01_SHELL编程之变量定义(一)
SHELL编程
-
该课程主要包括以下内容:
① Shell的基本语法结构
如:变量定义、条件判断、循环语句(for、until、while)、分支语句、函数和数组等;
② 基本正则表达式的运用;
③ 文件处理三剑客:grep、sed、awk工具的使用;
④ 使用shell脚本完成一些较复杂的任务,如:服务搭建、批量处理等。
说明:以上内容仅仅是基本要求,还有很多更深更难的语法需要扩充学习。
-
今日目标
-
熟悉grep、cut、sort等小工具和shell中的通配符的使用
-
==熟练掌握shell变量的定义和获取(重点)==
-
==能够进行shell简单的四则运算==
-
==熟悉条件判断语句,如判断整数,判断字符串等==
-
学习前奏
1. 文件处理工具
1.1 grep工具
行过滤
grep用于根据关键字进行行过滤
grep options 'keys' filename
OPTIONS:
-i: 不区分大小写
-v: 查找不包含指定内容的行,反向选择
-w: 按单词搜索
-o: 打印匹配关键字
-c: 统计匹配到的次数
-n: 显示行号
-r: 逐层遍历目录查找
-A: 显示匹配行及后面多少行
-B: 显示匹配行及前面多少行
-C: 显示匹配行前后多少行
-l:只列出匹配的文件名
-L:列出不匹配的文件名
-e: 使用正则匹配
-E:使用扩展正则匹配
^key:以关键字开头
key$:以关键字结尾
^$:匹配空行
--color=auto :可以将找到的关键词部分加上颜色的显示
临时设置:
# alias grep='grep --color=auto' //只针对当前终端和当前用户生效
永久设置:
1)全局(针对所有用户生效)
vim /etc/bashrc
alias grep='grep --color=auto'
source /etc/bashrc
2)局部(针对具体的某个用户)
vim ~/.bashrc
alias grep='grep --color=auto'
source ~/.bashrc
示例:
# grep -i root passwd 忽略大小写匹配包含root的行
# grep -w ftp passwd 精确匹配ftp单词
# grep -w hello passwd 精确匹配hello单词;自己添加包含hello的行到文件中
# grep -wo ftp passwd 打印匹配到的关键字ftp
# grep -n root passwd 打印匹配到root关键字的行好
# grep -ni root passwd 忽略大小写匹配统计包含关键字root的行
# grep -nic root passwd 忽略大小写匹配统计包含关键字root的行数
# grep -i ^root passwd 忽略大小写匹配以root开头的行
# grep bash$ passwd 匹配以bash结尾的行
# grep -n ^$ passwd 匹配空行并打印行号
# grep ^# /etc/vsftpd/vsftpd.conf 匹配以#号开头的行
# grep -v ^# /etc/vsftpd/vsftpd.conf 匹配不以#号开头的行
# grep -A 5 mail passwd 匹配包含mail关键字及其后5行
# grep -B 5 mail passwd 匹配包含mail关键字及其前5行
# grep -C 5 mail passwd 匹配包含mail关键字及其前后5行
1.2 cut工具
列截取
cut用于列截取
-c: 以字符为单位进行分割。
-d: 自定义分隔符,默认为制表符。\t
-f: 与-d一起使用,指定显示哪个区域。
# cut -d: -f1 1.txt 以:冒号分割,截取第1列内容
# cut -d: -f1,6,7 1.txt 以:冒号分割,截取第1,6,7列内容
# cut -c4 1.txt 截取文件中每行第4个字符
# cut -c1-4 1.txt 截取文件中每行的1-4个字符
# cut -c4-10 1.txt
# cut -c5- 1.txt 从第5个字符开始截取后面所有字符
课堂练习:
用小工具列出你当系统的运行级别。5/31.3 sort工具
排序
sort:将文件的每一行作为一个单位,从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
-u :去除重复行
-r :降序排列,默认是升序
-o : 将排序结果输出到文件中 类似 重定向符号>
-n :以数字排序,默认是按字符排序
-t :分隔符
-k :第N列
-b :忽略前导空格。
-R :随机排序,每次运行的结果均不同。
示例:
# sort -n -t: -k3 1.txt 按照用户的uid进行升序排列
# sort -nr -t: -k3 1.txt 按照用户的uid进行降序排列
# sort -n 2.txt 按照数字排序
# sort -nu 2.txt 按照数字排序并且去重
# sort -nr 2.txt
# sort -nru 2.txt
# sort -nru 2.txt
# sort -n 2.txt -o 3.txt 按照数字排序并将结果重定向到文件
# sort -R 2.txt
# sort -u 2.txt 1.4 uniq工具
去除连续的重复行
