数据结构───链表
花费一个周时间学完了链表(的一部分),简单总结一下。

链表的学习离不开画图,将其抽象成一种逻辑模型,可以减少思考时间,方便理解。
链表大致分为8种结构,自己学习并实现了两种结构,也是两种最经典的结构。一种是单向不带头非循环链表,另一种是双向带头循环链表。

无头单向非循环链表
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
以下就是该链表的实现:
1.链表的创建
定义一个结构体,包含存储的数据和指向后继节点的指针。
typedef int MyType;
//单向不带头非循环链表
typedef struct SingleLinklist{
MyType data;
struct SingleLinklist* next;
}SLNode;2.链表功能实现
由于是不带头链表,增删改功能需要修改链表的内容,所以需要传头节点的地址,功能函数用二级指针来接收,亦或者选择用返回值的方式。下面是采取传地址的方式。
先封装一个创建新节点的函数,方便以后多次使用:
SLNode* BuyNewNode(MyType x) {
SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));
newnode->data = x;
newnode->next = NULL;
return newnode;
}链表的尾插:
要实现单向链表的尾插,需要先判断是否头节点为空,然后遍历链表找到链表的最后一个结点。
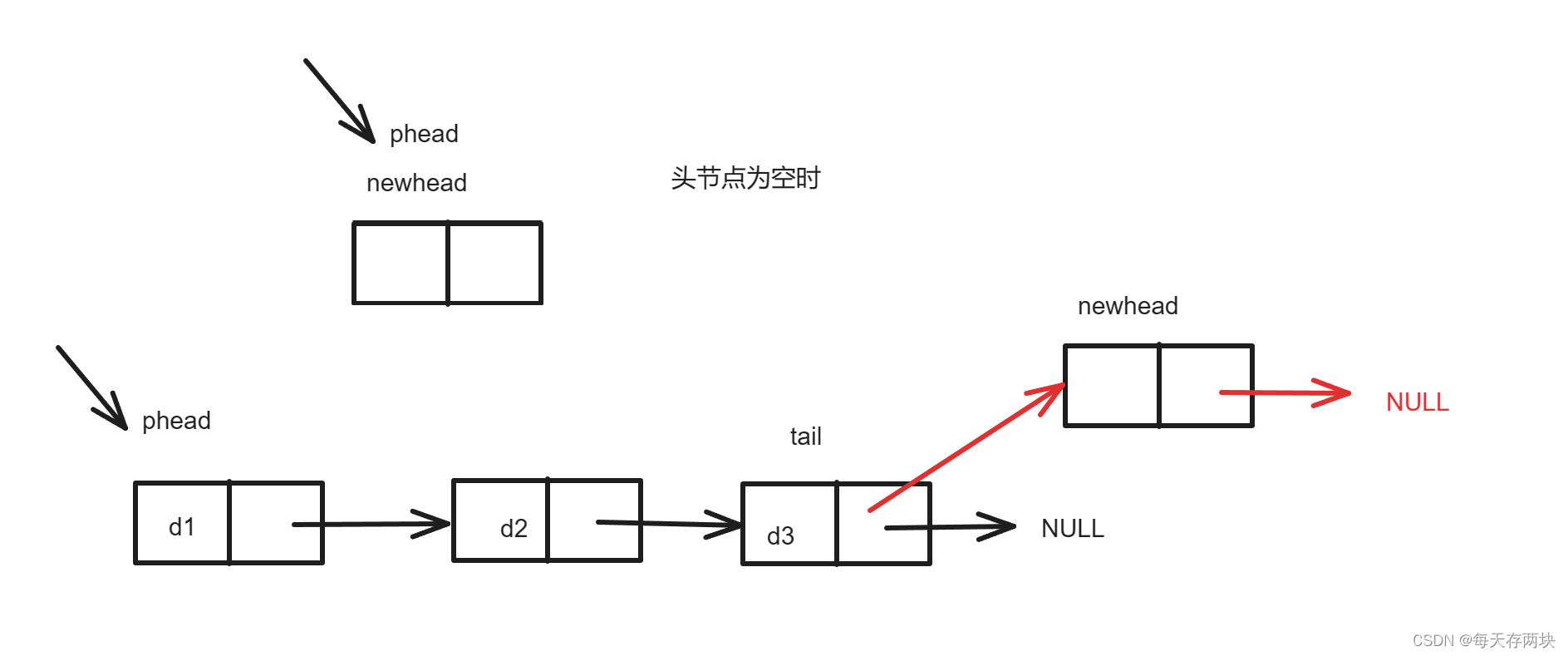
//尾插
void SLinkListPushBack(SLNode** pphead, MyType x) {
SLNode* newnode = BuyNewNode(x);
if (*pphead == NULL) {
*pphead = newnode;
}
else {
SLNode* tail = *pphead;
while (tail->next!=NULL) {
tail = tail->next;
}
tail->next = newnode;
}
}链表的头插:
链表的头插也大相径庭,也先判断头节点是否为空,头插完成后将新节点置成头。

