037、目标检测-算法速览
之——常用算法速览
杂谈
快速过一下目标检测的各类算法。
正文
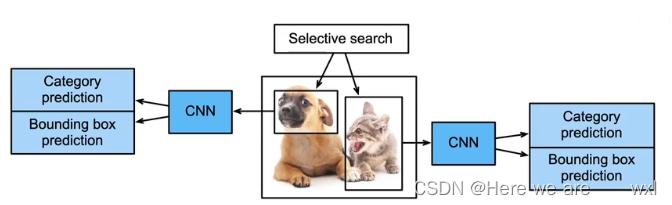
1.区域卷积神经网络 - R-CNN
region_based CNN,奠基性的工作。

选择锚框是一个较为复杂的算法,来自于神经网络还没发展的时候;启发式算法选择出锚框后,每一个锚框当做一个图片,然后用预训练好的CNN抽取特征;然后训练SVM用来分类,训练一个回归模型来预测边缘框,具体是:
将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别;
将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
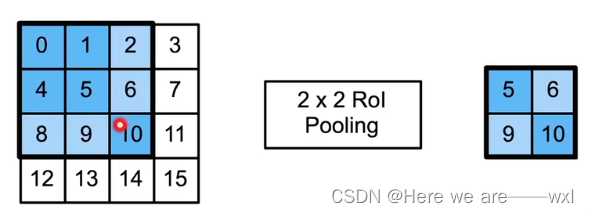
然而锚框的选择大小与比例是不一定的,这种情况下如何生成规则的训练batch呢,于是提出了RoI(region of interest),兴趣区域池化:

这个方法不会严格均匀地切割,而是会尽量按比例切割满足最后输出,看对应颜色:
Fast RCNN:
对于RCNN的加强,主要的改进是直接对整张图片抽特征而不是对锚框抽特征:
R-CNN的主要性能瓶颈在于,对每个提议区域,卷积神经网络的前向传播是独立的,而没有共享计算。 由于这些区域通常有重叠,独立的特征抽取会导致重复的计算。 Fast R-CNN 对R-CNN的主要改进之一,是仅在整张图象上执行卷积神经网络的前向传播。
搜到锚框之后再映射到CNN之后的feature map上:
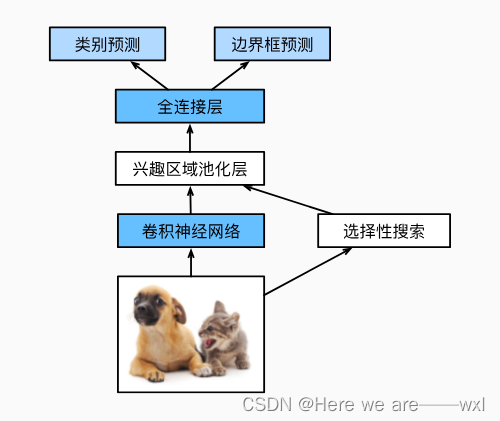
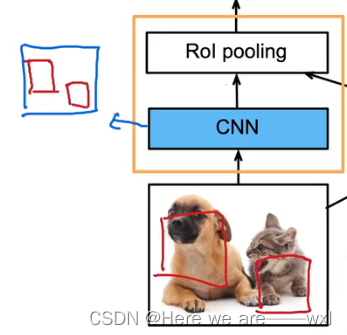
再把特征图上的ROI展平投入到全连接层进行预测。
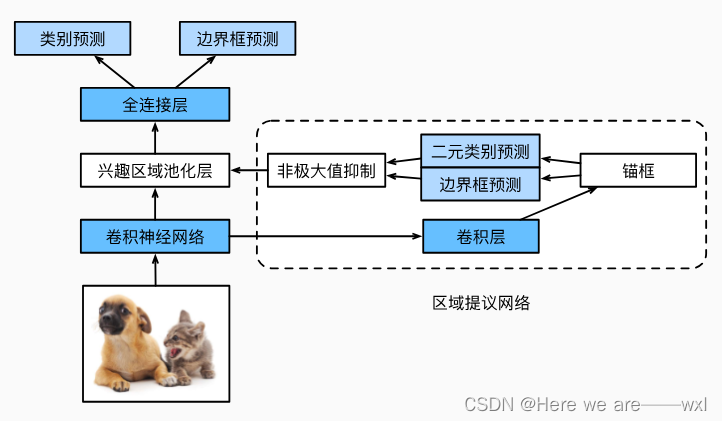
Faster R-CNN:
更进一步的改进是:
为了较精确地检测目标结果,Fast R-CNN模型通常需要在选择性搜索中生成大量的提议区域。 Faster R-CNN 提出将选择性搜索替换为区域提议网络(region proposal network),从而减少提议区域的生成数量,并保证目标检测的精度。
二分类预测锚框合理与不合理:
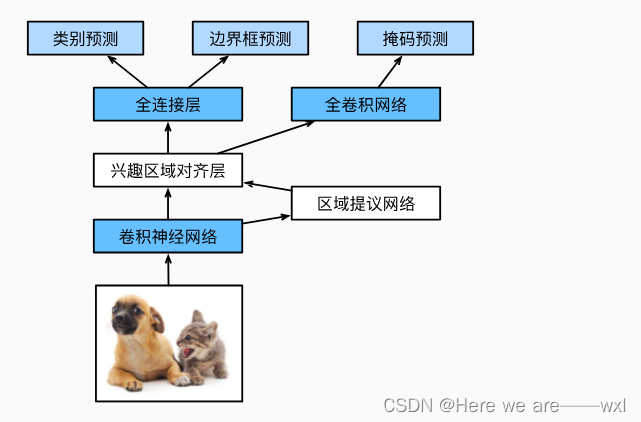
Mask R-CNN:
如果有像素级别的标号就用FCN来处理,提升原有的性能;roi pooling改为了roi align以避免像素级的误差:
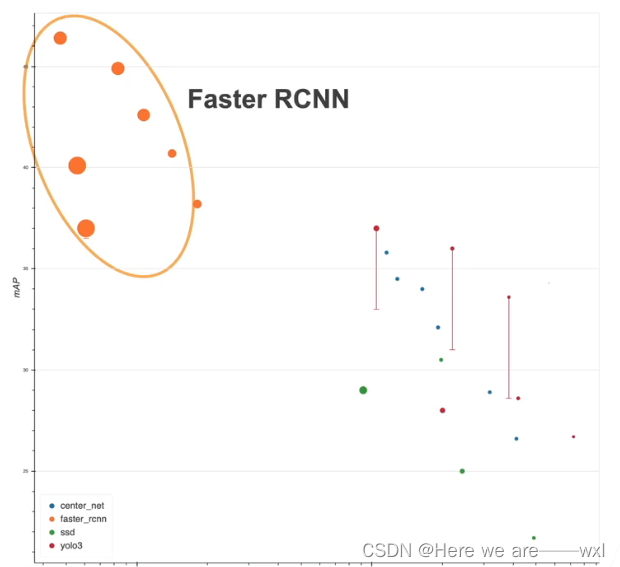
比较贵,实用性不高:

