使用Pandas进行时间重采样,充分挖掘数据价值
大家好,时间序列数据蕴含着很大价值,通过重采样技术可以提升原始数据的表现形式。本文将介绍数据重采样方法和工具,提升数据可视化技巧。
在进行时间数据可视化时,数据重采样是至关重要且非常有用的,它支持控制数据的粒度,以挖掘数据价值,并创建具有吸引力的图片。用户可以根据需求,对时间序列数据的频率进行上采样或下采样。
数据重采样主要有以下两个目的:
-
调整粒度:通过数据采集可以修改收数据点的时间间隔,只获取关键信息,剔除噪音数据,提升数据可视化效果。
-
对齐:重采样还有助于将来自不同时间间隔的多个数据源进行对齐,确保在创建可视化或进行分析时保持一致性。
例如,对于某家公司的每日证券数据进行可视化,挖掘长期趋势,并剔除噪音数据点。为此,可以通过取每月的平均收盘价,将每日数据重采样为每月频率,从而降低用于可视化的数据量,提升数据可视化的效果。
import pandas as pd
# 每日股票价格数据样本
data = {
'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),
'StockPrice': [100 + i + 10 * (i % 7) for i in range(365)]
}
df = pd.DataFrame(data)
# 按月频率重采样
monthly_data = df.resample('M', on='Date').mean()
print(monthly_data.head())
这个例子通过将每日数据重采样为每月数据,并计算出每月的平均收盘价,从而得到了更平滑、噪声更小的数据,从而更容易识别长期趋势和规律,以便做出决策。
1.选择正确的重采样频率
处理时间序列数据时,重采样的主要参数是频率,必须正确选择频率,才能获得具有洞察力和实用的可视化效果。不过,粒度和清晰度之间存在着权衡,粒度表示数据的详细程度,而清晰度则表示数据规律的展现程度。
例如,对于一年内每分钟记录的温度数据,对年度温度趋势进行可视化,但使用分钟级数据将导致图形过于密集和混乱。另外,如果将数据聚合为年度平均值,可能会丢失有价值的信息。
# 采集分钟级温度数据
data = {
'Timestamp': pd.date_range(start='2023-01-01', periods=525600, freq='T'),
'Temperature': [20 + 10 * (i % 1440) / 1440 for i in range(525600)]
}
df = pd.DataFrame(data)
# 按不同频率重采样
daily_avg = df.resample('D', on='Timestamp').mean()
monthly_avg = df.resample('M', on='Timestamp').mean()
yearly_avg = df.resample('Y', on='Timestamp').mean()
print(daily_avg.head())
print(monthly_avg.head())
print(yearly_avg.head())
此示例将分钟级温度数据重采样为日平均值、月平均值和年平均值。根据分析或可视化目标,可以选择最适合的详频率。每日平均值揭示了每日的温度规律,而每年平均值展示了年度趋势。
通过选择最佳的重采样频率,可以在数据细节和可视化清晰度之间取得平衡,进而传达数据中的规律和价值。
2.聚合方法
在处理时间数据时,了解各种聚合方法非常重要。通过这些方法,可以有效地总结和分析数据,揭示时间相关信息的不同方面。标准的聚合方法包括计算总和与平均值,或应用自定义函数。
例如,对于包含一年内零售店每日销售数据的数据集,对其进行年度收入趋势分析,为此可以使用聚合方法计算每月和每年的总销售额。
# 每日销售数据样本
data = {
'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),
'Sales': [1000 + i * 10 + 5 * (i % 30) for i in range(365)]
}
df = pd.DataFrame(data)
# 使用聚合方法计算每月和每年的销售额
monthly_totals = df.resample('M', on='Date').sum()
yearly_totals = df.resample('Y', on='Date').sum()
print(monthly_totals.head())
print(yearly_totals.head())
此示例使用sum()聚合方法将每日销售数据重采样为每月和每年的总销售额,通过该方法,可以分析在不同粒度级别上的销售趋势。月度总计揭示了季节变化,而年度总计则展示了年度业绩。
根据具体的分析需求,还可以使用其他聚合方法,如计算平均值和中位数,或根据数据集分布情况应用自定义函数,这对问题的解决很有意义。通过这些方法,可以用符合自己的分析或可视化目标的方式对数据进行总结,从时间数据中提取更多价值。
3.处理缺失数据
处理缺失数据是时间序列中的关键点,可确保数据中存在间隙时,可视化和分析仍能保持准确性和信息量。
例如,对于历史温度数据集,但由于设备故障或数据收集错误,某些日期的温度读数缺失。此时就必须处理这些缺失值,以创建有意义的可视化并保持数据的完整性。
# 带有缺失值的温度数据样本
data = {
'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),
'Temperature': [25 + np.random.randn() * 5 if np.random.rand() > 0.2 else np.nan for _ in range(365)]
}
df = pd.DataFrame(data)
# 前向填充缺失值(用前一天的温度填充)
df['Temperature'].fillna(method='ffill', inplace=True)
# 可视化温度数据
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
plt.plot(df['Date'], df['Temperature'], label='Temperature', color='blue')
plt.title('Daily Temperature Over Time')
plt.xlabel('Date')
plt.ylabel('Temperature (°C)')
plt.grid(True)
plt.show()
输出图形如下所示:
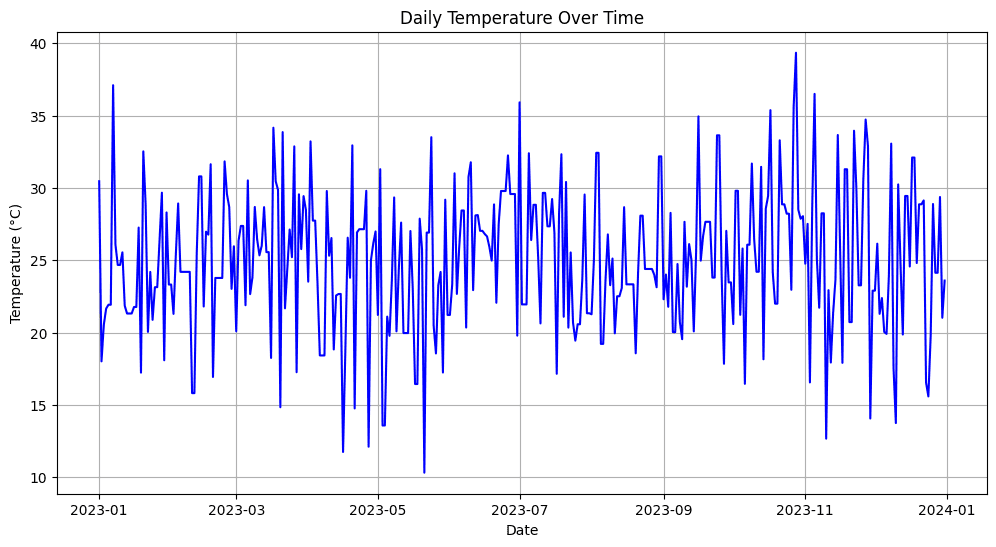
这个示例模拟了缺失的温度值(约占数据的20%),然后使用前向填充(ffill)方法填充了缺失的部分,即缺失值被前一天的温度替代。
处理缺失数据可确保可视化效果准确地反映时间序列中的基本趋势和规律,防止空缺数据影响整体数据。根据数据的性质和具体问题,可以采用插值或向后填充等其他策略。
4.可视化趋势和规律
在Pandas中进行数据重采样,有助于可视化连续或离散时间数据中的趋势和规律,进一步挖掘数据价值,突出显示不同的组成部分,包括趋势、季节性和不规则问题(可能是数据中的噪音)。
例如,对于包含过去几年每日网站流量数据的数据集,目标是可视化展示随后几年的整体流量趋势,识别任何季节性规律,并发现流量中不规则的峰值或谷值。
# 网站每日流量数据样本
data = {
'Date': pd.date_range(start='2019-01-01', periods=1095, freq='D'),
'Visitors': [500 + 10 * ((i % 365) - 180) + 50 * (i % 30) for i in range(1095)]
}
df = pd.DataFrame(data)
# 创建折线图,展示趋势
plt.figure(figsize=(12, 6))
plt.plot(df['Date'], df['Visitors'], label='Daily Visitors', color='blue')
plt.title('Website Traffic Over Time')
plt.xlabel('Date')
plt.ylabel('Visitors')
plt.grid(True)
# 添加季节性分解图
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df['Visitors'], model='additive', freq=365)
result.plot()
plt.show()
输出如下所示:
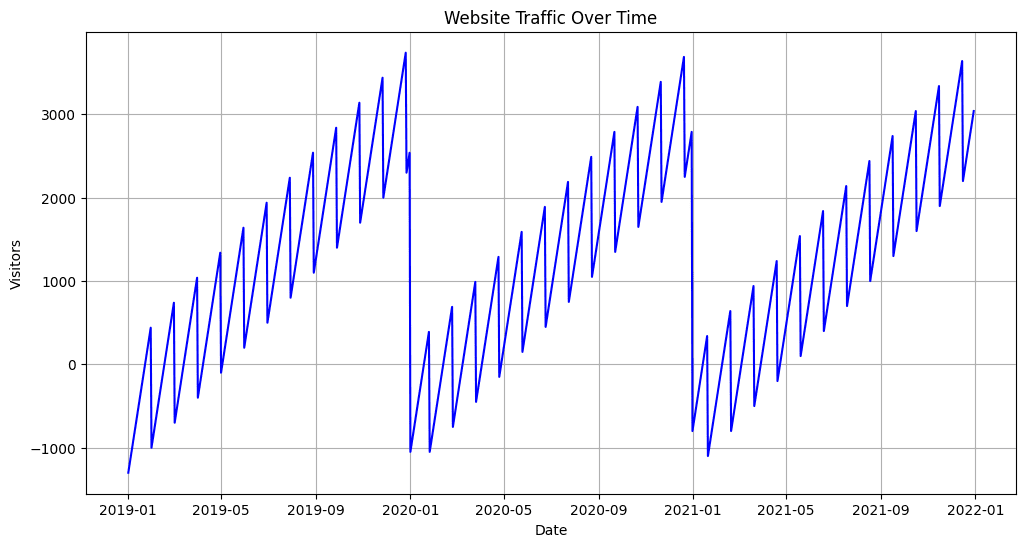
该示例创建了折线图,展示了随时间变化的每日网站流量趋势。该图描述了数据集中的整体增长和不规则规律。此外,为了将数据分解为不同的组成部分,本文使用了statsmodels库的季节性分解技术,包括趋势、季节性和残差等组成部分。
通过这种方式,可以展示网站流量的趋势、季节性和异常情况,从时间数据挖掘价值,进而将其转化为数据驱动的决策。
综上可知,重采样是一种强大的方法,可用于转换和汇总时间序列数据,以挖掘数据价值。使用聚合方法(如求和、平均值和自定义函数等)有助于揭示时间数据的不同方面,而可视化方法有助于识别趋势、季节性和不规则问题,从而清晰地展示数据中的规律。