//头插
void SLinkListPushPront(SLNode** pphead, MyType x) {
SLNode* newnode = BuyNewNode(x);
newnode->next = *pphead;
*pphead = newnode;
}链表的尾删:
单链表的麻烦之处可能就是,尾插之时,不好找上一个位置。这样就需要另外一个变量来保存上有个节点。

//尾删
void SLinkListPopBack(SLNode** pphead) {
//当链表为空,直接报错
assert(pphead);
//只有一个结点
if((*pphead)->next==NULL) {
free(*pphead);
*pphead = NULL;
}
//两个结点及以上
else {
SLNode* tail = *pphead;
while (tail->next->next) {
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}链表的头删:
头删就相对容易了,可以不用考虑一个还是多个情况,因为即使一个,它的下一个空节点为新的头节点也不受影响。

//头删
void SLinkListPopFront(SLNode** pphead) {
//链表为空
assert(*pphead);
SLNode* newphead = (*pphead)->next;
free(*pphead);
*pphead = newphead;
}链表的查找、插入:
查找的话遍历一遍链表就好啦。插入分为在前插入和在后插入。在前插入相对麻烦,因为单向链表的前一个节点需要再找一遍,所以需要重新定义一个变量,如果插入的位置是头节点之前的话,又就变成头插了(可以直接调用头插函数)。
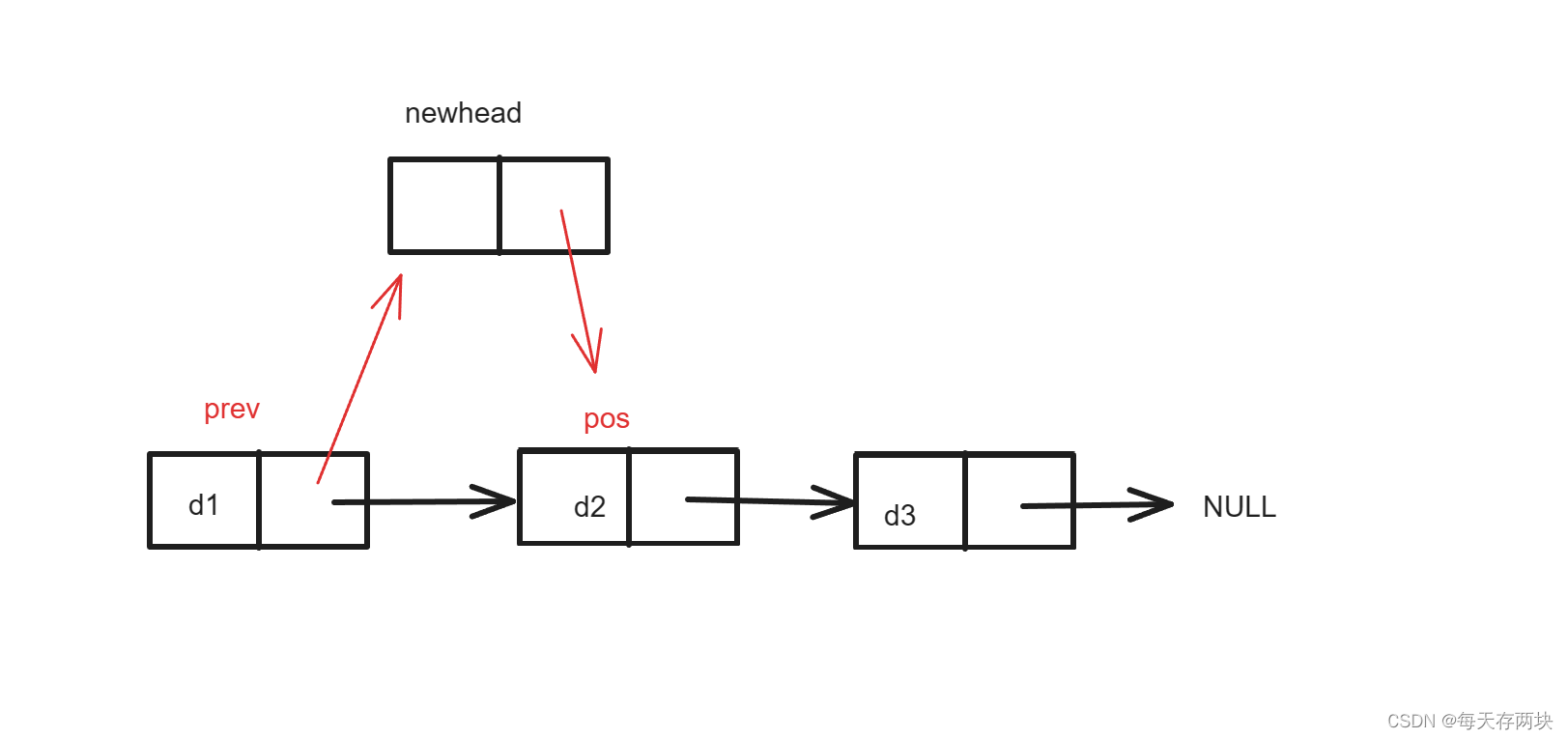
//查找
SLNode* SLinkListFind(SLNode* phead, MyType x) {
SLNode* cur = phead;
while (cur) {
if (cur->data == x) {
return cur;
}else{
cur = cur->next;
}
}
return NULL;
}
//在前插入
void SLinkListInterFormer(SLNode** pphead, SLNode*pos,MyType x) {
assert(pphead);
assert(pos);
SLNode* newnode = BuyNewNode(x);
if (*pphead ==pos) {
newnode->next = *pphead;
*pphead = newnode;
}
else {
SLNode* Prev = *pphead;
while (Prev->next != pos) {
Prev = Prev->next;
}
Prev->next = newnode;
newnode->next = pos;
}
}
//在后一个位置插入
void SLinkListInterAfter(SLNode* pos, MyType x) {
assert(pos);
SLNode* newnode = BuyNewNode(x);
newnode->next = pos->next;
pos->next = newnode;
}链表销毁:
由于传的的地址,直接一个函数就可以销毁了。
//摧毁链表
void SLinkListDestory(SLNode** pphead) {
assert(pphead);
SLNode* cur = *pphead;
while (cur) {
SLNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}双向带头循环链表
单向链表实现了,下面看一下双向带头循环链表,这种结构可以说是非常牛逼的一种链表结构。

