每日学术速递4.11
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.InstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning

标题:InstantBooth:无需测试时间微调的个性化文本到图像生成
作者:Jing Shi, Wei Xiong, Zhe Lin, Hyun Joon Jung
文章链接:https://arxiv.org/abs/2304.03411
项目代码:https://jshi31.github.io/InstantBooth/
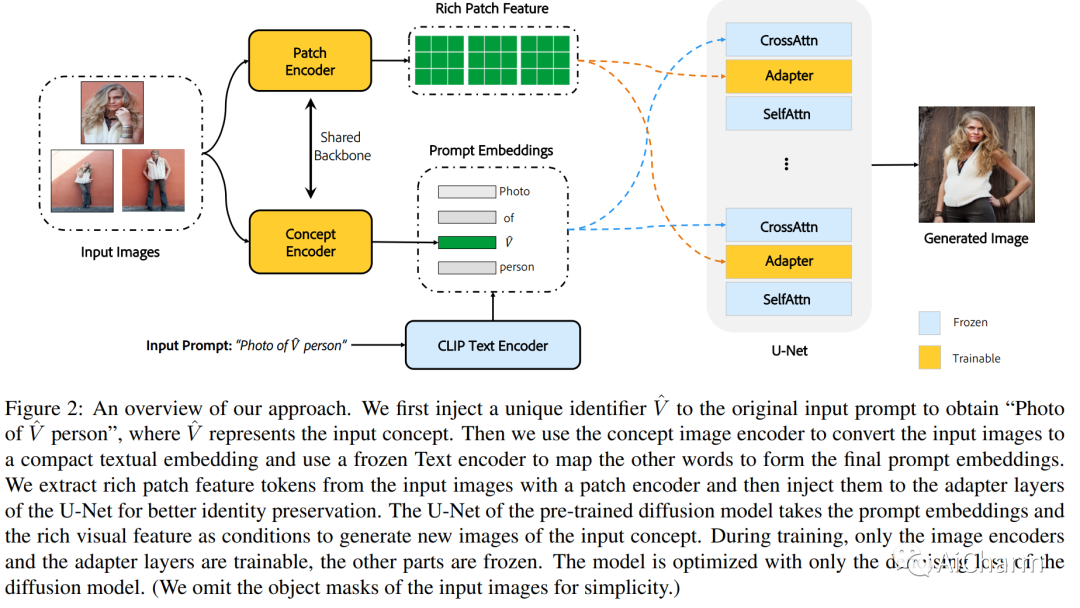
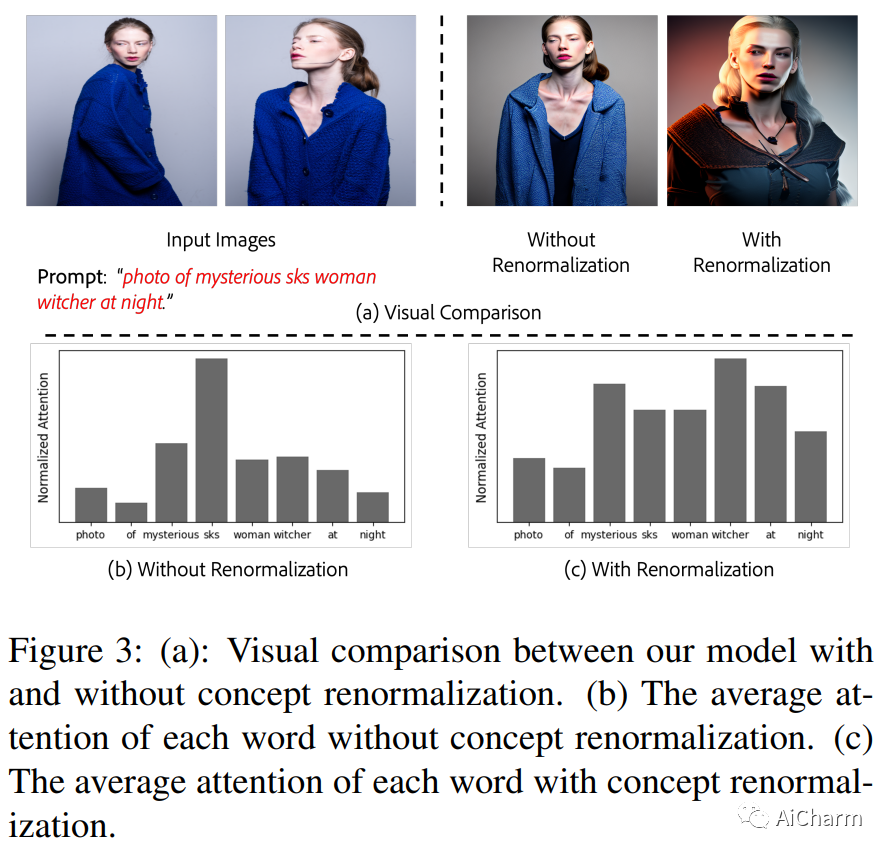
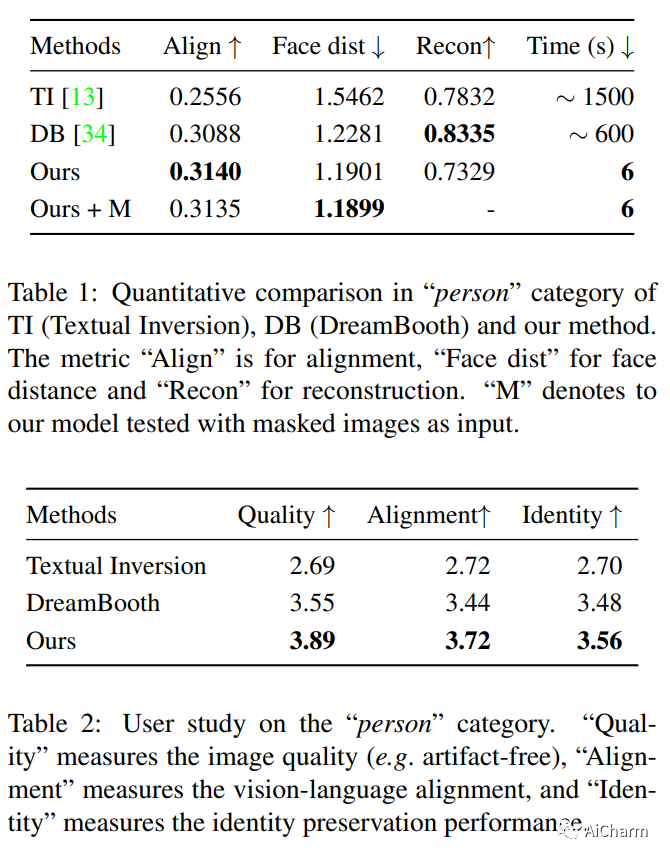
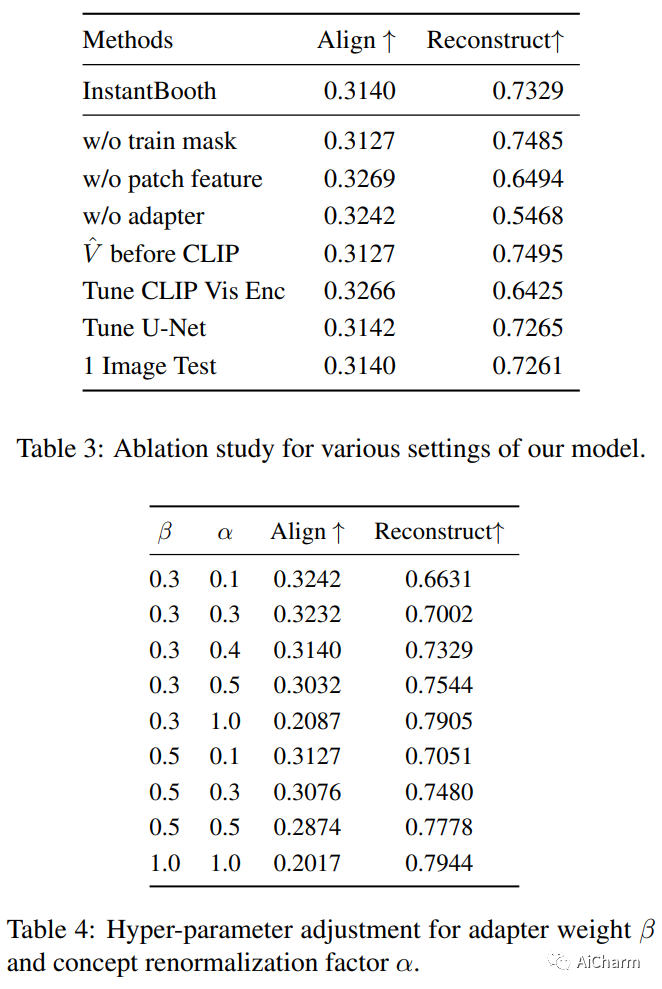
摘要:
个性化图像生成的最新进展允许预训练的文本到图像模型从一组图像中学习新概念。然而,现有的个性化方法通常需要对每个概念进行大量的测试时间微调,这既耗时又难以扩展。我们提出了 InstantBooth,这是一种基于预训练的文本到图像模型的新颖方法,无需任何测试时间微调即可实现即时文本引导图像个性化。