redis 非关系型数据库
redis 非关系型数据库,缓存型数据库。
关系型数据库和非关系型数据库的区别
关系型数据库是一个机构化的数据库,行和列。
列:声明对象
行:记录对象属性。
表与表之间是有关联,使用sql语句,来对指定的表,库,进行增删改查。
在创建表时,我们是设计好了表的结构。按照表结构来存储数据。数据与表结构不匹配,存储数据,会失败。
非关系型数据库:nosql not only sql
不需要定义库,也不需要定义表的结构,直接记录即可,而且每条记录都可以由不同的数据类型,字段(字段个数)
redis key:value 建值对形式存储。每个键之间没有之间关联。库与库之间相互独立。
区别:
1,数据的存储方式不同。
2,扩展方式,性能上的提升。关系型数据库靠的是提升本机的性能。非关系型数据库,可以横向扩展,加入节点服务器的方式提高性能。
3,对事务的支持性,mysql支持事务。(原子性,隔离性,一致性,持久性)
非关系型数据库也支持事务,但是稳定性和处理能力都不如关系型数据库。
非关系型数据库的主要场景:
1,操作的扩展性
2,海量数据处理
web2.0:交互。
纯动态网站的三高问题:
1,对数据库高并发读写的需求。
2,对海量数据高效存储与访问的需求。
3,对数据库的高可扩展性与高可用性的需求。
数据库缓存:
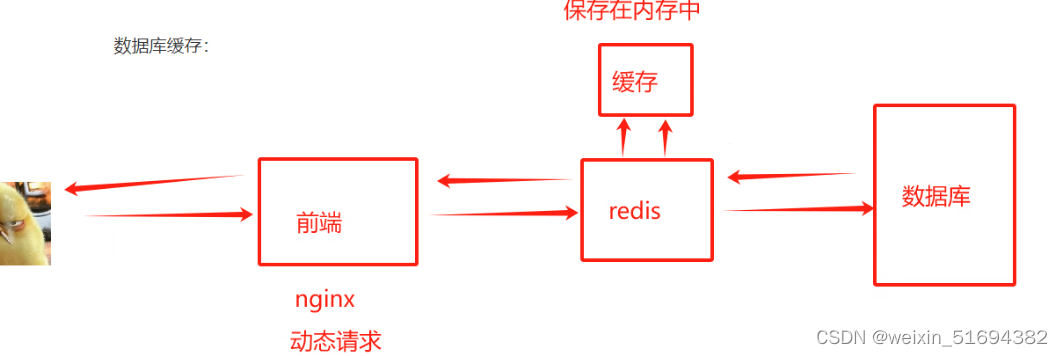
web页面缓存
cpu和硬盘之间缓存
常见的缓存需求场景
关系型数据库:
库----表---行,列----->存储数据
非关系型数据库:
库----集合----->保存键值对
他不需要是手动的创建库和集合。
redis:开源的,使用c语言编写的NQL数据库。
redis:基于内存运行,支持持久化(数据恢复)。采用的就是key-value(键值对)的存储形式。目前在分布式架构中,非常重要的一环。

redis服务器程序,是一个单进程模式,即只有一个主进程工作。也就是说在一台服务器上可以启动多个redis(端口号不能冲突)
redis的实际处理速度是完全依靠主进程的执行效率。
服务器只部署了一个redis进程,多个客户端访问,可能会导致redis的处理能力下降
如果部署了多个redis进程,虽然能提高redis的并发处理能力,但是会给服务器的cpu带来很大的压力。
一台服务器,一般部署3个redis进程。(根据情况来看,高并发,要部署多个。一般情况,单进程足够了)
redis的特点:
1,具有极高的读写速度,数据读取每秒110000次,写入数据每秒可执行81000的写入。
2,支持丰富的数据类型。
3,支持持久化。平常的数据都是保存在内存中,持久化可以写入到磁盘中,即可以保存到本地,也可以实现备份。
4,原子性,所有的操作都是原子性
5,支持主从模式---master-slave模式。
redis为什么这么快?应届 面试题
1,redis是纯内存结构,避免了磁盘I/O的耗时
2,核心模块是一个单进程,减少了线程切换和回收线程的时间。
3,I/O的多路复用机制。每一个执行线路,都可以同时读和写。高并发的效率大大提升。
特殊说明:redis的读写,仍然是单进程处理。
redis的服务控制命令:
/etc/init.d/redis_6379 status 状态
/etc/init.d/redis_6379 restart 重启
redis的命令工具:
redis-server:直接启动redis,只能启动
redis-benchmark:检测redis在本机的运行效率
redis-cil:命令行工具
redis-check-aof:检测AOF文件是否正常
redis-check-rdb:检测rdb文件是否正常
redis-benchmark:
-h:指定服务器的主机名 IP地址
-p:指定服务器的端口号
-c:指定并发连接数
-n:指定请求数。
redis-benchmark -h 192.168.176.80 -p 6379 -c 100 -n 10000 连接请求测试
redis-benchmark -h 192.168.176.80 -p 6379 -q -d 100 存取数据包的能力
redis-benchmark -t set,lpush -n 100000 -q 测试性能
一,如何进入redis
1,redis-cli -h 192.168.176.80 -p 6379 登录指定
-h 指定IP地址
-p 指定端口号
-a 指定登录密码
2,redis-cli 仅限于本地,远程登录还是要指定IP地址
二,redis的数据类型:
五大数据类型:
1,string(字符串):也是redis的最基本的类型,最大能存储512MB的数据,可以存储任何数据,数字,图片,文字,等等。
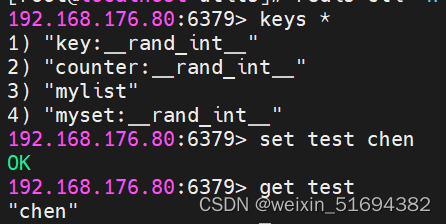
keys * :查看所有键值
*:表示所有
?:表示后面任意一位
创建键值: set test chen
读取键值:get test
修改键值 set test 10
判断键值对是否存在
exists test
1:存在 0:不存在
删除:del test
如何查看对应键值对的类型
type test
拼接字符串
没有,直接输入,显示当前长度
有,拼接字符串返回所有长度
append test1 hello

