性能优化必读 | AntDB-M高性能设计之线程池协程模型
实际应用场景中,一个AntDB-M节点一般会处理几千个连接,平均每个CPU需处理几百个线程连接,上下文切换频繁;一个进程的线程数太多,会消耗较多的资源,使用Pstack工具检查问题也非常困难,Pstack耗时太久可能导致AntDB-M节点主备切换;对于一些WEB应用或者短连接的使用场景,连接数量能达到几十万级别。
为了提高并发处理性能,AntDB-M除了支持One-Thread-Per-Connection模型,还实现了线程池模型。
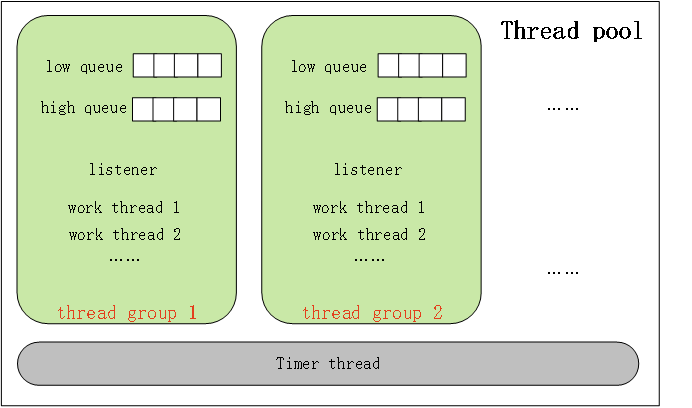
图1:AntDB-M线程池模型
AntDB-M 线程池模式最佳实践
AntDB-M线程池主要有以下四个特点:
1.平滑创建线程
线程池维护一个与CPU个数相等的Thread Group数组,每个Thread Group单独处理自己的连接, 新连接上来轮询地分配给所有Thread Group,Thread Group客户端发送的请求消息放到一个消息队列。Thread Group创建的工作线程都从这个消息队列中获取任务。
初始化时,Thread Group只有一个线程,可以负责收消息和处理任务,当任务处理不过来时,就会创建一个新的线程。Thread Pool有一个定时器负责周期性检查所有Thread Group是否繁忙,决定是否创建线程,或者唤醒休眠等待任务的线程,一次只会创建/唤醒一个线程。
2.平滑销毁线程
如果有大批业务连接退出,线程池也不会立即将线程销毁,而是等待一段时间。每个线程在等待一段时间之后,如果没有任务可处理,就会退出。在这个过程中,如果有新的消息,线程就会被唤醒。当然,Thread Group会保留最少一个线程来接收新的消息。
3.尽力提高业务处理效率
如果有线程需要去等待某些事件,比如IO、锁,可以认为这个线程不会占用CPU资源,应该开启一个新的线程利用CPU处理任务。Thread Group中的消息队列默认区分高低优先级,对于那些处于事务中的连接发来的消息,放置到高优先级队列。
工作线程处理任务时,优先从高优先级队列中获取消息,然后才处理低优先级队列中的消息。为了防止低优先级队列的消息饿死*[1],线程池的定时器还会定期检查如果有长时间未处理的低优先级消息,把它们移动到高优先级队列中。
*[1]备注:是指采取措施,以确保低优先级的消息在消息队列中也能得到处理,而不会被高优先级消息永远地排挤在后面,导致它们无法被及时处理。
4.系统资源开销限制
每个Thread Group都会有活跃线程上限,整个Thread Pool会有一个总的线程上限,以防止占用资源超出限制。过多的线程并没有优势,因为CPU资源总是有限的。
线程池的缺点:
1.处理任务不够及时
线程池会周期性地检查Thread Group是否过于繁忙,导致有些任务在一段时间内没有处理,然后决定创建新的线程。这段时间的任务,都会延迟一个检查周期时间。
2.没有均衡处理
如果有些Thread Group比较繁忙,有些比较空闲,Thread Group并不会做出调整。
3.不能充分利用CPU资源
虽然线程在等待IO或者临界资源时,会创建新的线程来弥补线程等待时CPU的浪费,但是很多等待事件线程池是无法感知到的,线程池的等待感知完全依赖于代码回调。
为了应对以上问题,AntDB-M同时引入了协程模式。协程模式相对于线程池模式来说,在上下文切换时,不需要内核参与,并且可以由应用层代码自己控制切换的时机。
协程运行时,依托于线程环境,一个线程在一个时刻运行一个协程,可以管理多个协程。从运行和调度的角度考虑,协程对于线程,相当于线程与内核的关系。
-
在协程运行时,线程将运行环境切换为协程,协程拥有CPU。
-
当协程运行完成或者主动让出CPU,可以切换到其它协程或者原来的线程环境。
但是线程不能强制切换协程,即没有抢占式调度。这样就不会有多余的上下文切换。
1+1>2 AntDB-M 协程模式
为了同时具备线程池和协程的优点,AntDB-M在线程池基础上实现了协程模型。连接与消息收发,以及线程的创建与销毁,都保持线程池的原有逻辑。对于业务处理,改由协程环境运行。
当一个消息处理完成,或者需要等待时(例如等待行锁或者表锁时),协程会主动让出CPU。当本线程的工作队列为空时,可以去其它线程的工作队列取任务(steal_task)。
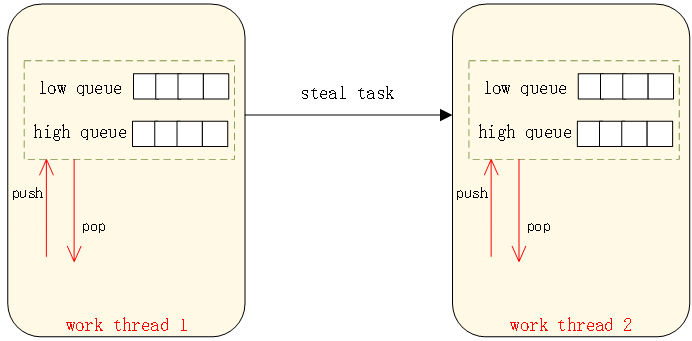
图2:AntDB-M协程模型
协程上下文创建与释放:
协程上下文使用boost::coroutine接口,make_fcontext创建一个上下文,jump_fcontext执行上下文接口。下面简称boost::coroutine为fcontext。包装fcontext的对象(context_t)需要包含一些基本信息,比如栈地址,为了减少内存分配次数,直接把context_t内存与栈内存放在一起。
协程上下文的切换主要有这几种场景:
1.新创建的协程上下文,处理请求,切入;
2.从其它工作线程的队列中获取任务进行处理,切入;
3.请求处理完成,切出到调用线程;
4.处理消息逻辑过程中,需要等待,比如行锁、表锁、临界资源等,需要切出;条件满足(比如其它线程释放行锁)或者等待超时,切入继续处理。
协程模型优势
AntDB-M采用M:N 的协程模型,内置steal_task调度模型来避免长尾效应。协程(用户态线程)切换相比Linux原生内核线程切换,性能提升一个数量级左右;同时steal_task可以实现CPU处理任务时每个核的负载均衡,有利于充分利用CPU资源。
因此,协程模型使得AntDB-M在模型设计上,天然具备高性能、低延迟的特性,以满足复杂的业务应用场景。
关于AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近15年,并在通信、金融、交通、能源、物联网等行业成功商用落地。