我们通过几个主要组件来实现这一点。首先,我们通过使用可学习的图像编码器将输入图像转换为文本标记来学习输入图像的一般概念。其次,为了保持身份的精细细节,我们通过向预训练模型引入一些适配器层来学习丰富的视觉特征表示。我们只在文本图像对上训练我们的组件,而不使用相同概念的成对图像。与 DreamBooth 和 Textual-Inversion 等基于测试时间微调的方法相比,我们的模型可以在语言-图像对齐、图像保真度和身份保存等不可见概念上产生具有竞争力的结果,同时速度提高 100 倍。
2.Lift3D: Synthesize 3D Training Data by Lifting 2D GAN to 3D Generative Radiance Field

标题:Lift3D:通过将 2D GAN 提升到 3D 生成辐射场来合成 3D 训练数据
作者:Leheng Li, Qing Lian, Luozhou Wang, Ningning Ma, Ying-Cong Chen
文章链接:https://arxiv.org/abs/2304.03526
项目代码:https://len-li.github.io/lift3d-web


摘要:
这项工作探索了使用 3D 生成模型来合成 3D 视觉任务的训练数据。生成模型的关键要求是生成的数据应逼真以匹配真实场景,并且相应的 3D 属性应与给定的采样标签对齐。然而,我们发现最近基于 NeRF 的 3D GAN 由于其设计的生成管道和缺乏明确的 3D 监督而很难满足上述要求。在这项工作中,我们提出了 Lift3D,这是一种倒置的 2D 到 3D 生成框架,以实现数据生成目标。与之前的方法相比,Lift3D 有几个优点:(1) 与之前的 3D GAN 不同,训练后输出分辨率是固定的,Lift3D 可以泛化到任何具有更高分辨率和逼真输出的相机固有特性。 (2) 通过将分离良好的 2D GAN 提升到 3D 对象 NeRF,Lift3D 提供生成对象的显式 3D 信息,从而为下游任务提供准确的 3D 注释。我们通过扩充自动驾驶数据集来评估我们框架的有效性。实验结果表明,我们的数据生成框架可以有效提高 3D 对象检测器的性能。
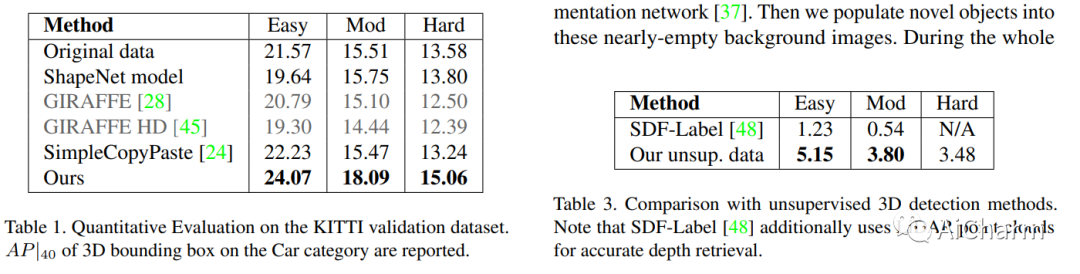
3.FineRecon: Depth-aware Feed-forward Network for Detailed 3D Reconstruction

标题:FineRecon:用于详细 3D 重建的深度感知前馈网络
作者:Noah Stier, Anurag Ranjan, Alex Colburn, Yajie Yan, Liang Yang, Fangchang Ma, Baptiste Angles
