【【萌新的SOC学习之 VDMA 彩条显示实验之一】】
萌新的SOC学习之 VDMA 彩条显示实验之一
实验任务 :
本章的实验任务是 PS写彩条数据至 DDR3 内存中 然后通过 VDMA IP核 将彩条数据显示在 RGB LCD 液晶屏上
下面是本次实验的系统框图
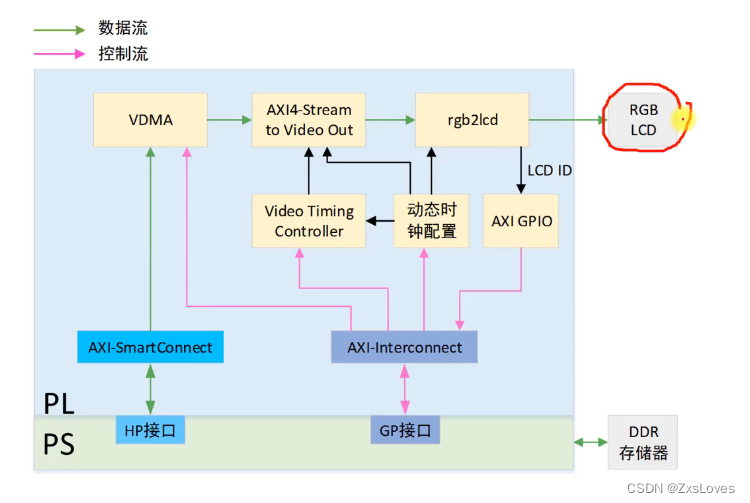
VDMA 通过 HP接口 与 PS端的 DDR 存储器 进行交互
因为 VDMA 出来的是 stream流 的 数据 我们现在需要的是把 这个 stream流的数据 通过这个 AXI4-Stream to Video Out 模块
变成 RGB 所能接收的 格式
因为 LCD 有很多的 型号啊 分辨率 之类的
我们可以通过 AXI GPIO 这个接口 接收 LCD的ID 以便 为了后续的设计做处理
下面的 Video Timing Controller VTC 是用来给我们的 RGB 提供一个时序信息
还有一个 动态时钟配置 就是为了给不同屏幕 提供不同的同步时钟
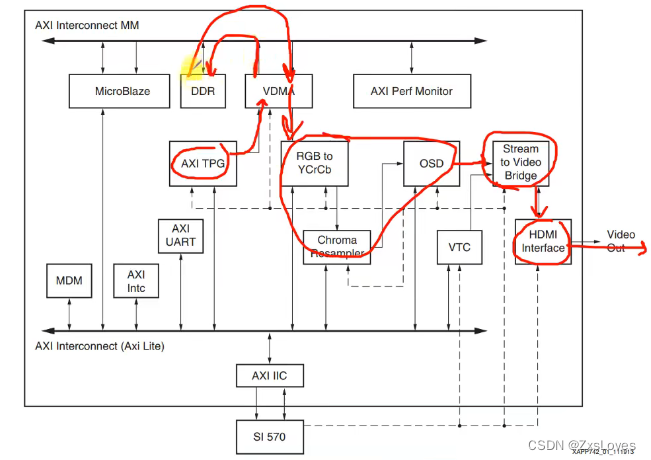
为什么在这里 它要先把 VDMA的数据传递到 DDR 再传回 VDMA呢
目的是 为了 解决 视频源 和 视频不匹配的问题
我们目前 可以 先简化这样的流程设计

因为 我们目前所处理的是 固定的型号的屏幕 那么我们可以 删除 AXI GPIO 接口
动态时钟配置 删除 改为 使用 PLL 锁相环 提供 固定时钟的 频率
这个 rgb2lcd 的 IP 只是为了 把 LCD 信号 封装 我们在前期的设计中 也可以暂时将它 删除 取消
还有对于 VTC模块 PS端本来会针对 不同的屏幕 输出 不同的时序 但是 目前来说 我们只针对使用 一个时序 所以可以把PS端 连接输入到 VTC 的 线删除 让它 输出固定频率 不需要调配了
下面是调配完成的 系统框图