uniq:去除连续重复行
-i: 忽略大小写
-c: 统计重复行次数
-d:只显示重复行
# uniq 2.txt
# uniq -d 2.txt
# uniq -dc 2.txt 1.5 tee工具
tee工具从标准输入读取并写入标准输出和文件,即:双向覆盖重定向<屏幕输出|文本输入>
-a 双向追加重定向
# echo hello world
# echo hello world|tee file1
# cat file1
# echo 999|tee -a file1
# cat file1 1.6 paste工具
paste工具用于合并文件行
-d:自定义间隔符,默认是tab
-s:串行处理,非并行
[root@server shell01]# cat a.txt
hello
[root@server shell01]# cat b.txt
hello world
888
999
[root@server shell01]# paste a.txt b.txt
hello hello world
888
999
[root@server shell01]# paste b.txt a.txt
hello world hello
888
999
[root@server shell01]# paste -d'@' b.txt a.txt
hello world@hello
888@
999@
[root@server shell01]# paste -s b.txt a.txt
hello world 888 999
hello
1.7 tr工具
==字符转换:替换,删除==
tr用来从标准输入中通过替换或删除操作进行字符转换;主要用于删除文件中控制字符或进行字符转换。
使用tr时要转换两个字符串:字符串1用于查询,字符串2用于处理各种转换。
语法:
commands|tr 'string1' 'string2'
tr 'string1' 'string2' < filename
tr options 'string1' < filename
-d 删除字符串1中所有输入字符。
-s 删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串。
a-z 任意小写
A-Z 任意大写
0-9 任意数字
[:alnum:] all letters and digits 所有字母和数字
[:alpha:] all letters 所有字母
[:blank:] all horizontal whitespace 所有水平空白
[:cntrl:] all control characters 所有控制字符
\b Ctrl-H 退格符
\f Ctrl-L 走行换页
\n Ctrl-J 新行
\r Ctrl-M 回车
\t Ctrl-I tab键
[:digit:] all digits 所有数字
[:graph:] all printable characters, not including space
所有可打印的字符,不包含空格
[:lower:] all lower case letters 所有小写字母
[:print:] all printable characters, including space
所有可打印的字符,包含空格
[:punct:] all punctuation characters 所有的标点符号
[:space:] all horizontal or vertical whitespace 所有水平或垂直的空格
[:upper:] all upper case letters 所有大写字母
[:xdigit:] all hexadecimal digits 所有十六进制数字
[=CHAR=] all characters which are equivalent to CHAR 所有字符
[root@server shell01]# cat 3.txt 自己创建该文件用于测试
ROOT:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
boss02:x:516:511::/home/boss02:/bin/bash
vip:x:517:517::/home/vip:/bin/bash
stu1:x:518:518::/home/stu1:/bin/bash
mailnull:x:47:47::/var/spool/mqueue:/sbin/nologin
smmsp:x:51:51::/var/spool/mqueue:/sbin/nologin
aaaaaaaaaaaaaaaaaaaa
bbbbbb111111122222222222233333333cccccccc
hello world 888
666
777
999
# tr -d '[:/]' < 3.txt 删除文件中的:和/
# cat 3.txt |tr -d '[:/]' 删除文件中的:和/
# tr '[0-9]' '@' < 3.txt 将文件中的数字替换为@符号
# tr '[a-z]' '[A-Z]' < 3.txt 将文件中的小写字母替换成大写字母
# tr -s '[a-z]' < 3.txt 匹配小写字母并将重复的压缩为一个
# tr -s '[a-z0-9]' < 3.txt 匹配小写字母和数字并将重复的压缩为一个
# tr -d '[:digit:]' < 3.txt 删除文件中的数字
# tr -d '[:blank:]' < 3.txt 删除水平空白
# tr -d '[:space:]' < 3.txt 删除所有水平和垂直空白
小试牛刀
