Linux入门攻坚——6、磁盘管理——分区及文件系统管理
磁盘管理主要涉及分区的管理,以及分区后的文件系统管理。
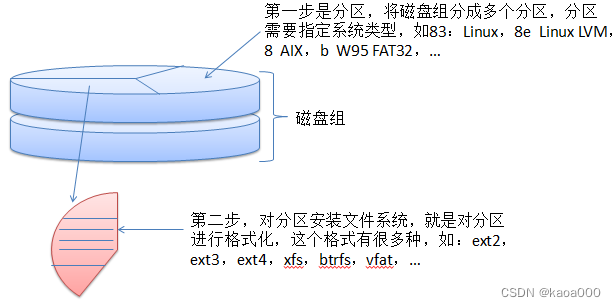
磁盘的使用大体要分两步:
文件系统也是一个软件,根是自引用的。
文件系统的全局结构:物理格式:

一个磁盘刚被生产出来的时候,它里边没有划分扇区,第一步要做的事情就是低级格式化,又叫物理格式化。物理格式化会把磁盘分为一个一个的扇区,同时在物理格式化的时候,也会检测这个磁盘当中有没有坏扇区存在,如果有坏扇区存在,那么就会使用一些备用扇区来顶替坏扇区。总之,物理格式化做的就是划分扇区,并且检测出坏扇区,同时用一些备用扇区来替换坏扇区。
逻辑格式化:高级格式化
物理格式化完了之后,接下来应该逻辑格式化,又叫作高级格式化,逻辑格式化会把磁盘分为一个一个的分区,又叫一个一个的分卷。比如大家最熟悉的C盘D盘E盘,这就是三个不同的分区。
一个磁盘被分为多个分区,那每一个分区的大小是多少?他是从哪个地址到哪个地址?它的一个地址范围是多少?这个就需要用分区表来记录。在每一个分区当中,可以建立各自独立的文件系统,比如说在C盘这个分区里边,可以建立一个unix的文件系统。
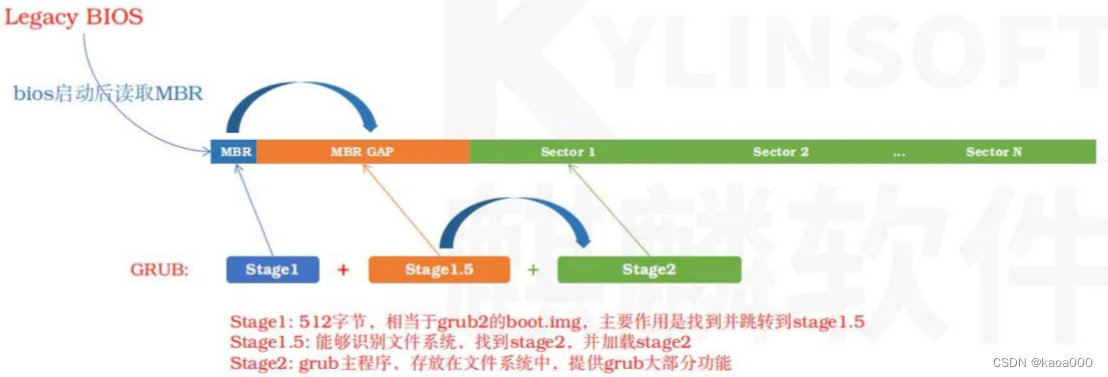
一般磁盘经过分区后,由MBR + MBR GAP + 若干分区组成.
