4种经典的限流算法与集群限流
0、基础知识
1000毫秒内,允许2个请求,其他请求全部拒绝。
不拒绝就可能往db打请求,把db干爆~
interval = 1000
rate = 2;
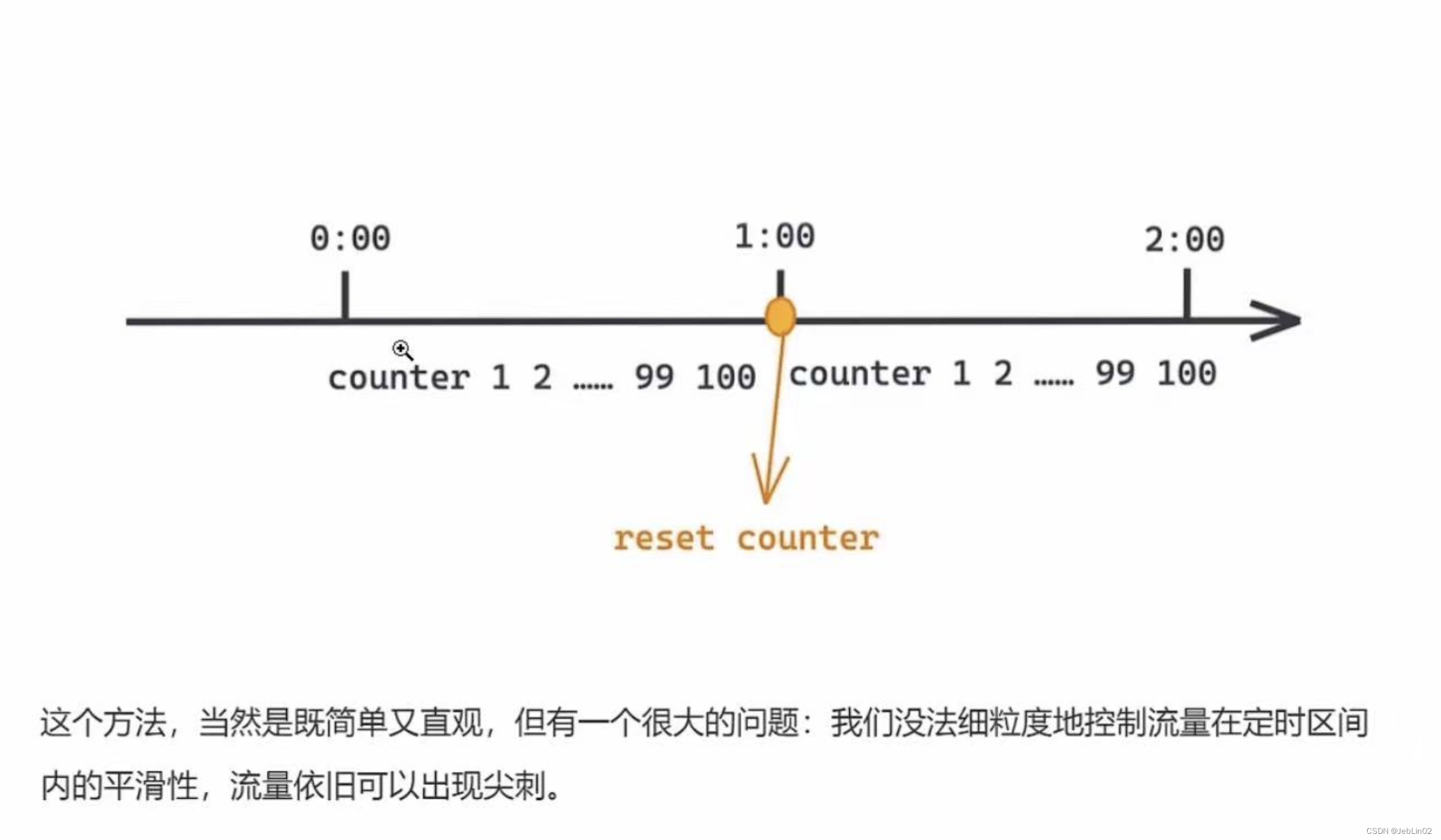
一、固定窗口限流
固定窗口限流算法(Fixed Window Rate Limiting Algorithm)是一种最简单的限流算法,其原理是在固定时间窗口(单位时间)内限制请求的数量。通俗点说主要通过一个支持原子操作的计数器来累计 1 秒内的请求次数,当 1 秒内计数达到限流阈值时触发拒绝策略。每过 1 秒,计数器重置为 0 开始重新计数。
/**
* 固定窗口限流算法
* 比如1000ms 允许通过10个请求
* @author jeb_lin
* 14:14 2023/11/19
*/
public class FixWindowRateLimiter {
private long interval; // 窗口的时间间隔
private long rate; // 限制的调用次数
private long lastTimeStamp; // 上次请求来的时间戳
private AtomicLong counter; // 计数器
public FixWindowRateLimiter(long interval,long rate){
this.interval = interval;
this.rate = rate;
this.lastTimeStamp = System.currentTimeMillis();
this.counter = new AtomicLong(0);
}
public static void main(String[] args) {
// 比如1000ms 允许通过10个请求
FixWindowRateLimiter limiter = new FixWindowRateLimiter(1000,2);
for (int i = 0; i < 4; i++) {
if(limiter.allow()){
System.out.println(i + " -> ok ");
} else {
System.out.println(i + " -> no");
}
}
}
private boolean allow() {
long now = System.currentTimeMillis();
if(now - lastTimeStamp > interval){
counter.set(0L);
lastTimeStamp = now;
}
if(counter.get() >= rate){
return false;
} else {
counter.incrementAndGet();
return true;
}
}
}输出:
0 -> ok
1 -> ok
2 -> no
3 -> no优点
- 简单易懂
缺陷
- 存在临界问题
 本来就允许1秒内进来2个请求,这时候进来了4个
本来就允许1秒内进来2个请求,这时候进来了4个
/**
* 测试不正常的情况
*/
private static void testUnNormal() throws Exception{
// 比如1000ms 允许通过10个请求
FixWindowRateLimiter limiter = new FixWindowRateLimiter(1000,2);
