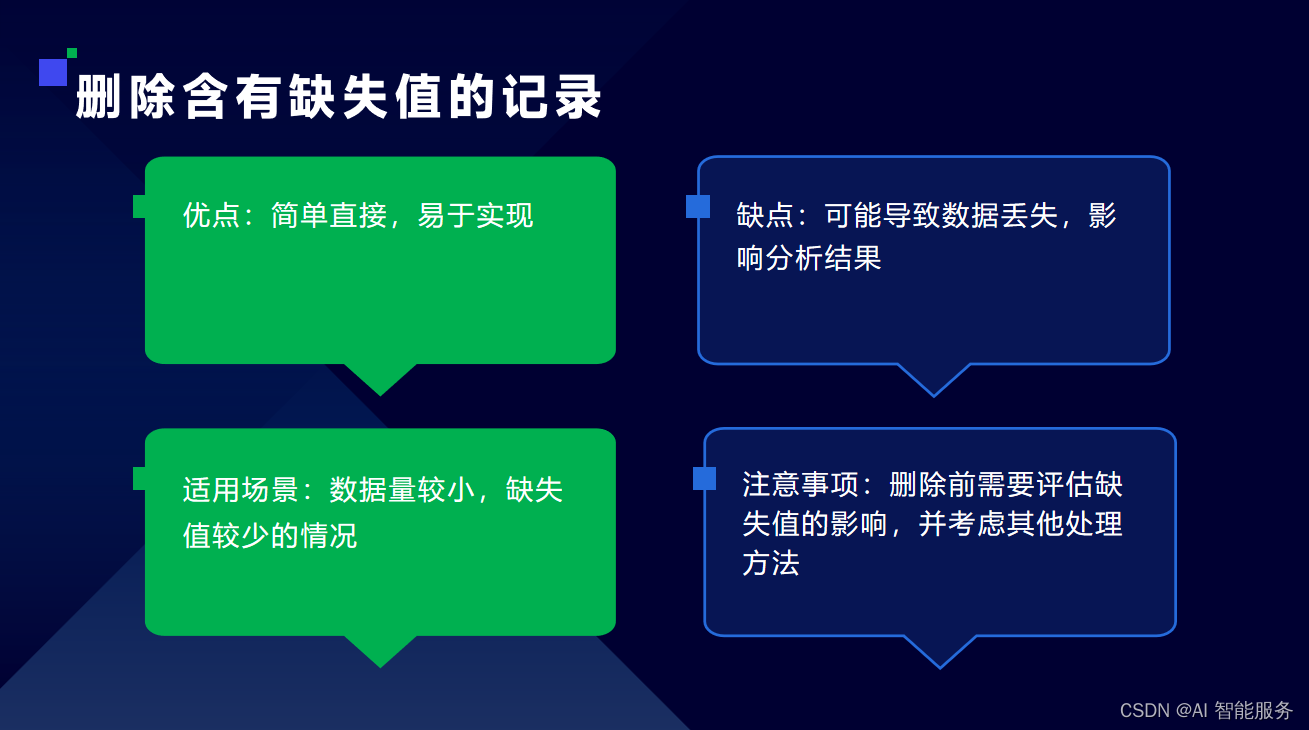
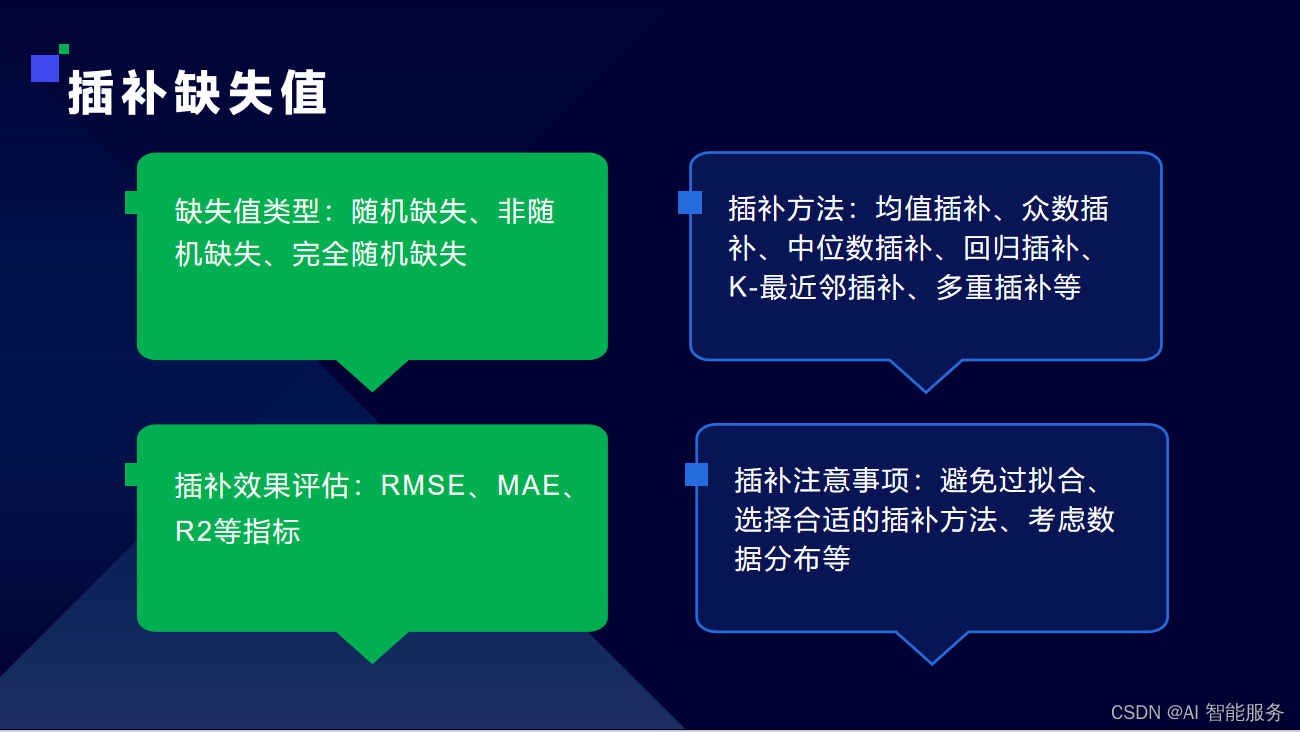
3.2重复数据处理
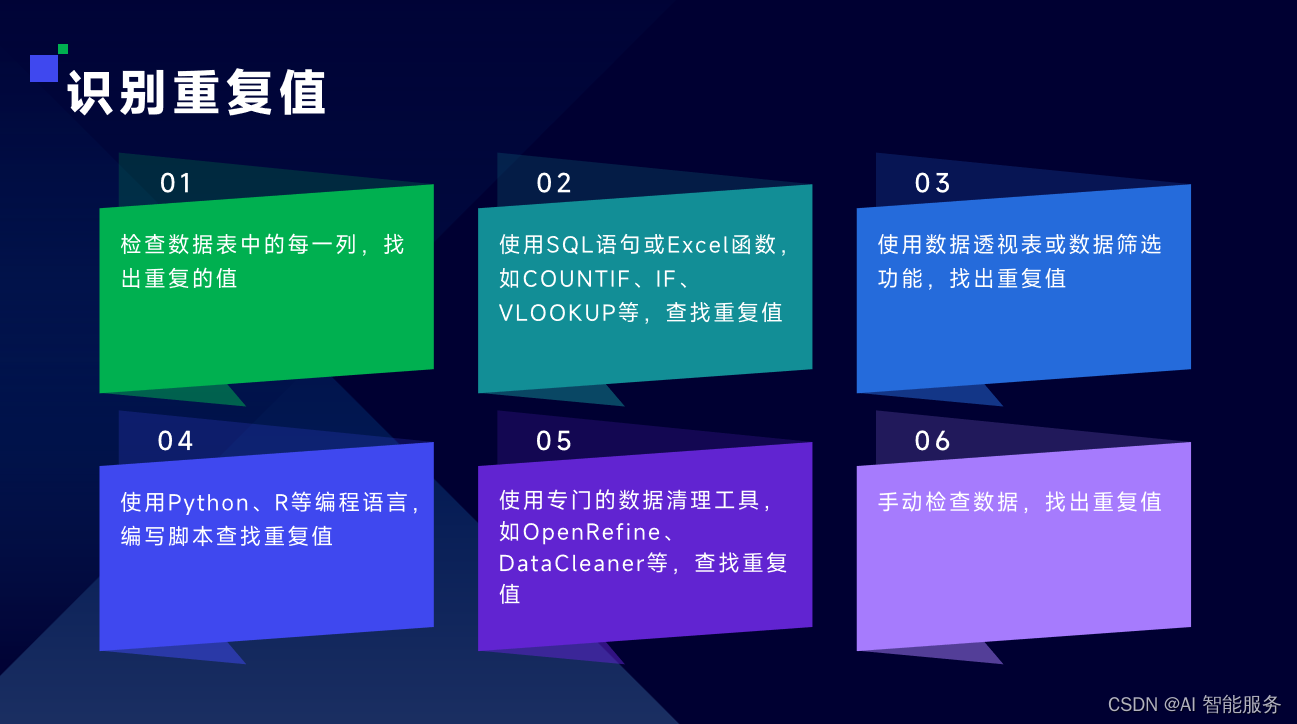
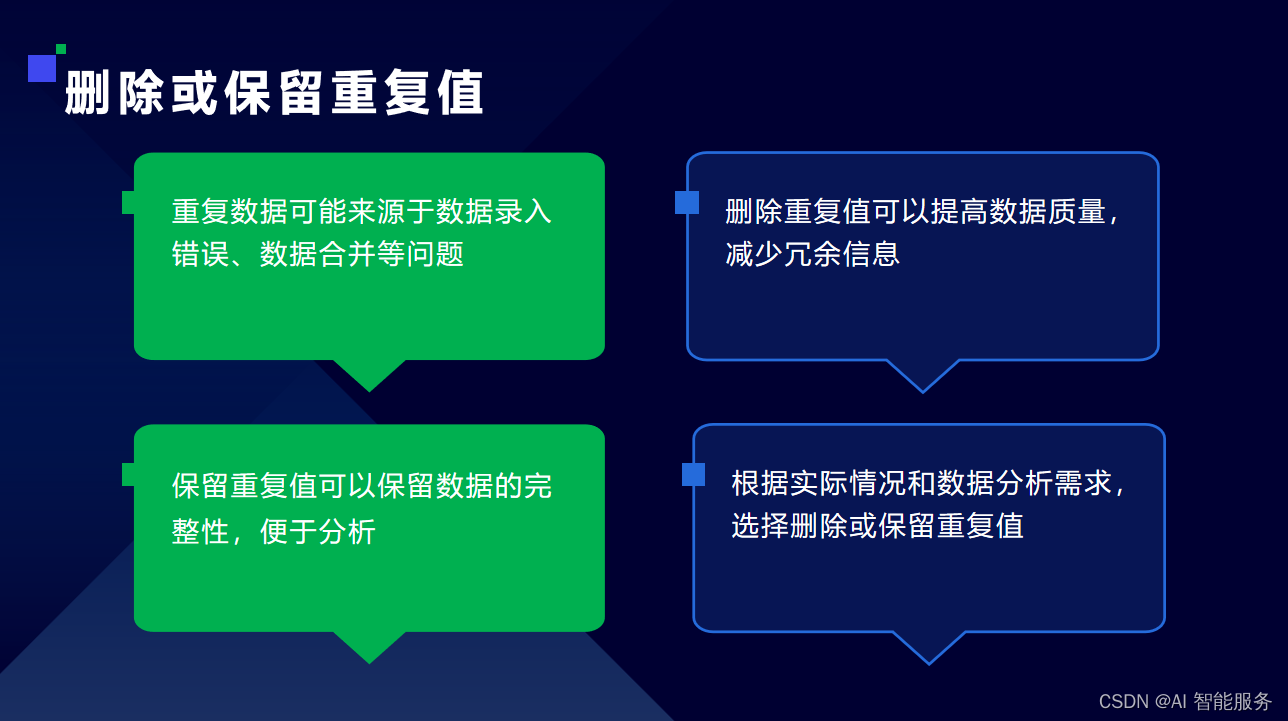
3.3噪声数据处理


4.数据异常处理的挑战
数据异常处理是数据分析中的重要环节,但同时也面临着一些挑战。以下是数据异常处理中面临的几个主要挑战:
- 异常值的识别:异常值是指数据中不符合预期或不符合常识的值。在异常值的识别中,需要考虑数据的分布、变化规律等因素,同时还需要对数据进行深入的分析和探索。如果异常值的识别方法不当,可能会影响数据分析的结果。
- 异常值对分析结果的影响:异常值对数据分析结果会产生一定的影响。如果异常值的处理方法不当,可能会使分析结果出现偏差或错误。因此,在处理异常值时,需要考虑其对分析结果的影响,并采取合适的处理方法。
- 数据质量的影响:数据质量是影响数据异常处理的重要因素之一。如果数据质量较差,可能会使数据异常的处理更加困难,同时也可能影响数据分析的结果。因此,在处理数据异常时,需要考虑数据质量的影响,并对数据进行必要的清洗和预处理。
- 数据量大的挑战:在大数据时代,数据量的大小是影响数据异常处理的重要因素之一。对于大规模的数据集,需要进行高效的异常检测和处理,同时也需要考虑计算成本和时间成本等因素。
为了解决这些挑战,需要不断探索和研究新的数据异常处理技术和方法。同时,也需要加强数据治理和数据质量管理的力度,提高数据处理和分析的效率和准确性。