kafka分布式安装部署
1.集群规划

2.集群部署
官方下载地址:http://kafka.apache.org/downloads.html
(1)上传并解压安装包
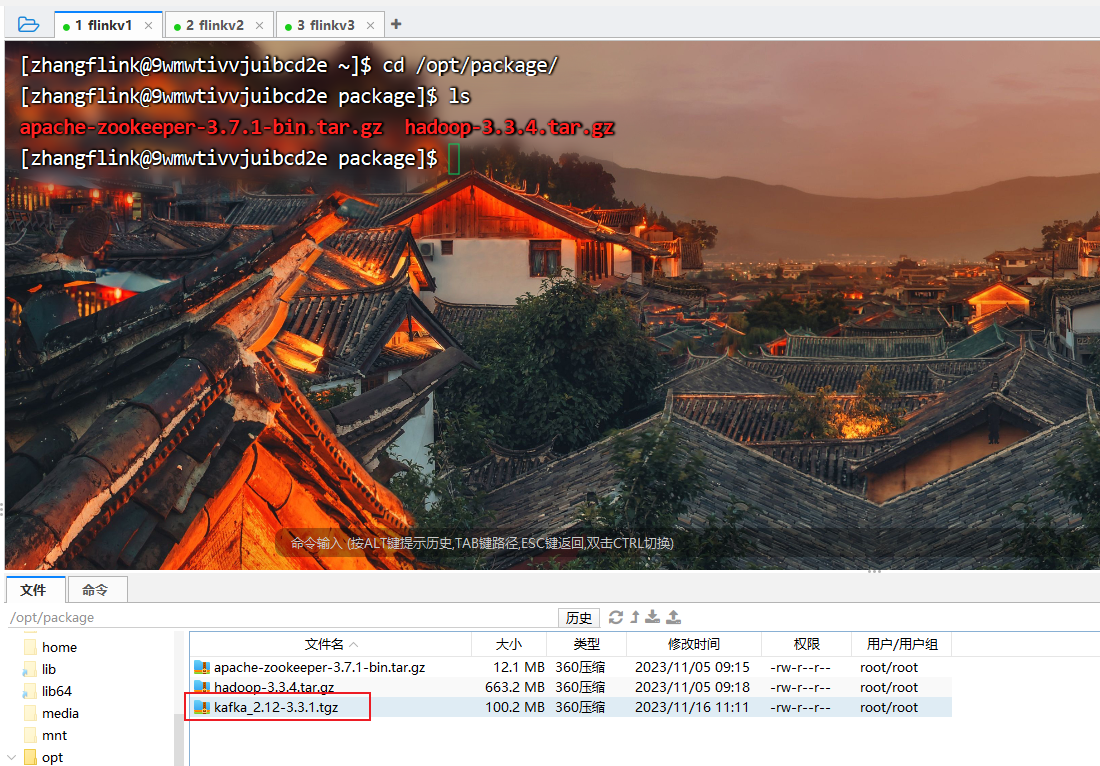
[zhangflink@9wmwtivvjuibcd2e package]$ tar -zxvf kafka_2.12-3.3.1.tgz -C ../software/

(2)修改解压后的文件名称
[zhangflink@9wmwtivvjuibcd2e software]$ mv kafka_2.12-3.3.1/ kafka

(3)进入到/opt/software/kafka目录,修改配置文件

[zhangflink@9wmwtivvjuibcd2e config]$ vim server.properties

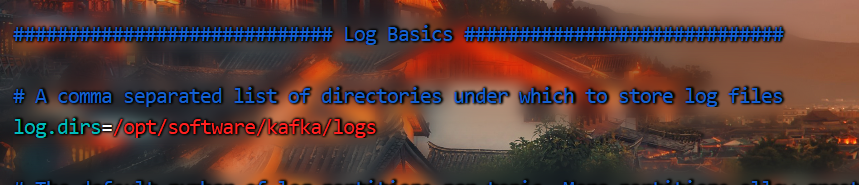
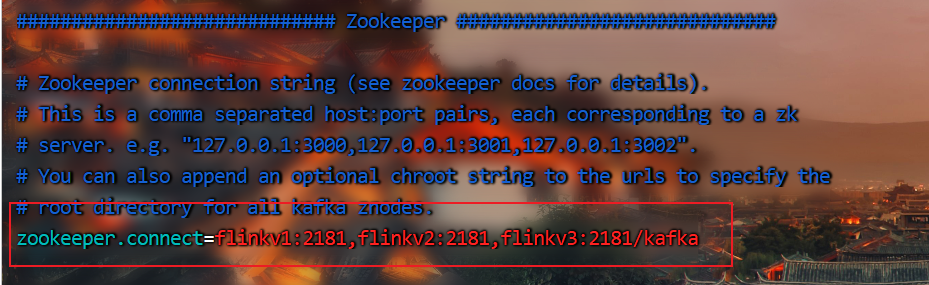
(3)配置系统环境变量
[zhangflink@9wmwtivvjuibcd2e config]$ sudo vim /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/opt/software/kafka
export PATH=$PATH:$KAFKA_HOME/bin

