消息消费过程
前言
本文介绍下Kafka消费过程, 内容涉及消费与消费组, 主题与分区, 位移提交,分区再平衡和消费者拦截器等内容。
消费者与消费组
Kafka将消费者组织为消费组, 消息只会被投递给消费组中的1个消费者。因此, 从不同消费组中的消费者来看, Kafka是多播(Pub/Sub)模式。从同一个消费组中的消费者来看, Kafka是单播(P2P)模式。
开发流程
- 配置consumer参数并创建consumer实例;
- 订阅主题;
- 拉取消息并消费;
- 提交消费偏移量;
- 关闭consumer;
class ConsumerTest {
public static void main(String[] args) {
Properties props = new Properties();
// bootstrap server
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "");
// group.id, 如果当前consumer需要加入到某个group中, 否则自成一个group
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "");
// 自动创建topic, 开发中可能consumer端的小伙伴先开始, 等不及生产端。
props.setProperty(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG, "");
// 自动提交offset设置, 样例中为手动提交
// props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "");
// 自动提交offset的时间间隔
// props.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "");
// offset reset配置
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "");
// key和value的deserializer配置
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
boolean running = true;
while(running) {
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));
for(ConsumerRecord<String,String> record : records) {
// 消费消息
}
// 消费成功提交offset
consumer.commitSync();
}
consumer.close();
}
}
主题与分区
每个Topic中的消息由若干个分区存储, 每个分区存储了整个Topic下消息的一部分。在消息消费阶段, 同一个partition会被分配给消费组中的某一个consumer。因此partion的数量决定了一个consumer group中consumer的上限。
例如, Topic test 有 3 个partition, 对应的consumer group test-group中有4个consumer(consumer-1, consumer-2, consumer-3, consumer-4), 那么其中的某个consumer会处于空闲状态, 因为没有partition可以被分配, 进而也就无消息可消费。
反序列化
consumer作为消息的消费方, 必须使用与producer serializer相兼容的deserializer, 这样才能正确解析出对应的消息, 进而做消息消费。可以配置消息的key和message的deserialzer。Kafka内置了基本数据类型的Deserializer, IntegerDeserializer。
interface Deserializer {
T deserialize(String topic, byte[] data);
void close();
}
主题订阅
- 订阅通过subscribe方法完成。如果订阅方法反复调用, 仅最后一次的调用生效。
- 订阅多个特定主题, subscribe(collection);
- 订阅某种模式的主题, subscribe(pattern);
- 订阅某个主题的特定partition, assign(partition);
- 无论是哪种订阅方式, 一个consumer只能使用其中的一种, 都可以通过unsubscribe来取消订阅;
消息获取
- 消息消费的前提是topic中的消息投递给consumer。总体来说消息投递有2种模式, 推模式和拉模式。
- 推模式: client建立到server的长链接, 当server中有消息产生时, 第一时间通过该长链接推送到client;
- 拉模式: client主动发起消息请求, 从server端拉取消息;
