可以提取图像文本的 5 大 Python 库
主要是了解并掌握文本定位和识别的OCR工具哦~
 光学字符识别是一个古老但依然具有挑战性的问题,涉及从非结构化数据中(包括图像和PDF文档)检测和识别文本。它在银行、电子商务和社交媒体内容管理等领域具有广泛的应用。
光学字符识别是一个古老但依然具有挑战性的问题,涉及从非结构化数据中(包括图像和PDF文档)检测和识别文本。它在银行、电子商务和社交媒体内容管理等领域具有广泛的应用。
但与数据科学中的每个主题一样,尝试学习如何解决OCR任务时存在大量的资源。这就是为什么我写下这篇教程,它可以帮助您入门。
在本文中,我将展示一些Python库,可以让您轻松从图像中提取文本,无需太多麻烦。这些库的说明后面附有一个实际示例。所使用的数据集均来自Kaggle。
目录:
pytesseract
EasyOCR
Keras-OCR
TrOCR
docTR
1. pytesseract
它是最流行的Python库之一,用于光学字符识别。它使用Google的Tesseract-OCR引擎从图像中提取文本。支持多种语言。
如果想知道是否支持您的语言,请查看这个链接:https://tesseract-ocr.github.io/tessdoc/Data-Files-in-different-versions.html。您只需要几行代码将图像转换为文本:
# installation
!sudo apt install tesseract-ocr
!pip install pytesseract
import pytesseract
from pytesseract import Output
from PIL import Image
import cv2
img_path1 = '00b5b88720f35a22.jpg'
text = pytesseract.image_to_string(img_path1,lang='eng')
print(text)输出:
 我们还可以尝试获取图像中每个检测到的项目的边界框坐标。
我们还可以尝试获取图像中每个检测到的项目的边界框坐标。
# boxes around character
print(pytesseract.image_to_boxes(img_path1))结果:
~ 532 48 880 50 0
...
A 158 220 171 232 0
F 160 220 187 232 0
I 178 220 192 232 0
L 193 220 203 232 0
M 204 220 220 232 0
B 228 220 239 232 0
Y 240 220 252 232 0
R 259 220 273 232 0
O 274 219 289 233 0
N 291 220 305 232 0
H 314 220 328 232 0
O 329 219 345 233 0
W 346 220 365 232 0
A 364 220 379 232 0
R 380 220 394 232 0
D 395 220 410 232 0
...正如您所注意到的,它估算了每个字符的边界框,而不是每个单词!如果我们想提取每个单词的框,而不是字符,那么应该使用image_to_data的另一种方法,而不是image_to_boxes:
# boxes around words
print(pytesseract.image_to_data(img_path1))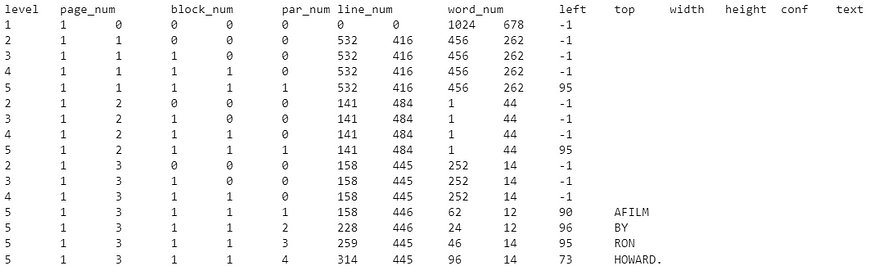
这是返回的结果,并不是很完美。例如,它将“AFILM”解释为一个单词。此外,它没有检测和识别输入图像中的所有单词。
2. EasyOCR
轮到另一个开源Python库:EasyOCR。与pytesseract类似,它支持80多种语言。您可以通过网络演示快速而轻松地尝试它,无需编写任何代码。它使用CRAFT算法来检测文本并使用CRNN作为识别模型。此外,这些模型是使用Pytorch实现的。