刷新配置文件
[zhangflink@9wmwtivvjuibcd2e config]$ source /etc/profile
(4)分发环境变量文件到其他节点,并source刷新配置文件
[zhangflink@9wmwtivvjuibcd2e software]$ /home/zhangflink/bin/xsync /etc/profile
[zhangflink@9wmwtivvjuibcd2e-0001 ~]$ source /etc/profile
[zhangflink@9wmwtivvjuibcd2e-0002 ~]$ source /etc/profile
(5)分发kafka文件到其他节点
[zhangflink@9wmwtivvjuibcd2e software]$ /home/zhangflink/bin/xsync kafka/
修改其他

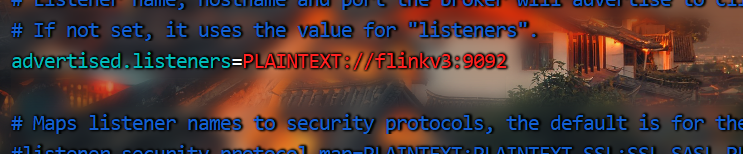
3.启动集群
先启动Zookeeper集群,然后启动Kafka。
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[zhangflink@9wmwtivvjuibcd2e-0001 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[zhangflink@9wmwtivvjuibcd2e-0002 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
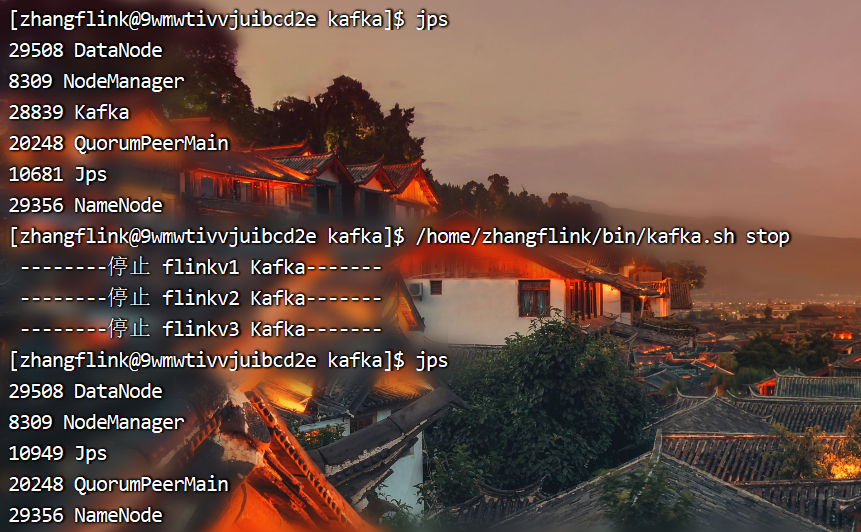
查看进程
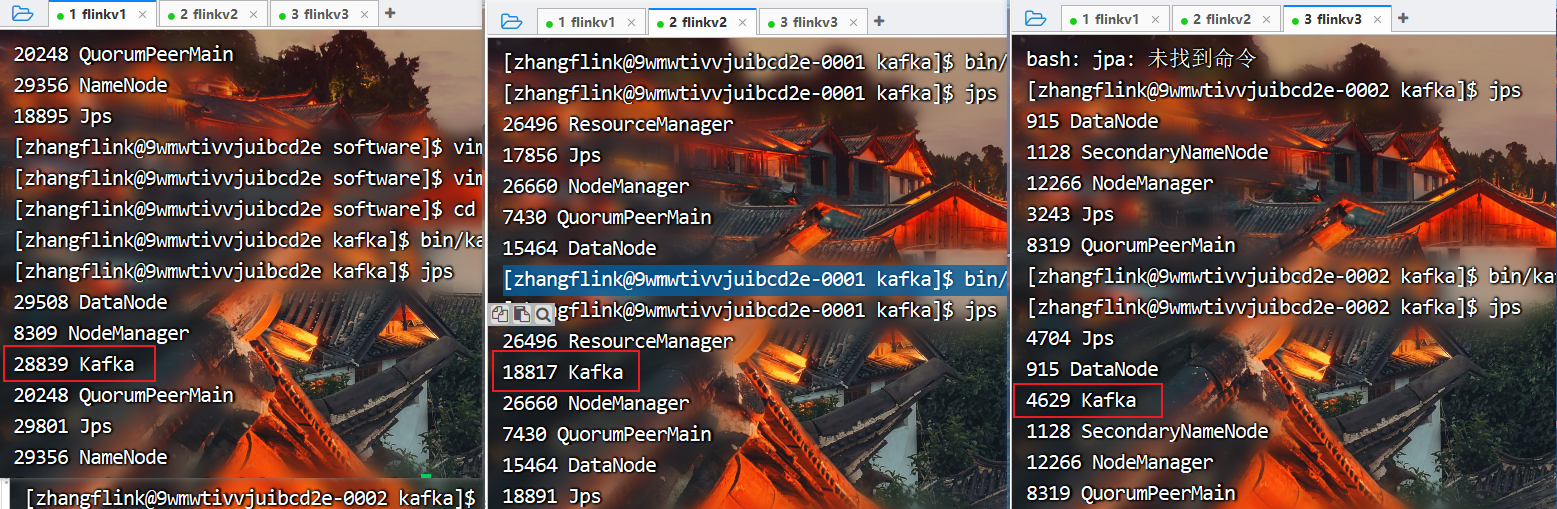
**
如果启动后一段时间发现节点停止,日志有如下报错,说明brokerID重复导致修改即可
**