-
使用小工具分别截取当前主机IP;截取NETMASK;截取广播地址;截取MAC地址
[root@server shell01]# ifconfig eth0|grep 'Bcast'|tr -d '[a-zA-Z ]'|cut -d: -f2,3,4 10.1.1.1:10.1.1.255:255.255.255.0 [root@server shell01]# ifconfig eth0|grep 'Bcast'|tr -d '[a-zA-Z ]'|cut -d: -f2,3,4|tr ':' '\n' 10.1.1.1 10.1.1.255 255.255.255.0 [root@server shell01]# ifconfig eth0|grep 'HWaddr'|cut -d: -f2-|cut -d' ' -f4 00:0C:29:25:AE:54 # ifconfig eth1|grep Bcast|cut -d: -f2|cut -d' ' -f1 # ifconfig eth1|grep Bcast|cut -d: -f2|tr -d '[ a-zA-Z]' # ifconfig eth1|grep Bcast|tr -d '[:a-zA-Z]'|tr ' ' '@'|tr -s '@'|tr '@' '\n'|grep -v ^$ # ifconfig eth0|grep 'Bcast'|tr -d [:alpha:]|tr '[ :]' '\n'|grep -v ^$ # ifconfig eth1|grep HWaddr|cut -d ' ' -f11 # ifconfig eth0|grep HWaddr|tr -s ' '|cut -d' ' -f5 # ifconfig eth1|grep HWaddr|tr -s ' '|cut -d' ' -f5
-
将系统中所有普通用户的用户名、密码和默认shell保存到一个文件中,要求用户名密码和默认shell之间用tab键分割
[root@server shell01]# grep 'bash$' passwd |grep -v '^root'|cut -d: -f1,2,7|tr ':' '\t' stu1 x /bin/bash code x /bin/bash kefu x /bin/bash kefu1 x /bin/bash kefu2 x /bin/bash user01 x /bin/bash stu2 x /bin/bash [root@server shell01]# grep bash$ passwd |grep -viE 'root|mysql'|cut -d: -f1,2,7|tr ':' '\t' |tee a.txt 注释: -E 匹配扩展正则表达式,|代表或者,是一个扩展正则
2. 编程语言分类
-
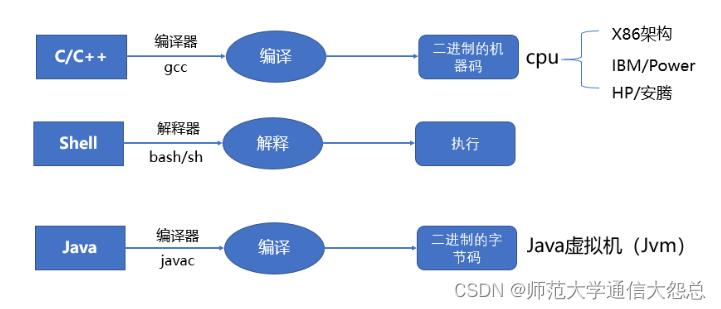
编译型语言:
==程序在执行之前需要一个专门的编译过程==,把程序编译成为机器语言文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++
-
解释型语言:
程序不需要编译,程序在运行时由==解释器==翻译成机器语言,每执行一次都要翻译一次。因此效率比较低。比如Python/JavaScript/ Perl /ruby/Shell等都是解释型语言。
-
总结:
编译型语言比解释型语言==速度较快==,但是不如解释型语言==跨平台性好==。如果做底层开发或者大型应用程序或者操作系开发一==般都用编译型语言==;如果是一些服务器脚本及一些辅助的接口,对速度要求不高、对各个平台的==兼容性有要求==的话则一般都用==解释型语言==。
3. shell介绍
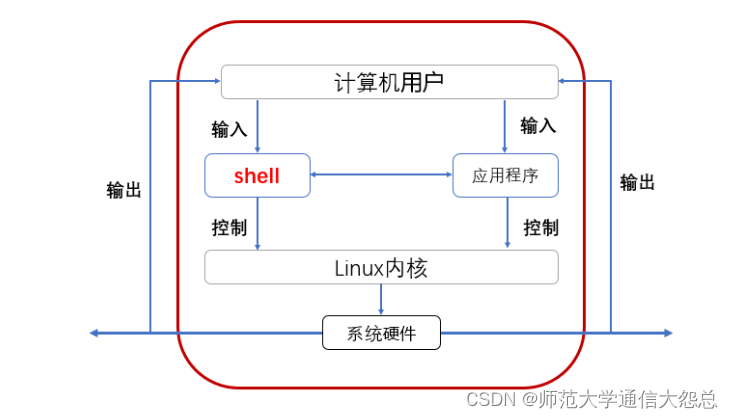
总结:
-
==shell就是人机交互的一个桥梁==
-
shell的种类
[root@MissHou ~]# cat /etc/shells /bin/sh #是bash shell的一个快捷方式 /bin/bash #bash shell是大多数Linux默认的shell,包含的功能几乎可以涵盖shell所有的功能 /sbin/nologin #表示非交互,不能登录操作系统 /bin/dash #小巧,高效,功能相比少一些 /bin/tcsh #是csh的增强版,完全兼容csh /bin/csh #具有C语言风格的一种shell,具有许多特性,但也有一些缺陷
-
用户在终端(终端就是bash的接口)输入命令
| bash //bash就是shell的一种类型(bash shell) | kernel | 物理硬件等
###4. shell脚本
-
什么是shell脚本?
-
一句话概括
简单来说就是将需要执行的命令保存到文本中,==按照顺序执行==。它是解释型的,意味着不需要编译。
-
准确叙述
若干命令 + 脚本的基本格式 + 脚本特定语法 + 思想= shell脚本
-
-
什么时候用到脚本?