a. MBR+MBR GAP一般是2048bytes, 主要用于写入引导程序(如grub、LILO等),引导系统启动;
b. MBR固定是512字节,446(引导写入区域)+64(分区表)+2(固定55aa)
MBR为磁盘的第一个扇区,共512Bytes,其中,前446字节是引导代码区,随后的64字节用于存储分区信息,每个分区信息16字节,共可以存储4个分区信息,所以,使用MBR分区最多容纳四个分区。最后两个字节为55AA。
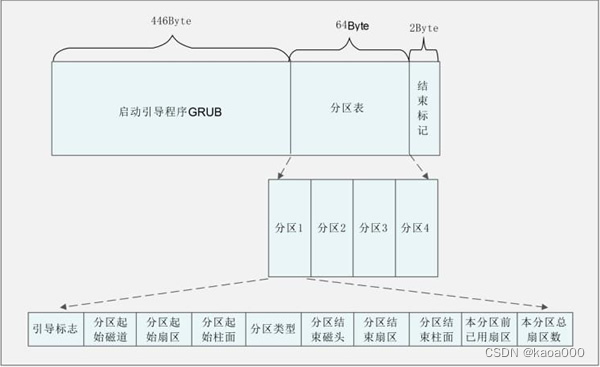
硬盘0磁道1 扇区的512个字节中记录的信息如下:
512= 446 + 64 + 2
MBR(主引导记录) MPT(主分区标示) 55aa(硬盘的有效性表示)
| 存储字节 | 数据内容及含义 |
|---|---|
| 第 1 字节 | 引导标志 |
| 第 2 字节 | 本分区的起始磁道号 |
| 第 3 字节 | 本分区的起始扇区号 |
| 第 4 字节 | 本分区的起始柱面号 |
| 第 5 字节 | 分区类型,可以识别主分区和扩展分区 |
| 第 6 字节 | 本分区的结束磁道号 |
| 第 7 字节 | 本分区的结束扇区号 |
| 第 8 字节 | 本分区的结束柱面号 |
| 第 9~12 字节 | 本分区之前已经占用的扇区数 |
| 第 13~16 字节 | 本分区的总扇区数 |
通过最后的 9~12,13~16字节,可以看出,总扇区数最多是4G个,即2的32次方,而每个扇区512字节,所以MBR方式支持的磁盘最大4Gx512=2T字节。即2TB。(可以使用UEFI和GPT进行替代)
从上述可以看出,所谓分区,就是在主引导分区中,即磁盘的第一个扇区中修改分区表的内容,规定每个分区从哪个扇区开始,到哪个扇区结束,规定了分区的边界。
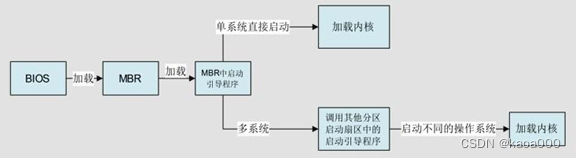
启动引导程序的作用
BIOS 的作用就是自检,然后从 MBR 中读取出启动引导程序。启动引导程序最主要的作用就是加载操作系统的内核。当然,每种操作系统的启动引导程序都是不同的。
每种操作系统的文件格式不同,因此,每种操作系统的启动引导程序也不一样。不同的操作系统只有使用自己的启动引导程序才能加载自己的内核。如果服务器上只安装了一个操作系统,那么这个操作系统的启动引导程序就会安装在 MBR 中。BIOS 调用 MBR 时读取出启动引导程序,就可以加载内核了。
但是在有些时候,服务器中安装了多个操作系统,而 MBR 只有一 个,那么在 MBR 中到底安装哪个操作系统的启动引导程序呢?
很明显,一个 MBR 是不够用的。每块硬盘只能有一个 MBR 是不能更改的,所以不可能増加 MBR 的数量。系统只能在每个文件系统(即每个分区)中单独划分出一个扇区,称作引导扇区(Boot Sector)。每个分区的引导扇区中也能安装启动引导程序,也就是说,在 MBR 和每个单独分区的引导扇区中都可以安装启动引导程序。这样多个操作系统才能安装在同一台服务器中(每个操作系统要安装在不同的分区中),而且每个操作系统都是可以启动的。
还有一个问题,BIOS 只能找到 MBR 中的启动引导程序,而找不到在分区的引导扇区中的启动引导程序。那么,要想完成多系统启动,方法是増加启动引导程序的功能,让安装到 MBR 中的启动引导程序(GRUB)可以调用在分区的引导扇区中的其他启动引导程序。
这里有一个分区起始位置的约定:分区是以柱面为单位。因为磁盘的第1扇区被mbr占用,所以mbr所属的柱面不能被分区使用。所以分区应该从第二柱面开始(实际上看是一个磁面的一条磁道)。这就是下图的MBR GAP部分,62个扇区,一个柱面即一个磁道,含有63个扇区,被MBR占用一个扇区后,就不能在归到其他分区,所以,一般的第一个分区是从63扇区开始的。(也有一种是从2048开始,总之就是分区不能跨磁道。)