Thread.sleep(500);
for (int i = 0; i < 4; i++) {
if(limiter.allow()){
System.out.println(i + " -> ok ");
} else {
System.out.println(i + " -> no");
}
Thread.sleep(250);
}
}输出:
0 -> ok
1 -> ok
2 -> ok
3 -> ok 二、滑动窗口限流
滑动窗口限流算法是一种常用的限流算法,它将单位时间周期分为n个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。比如上图的示例中,每 500ms 滑动一次窗口就可以避免这种临界问题,可以发现窗口滑动的间隔越短,时间窗口的临界突变问题发生的概率也就越小,不过只要有时间窗口的存在,还是有可能发生时间窗口的临界突变问题。

类似于微积分:假如我切成1000个窗口,每1ms一个计数器
/**
* 滑动窗口限流算法
* 比如1000ms 允许通过 2 个请求
*
* @author jeb_lin
* 14:14 2023/11/19
*/
public class SlidingWindowRateLimiter {
private long interval; // 窗口的时间间隔
private long maxRequest; // 限制的调用次数
private Map<Long, AtomicLong> millToCount = null; // 假如1秒切成1000个窗口,也就是1毫秒一个计数器
private LinkedList<Long> timeStampList = null; // 出现请求的那个时间戳,需要记录下来,用于后期的删除
private AtomicLong counter; // 计数器
public SlidingWindowRateLimiter(long interval, long maxRequest) {
this.interval = interval;
this.maxRequest = maxRequest;
this.millToCount = new HashMap<>();
this.timeStampList = new LinkedList<>();
this.counter = new AtomicLong(0);
}
public static void main(String[] args) throws Exception {
testNormal();
}
/**
* 测试正常的情况
*/
private static void testNormal() {
// 比如1000ms 允许通过10个请求
SlidingWindowRateLimiter limiter = new SlidingWindowRateLimiter(1000, 2);
for (int i = 0; i < 10; i++) {
if (limiter.allow()) {
System.out.println(i + " -> ok ");
} else {
System.out.println(i + " -> no");
}
}
}
private boolean allow() {
long now = System.currentTimeMillis();