带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了。
1.链表的创建
由于是双向,所以一个前继指针,一个后继指针。
typedef int MyType;
//双向循环带头链表
typedef struct DoubleLinklist {
MyType val;
struct DoubleLinklist* next;
struct DoubleLinklist* prev;
}DLNode;2.链表功能实现
上面的单向链表不带头所以不需要初始化,直接phead=NULL;就可以开始创建链表。而这种结构的好处就是不用传地值了,因为它修改的是结构体里的内容,不过要先创建一个哨兵位节点—站岗用的。
链表初始化:
//初始化链表
DLNode* DLNodeInit() {
DLNode* phead = (DLNode*)malloc(sizeof(DLNode));
//哨兵位 不存储有效数据
phead->next = phead;
phead->prev = phead;
return phead;
}malloc新节点:
//创建新节点
DLNode* CeateNewnode(MyType x) {
DLNode* newhead = (DLNode*)malloc(sizeof(DLNode));
newhead->val = x;
newhead->next = NULL;
newhead->prev = NULL;
return newhead;
}链表的尾插:
尾插只需要找到head->prev就行。没有节点时,head->prev就是它自己。
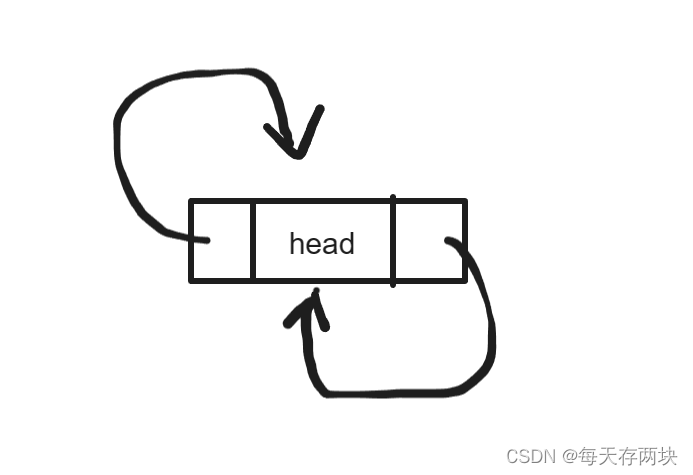 所以尾插就可以轻松实现。
所以尾插就可以轻松实现。