分区完成后,就要对分区安装文件系统,所谓安装文件系统,从我个人的理解,就是对上面分区范围内的扇区中的部分扇区数据进行填充或修改,使之符合一定的数据结构,从底层扇区来讲,并没有什么改变,扇区依然保存的是0101序列,只不过,安装文件系统后,对特定的扇区内容进行了规定,扇区的特定位置保存的是什么数据,所以,文件系统是内核的一个进程,这个进程要使用这个进程能够理解的磁盘扇区数据结构,来进行磁盘的使用。
对于linux的文件系统,常用的如ext,其分区大致结构如下

预留一块区域作为引导区,所以第一个块组的前面要留 1K,用于启动引导区。最终,整个文件系统格式就是上面这个样子。那么为什么是引导块而不是引导扇区?为什么是1K而不是512?这其实又是一个逻辑的概念,磁盘属于块设备,读写是以一个扇区为单位进行的,但是经过测算统计,说是一次读2或4或8个扇区数据,效率会更好,还有一个原因是数据要使用,需要先读入内存中,而内存是分页使用的,一个页大小通常是4K,两个数据相匹配,于是就规定了一次读写操作的数据单位为块,一块可以是2、4、8个扇区。
几个概念:
- node Bitmap:即inode位图,用二进制的方式记录了inode的使用情况, 比如inode是否空闲等。
- Block Bitmap:即块位图,同Inode Bitmap,用二进制方式记录了块的使用情况。当查找或创建文件时,会扫描此位图来寻找空闲的inode号对应的块。
- super block:超级块包含了该硬盘或分区上的文件系统的整体信息,如文件系统的大小等。
- dentry:在内核中起到了连接不同的文件对象inode的作用,进而起到了维护文件系统目录树的作用。dentry是一个纯粹的内存结构,由文件系统在提供文件访问的过程中在内存中直接建立。dentry中包含了文件名,文件的inode号等信息。
在Linux中,一切皆文件,对于文件,又分为元数据和数据,元数据是保存文件的属性,如文件的字节数、属主属组、读、写、执行权限、时间戳等等,数据就是文件的实际内容。ext文件系统将元数据保存在inode列表中,数据保存在数据块中,要创建一个新文件,先扫描inode位图,找到一个空的节点,填充新建文件的属性信息,然后扫描数据块位图块,找到空白数据块,保存实际数据内容。在节点inode中将保存分配的数据块号。如果分区很大,位图块也会很大,扫描这两个位图块会很耗费时间。然后,从程序的数据局部性特性出发,将分区再分成一个个块组,块组中的块位图数据量会小很多,操作将加快,所以分区又进行了块组划分。
在ext文件系统的格式中,数据块的位图是放在一个块里面的,共 4k,也就是最大可以表示空间为128M(4K*8bit*4K,4K*8bit表示位图共有多少位,1位就表示一个块,共可以表示多少数据块,后面的4K代表数据块的大小,一般是1,2,4,所以取最大4K,最大空间就是128M)。现在很多文件都比这个大。我们先把这个结构称为一个块组。有 N 多的块组,就能够表示 N 大的文件。
因为块组有多个,块组描述符也同样组成一个列表,我们把这些称为块组描述符表(GDT)。对于块组描述符表来讲,如果每个块组里面都保存一份完整的块组描述符表,一方面很浪费空间;另一个方面,由于一个块组最大 128M,而块组描述符表里面项数的多少,也就决定了块组的多少,128M * 块组的总数目是整个文件系统的大小,就被限制住了。改进的思路就是引入 Meta Block Groups 特性。
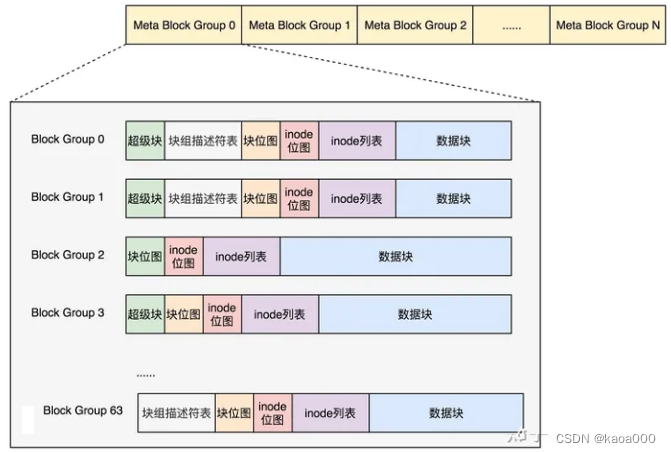
