【Java网络原理】 六
本文主要介绍了网络层的IP协议/NAT机制/IPv6的由来以及在数据链路层涉及到的以太网协议和DNS域名解析系统
一.网络层
1.IP协议

各个字段所表示的含义
>4位版本号
用来表示IP协议的版本,现在只有两个版本IPv4 ,IPv6
>4位首部长度
IP报头可变,带有选项
单位是4字节
>8位服务类型
(只有四种有效)
最小时延
最大吞吐量
最高可靠性
最小成本
四种形态互斥,只能切换到一种形态
>16位总长度
IP报头+载荷的长度
最大长度虽然只有64kb,但是IP协议自身支持拆包组包机制,如果需要携带一个比较长的数据,IP协议会自动把数据报拆成多个,接收方分用的时候,也会把多个数据报合并成一个数据报。
以下三个字段字段描述的是IP数据报拆包的过程
>16位标识
拆除的多个包,16位标识是相同的
>3位标志位
有一位表示是否允许拆包,有一位表示是否是最后一个包
>13位片偏移
拆包后,通过片偏移,区分包的先后顺序(前一个包片偏移更小,后一个更大)
描述了整个IP数据报拆包组包的过程,当IP数据报携带比较长的数据的时候,IP协议就会触发拆包
拆包:
把一个打包拆成多个小包,多个小的IP数据报都会带有IP报头,载荷是TCP数据报的几个部分

>8位生存时间TTL
单位是次。初始情况下会有个数值,每次经过一个路由器转发,TTL-1,减到0就会被丢弃
正常来说,TTL足以支持数据报到达网络的任意一个位置的,TTL位0,基本不可达
>8位协议
描述上层传输层使用哪种协议,分用的时候就知道把数据交给哪种传输层协议处理
>16位首部校验和
校验首部是否正确就行,载荷数据传输层校验过了
>32位源地址
>32位目的地址
IP地址
一般用点分十进制表示:把32位分为四个部分,每个部分8个字节,每个部分的范围是0-255。
比如,192.168.1.2
事实上,32位表示的数据量非常有限42亿9千万
既然是地址,原则上是不能重复的,然而现在全世界上的设备,早就超过这个数字了,这就涉及到了一个非常严重的问题:IP不够用了怎么办?
一般来说有三种方法:
1.动态分配DHCP
某个设备不会一直上网,需要上网,就分配,不需要就不分配。但是这种方法只能缓解!不能完全解决问题!
2.NAT机制(网络地址转换)
3.IPv6(增加IP的数量)
2.NAT机制
把ip地址分成两类
1.内网IP
不同的局域网内的设备,内网ip可以重复;同一个局域网内的设备,内网ip不能重复
比如我的电脑上的IP地址(他其实就是一个内网IP)

2.外网IP
外网ip不饿能重复
现在设备之间的通信有以下情况:
1.局域网内部的设备之间进行通信,是完全可以的,因为IP地址是互不相同的。
2.两个局域网通信:A局域网中的设备,希望和B局域网设备通信,这个时候怎么办,毕竟这两个ip可能相同
当前的规则是禁止这个情况的,要想通信就需要有一个带有外网ip的设备进行中转,局域网内的设备访问带有外网ip的设备
比如我们平常使用的电脑手机,都是在局域网内使用的,它们会有一个内网ip;还有一类设备,是服务器,服务器可以有外网ip,这个时候就涉及到NAT工作了
举个例子:

当这个数据报到达cctalk服务器之后,cctalk服务器并不知道这个数据是源自于我的电脑ip,而是只知道源自于路由器的ip
NAT机制下,意义在于,一个外网IP代表的不一定是一个设备了,而是很多设备。
对于NAT设备,会在触发NAT的时候,维护一个映射表,表示了替换前ip和替换后ip的映射
当然,上述只是简化版本。
NAT缺点
1.效率不高
2.非常繁琐
3.不方便直接访问局域网内的设备
但是NAT是一个纯软件实现的方案,成本很低,优势明显。
3.IPv6
从根据上解决IP地址不够用问题
IPv4是4个字节,32位表示IP地址
IPv6是16个字节,128位表示IP地址
IPv6的数量是:2^128=(2^32)^4 这是一个天文数字,足够为地球上的每粒沙子都分配一个地址
缺点是:
IPv6和IPv4不兼容,要想升级IPv6,就需要更换路由器设备,成本很高
相比之下,NAT方案,只需要路由器开发商开出新版本的软件,升级软件就可以支持,成本较低
因此IPv6的发展比NAT要慢很多。
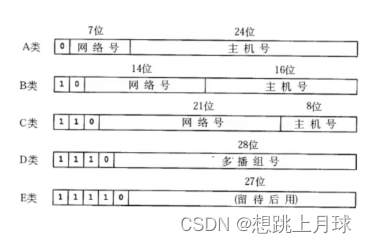
4.IP地址
IP地址分为两个部分:网络号和主机号
1.同一个局域网中设备网络号必须相同,主机号必须不同
2.两个相邻的局域网,网络号必须不同
那么一个Ip地址,哪个部分是网络号,哪个部分是主机号
通过子网掩码来识别:
子网掩码和IP地址一样,也是四个字节,32位的整数
左侧必须是连续的1,右侧必须是连续的0
1的范围描述了IP地址的对应哪些位是网络号
家用路由器子网掩码一般是255.255.255.0

子网掩码是现代的划分网络号的方案
以前还有一种方法
广播地址
如果IP地址中的主机号全部设为1,就成为了广播地址,用于给同一个链路上的相互连接的所有主机发送数据报;
比如:
子网掩码是255.255.255.0(最后八位是主机号)
如果ip地址是192.168.0.255(255代表全1)
往这个IP上发送数据报,这个数据就会被转发给局域网中的所有设备
(此处的广播,在传输层只能使用UDP,不是使用TCP,TCP无法针对广播地址进行三次握手建立连接)
举个常见的例子:
将手机上的内容投屏到电视上,前提是手机和电视在同一个局域网下(同一个wifi下),手机点击搜索设备,就能把所有同一个局域网下的设备都找出来,这个搜索的过程就可以基于广播IP实现
5.路由选择
路由选择的IP协议的另一个功能。
由于路由器,无法做到理解全貌,只能认识部分网络环境,在这个前提下,进行路由转发,走一步算一步,给出的路径不一定是最优解,只能说是较优解。
每一个路由器内部,有一个路由表
数据报到达路由器的时候,就需要查询路由表
1)如果查到了就按照这个方向转发
2)如果没查到,路由器就会给一个默认的方向,沿着默认的方向走
二.数据链路层
数据链路层的代表协议是以太网协议
以太其实是人们人们设想出来的一种物质,事实上并不存在。
另外以太网协议既涉及到数据链路层的内容,也涉及到物理层的内容
1.以太网协议

以太网协议报头有三个字段:
>目的地址
>源地址
这个地址叫做mac地址,长度是6字节
为什么有了IP地址,还要mac地址
这其实是因为这两个地址,都被各自独立设计出来了,因此都保留下来了
![]()
(一般使用十六进制数字,表示mac地址)
两个十六进制数字,就是一个字节
(字节之间一般是-或者:来分割)
mac地址比IPv4的地址大很多
mac地址都是网卡出厂的出后就固定了,可以保证每个设备的网卡都有独立的mac地址的
>类型
以太网数据帧的载荷有多种形式,通过这个字段来标识
载荷部分最大长度是1500(1kb多一点)
一个稍微大一点的传输层/应用层数据报都会在数据链路层被切分成多个
其实IP数据报分包和组包这个过程就是为了MTU(最大值)而做的
2.域名
上网就要访问服务器,知道服务器的ip地址,但是ip地址不方便人们记忆和传播,于是就出现了域名。
比如:www.baidu.com
三级域名.二级域名.一级域名
这个域名机器不认识,就需要一套系统,把域名解析成ip地址----这就促成了域名解析系统的诞生。
3.DNS域名解析系统
DNS的工作原理简单的来说就是:主机A想访问www.baidu.com,主机会先访问DNS服务器,让DNS服务器返回www.baidu.com的IP地址给主机,于是主机就可以访问这个IP地址
DNS服务器如何能够承受高并发的状况的呢?
开源节流
1.每个电脑上在进行域名解析的时候都会有缓存,这样不至于每一次访问域名都要真的访问DNS
2.全世界搭建了很多的DNS镜像服务器(和最初的DNS服务器同步数据)
此时访问镜像和访问那个DNS服务器效果一样
但是如果根域名服务器(在美国)还是可以控制镜像服务器,这也意味着美国掌握着世界上任何一个国家的网络使用权。