// 剔除掉过期的窗口,比如现在是1001ms,那么1ms的窗口就需要剔除掉
while (!timeStampList.isEmpty() && now - interval > timeStampList.getFirst()) {
long timeStamp = timeStampList.poll();
for (int i = 0; i < millToCount.getOrDefault(timeStamp,new AtomicLong(0)).get(); i++) {
counter.decrementAndGet();
}
millToCount.remove(timeStamp);
}
if (counter.get() >= maxRequest) {
return false;
} else {
timeStampList.add(now); // 当前出现成功请求,那么串上list
AtomicLong timeStampCounter = millToCount.getOrDefault(now, new AtomicLong(0L));
timeStampCounter.incrementAndGet();
millToCount.put(now, timeStampCounter);
counter.incrementAndGet();
return true;
}
}
}优点
- 简单易懂
- 精度高(通过调整时间窗口的大小来实现不同的限流效果)
缺陷
- 依旧存在临界问题,不可能无限小
- 占用更多内存空间
三、漏桶算法(固定消费速率)
漏桶限流算法(Leaky Bucket Algorithm)拥有更平滑的流量控制能力。其中漏桶是一个形象的比喻,这里可以用生产者消费者模式进行说明,请求是一个生产者,每一个请求都如一滴水,请求到来后放到一个队列(漏桶)中,而桶底有一个孔,不断的漏出水滴,就如消费者不断的在消费队列中的内容,消费的速率(漏出的速度)等于限流阈值。即假如 QPS 为 2,则每 1s / 2= 500ms 消费一次。漏桶的桶有大小,就如队列的容量,当请求堆积超过指定容量时,会触发拒绝策略。
类似于Kafka的消费者,在不调整配置的情况下,消费速度是固定的,多余的请求会积压,如果超过你kafka配置的topic最大磁盘容量,那么会丢消息。(topic是一个目录,topic下N个partition目录,假如你每个partition配置了1G的容量,那么超过这个这个容量,就会删除partition下的segement文件 xxx.index,xxx.log)

/**
* 漏桶算法
* 比如 1秒只能消费2个请求
*
* @author jeb_lin
* 15:55 2023/11/19
*/
public class LeakyBucketRateLimiter {
private int consumerRate; // 消费速度
private Long interval; // 时间间隔,比如1000ms
private int bucketCapacity; // 桶的容量
private AtomicLong water; // 桶里面水滴数量
public LeakyBucketRateLimiter(int consumerRate, Long interval, int bucketCapacity) {