每一个元块组包含 64 个块组,块组描述符表也是 64 项,备份三份,在元块组的第一个,第二个和最后一个块组的开始处。这样化整为零,就可以发挥出 ext4 的 48 位块寻址的优势了,在超级块 ext4_super_block 的定义中,可以看到块寻址分为高位和低位,均为 32 位,其中有用的是 48 位,足够用了。
上面就是块组的逻辑结构,之所以叫逻辑结构,是因为从磁盘角度看,什么也没改变,还是一个个扇区保存了一串串01数据。
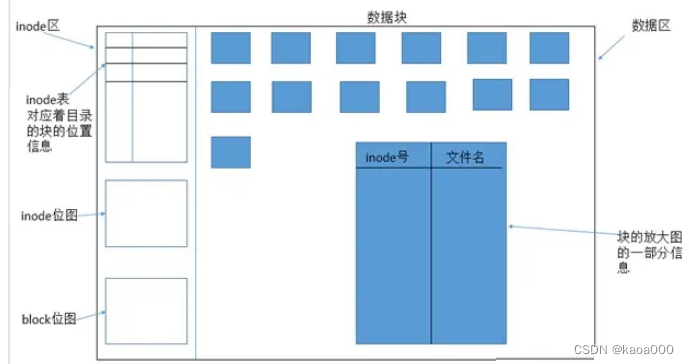
文件的保持,分为inode区和数据区,文件系统通常会将一个文件的元数据和实际数据两部份的数据分别存放在不同的区块,权限与属性放置到inode中,至于实际数据则放置到data block区块中。
文件的查找过程:以/var/log/message为例:

超级区块(superblock)会记录整个文件系统的整体信息,包括inode与block的总量、使用量、剩余量等,每个inode与block都有编号。超级块就是文件系统的心脏,它如此重要,以至于不得不做多个备份,在0或3、5、7的幂次方的块组中存在备份,即3,5,7的0次,1次,2次,3次。。。中,如,0次方就是组1,1次方就是3,5,7组中,2次方就是9,25,49组中等。
inode的数量与大小也是在格式化时就已经固定了,有三点需要注意:
a, 每个inode大小均固定为128bytes;
b, 每个档案都仅会占用一个inode而已;
c, inode记录一个block号码要花掉 4bytes
假设一个档案有4MB且每个block为4KB时,那么至少需要1K个block号码的记录,也就是需要inode至少有1K*4Bytes=4KB这么大(一个块用4Bytes表示),这不是开玩笑吗!每个inode只有128 bytes!!!
为此Ext2文件系统很聪明的将inode记录block号码的区域定义为:
12个直接 + 1个间接 + 个双间接 + 1个三间接记录区。

这样子inode能够指定多少个block呢?(以1KB大小的Block为例)
12个直接指向:共可记录12笔记录,也即12 blocks;
1个间接指向:1KB/4=256笔记录,也即256 blocks;
1个双间接指向:(1KB/4)*(1KB/4)=256*256=256^2笔记录,也即256^2 blocks;
1个三间接指向:(1KB/4)*(1KB/4)*(1KB/4)=256*256*256=256^3笔记录,也即256^3 blocks;
还有一个问题是关于根文件目录,根是自引用的,就是说根是高于磁盘的,系统默认就知道根在哪里,即对于一个分区,系统默认知道根,即/对应的inode在哪。一般的ext分区,其根对应的inode都是2。

对于普通数据文件,数据块中保存的是文件的实际内容,对于目录文件,数据块中保存的是其下文件与inode的对应表。
Linux磁盘管理:是对设备的管理,计算机的组成包括CPU、内存、I/O设备,磁盘就是I/O设备
I/O Portd:I/O设备地址;
一切皆文件:open(), read(), write(), close()
块设备:block,存取单位“块”,磁盘
字符设备:char,存取单位“字符”,键盘
设备文件:关联至一个设备驱动程序,进而能够跟与之对应的硬件设备进行通信;
设备号码:
主设备号:major number,标识设备类型
次设备号:minor number,标识同一类型下的不同设备
硬盘接口类型:
IDE、SCSI:并口
SATA、SAS、USB:串口
/dev/DEV_FILE
磁盘设备的设备文件命名:
IDE:/dev/hd
SCSI,SATA,SAS,USB:/dev/sd
不同设备:a-z,如/dev/sda,/dev/sdb,...