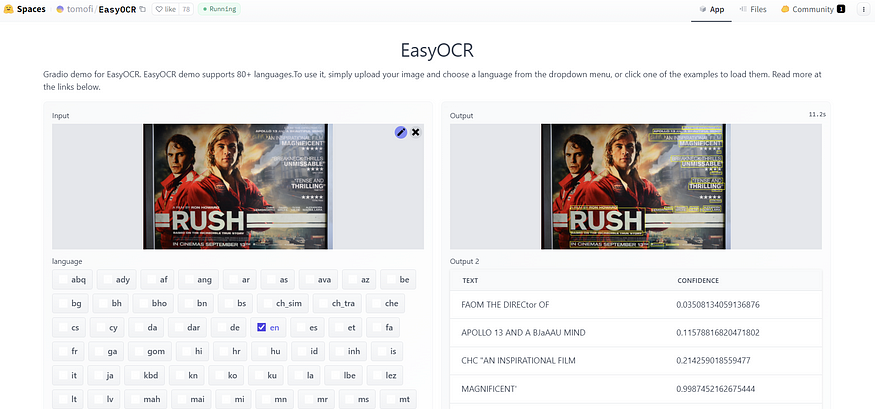
如果在Google Colab上工作,建议您设置GPU,这有助于加快此框架的速度。以下是详细代码:
# installation
!pip install easyocr
import easyocr
reader = easyocr.Reader(['en'])
extract_info = reader.readtext(img_path1)
for el in extract_info:
print(el)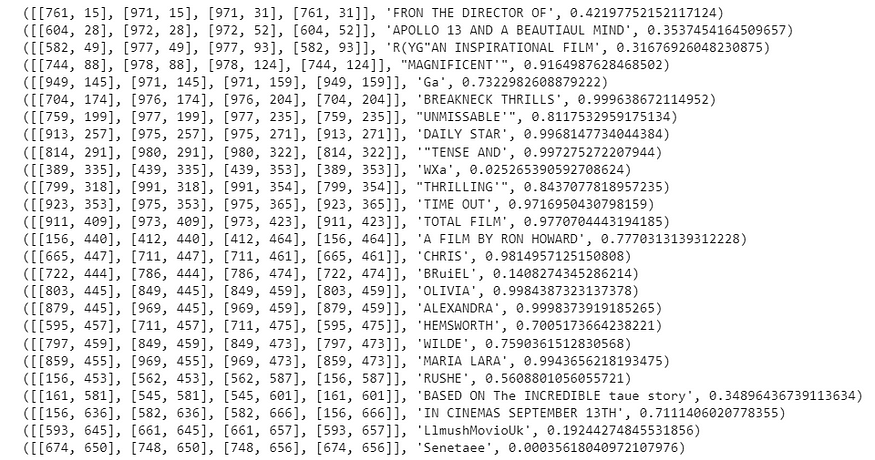
与pytesseract相比,结果要好得多。对于每个检测到的文本,我们还有边界框和置信度级别。
3. Keras-OCR
Keras-OCR是另一个专门用于光学字符识别的开源库。与EasyOCR一样,它使用CRAFT检测模型和CRNN识别模型来解决任务。与EasyOCR的不同之处在于,它使用Keras而不是Pytorch实现。Keras-OCR的唯一不足之处是它不支持非英语语言。
# installation
!pip install keras-ocr -q
import keras_ocr
pipeline = keras_ocr.pipeline.Pipeline()
extract_info = pipeline.recognize([img_path1])
print(extract_info[0][0])这是提取的第一个单词的输出:
('from',
array([[761., 16.],
[813., 16.],
[813., 30.],
[761., 30.]], dtype=float32))为了可视化所有结果,我们将输出转换为Pandas数据框:
diz_cols = {'word':[],'box':[]}
for el in extract_info[0]:
diz_cols['word'].append(el[0])
diz_cols['box'].append(el[1])
kerasocr_res = pd.DataFrame.from_dict(diz_cols)
kerasocr_res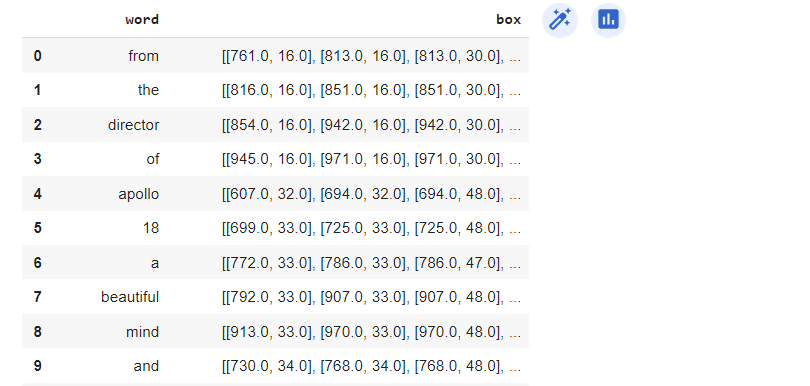
神奇的是,我们可以看到我们有更清晰和更精确的结果。
4. TrOCR
TrOCR是一种基于transformers的生成式图像模型,用于从图像中检测文本。它由编码器和解码器组成:TrOCR使用预训练的图像变换器作为编码器和预训练的文本变换器作为解码器。有关更多详细信息,请查看论文。Hugging Face平台上还有这个库的良好文档。首先,我们加载预训练模型:
# installation
!pip install transformers
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
model_version = "microsoft/trocr-base-printed"
processor = TrOCRProcessor.from_pretrained(model_version)
model = VisionEncoderDecoderModel.from_pretrained(model_version)在传递图像之前,我们需要调整其大小并进行规范化。一旦图像已经转换,我们可以使用.generate()方法提取文本。
image = Image.open(img_path1).convert("RGB")
pixel_values = processor(image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
extract_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print('output: ',extract_text)