this.consumerRate = consumerRate;
this.interval = interval;
this.bucketCapacity = bucketCapacity;
this.water = new AtomicLong(0);
scheduledTask();
}
// 周期任务,比如每1000ms消费2个请求
private void scheduledTask() {
ScheduledExecutorService service = Executors.newScheduledThreadPool(1);
service.scheduleAtFixedRate((Runnable) () -> {
for (int i = 0; i < consumerRate && water.get() > 0; i++) {
this.water.decrementAndGet();
}
System.out.println("water -> " + this.water.get());
}, 0, interval, TimeUnit.MILLISECONDS);
}
public static void main(String[] args) {
// 1000毫秒消费2个请求
LeakyBucketRateLimiter limiter = new LeakyBucketRateLimiter(2, 1000L, 10);
for (int i = 0; i < 10; i++) {
if (limiter.allow()) {
System.out.println(i + "-> ok");
} else {
System.out.println(i + "-> no");
}
}
}
private boolean allow() {
if (bucketCapacity < water.get() + 1) {
return false;
} else {
water.incrementAndGet();
return true;
}
}
}输出:
0 -> ok
1 -> ok
2 -> no
3 -> no
4 -> no
5 -> no
6 -> no
7 -> no
8 -> no
9 -> no优点
- 可以控制请求的处理速度,避免过载或者过度闲置,避免瞬间请求过多导致系统崩溃或者雪崩。
- 可以通过调整桶的大小和漏出速率来满足不同的限流需求(这个基本靠手动)
缺陷
- 需要对请求进行缓存,会增加服务器的内存消耗。
- 但是面对突发流量的时候,漏桶算法还是循规蹈矩地按照固定的速率处理请求。
四、令牌桶算法
令牌桶算法是一种常用的限流算法,相对于漏桶算法,它可以更好地应对突发流量和解决内存消耗的问题。该算法维护一个固定容量的令牌桶,每秒钟会向令牌桶中放入一定数量的令牌。当有请求到来时,如果令牌桶中有足够的令牌,则请求被允许通过并从令牌桶中消耗一个令牌,否则请求被拒绝。
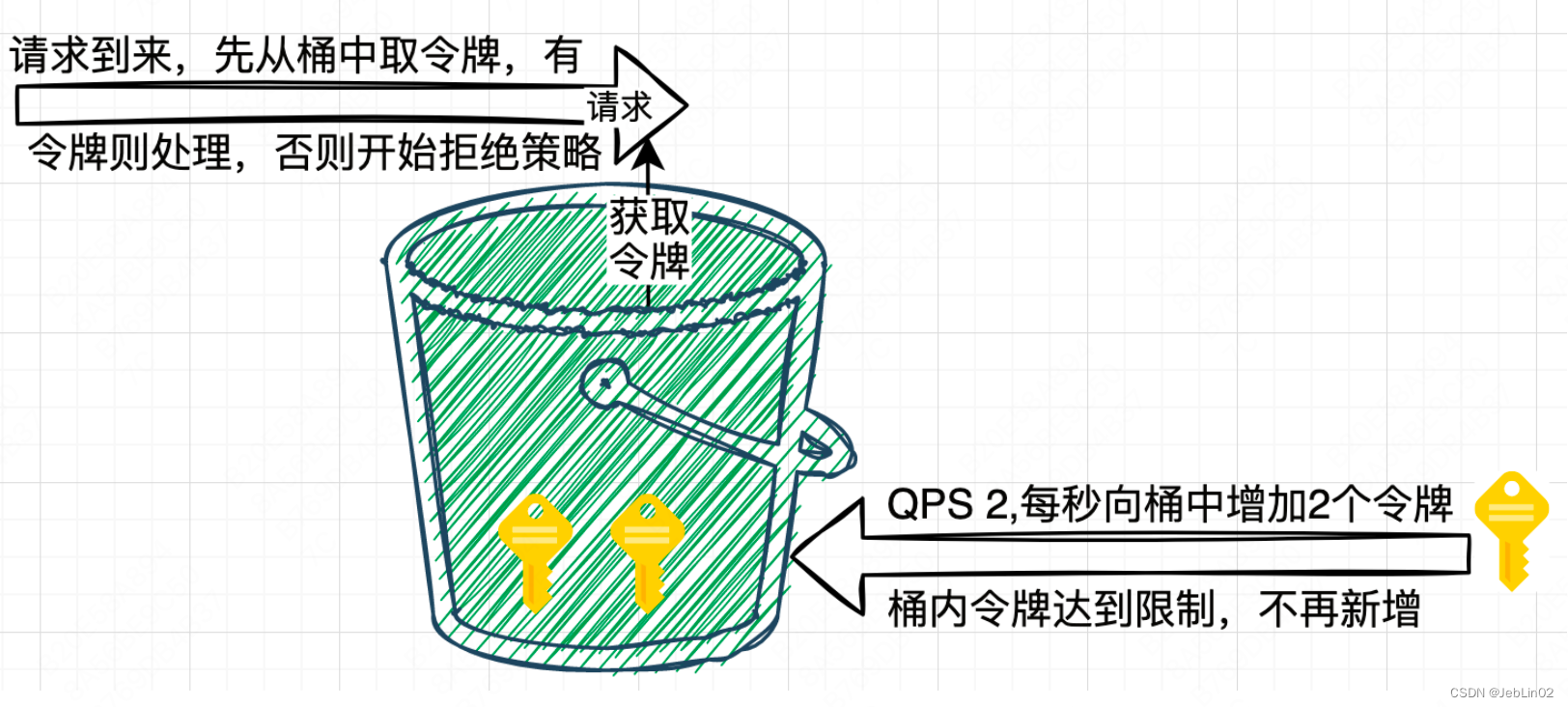
4.2 令牌桶限流代码实现
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
/**
* 令牌桶限流算法
* 每 1000ms 生成2个令牌
*
* @author jeb_lin
* 14:14 2023/11/19
*/
public class TokenBucketRateLimiter {