//尾插
void DLNodePushBack(DLNode* phead, MyType x) {
//因为只改变phead指向的结构体的东西,并不改变Phead,所以只传一级指针
assert(phead);
//malloc新节点
DLNode* newnode = CeateNewnode(x);
//pehad->prev==tail
DLNode* tail = phead->prev;
//连接新节点
tail->next = newnode;
newnode->prev = tail;
//首尾相连,形成循环
phead->prev = newnode;
newnode->next = phead;
}链表的头插:
链表的头插注意的是插入到head->next也就是head的下一个节点。因为链表遍历是从head的下一个节点开始。这也是我一开始打错的原因。
//打印链表
void DLNodePrint(DLNode* phead) {
assert(phead);
//phead里没有存有效数据,所以从phead的下一个开始
DLNode* cur = phead->next;
while (cur != phead) {
printf("%d->", cur->val);
cur = cur->next;
}
printf("\n");
}

//头插
void DLNodePushFront(DLNode* phead, MyType x) {
assert(phead);
DLNode* newnode = CeateNewnode(x);
DLNode* next = phead->next;
newnode->prev = phead;
phead->next = newnode;
next->prev = newnode;
newnode->next = next;
//可以调用插入函数,因为头插就是phead后结点插入
/*DLNodeInterBack(phead, x);*/
}链表的尾删:
尾节点不需要遍历就能找到,而且它的前一个节点也可以找到,这样就减少了消耗。不过需要注意的是,得先判断是不是没有节点,准确来说是不是只有一个哨兵位节点。

//尾删
void DLNodePopBack(DLNode* phead) {
assert(phead);
if(phead->next != phead) {
DLNode* tail = phead->prev;
tail->prev->next = phead;
phead->prev = tail->prev;
free(tail);
tail = NULL;
}
}链表的头删:
头删也大相径庭,跟尾删一样要先判断是不是只有一个头节点。
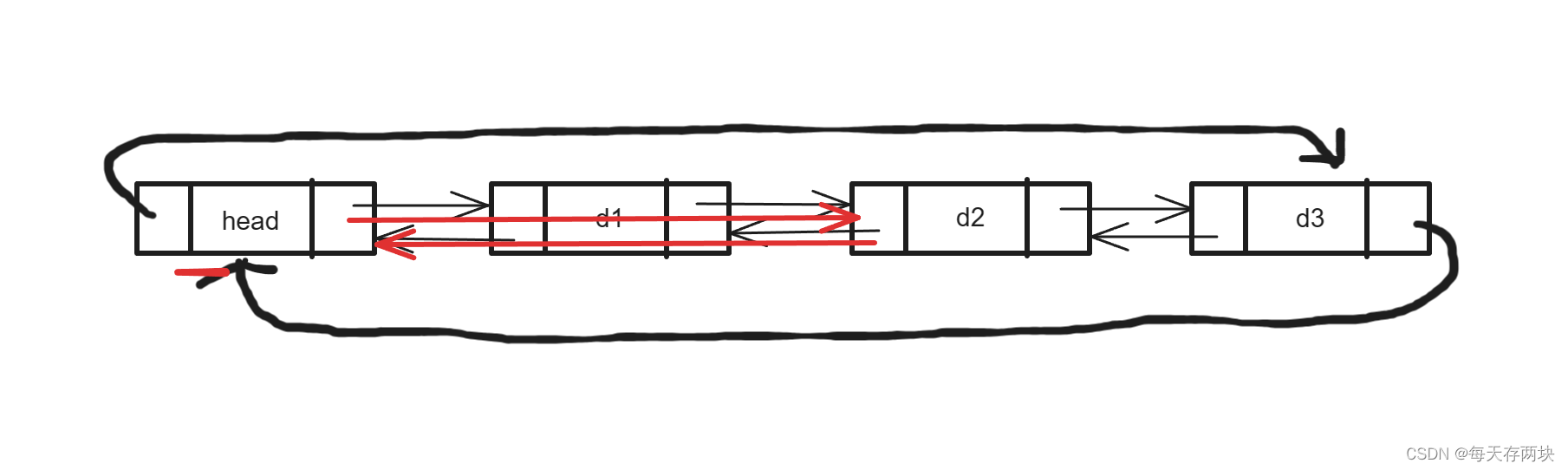
//头删
void DLNodePopFront(DLNode* phead) {
assert(phead);
if (phead->next != phead) {
DLNode* del = phead->next;
phead->next = del->next;
del->next->prev = phead;
free(del);
del = NULL;
}
}链表的查找、插入和删除:
为什么上个链表没有删除,因为忘记实现了。除了删除,只要查找到位置,修改,插入,删除其实都是很容易的事情。当然在这个完美的链表结构就更容易实现啦。