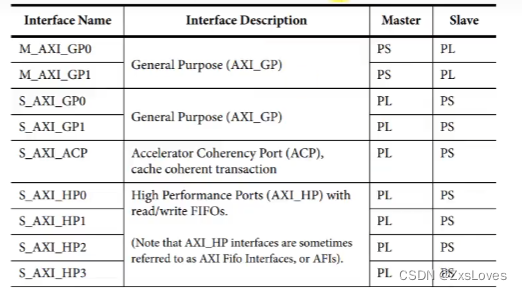
在 zynq中 GP接口 PS 作为 主机 HP接口 PS作为从机
HP 和 GP接口的区别
HP接口 指的是
High-Performance Ports
如果涉及到 大量数据 高带宽的性能传输 用HP
GP 接口指的是
General-Purpose Ports
GP 主要会用到一些中低速的传输
对于zynq HP 是 PL端指向 PS端的
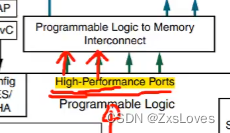
而对于 GP接口 PS PL 都可以作为主机和从机

这是我们从图上直观的感知出来的 现在我们观察 用户手册发现HP和 GP 的 区别
HP接口 为PS端的DDR和 OCM 提供一个高带宽的数据路径
每一个HP接口都包含了 FIFO 缓存 提供了 读写的传输
我们在设置的时候 会发现 HP接口是 slave
但是 我们在文档里 可以发现 HP接口 还有显示 master 的 其实这是看我们和什么进行比较 如果我们HP与 AXI interconnect 进行比较时 这就是 master接口
GP接口总线的数据位宽是32位
而HP接口总线的数据位宽 可以是32位 也可以是64位
GP接口 没有FIFO 作缓冲
VDMA 提供了一种高带宽的存储访问 在 存储器与 目标外设之间
AXI目标外设是 AXI stream video 类型的目标外设
AXI Stream Video 协议

tuser—作用 start of Frame 表示一帧的开始
tlast ----作用 用来指示 一行的结尾
tkeep 和 tstrb 如果我们 用到了这两个信号 我们就把它赋值为1 就可以了
tuser信号 可能是多个比特的信号 但是只有 bit 0 才代表了 start of Frame
如何用 vaild 和 ready 信号 来传递 SOF信息
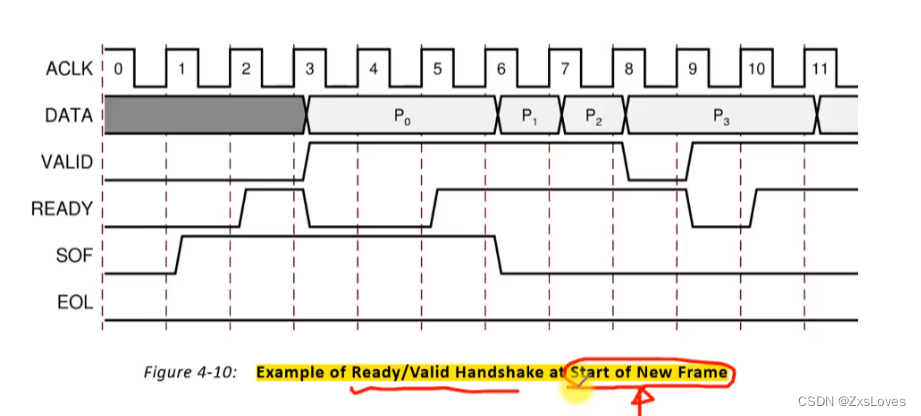
为什么要有 EOL信号 是用来表示我们信号的时序
EOL 代表着 一行的结束 它是在 AXI4-Stream 的 TLAST信号上 的
我们把 TLAST置为高 就相当于 代表着 一行的 结束
VDMA相对于 DMA 不仅接口类型不同 它还会 提供 帧缓存
帧缓存 就是在 存储器内部开辟一个视频空间 用来存储 输入的视频数据 或者是要输出的 视频图像
帧缓存的存在 是为了用来处理 帧速率的 改变 还有图像维度的 改变
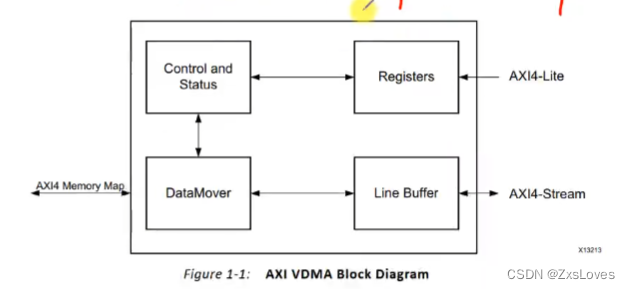
VDMA 模块示意图
VDMA 左边 接到了 DDR上 它是一种 存储映射接口
右边接到了 AXI Stream 的 VDMA 接口
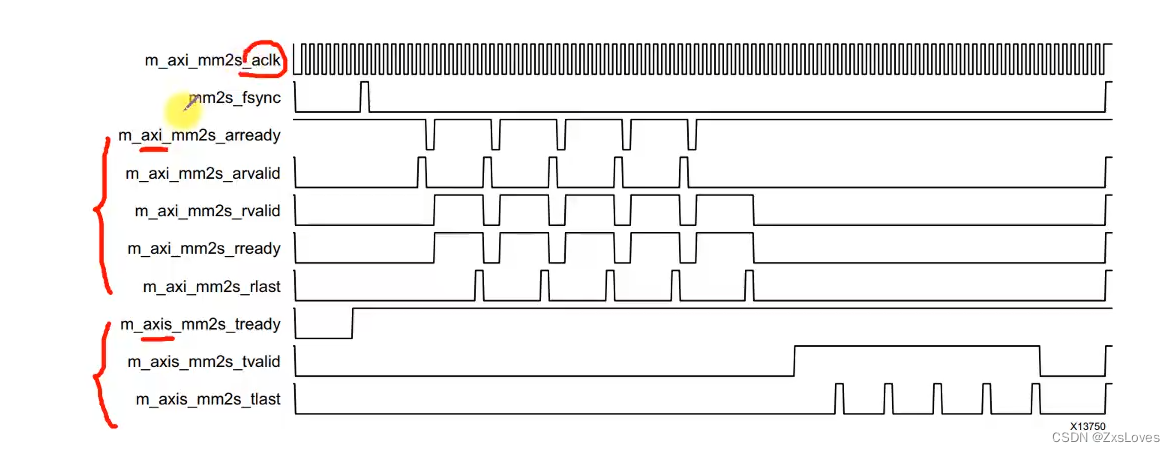
第二个 fsync 是帧同步信号
帧同步信号的下降沿 标示着一帧信号的开始
然后我们先把 address 的 vaild 信号 拉高 在这里拉高了5次
表示我们从内存中 连续读出 五行 图像 (然后这五行图像组成了1帧)

下面是 读数据通道 它会返回我们从内存中 读出来的数据

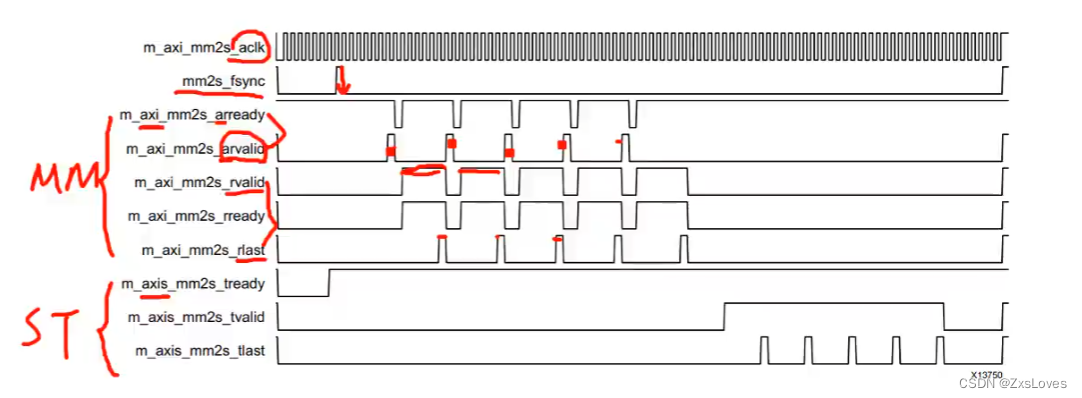
这两个 共同组成了MM 接口
下面我们来讲述ST接口
我们从MM 读出的数据 会先存到 line buffer 中 然后从 ST接口传输出去

我们可以观察到 当tvaild 拉高时 代表从内存读出来的数据以ST的形式正在输出
tlast 拉高 表示的时eol 所以在每一行的最后 都会拉高

st 接口的 tlast 表示 每一行的 最后一个像素点

axi协议的 last 信号 实际上是 突发传输的 最后一个数据
下面我们从 Block Design 中 学习具体的内容

第一个 S_AXI_LITE 接口 主要接到了 zynq 上的 GP端 用来传输 我们主机对 VDMA 的 各种控制

这两个的 下标前缀都是 AXIS 表示这是 传输 图像数据 的 Stream 接口
剩下两个是相对于我们 在上图 总体规划的左侧的 存储器映射接口

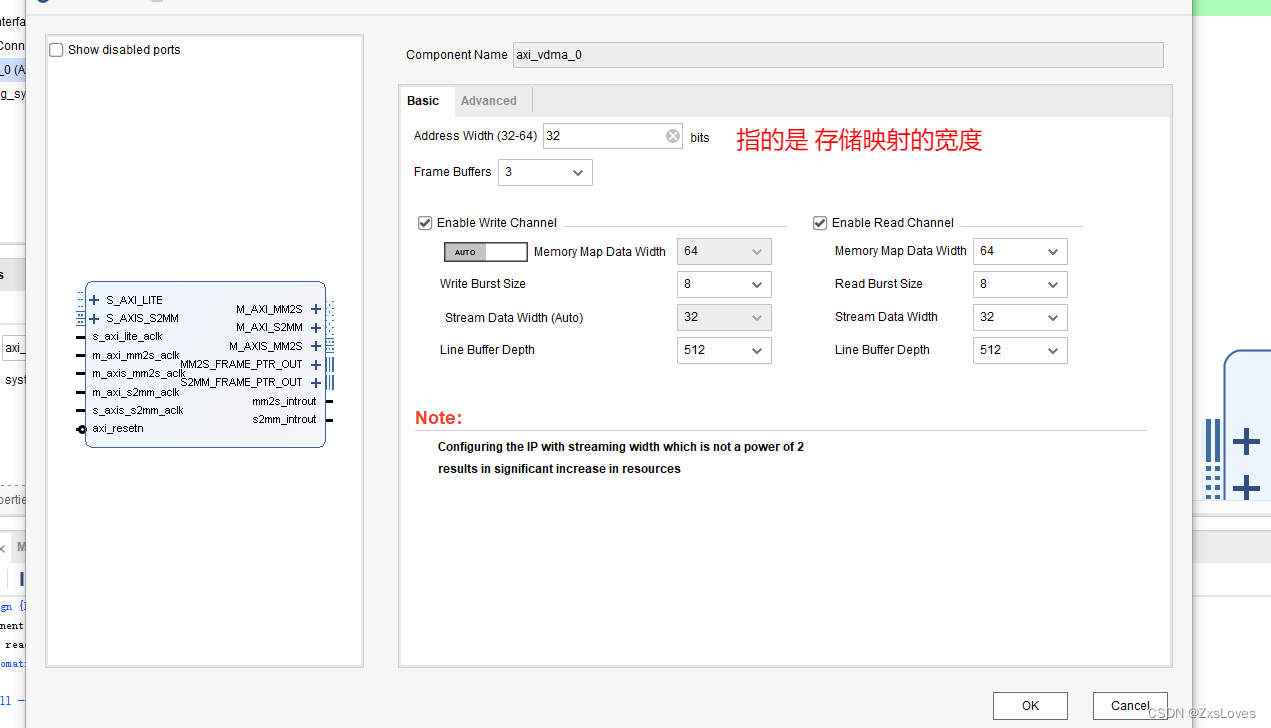
Address Width 表示我们最大访问的范围 32 就是 2的32次方
Frame Buffers 帧缓存 我们默认为3
(意思是 在同时使能读 同时使能写 的 状况下 我们 默认为 3 )
现在这里 我们只进行 读 不进行写 所以我们在内存中 只开辟一个帧缓存的空间

Memory Map Data Width 指的是 存储器 映射位宽
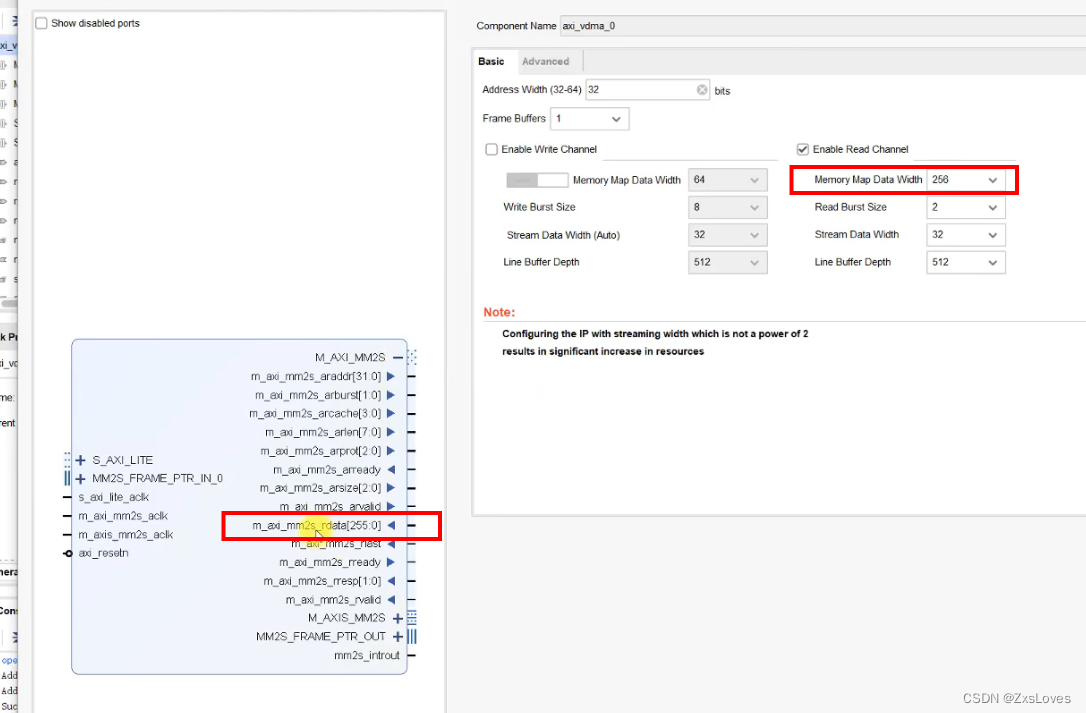
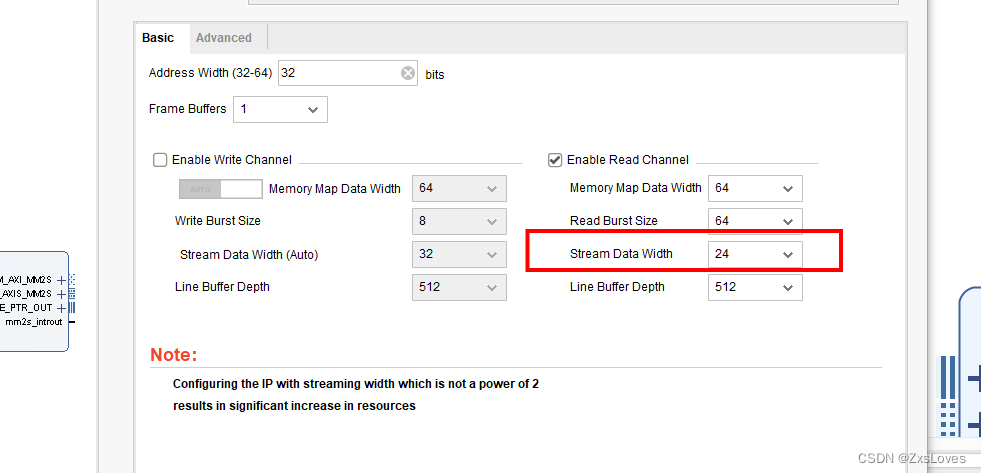
这里的 Stream Data Width 实际上就是我们传输的 (图片 这种形式下的 数据位宽
这里我们读RGB888 RGB888是 24bit 的数据
Line Buffer Depth 这里是 行缓存的大小
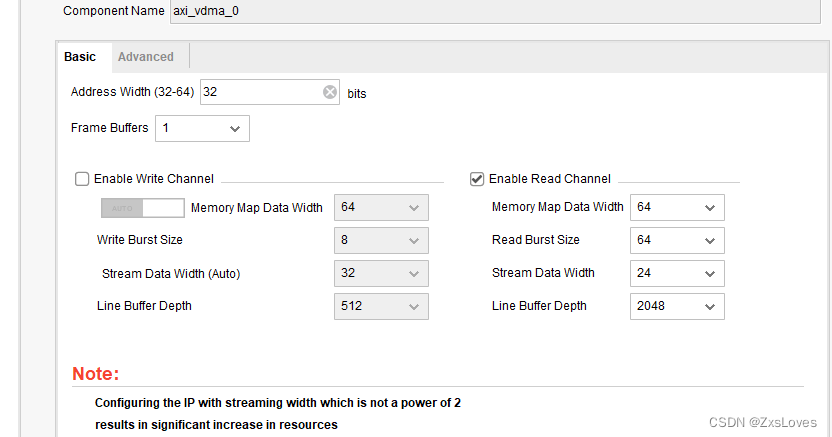
这是得到的 最后配置
然后我们观察 Advanced 选项
里面有一个 Fsync Options 这是 设置 帧同步的选项 我们可以选择 None 也可以选择 帧同步
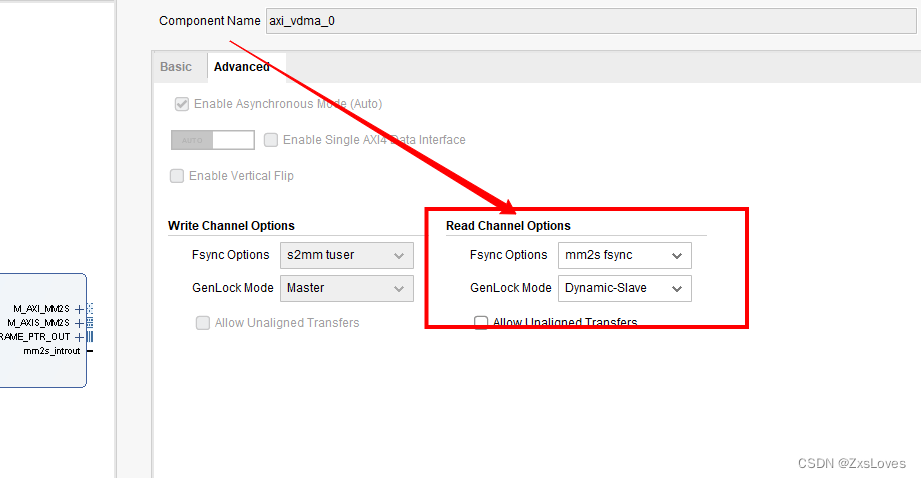
帧同步 是什么意思呢
我们只有在 帧同步信号的下降沿 我们才对一帧进行操作
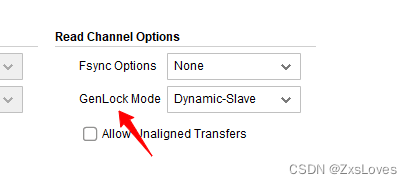
GenLock Mode 指的是 帧缓存的同步模式 这个只有在同步使能读通道 写通道的时候 才会出现这个
我们配置完毕后 选择自动连接 如下是整个电路示意图
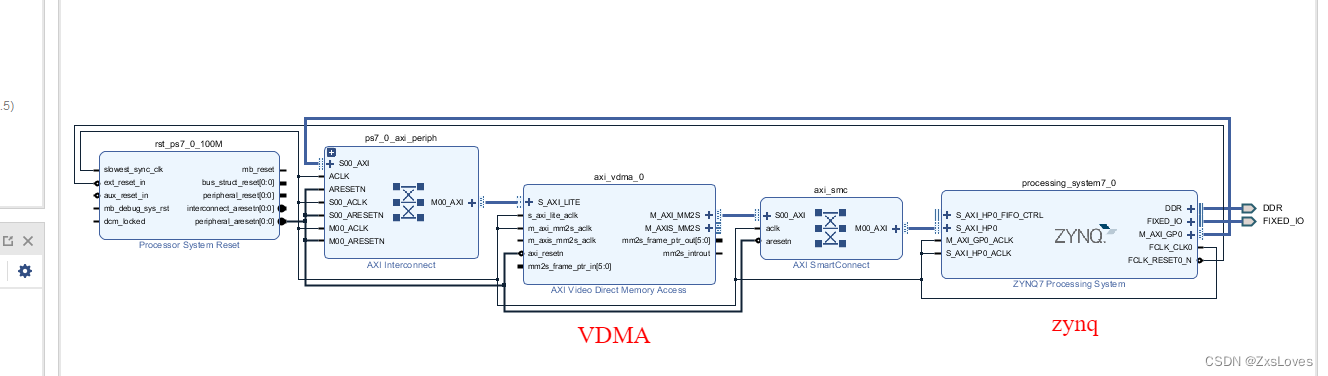
我们观察 如图 发现它会出现两个互联 一个是 AXI interconnect 互联 还有一个是 AXI SmartConnect 互联
现在我们讲述一下 这两个互联之间的 区别和联系
Smart互联 更加紧密的集成到了Vivado的开发环境中去
AXI 互联 可以用在所有的存储器映射中
有一些特定的情况 针对高带宽 的传输 我们使用 Smart互联 他会对我们的设计进行更好的优化 ,它会给系统带来更大的带宽和更小的延时 。
对于中高性能的设计 一般来说用 AXI SmartConnect
对于 低性能如 AXI4-Lite 复杂度比较小 所以用 AXI interconnect