private long interval; // 窗口的时间间隔
private long rate; // 速率
private AtomicLong tokenCounter; // 令牌的数量
private final long bucketCapacity; // 桶的大小
public TokenBucketRateLimiter(long interval, long rate ,long bucketCapacity) {
this.interval = interval;
this.rate = rate;
this.tokenCounter = new AtomicLong(0);
this.bucketCapacity = bucketCapacity;
scheduledProduceToken();
}
private void scheduledProduceToken() {
ExecutorService executorService = Executors.newScheduledThreadPool(1);
((ScheduledExecutorService) executorService).scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
// 桶里面放不下了
if(tokenCounter.get() + rate > bucketCapacity){
System.out.println("bucket is full");
return;
}
long token = tokenCounter.addAndGet(rate);
System.out.println("token -> " + token);
}
}, 0, interval, TimeUnit.MILLISECONDS);
}
public static void main(String[] args) throws Exception {
testNormal();
}
/**
* 测试正常的情况
*/
private static void testNormal() throws Exception{
// 比如1000ms 允许通过10个请求
TokenBucketRateLimiter limiter = new TokenBucketRateLimiter(1000, 2,10);
// 模拟瞬时流量,5秒前都没请求,5秒后瞬时流量上来了
Thread.sleep(5000);
for (int i = 0; i < 12; i++) {
if (limiter.allow()) {
System.out.println(i + " -> ok ");
} else {
System.out.println(i + " -> no");
}
}
}
private boolean allow() {
if(tokenCounter.get() > 0){
tokenCounter.getAndDecrement();
return true;
}
return false;
}
}输出:
token -> 2
token -> 4
token -> 6
token -> 8
token -> 10
bucket is full
0 -> ok
1 -> ok
2 -> ok
3 -> ok
4 -> ok