因为无论前插后插还是删除,直接就可以找前一个结点和后一个节点。
//查找
DLNode* DLNodeFind(DLNode* phead, MyType x) {
assert(phead);
DLNode* cur = phead->next;
while (cur != phead) {
if (cur->val == x) {
return cur;
}
cur = cur->next;
}
return NULL;
}
//结点前插入
void DLNodeInterFront(DLNode* pos, MyType x) {
assert(pos);
DLNode* newnode = CeateNewnode(x);
DLNode* former = pos->prev;
former->next = newnode;
newnode->prev = former;
newnode->next = pos;
pos->prev = newnode;
}
//结点后插入
void DLNodeInterBack(DLNode* pos, MyType x) {
assert(pos);
DLNode* newnode = CeateNewnode(x);
DLNode* latter = pos->next;
pos->next = newnode;
newnode->prev = pos;
newnode->next = latter;
latter->prev = newnode;
}
//删除节点
void DLNodeErase(DLNode* pos) {
assert(pos);
DLNode* former = pos->prev, * latter = pos->next;
former->next = latter;
latter->prev = former;
free(pos);
pos = NULL;
}链表销毁:
需要注意的是,这里传的是一级指针,所传指针需要在函数外置空。
//摧毁链表
void DLNodeDestroy(DLNode* phead) {
assert(phead);
DLNode* cur = phead->next;
while (cur!=phead) {
DLNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
phead = NULL;
}链表基础题
链表的实现完成了,学了知识就需要接下来不断巩固。
刷题就是最好的方式,下面是几道关于链表的简单题目。
203. 移除链表元素 - 力扣(LeetCode)
题解:可以看到,移除所给值的节点,直接遍历就好啦,不过需要注意的是是否为头节点,如果为头节点就需要将头指针转移,就是头删。单向链表删除节点,需要遍历出上一个节点,如果每次删除都要遍历一遍,不如只遍历一遍将节点保存一下,再继续往下走,删除时就只需要将保存的前继节点连接到后一个节点就行。也是双指针问题。
struct ListNode* removeElements(struct ListNode* head, int val){
if(head==NULL){
return NULL;
}
struct ListNode* cur=head;
struct ListNode* prev=NULL;
while(cur){
if(cur->val==val){
//头删
if(cur==head){
head=head->next;
free(cur);
cur=head;
}else{
prev->next=cur->next;
free(cur);
cur=prev->next;
}
}else{
prev=cur;
cur=cur->next;
}
}
return head;
}面试题 02.04. 分割链表 - 力扣(LeetCode)
这道题的思路是遍历一遍链表,将小于目标值的节点合成一个链表,大于目标值的节点合成一个链表,然后将两个链表尾首相连即可。需要注意的是如果连接后的链表的最后一个节点的后继指针不为空,需要置空,否则他依旧指向某个节点,这样一来就形成了死循环了。
还有种情况就是没有小于目标值的节点,这样直接返回大于目标值的节点就好啦。
struct ListNode* partition(struct ListNode* head, int x){
struct ListNode*cur=head;
struct ListNode*samllerHead=NULL;
struct ListNode*samallerTail=NULL;
struct ListNode*greaterHead=NULL;
struct ListNode*gearterTail=NULL;
while(cur){
if(cur->val<x){
if(samllerHead==NULL){
samllerHead=samallerTail=cur;
}else{
samallerTail->next=cur;
samallerTail=samallerTail->next;
}
}else{
if(greaterHead==NULL){
greaterHead=gearterTail=cur;
}else{
gearterTail->next=cur;
gearterTail=gearterTail->next;
}
}
cur=cur->next;
}
if(samallerTail){
samallerTail->next=greaterHead;
}else{
samallerTail=greaterHead;
}
if(gearterTail){
gearterTail->next=NULL;
}
if(samllerHead==NULL){
samllerHead=greaterHead;
}
return samllerHead;
}面试题 02.02. 返回倒数第 k 个节点 - 力扣(LeetCode)
这道题解法也是双指针,可以用到双指针中的快慢指针。快指针先走k步,然后再跟慢指针一起走,当快指针为空时,此时慢指针就是倒数第k个节点。
int kthToLast(struct ListNode* head, int k){
struct ListNode* fast=head,*slow=head;
//先让fast走k步
while(k--){
fast=fast->next;
}
//再一起走,当fast为NULL时,此时slow就是第k的位置
while(fast){
slow=slow->next;
fast=fast->next;
}
return slow->val;
}
个人总结
链表的操作虽然学会了,但放在题目还是不会,还是算法基础太薄弱了,已经准备买书买咖啡早起学算法了,希望终有一天我也能成为一个算法大佬。