因此国内大力发展IPv6一部分原因也是为了摆脱DNS的限制(虽然IPv6也需要DNS,但是它是一套新的DNS,和之前的不相关)
从技术角度看,NDS服务器是否会挂?
会。
尤其是所在地区的DNS镜像服务器
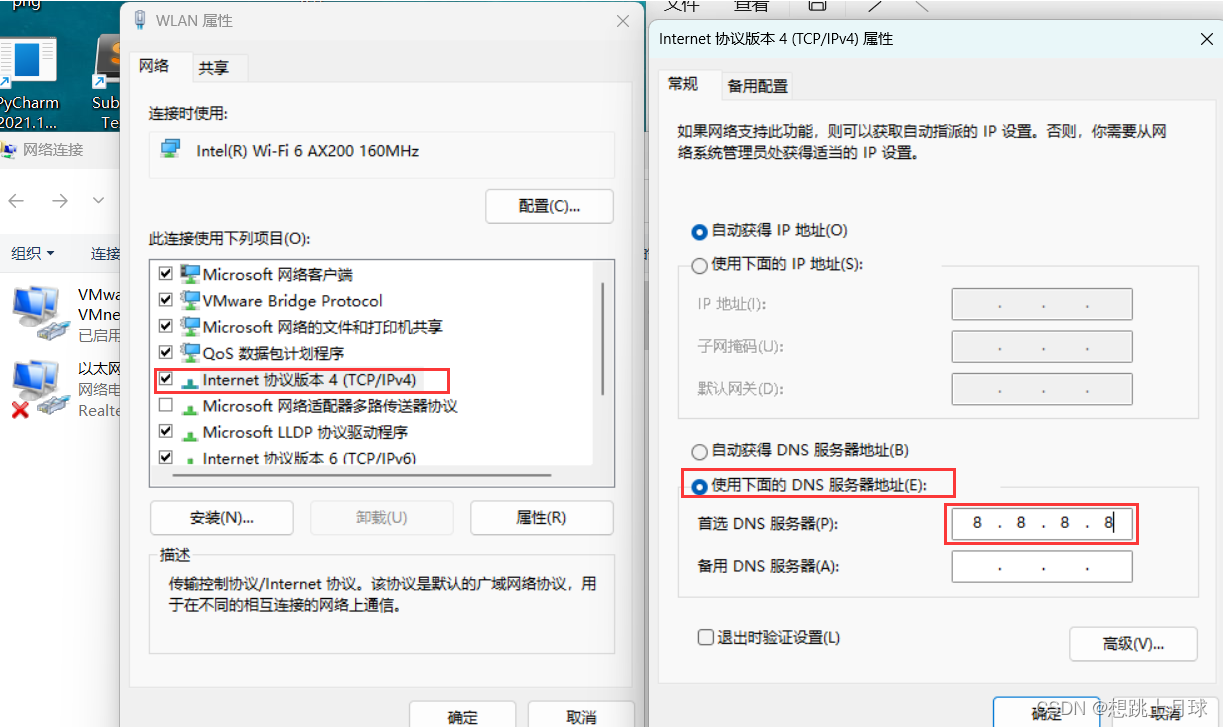
比如:遇到类似这样的情况:qq能用,浏览器不能用
这种时候就很有能是DNS镜像服务器挂了,好在如果挂了可以改镜像服务器
比如改成谷歌维护的DNS服务器8.8.8.8
在网络管理中修改: