2023.11.19 hadoop之MapReduce
目录
1.简介
2.分布式计算框架-Map Reduce
3.mapreduce的步骤
4.MapReduce底层原理
map阶段
shuffle阶段
reduce阶段
1.简介
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
什么是计算,分布式计算?
计算:对数据进行处理,使用统计分析等手段得到需要的结果
分布式计算:多台服务器协同工作,共同完成一个计算任务
分布式计算常见的2中工作模式?
分散->汇总
(Map Reduce就是这种模式)
中心调度->步骤执行
(大数据体系的Spark、Flink等是这种模式)
2.分布式计算框架-Map Reduce
分布式计算框架-Map Reduce
Map Reduce的思想核心:分而治之
所谓分而治之就是把一个复杂的问题按一定的分解方法分为规模较小的若干部分,然后逐个解决,分别找出各部分的解,再把把各部分的解组成整个问题的解。
Map:负责分,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行
计算,几乎没有依赖关系。
Reduce:负责合,即对map阶段的结果进行全局汇总。
Map Reduce是“分散->汇总”模式的分布式计算框架,可供开发人员开发相关程序进行分布式数据计算。
Map功能接口提供了“分散”的功能,由服务器分布式对数据进行处理
Reduce功能接口提供了“汇总(聚合)”的功能,将分布式的处理结果汇总统计
3.mapreduce的步骤
shuffe是map的后期,reduce的前期
输入-map负责分-shuffe(分区_排序_规约_分组)-reduce负责和-输出
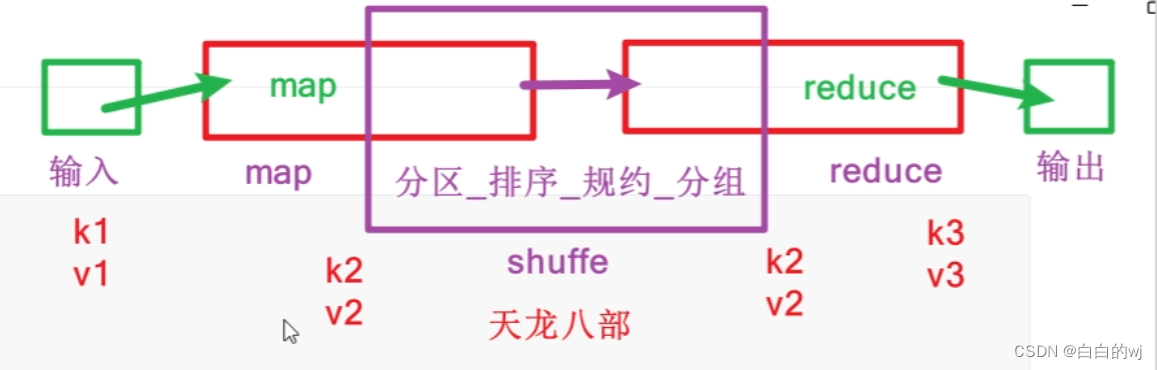
词频统计命令的流程:
已知文件内容:
hadoop hive hadoop spark hive
flink hive linux hive mysql
input结果:
k1(行偏移量) v1(每行文本内容)
0 hadoop hive hadoop spark hive
30 flink hive linux hive mysql
map结果:
k2(split切割后的单词) v2(拼接1)
hadoop 1
hive 1
hadoop 1
spark 1
hive 1
flink 1
hive 1
linu 1
hive 1
mysql 1
分区/排序/规约/分组结果:
k2(排序分组后的单词) v2(每个单词数量的集合)
flink [1]
hadoop [1,1]
hive [1,1,1,1]
linux [1]
mysql [1]
spark [1]
reduce结果:
k3(排序分组后的单词) v3(聚合后的单词数量)
flink 1
hadoop 2
hive 4
linux 1
mysql 1
spark 1
output结果: 注意: 输出目录一定不要存在,否则报错
flink 1
hadoop 2
hive 4
linux 1
mysql 1
spark 1
4.MapReduce底层原理

map阶段
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下Split size 等于 Block size。每一个切片由一个MapTask处理(当然也可以通过参数单独修改split大小)
第二阶段是对切片中的数据按照一定的规则解析成对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个,调用一次map方法。每次调用map方法会输出零个或多个键值对
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。
如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中
第六阶段是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
shuffle阶段
shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等
Spill阶段:当内存中的数据量达到一定的阀值(80%)的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序
Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件
Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上
Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
reduce阶段
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。