同一设备上的不同分区:1,2,3...,如/dev/sda1,/dev/sda5,...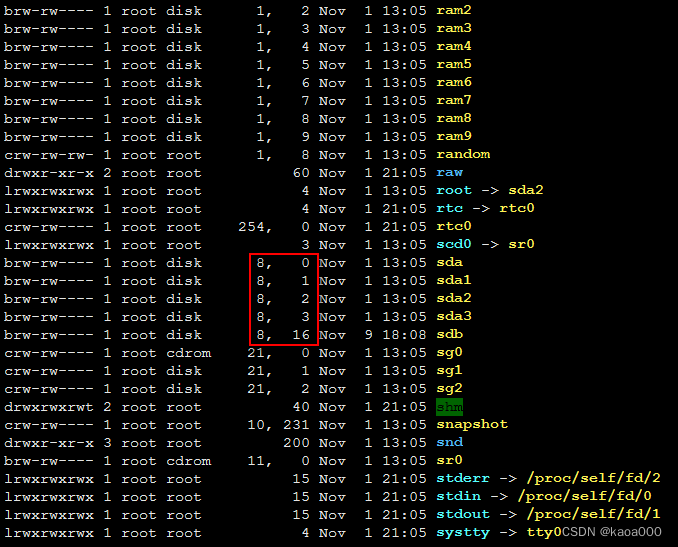
设备文件是特殊文件,一般只有元数据信息,而没有数据信息(内容)。
机械式硬盘:
track:磁道
cylinder:柱面
sector:扇区,512bytes
如何分区:按柱面划分
0磁道0扇区:512bytes,是MBR,保存了分区的信息,参考前面。
磁盘分区管理操作:fdisk、parted、sfdisk
fdisk:对于一块硬盘来讲,最多只能管理15个分区
fdisk -l [-u] [DEVICE]:显示分区情况
fdisk device:对设备进行分区,包含很多内部命令,如下:
p:print,显示当前硬件的已有分区,包括没有保存的改动
n:new,创建新分区; e:扩展分区, p:主分区
d:delete,删除一个分区
w:write,写入磁盘,即保存退出
q:quit,不保存退出
m:获取帮助
t:修改分区类型; L:
l:显示所支持的分区类型
显示当前设备分区情况:

分区(Centos6):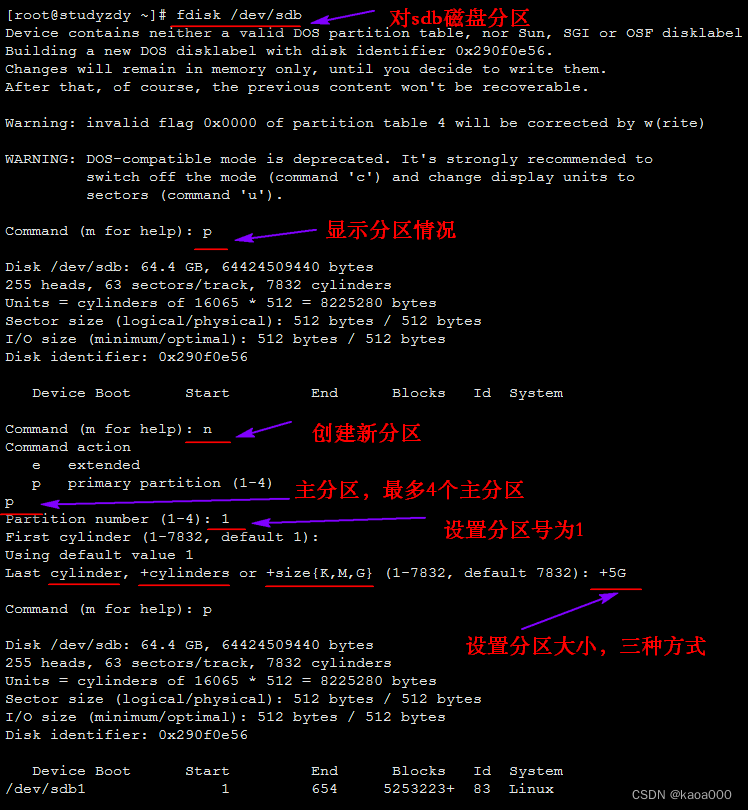
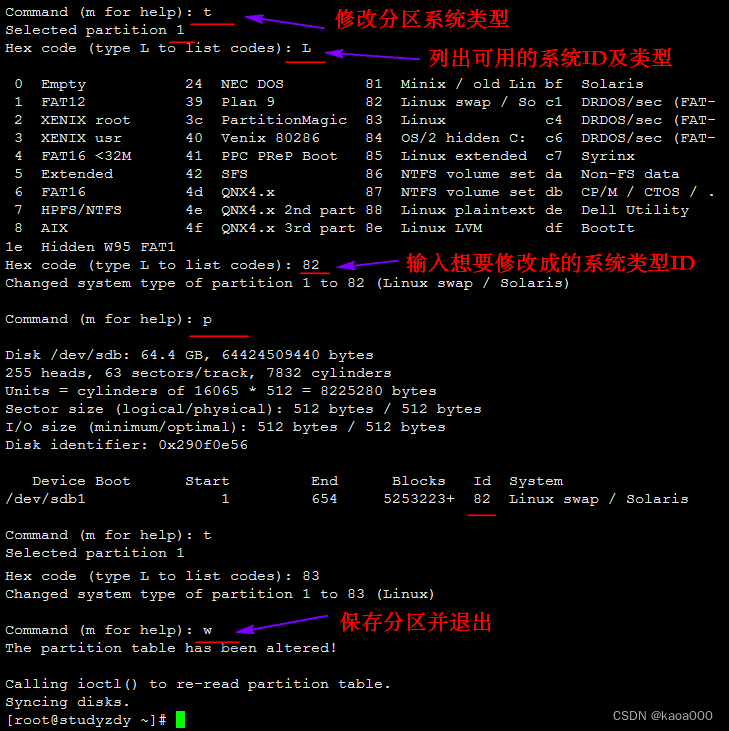
查看内核是否已经识别新的分区:
cat /proc/partitions 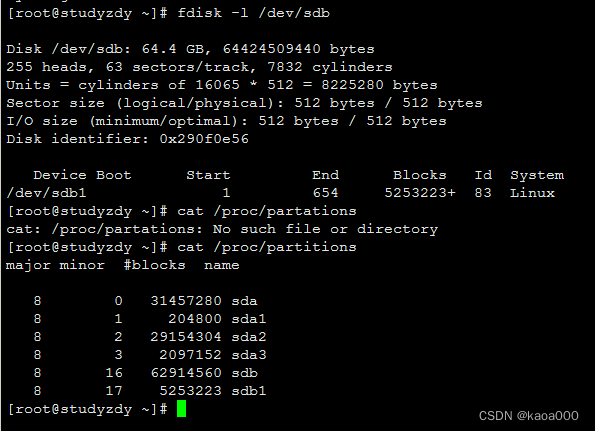
centos7:
两个版本使用w退出时,都进行了同步磁盘操作,所以分区后,使用fdisk及cat /proc/partitions查看,新分区都显示出来了: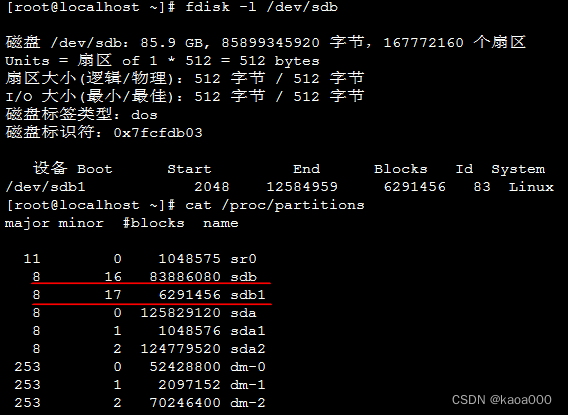
如果在/proc/partitions中没有,则要通知内核重新读取硬盘分区表:
partx -a /dev/DEVICE [-n M:N]
kpartx -a /dev/DEVICE -f :force
Centos5使用:partprobe [/dev/DEVICE]
文件系统管理:
Linux文件系统:ext2,ext3,ext4,xfs,btrfs,reiserfs,jfs,
swap:交换分区
光盘:iso9660
Windows:fat32,ntfs,
Unix:FFS,UFS,JFS2
网络文件系统:NFS,CIFS
集群文件系统:GFS2,OCFS2
分布式文件系统:ceph,moosefs,mogilefs,GlusterFS,Lustre
根据是否支持“journal”功能:
日志型文件系统:ext3,ext4,
非日志型文件系统:ext2,vfat
文件系统的组成部分:
内核中的模块:ext4,xfs
用户空间的管理工具:mkfs.ext4,mkfs.xfs,mkfs.vfat
因为Linux的文件系统如此之多,Linux使用的是VFS,Virtual FileSystem,虚拟文件系统。提供统一的应用接口,屏蔽底层不同磁盘,不同文件系统操作的差异。
创建文件系统:
cat /proc/filesystems,当前系统支持的文件系统
lsmod,内核加载的模块
用户空间的管理工具:
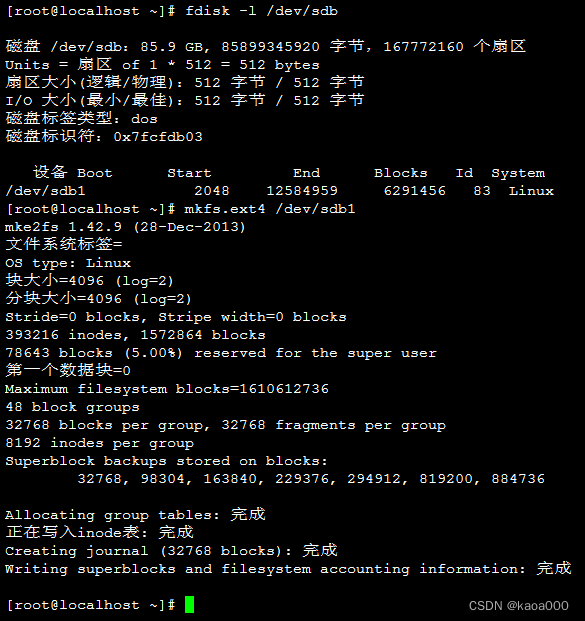
安装文件系统,相当于格式化:
blkid /dev/sdb1 :块设备属性信息查看
-U UUID :根据指定的UUID来查找对应的设备
-L ‘LABEL’ :根据指定的LABEL来查找对应的设备