# output: 2.50这与先前的库不同,它返回一个无意义的数字。为什么?TrOCR仅包含识别模型,而没有检测模型。要解决OCR任务,首先需要检测图像中的对象,然后提取输入中的文本。由于它只关注最后一步,它的性能不佳。要使其正常工作,最好使用边界框裁剪图像的特定部分,如下所示:
crp_image = image.crop((750, 3.4, 970, 33.94))
display(crp_image)
然后,我们尝试再次应用模型:
pixel_values = processor(crp_image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
extract_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(extract_text)
此操作可以重复应用于图像中包含的每个单词/短语。
5. docTR
最后,我们涵盖了用于从文档中检测和识别文本的最后一个Python包:docTR。它可以将文档解释为PDF或图像,然后将其传递给两阶段方法。在docTR中,文本检测模型(DBNet或LinkNet)后跟文本识别的CRNN模型。由于使用了这两个深度学习框架,这个库要求安装Pytorch和Tensorflow。
! pip install python-doctr
# for TensorFlow
! pip install "python-doctr[tf]"
# for PyTorch
! pip install "python-doctr[torch]"然后,我们导入使用docTR的相关库并加载模型,它是一个两步方法。实际上,我们需要指定文本检测和文本识别的DBNet和CRNN的模型,文本检测和文本识别的后端模型:
from doctr.io import DocumentFile
from doctr.models import ocr_predictor
model = ocr_predictor(det_arch = 'db_resnet50',
reco_arch = 'crnn_vgg16_bn',
pretrained = True
)我们最终读取文件,使用预训练模型,并将输出导出为嵌套字典:
# read file
img = DocumentFile.from_images(img_path1)
# use pre-trained model
result = model(img)
# export the result as a nested dict
extract_info = result.export()这是非常长的输出:
{'pages': [{'page_idx': 0, 'dimensions': (678, 1024), 'orientation': {'value': None, 'confidence': None},...为更好地可视化,最好使用双重循环,仅获取我们感兴趣的信息:
for obj1 in extract_info['pages'][0]["blocks"]:
for obj2 in obj1["lines"]:
for obj3 in obj2["words"]:
print("{}: {}".format(obj3["geometry"],obj3["value"]))
docTR是从图像或PDF中提取有价值信息的另一个好选择。
结论
五个工具各有优点和缺点。当选择这些软件包之一时,首先考虑您正在分析的数据的语言。如果考虑到非英语语言,EasyOCR可能是最适合的选择,因为它具有更广泛的语言覆盖和更好的性能。免责声明:该数据集根据知识共享署名4.0国际许可(CC by 4.0)许可。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除