- 从代码来看, Kafka是拉模式。由于consumer无法预知, topic中是否有新消息, 因此无效请求是存在的。Kafka设计者也注意到了这点, 提供了如下方法, 加入了一个等待窗口。如果窗口内有新消息到达, 则立刻返回; 如果始终无消息到达, 则超时后返回。平衡消息消费的及时性, 无效请求数量, 和server端实现复杂性。
kafkaConsumer.poll(timeout, timeunit)
内部涉及消费者位移, 消费者协调器, 组协调器, 消费者选择具, 分区分配的分发和再分配, 消费者心跳等内容。
位移提交
位移是消息在存储中的位置说明。通常来说, 消费者继续消费尚未消费的消息。消息存储和消费的逻辑模型如下:
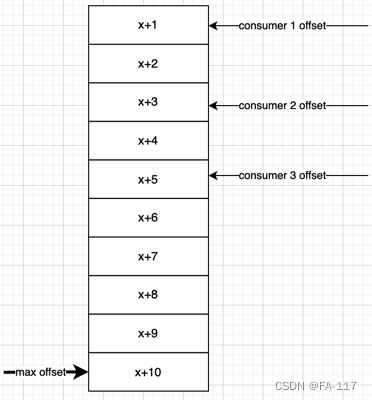
- 消息是按照partition存储的;
- 消息写入partition时, offset单调递增;
- 从partition消费时, 每个消费者维护自己的offset; 消费中断后恢复时, 从上次保存的offset位置开始继续消费;
因此消息是否已经被消费由offset决定, offset及其之前的消息是已消费的消息, offset之后是待消费消息。因此, 消费者完成某个分区的消费之后, 需要提交该offset给Kafka Server。提交方式有两种自动提交和手动提交;
| 提交方式 | 说明 | 优缺点 |
|---|---|---|
| 自动提交 | (默认方式) Kafka Client周期性地提交偏移量 | 优点是简单, 确定是重复消费和丢失风险 |
| 手动提交 | 由用户主动提交偏移量 | 优点是可细粒度管理, 缺点是相对复杂 |
自动提交
自动提交是按照时间间隔提交, 如果在消息拉取和位移提交之间client崩溃, 对下一次消费的影响分三种场景讨论(如下图所示)。

- consumer thread中poll和消费是串行的, 但consumer thread和commit thread是并行的;
- 在poll和crash之间发生commit, 那么当client恢复后从x+7开始拉取消息, [x+3, x+6] 的消息丢失;
- 在crash之后发生commit, 那么当client恢复后从x+7开始拉取消息, [x+3, x+6] 的消息丢失;
- 全程没有发生commit, 那么当client恢复后从x+1开始拉取消息, [x+1, x+3]的消息重复消费;
手动提交
也有两种模式, 同步提交和异步提交。前者在得到server确认之前所在线程会阻塞, 后者线程继续运行。是需要结合场景来选择。
| 提交方式 | 说明 | 优缺点 |
| 同步提交 | 针对当前拉取的一批消息, 统一提交 | 简单, 无法做细粒度控制 |
| 异步提交 | 基于回调通知结果 | 可以按分区提交, 指定offset参数提交 |
指定offset
消费消息需要从某个offset开始, 如果是首次消费又该从哪个位置开始呢?
-
由参数auto.offset.reset设定默认行为
| 参数值 | 行为 |
|----|----|
| earliest | 从分区第一条消息的offset开始 |
| latest | 从上次保存的offset开始, 首次消费时和earliest行为一致 |
| none | 程序逻辑自定义, 如果未设置则抛出异常 | -
程序通过seek方法指定offset位置, 如果指定offset越界也会触发auto.offset.reset行为; 由于offset是partition级别的概念, 因此seek的使用是面向partition, 这就意味着对同一个topic的多个partition来说, 可以seek不同的offset。此外seek方法也支持基于timestamp定位消息。站在更高的视角来看, seek提供了parttion级别的消息搜索能力。
-
由于seek的存在, 我们可以把offset存储在DB或者其他Kafka之外的地方, 并基于seek进行恢复。
再平衡
再平衡是把分区所有权从1个消费者转移到另一个消费者的行为, 它保障消费组的可用性和伸缩性。从可用性而言, 消费故障可以恢复。就伸缩性而言, 消费组内的消费者可以扩缩容。再平衡期间, 所有的消费者暂停消费, 直到再平衡结束。由于再平衡期间, 消费者的消费状态会丢失, 再平衡之后每个partition的offset以Kafka已持久保存的offset为准, 因此可能存在重复消费情况。
Kafka提供ConsumerRebalanceListener接口, 使得该过程可以被Consumer感知, 至于怎么处理则是应用需要解决的问题, Kafka也只能帮我们到这里。
消费者拦截器
Kafka提供了ConsumerInterceptor接口, 允许我们在poll方法返回前和commit方法调用后触发, 允许我们做一些定制化的工作, 比如消息过滤, 日志输出, 消息追踪等操作。从网络应用开发的角度来说, 这种是一种常见的实现方式, 比如Tomcat中的Filter。
拦截器通过interceptor.classes配置生效, 多个拦截器可以组合成为"拦截器Pipeline"。如果其中一个拦截器异常, 后续的拦截器从最近一次成功的拦截器继续执行, 因此需要提防副作用。