重复化、复杂化的工作,通过把工作的命令写成脚本,以后仅仅需要执行脚本就能完成这些工作。
①自动化分析处理
②自动化备份
③自动化批量部署安装
④等等...
-
如何学习shell脚本?
-
尽可能记忆更多的命令
-
掌握脚本的标准的格式(指定魔法字节、使用标准的执行方式运行脚本)
-
必须==熟悉掌握==脚本的基本语法(重点)
-
学习脚本的秘诀:
多看(看懂)——>多模仿(多练)——>多思考
-
脚本的基本写法:
#!/bin/bash //脚本第一行, #!魔法字符,指定脚本代码执行的程序。即它告诉系统这个脚本需要什么解释器来执行,也就是使用哪一种Shell //以下内容是对脚本的基本信息的描述 # Name: 名字 # Desc:描述describe # Path:存放路径 # Usage:用法 # Update:更新时间 //下面就是脚本的具体内容 commands ...
-
脚本执行方法:
-
标准脚本执行方法(建议):(魔法字节指定的程序会生效)
[root@MissHou shell01]# cat 1.sh #!/bin/bash #xxxx #xxx #xxx hostname date [root@MissHou shell01]# chmod +x 1.sh [root@MissHou shell01]# ll total 4 -rwxr-xr-x 1 root root 42 Jul 22 14:40 1.sh [root@MissHou shell01]# /shell/shell01/1.sh MissHou.itcast.cc Sun Jul 22 14:41:00 CST 2018 [root@MissHou shell01]# ./1.sh MissHou.itcast.cc Sun Jul 22 14:41:30 CST 2018
-
非标准的执行方法(不建议):(魔法字节指定的程序不会运作)
[root@MissHou shell01]# bash 1.sh MissHou.itcast.cc Sun Jul 22 14:42:51 CST 2018 [root@MissHou shell01]# sh 1.sh MissHou.itcast.cc Sun Jul 22 14:43:01 CST 2018 [root@MissHou shell01]# [root@MissHou shell01]# bash -x 1.sh + hostname MissHou.itcast.cc + date Sun Jul 22 14:43:20 CST 2018 -x:一般用于排错,查看脚本的执行过程 -n:用来查看脚本的语法是否有问题 注意:如果脚本没有加可执行权限,不能使用标准的执行方法执行,bash 1.sh 其他: [root@server shell01]# source 2.sh server Thu Nov 22 15:45:50 CST 2018 [root@server shell01]# . 2.sh server Thu Nov 22 15:46:07 CST 2018 source 和 . 表示读取文件,执行文件里的命令
-
5. bash基本特性
####5.1 命令和文件自动补全
Tab只能补全命令和文件 (RHEL6/Centos6)
####5.2 常见的快捷键
^c 终止前台运行的程序 ^z 将前台运行的程序挂起到后台 ^d 退出 等价exit ^l 清屏 ^a |home 光标移到命令行的最前端 ^e |end 光标移到命令行的后端 ^u 删除光标前所有字符 ^k 删除光标后所有字符 ^r 搜索历史命令
####5.3 常用的通配符(重点)
*: 匹配0或多个任意字符
?: 匹配任意单个字符
[list]: 匹配[list]中的任意单个字符
[!list]: 匹配除list中的任意单个字符
{string1,string2,...}:匹配string1,string2或更多字符串
举例:
touch file{1..3}
touch file{1..13}.jpg
# ls file*
# ls *.jpg
# ll file?
# ll file?.jpg
# ll file??.jpg
# ll file1?.jpg
# ll file?.jpg
# ll file[1023].jpg
# ll file[0-13].jpg
# ll file1[0-9].jpg
# ll file[0-9].jpg
# ll file?[1-13].jpg
# ll file[1,2,3,10,11,12].jpg
# ll file1{11,10,1,2,3}.jpg
# ll file{1..10}.jpg
# ll file{1...10}.jpg
####5.4 bash中的引号(重点)
-
双引号"" :会把引号的内容当成整体来看待,允许通过$符号引用其他变量值
-
单引号'' :会把引号的内容当成整体来看待,禁止引用其他变量值,shell中特殊符号都被视为普通字符
-
反撇号`` :反撇号和$()一样,引号或括号里的命令会优先执行,如果存在嵌套,反撇号不能用
[root@server dir1]# echo "$(hostname)" server [root@server dir1]# echo '$(hostname)' $(hostname) [root@server dir1]# echo "hello world" hello world [root@server dir1]# echo 'hello world' hello world [root@server dir1]# echo $(date +%F) 2018-11-22 [root@server dir1]# echo `echo $(date +%F)` 2018-11-22 [root@server dir1]# echo `date +%F` 2018-11-22 [root@server dir1]# echo `echo `date +%F`` date +%F [root@server dir1]# echo $(echo `date +%F`) 2018-11-22