mkfs.FS_TYPE /dev/sdb1
ext4、xfs、btrfs、vfat等
mkfs -t FS_TYPE -L 'LABEL' /dev/sdb1
mke2fs:ext系列文件系统专用管理工具
-t {ext2 | ext3 | ext4}
-b {1024 | 2048 | 4096}
-L ‘LABEL’
-j :相当于-t ext3
-i #:数据空间每多少个字节创建一个inode:此大小不应该小于block大小
-N #:为数据空间创建多少个inode
-m #:为管理人员预留的空间占据的百分比
-O FEATURE[,...]:启用指定特性, -O ^FEATURE:关闭指定特性
mkswap [option] device:创建交换分区
-L 'LABEL'
先调整分区类型为82
e2label DEVICE [LABEL]:管理ext系列文件系统的LABEL
tune2fs:重新设定ext系列文件系统可调整参数的值
-l :查看指定文件系统超级块信息:
-L ‘LABEL’:修改卷标
-m #:修改预留给管理员的空间百分比
-j :将ext2升级为ext3
-O:文件系统属性启用或禁用
-o:调整文件系统的默认挂载选项
-U UUID:修改UUID
dumpe2fs:
-h:查看超级块信息
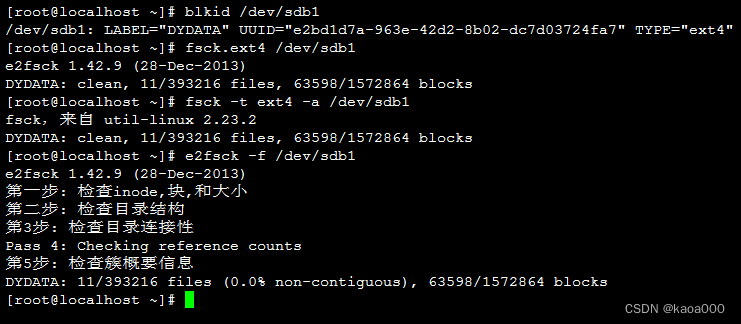
文件系统检测:
fsck:File System ChecK
fsck.FS_TYPE
fsck -t FS_TYPE
-a : 自动修复错误
-r : 交互式
注意:FS_TYPE一定要与分区上已有文件系统类型相同。
e2fsck:ext系列文件系统专用的检测修复工具
-f:强制性修复