ICASSP2023年SPGC多语言AD检测的论文总结
文章目录
- 引言
- 正文
- Abstract
- Related Article
- No.1: CONSEN: COMPLEMENTARY AND SIMULTANEOUS ENSEMBLE FOR ALZHEIMER'SDISEASE DETECTION AND MMSE SCORE PREDICTION
- 特征相关
- 模型结构
- 数据处理
- 结果分析
- No.2: CROSS-LINGUAL TRANSFER LEARNING FOR ALZHEIMER'S DETECTION FROM SPONTANEOUS SPEECH
- 特征相关
- 模型结构
- 数据处理
- 结果分析
- No.3: THE USTC SYSTEM FOR ADRESS-M CHALLENGE
- 特征相关
- 模型结构
- 数据处理
- 结果分析
- No.4: Baseline/MULTILINGUAL ALZHEIMER'S DEMENTIA RECOGNITION THROUGH SPONTANEOUS SPEECH: A SIGNAL PROCESSING GRAND CHALLENGE
- 特征相关
- 模型结构
- 数据处理
- 结果分析
- No.5: EXPLORING LANGUAGE-AGNOSTIC SPEECH REPRESENTATIONS USING DOMAIN KNOWLEDGE FOR DETECTING ALZHEIMER’S DEMENTIA
- 特征相关
- 模型结构
- 数据处理
- 结果分析
- No.6: Cross-lingual Alzheimer's Disease detection based on paralinguistic and pre-trained features
- 特征相关
- 模型结构
- 数据处理
- 结果分析
- 总结
引言
- 已经读完了所有的文章,这里需要对于跨语言AD检测的比赛进行一个综合性的总结。
- 主要是总结一下几个方向
- 这些论文尝试了哪些特征?是如何实现的?结论如何?
- 这些论文是如何实现分类问题的?如何实现检测问题的?
- 这些论文是如何处理数据的?
- 这些论文是如何改良结果的。
正文
Abstract
- 在第一部分,首先对每一篇论文的技术方案从四个方面进行总结,分别是特征相关、模型实现相关、处理数据的方式还有结果分析。正在第二部分,我们将对左右文章进行总结,从使用特征,实现方法,数据集处理进行分析。
- 最后一部分,将会对全文进行一个总结,总结出下一步应该干什么。
Related Article
No.1: CONSEN: COMPLEMENTARY AND SIMULTANEOUS ENSEMBLE FOR ALZHEIMER’SDISEASE DETECTION AND MMSE SCORE PREDICTION
- 相关论文学习链接:链接
特征相关
音频特征尝试Acoustic Features
- wav2vec:53个跨语言模型得出,对应项目链接,但是没有在希腊语上调整过。
- i-vector:链接
- x-vector:链接
- VGGish:链接
不流利特征Disfluency Features Extraction
- Unnatural speech Breaks不自然的停顿
- longer speech durations更长时间的发音
- more speech pause更多的语音停顿
- slower speech rate更慢的语音速率
- 。。。一共18种不流利特征
模型结构
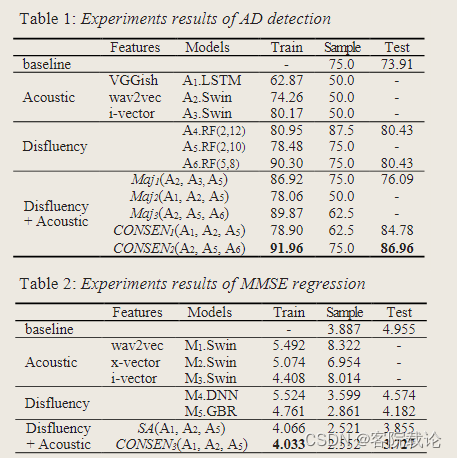
- 特征融合的效果更好,使用Majority Voting解决。
数据处理
数据进行分段,按照角色和停顿进行分段
结果分析
- 不流利特征集的分类效果,要好于音频特征集,所以disfluency特征更加不受语言的限制
- 特征融合之后,效果有显著提升。
No.2: CROSS-LINGUAL TRANSFER LEARNING FOR ALZHEIMER’S DETECTION FROM SPONTANEOUS SPEECH