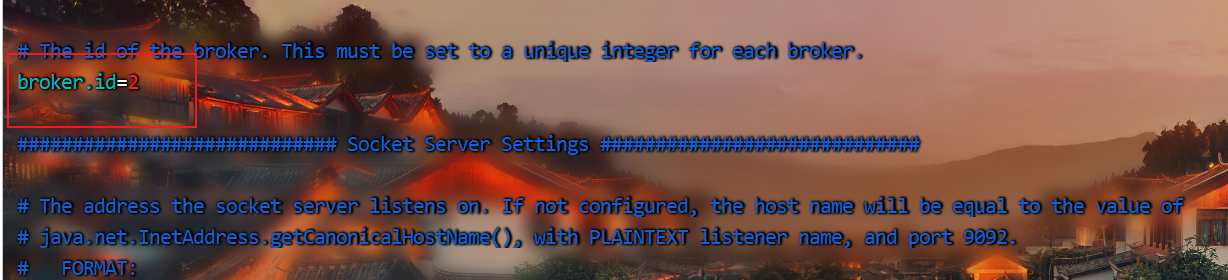
修改完后再次启动日志正常,brokerID正常


4.集群启停脚本
(1)在/home/zhangflink/bin目录下创建文件kafka.sh脚本文件
[zhangflink@9wmwtivvjuibcd2e kafka]$ sudo vim /home/zhangflink/bin/kafka.sh
编辑脚本
#! /bin/bash
case $1 in
"start"){
for i in flinkv1 flinkv2 flinkv3
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/software/kafka/bin/kafka-server-start.sh -daemon /opt/software/kafka/config/server.properties"
done
};;
"stop"){
for i in flinkv1 flinkv2 flinkv3
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/software/kafka/bin/kafka-server-stop.sh "
done
};;
esac
(2)添加执行权限
[zhangflink@9wmwtivvjuibcd2e kafka]$ sudo chmod 777 /home/zhangflink/bin/kafka.sh
如果启动脚本执行后,kafka进程没有启动,也没有报错,那么大概是以下问题
问题原因:
登录式Shell,采用用户名比如xxx登录,会自动加载/etc/profile
非登录式Shell,采用ssh比如ssh 192.168.1.121登录,不会自动加载/etc/profile,会自动加载~/.bashrc
解决方法:
先测试 ssh [bigdata111 ip] “which java” 是否有反应,如果显示"no found",则需要配置
执行命令
[zhangflink@9wmwtivvjuibcd2e bin]$ ssh flinkv1 "which java"
出现报错
which: no java in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin)
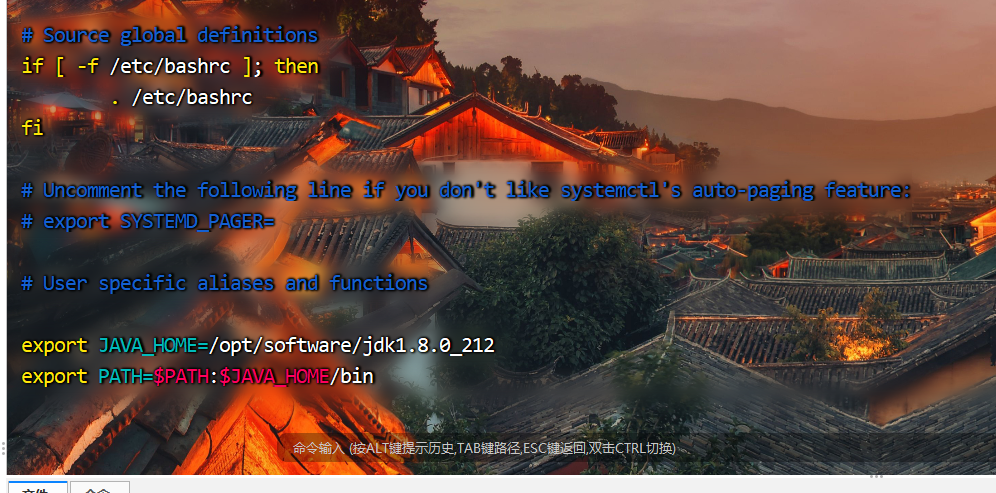
配置 ~/.bashrc文件
[zhangflink@9wmwtivvjuibcd2e ~]$ cd /home/zhangflink/bin/
[zhangflink@9wmwtivvjuibcd2e bin]$ vim ~/.bashrc
添加配置文件
export JAVA_HOME=/opt/software/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
并将.bashrc文件分发到其他节点上
[zhangflink@9wmwtivvjuibcd2e bin]$ /home/zhangflink/bin/xsync ~/.bashrc
继续测试 ssh [bigdata111 ip] “which java” 成功后重启脚本,看进程是否存在

然后再次执行脚本启动kafka,发现启动成功。
Kafka命令行操作
1 主题命令行操作
(1)查看操作主题命令参数
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-topics.sh
参数描述
–bootstrap-server <String: server toconnect to> 连接的Kafka Broker主机名称和端口号。
–topic <String: topic> 操作的topic名称。
–create 创建主题。
–delete 删除主题。
–alter 修改主题。
–list 查看所有主题。
–describe 查看主题详细描述。
–partitions <Integer: # of partitions> 设置分区数。