文章链接:https://arxiv.org/abs/2304.01480


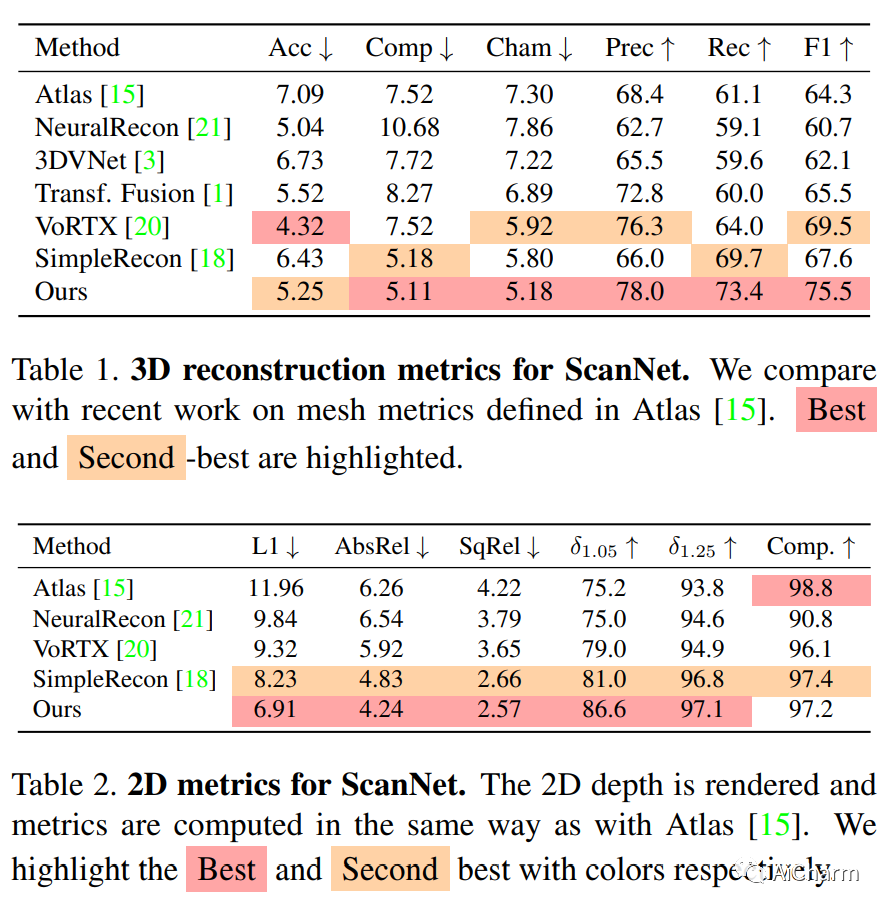
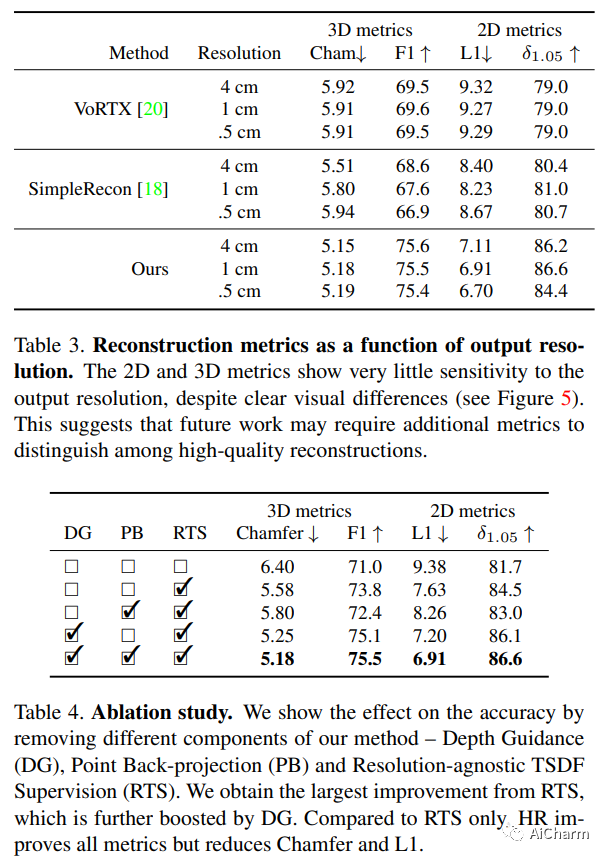
摘要:
最近关于从姿势图像进行 3D 重建的工作表明,使用深度神经网络直接推断场景级 3D 几何结构而无需迭代优化是可行的,显示出非凡的前景和高效率。然而,通常表示为 3D 截断符号距离函数 (TSDF) 的重建几何结构通常很粗糙,没有精细的几何细节。为了解决这个问题,我们提出了三种有效的解决方案来提高基于推理的 3D 重建的保真度。我们首先提出了一种与分辨率无关的 TSDF 监督策略,以便在训练期间为网络提供更准确的学习信号,避免之前工作中出现的 TSDF 插值的缺陷。然后,我们引入了一种使用多视图深度估计的深度引导策略,以增强场景表示并恢复更准确的表面。最后,我们为网络的最后一层开发了一种新颖的架构,除了粗糙的体素特征之外,还对高分辨率图像特征的输出 TSDF 预测进行了调节,从而能够更清晰地重建精细细节。我们的方法产生平滑且高度准确的重建,显示出跨多个深度和 3D 重建指标的显着改进。
更多Ai资讯:公主号AiCharm