- 鲁汶大学的比赛结果,第二名,是唯一一个公开代码,公开pt文件的队伍。
- 文章学习链接:相关链接
特征相关
音频特征
- eGeMAPS:来自OpenSmile,相关链接
模型结构
- 主要是对于eGeMAPS的处理,分为4个部分
这里没有细看,不过可以结合代码进行学习
数据处理
数据平衡和补充
- 去除没有MMSE分数的AD患者
- 去除8个AD患者,保证AD患者和健康人的数据平衡,都是114个人
- 补充未知的数据,确保所有人的特征都有
数据扩容——分段
- 将数据分为10段等长的段落,然后对每段计算对应的OpenSmile的eGeMAPS特征
结果分析
- 单纯从使用结果上来看,这里仅仅使用了音频特征,分类的准确率就达到了88.9%,所以有效利用音频特征,音频特征也是能够有效进行分类的。
No.3: THE USTC SYSTEM FOR ADRESS-M CHALLENGE
- 综合排名第三的是中科大的论文,整体性能不错,但是没有提供源代码,参考的信息不多。
- 文章学习链接:相关链接
特征相关
Silence Features静音特征:
- 静音的次数、静音时间和语音持续时间的比率、静音和语音持续时间的统计特征
Acoustic Features音频特征
- 低频段音频特征
- eGeMAPS(eGM):来自OpenSmile,相关链接
- ComParE2016(CPE):来源同上
Language Features语义特征
- facebook/wav2vec2-base-960h" model (WB):对应链接
- 使用英语和希腊语数据集进行微调强化,保证语义特征的有效性
- facebook/hubert-base-ls960" model (HB):对应链接
模型结构
- 中科大探索的很全面,不仅仅尝试了前两篇论文的所有特征,还额外增加了语义特征,
数据处理
提取韵律信息
- 对声音使用低通滤波,保留语言中通用的韵律信息,过滤表示语言音素信息的高频信息
结果分析
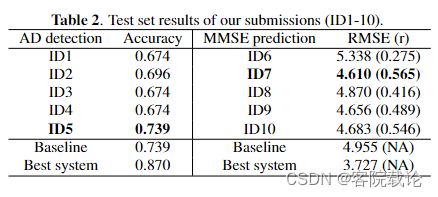
-
中科大探索的很全面,不仅仅尝试了前两篇论文的所有特征,还额外增加了语义特征,同时还使用了不同的融合方式进行测试,但是效果比单单使用某一种特征的效果还差,这不排除,没有对数据进行有效地处理,同时连接的方式有问题。
-
ID5仅仅使用了语义特征,效果最好,说明了语义特征有效性,但是需要使用特定双语数据集进行平衡微调才有效。
-
做了这么多实验,只是想证明单独使用音频特征的有效性。
No.4: Baseline/MULTILINGUAL ALZHEIMER’S DEMENTIA RECOGNITION THROUGH SPONTANEOUS SPEECH: A SIGNAL PROCESSING GRAND CHALLENGE
- 综合排名第四的是baseline,很诧异,二十多支参赛队伍,只有三个队伍的效果是超过baseline的。说明baseline的效果还是很厉害的。
- 文章学习链接:相关链接
特征相关
Acoustic Features音频特征
- eGeMAPS(eGM):来自OpenSmile,相关链接
- F0(基频)半音、响度、频谱流、MFCC(梅尔频率倒谱系数)、抖动、闪变、F1、F2、F3、alpha比、Hambarg指数以及斜率V0特征,以及它们最常见的统计功能,每帧总共88个特征
模型结构
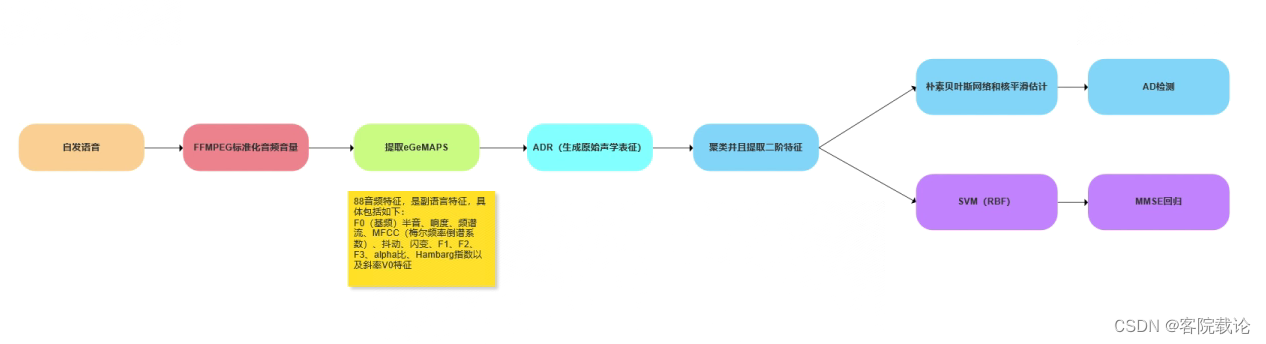
- 并没使用很复杂方式进行特征提取,而是使用传统的机器学习进行处理,并没有使用任何其他的方法。
数据处理
标准化音频文件
- 使用ffmpeg的EBU R128扫描器滤波器来标准化音频文件的音量
帧化处理
- 对音频应用了1秒钟的滑动窗口(没有重叠),并在这些帧上提取了eGeMAPS特征
结果分析
- baseline虽然是参考的基准,但是效果各项都很全面,都很厉害,同时他处理音频方式的也很独特,需要好借鉴学习。
- baseline证明了传统音频特征的有效性,同时对声音进行帧化处理,提取的特征更加明确。
No.5: EXPLORING LANGUAGE-AGNOSTIC SPEECH REPRESENTATIONS USING DOMAIN KNOWLEDGE FOR DETECTING ALZHEIMER’S DEMENTIA