–replication-factor<Integer: replication factor> 设置分区副本。
–config <String: name=value> 更新系统默认的配置。
(2)查看当前服务器中的所有topic
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-topics.sh --bootstrap-server flinkv1:9092 --list
(3)创建 flumeData topic
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-topics.sh --bootstrap-server flinkv1:9092 --create --partitions 1 --replication-factor 3 --topic flumeData
选项说明:
–topic 定义topic名
–replication-factor 定义副本数
–partitions 定义分区数

(4)查看first主题的详情
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-topics.sh --bootstrap-server flinkv1:9092 --describe --topic flumeData

(5)修改分区数(注意:分区数只能增加,不能减少)
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-topics.sh --bootstrap-server flinkv1:9092 --alter --topic flumeData --partitions 3
(6)删除topic
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-topics.sh --bootstrap-server flinkv1:9092 --delete --topic flumeData
2 生产者命令行操作
(1)查看操作生产者命令参数
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-console-producer.sh
参数 描述
–bootstrap-server <String: server toconnect to> 连接的Kafka Broker主机名称和端口号。
–topic <String: topic> 操作的topic名称。
(2)发送消息
[zhangflink@9wmwtivvjuibcd2e kafka]$bin/kafka-console-producer.sh --bootstrap-server flinkv1:9092 --topic flumeData
3 消费者命令行操作
(1)查看操作消费者命令参数
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-console-consumer.sh
参数 描述
–bootstrap-server <String: server toconnect to> 连接的Kafka Broker主机名称和端口号。
–topic <String: topic> 操作的topic名称。
–from-beginning 从头开始消费。
–group <String: consumer group id> 指定消费者组名称。
(2)消费消息
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-console-consumer.sh --bootstrap-server flinkv1:9092 --topic flumeData
把主题中所有的数据都读取出来(包括历史数据)
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-console-consumer.sh --bootstrap-server flinkv1:9092 --from-beginning --topic flumeData