直接查看长度:strlen test1
incr test 递增1
decr test 递减1
只能改数字
incrby test 10 增加10
decrby test 10 减10
设置键值对生命周期:
setex test2 15 lo
ttl test2 查看键值对的生命周期
(integer)-2:结束
-1:表示永不过期
修改生命周期
expire test 30
创建多个:
mset key1 hello key2 world
打印多个:MGET key1 key2
2,list 数据类型
列表
创建列表
倒叙插入
lpush chen a b c 1 2 3
正序插入:
rpush cg 1 2 3 4
以下标查看:
lrange chen 0 -1
lindex chen 0 查看第0个
添加:
在前面添加:
lpushx cg 10
在后面添加
rpushx cg 5
删除:
lpop cg 删除第一个
rpop cg 删除最后一个
修改下标为3的元素
lset cg 3 shuai
在指定元素前后进行插入
linsert chenc before 3 10
linsert chenc after 3 11
三,hash类型:
hash类型用于存储对象,采用hash格式来进行操作。占用的磁盘空间少,而且一个hash可以存储4294967295个键值对。
创建:
hset cc tall yes
查看:
hget cc tal
添加新字段:
hset cc handsan yes
打印多个
hmget cc tall handsan
删除:
hdel cc tall


一次性设置多个字段
hmset chc tall yes age 21 ah 阿斯顿
中文会显示乱码
打印:
hmget chc tall age ah
直接查看全部键字段名,值
hgetall chc
分开查看
键字段名:hkeys chc
键值:hvals chc
删除:del cg
四,set 数据类型(无序集合)
元素类型也是string,元素是唯一的,不允许重复。多个集合类型可以进行并集。交集和差集运算。
set当中的元素类型是唯一的,可以跟踪一些唯一性数据。访问微博的用户名。只要把对应名称写入redis,set集合可以自动保存唯一性,保证下次访问
flushall 删除redis所有库
创建 (重复的不算)
sadd myset a a c
查看:
smembers myset

查看集合有没有指定元素
sismember myset c
1,存在 0,不存在
添加元素:
sadd myset b d e f
移除
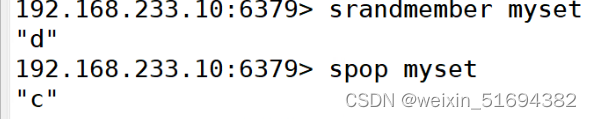
随机移除:
srandmember myset
spop myset
指定移除:
srem myset a c
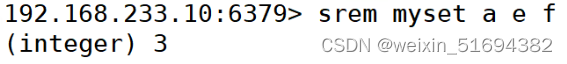
五,有序集合:元素类型也是string,元素唯一不能重复。
每个元素都会关联一个double(小数点)的分数(score,表示权重)可以通过权重的大小。进行排序。元素的权重可以重复
zset
在线积分的排行榜,可以实时更新用户的分数。zrange命令获取积分top10的用户。zrank命令通过username来获取用户的排行信息。
创建:
zadd myzset 1 one
添加:
zadd myzset 2 two 3 three
查看
加withscores 才显示权重
zrange myzset 0 -1 withscores
查看元素的排名:
zrank myzset one
查看集合有多少元素
zcard myzset

![]()
统计权重范围之内元素的个数:
zcount myzset 1 3
删除成员
zrem myzset three
查看元素权重:
zscore myzset two
set和hset 创建普通类型和hash类型,怎么选择?
一般情况下,如五特殊需求,普通的创建方式即可
对一个键进行多字段存储,节省内存,使用hash方式。
如何对key进行重命名
rename test chen
查看当前库中的键值对数:
dbsize
redis的库 库都是创建好的,16个库
数字排名:0-15
切换库
select 1
把当前库移到其他库中
move test 1
如何给库创建密码:
config set requirepass 123456
再次进入不加密码看不了数据
在内进入
auth 123456
在外进入加 -a 123456
redis-cli -h 192.168.176.71 -p 6379 -a 123456
如何情况库数据
flushdb:情空当前库(不要用,慎用)
flushall:清空全部库(不要用,慎用)
总结:
redis的特点:读写速度快。
数据类型:
1,string
2,list
3,hash 对一个键进行多字段存在要用hash节省空间
4,无序集合 set 元素不能重复,可以用来定义唯一值
5,有序集合 zset,元素不能重复,但是权重可以相同,用来排名