- 综合排名第五的是加拿大大学的阿尔伯特大学,没有提供源代码,但是也是仅有的五篇文章之一,总结一下。
- 文章学习链接:相关链接
特征相关
word level duration features词级持续时间特征集
- 这个特征集主要描述的是说话者是否使用了短词或者长词,以及他们说出他们的时间
- Whisper实现
Pause rate features set停顿率特征集
- 这个特征集描述的是自发语音中的检测出的停顿的分布。
- OpenSmile实现
Speech intelligibility feature set
- 这个特征集描述了听者可以理解语音的易用性和准确性,这里由语音识别模型分配给每个识别词的词级置信度分数表示。
- 感觉欠妥,这部分过分牵扯到了口音清晰的重要性
模型结构
- 特征提取 + 常规机器学习方法分类
数据处理
统一数据模态
- 使用Whisper-Large将所有音频进行撰写,然后在进行翻译,统一翻译为英文进行处理。
结果分析
- 三种特征整体来说还是很有效的,最起码具有可理解性,而且作者尝试了不同的结合方式。
No.6: Cross-lingual Alzheimer’s Disease detection based on paralinguistic and pre-trained features
- 综合排名第六的是清华大学的分析文章,也是我看来应该是最好的,而且是最有潜力的文章,单单使用了单一模态的特征效率就很高,如果特征进行融合,效果应该会更高。
- 文章学习链接:相关链接
特征相关
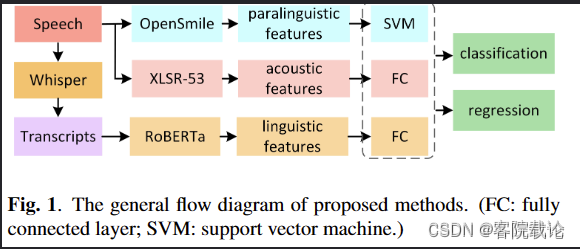
Paralinguistic features based approach副语言特征相关方法——OpenSmile
- 之前已经说过了,副语言特征对于单语言而言效果很棒,这里使用开源的OpenSmile框架对副语言特征进行副语言特征提取,主要是用了三个副语言特征数据集
- IS10-Paralinguistics-compat feature set
- IS10-Paralinguistics feature set
- IS11-speaker-state feature set.
Pre-trained acoustic features based approach基于预训练模型提取的音频特征——XLSR-53
- 我们这里用的是预先训练过的XLSR-53模型作为预训练模型,这个东西是跨语言预训练模型,在53种语言数据集上进行过训练。
Pre-trained linguistic features based approac基于预训练的语义特征方法——Whisper
- 翻译之后的文本将会用来对RoBERTa模型进行微调。最终的分类任务和回归任务是通过调整最终神经元的数量来实现的。
模型结构
数据处理
- 并未涉及到很多数据处理方式
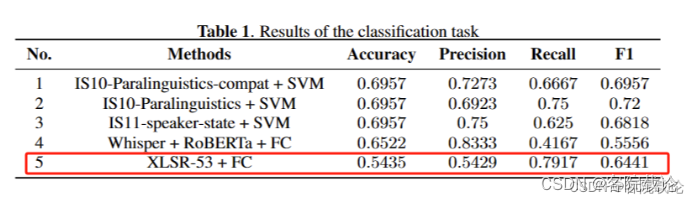
结果分析
总结
目前来看,总共6篇文章,各自使用了不同的方法,尝试了不同的特征,根据每一篇文章的内容可以做出来如下的一些总结
-
第一篇文章,证明了disfluency feature的有效性,同时AD任务和MMSE分类任务的相关性。
-
第二篇文章,证明了在有效的数据处理的情况下,eGeMAPS特征的有效性。
-
第三篇文章,证明了通过平衡数据微调之后的语义特征,具有跨语言的特性,效果较好。
- 有效的链接,应该是比单模态的效果要好;无效的链接,只会让融合之后的结果更差。
-
第四篇文章——baseline,证明了常见音频特征eGeMAPS的有效性,同时帧化处理之后的特征更加明显。
-
第五篇文章,虽然他自己说这两种特征有效,但是可理解性的定义并没有牵扯到语义,个人认为没有什么效果,这篇文章没啥效果。
-
第六篇文章,证明了副语言特征的的有效性,证明了语义特征的和文本内容高度绑定,并不能实现跨语言分析。
-
综上,可以在特征融合上下功夫,每一篇文章都没有时间去充分证明特征融合的有效性,或者说做的融合都很糟糕。最起码不应该比原来的模型差。
-
除此之外,还应该尝试多种数据预处理方式,包括帧化,低频过滤、文本翻译转写等操作。