5 -> ok
6 -> ok
7 -> ok
8 -> ok
9 -> ok
10 -> no
11 -> no优点
Guava的RateLimiter限流组件,就是基于令牌桶算法实现的。
- 精度高:令牌桶算法可以根据实际情况动态调整生成令牌的速率,可以实现较高精度的限流。
- 弹性好:令牌桶算法可以处理突发流量,可以在短时间内提供更多的处理能力,以处理突发流量。
缺陷
- 实现复杂:在短时间内有大量请求到来时,可能会导致令牌桶中的令牌被快速消耗完,从而限流。这种情况下,可以考虑使用漏桶算法。(需要削峰填谷,学习kafka就用漏桶算法)
- 时间精度要求高:令牌桶算法需要在固定的时间间隔内生成令牌,因此要求时间精度较高,如果系统时间不准确,可能会导致限流效果不理想。
五、集群限流
参考阿里的 cluster-flow-control | Sentinelcluster-flow-control![]() https://sentinelguard.io/zh-cn/docs/cluster-flow-control.html
https://sentinelguard.io/zh-cn/docs/cluster-flow-control.html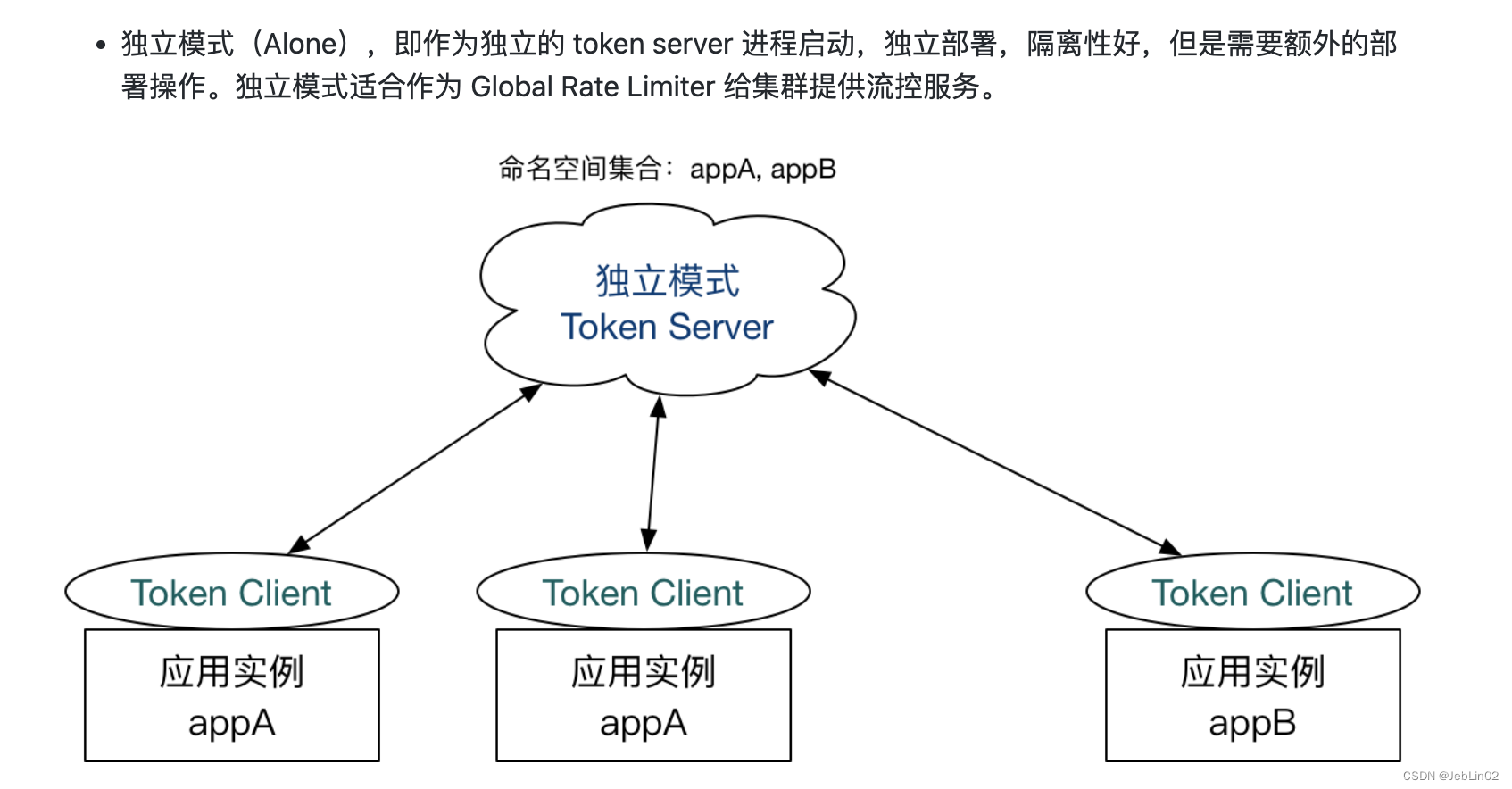
FQA
1、为什么要有集群限流?
假如我的商品A服务,有20台服务器,每台服务器设置了单机限流,比如说100QPS,那么集群的QPS应该是2000,但是由于流量分配不均导致有200QPS打到了同一台机器,此时就触发了限流。
2、为什么集群限流推荐独立部署的模式?
Sentinel 提供了独立部署模式和嵌入应用的模式,假如是使用嵌入模式,也就是我的商品A服务里面有一台服务器是需要提供总体Token统计工作的,那么很容易出现单机故障,也容易出现假死的现象。因为这台机器本身是有业务在身的,本身是有负载的。(相同的原理出现在ES的Node节点管理上,es的Node节点有Master节点和Data节点,Data节点负责document的index和query,Master节点专心干集群和index的管理工作,比如新增删除index,分工明确,假如Master的功能放在Data上,那么可能由于某一时间来了一条特殊的query命令需要进行复杂的计算或者返回大数据的话,或者gc等情况,那么这个Node节点可能无法对外提供服务,造成假死现象,那么这个Master就会重新选举,到时候可能出现脑裂的情况)
3、剩余令牌数量,在哪管理?
假如我的商品服务A的接口Interface-1 设置的集群限流是 1000QPS,那么当目前有500QPS的时候,剩余令牌数量A1tokenCounter可以理解为剩下500个,那么这个500维护在哪?
众所周知,Token Server的服务,不可能只有一台机器,分布式部署下为了系统的高可用,Token Server假如有10台机器,
a、那么是这10台 Token Server机器都维护了商品服务A的接口Interface-1的 A1tokenCounter 数据吗?
如果是,那么如何更新,数据如何同步到各台机器?
b、如果数据不是在10台Token Server维护的,而是在Redis中维护的,然后每次都去请求Redis,那么接下来的问题是,Redis也是有Master和N台Slaver ,你读的是Slaver机器,那么主从延迟情况下,你怎么保证QPS不会超出你设定的QPS?