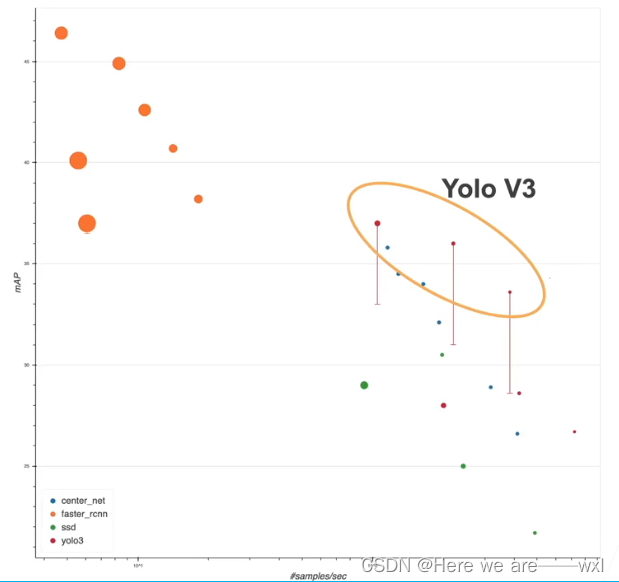
2.单发多框检测SSD,single shot detection
单发步枪,只跑一遍,不需要两个网络。
生成锚框的办法:

然后的操作:

多个分辨率下去锚框然后用算法预测类别和边界框,参考上面RCNN的预测方法。

性能,更快但没那么准:
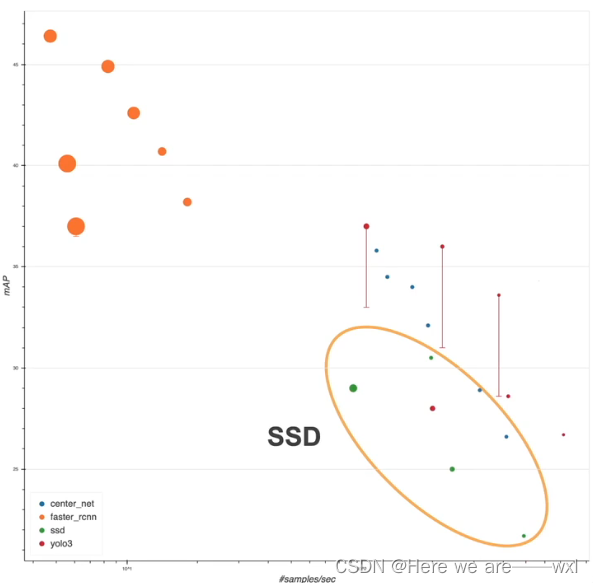
主要原因应该是没有什么改进?

3.yolo
you only live once:

you only look once:

每个锚框预测了多个边缘框,因为这样均匀分割的锚框可能会同时挨到多个真实边缘框。
后续通过细节改进进行提升,比如引入数据集真实框的先验知识之类的。