使用Jupyter Notebook调试PySpark程序错误总结
项目场景:
在Ubuntu16.04 hadoop2.6.0 spark2.3.1环境下
简单调试一个PySpark程序,中间遇到的错误总结(发现版对应和基础配置很重要)
注意:在前提安装配置好
hadoop hive anaconda jupyternotebook spark zookeeper
(有机会可以安排一下教程)
问题:
pyspark发现没有出现spark图标
cuihaipeng01@hadoop1:~$ pyspark
Python 3.7.6 (default, Jan 8 2020, 19:59:22)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/apps/spark/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/apps/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2023-11-17 14:14:21 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Traceback (most recent call last):
File "/apps/spark/python/pyspark/shell.py", line 45, in <module>
spark = SparkSession.builder\
File "/apps/spark/python/pyspark/sql/session.py", line 173, in getOrCreate
sc = SparkContext.getOrCreate(sparkConf)
File "/apps/spark/python/pyspark/context.py", line 343, in getOrCreate
SparkContext(conf=conf or SparkConf())
File "/apps/spark/python/pyspark/context.py", line 118, in __init__
conf, jsc, profiler_cls)
File "/apps/spark/python/pyspark/context.py", line 186, in _do_init
self._accumulatorServer = accumulators._start_update_server()
File "/apps/spark/python/pyspark/accumulators.py", line 259, in _start_update_server
server = AccumulatorServer(("localhost", 0), _UpdateRequestHandler)
File "/apps/anaconda3/lib/python3.7/socketserver.py", line 452, in __init__
self.server_bind()
File "/apps/anaconda3/lib/python3.7/socketserver.py", line 466, in server_bind
self.socket.bind(self.server_address)
socket.gaierror: [Errno -2] Name or service not known
>>>
原因分析:
注意到这句话
socket.gaierror: [Errno -2] Name or service not known导致这个问题的原因有:
1.SPARK_MASTER_IP没有指定2.没有导入pyspark库
1.检查SPARK_MASTER_IP
编辑spark-env.sh配置文件
vim /apps/spark/conf/spark-env.shexport SPARK_DIST_CLASSPATH=$(/apps/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/apps/hadoop/etc/hadoop
export JAVA_HOME=/apps/java
export SPARK_MASTER_IP=cuihaipeng01
发现我的配置是没有问题的,我这里的cuihaipeng01是我映射的主机名,对应的ip是没有问题的,于是排除了这个问题。
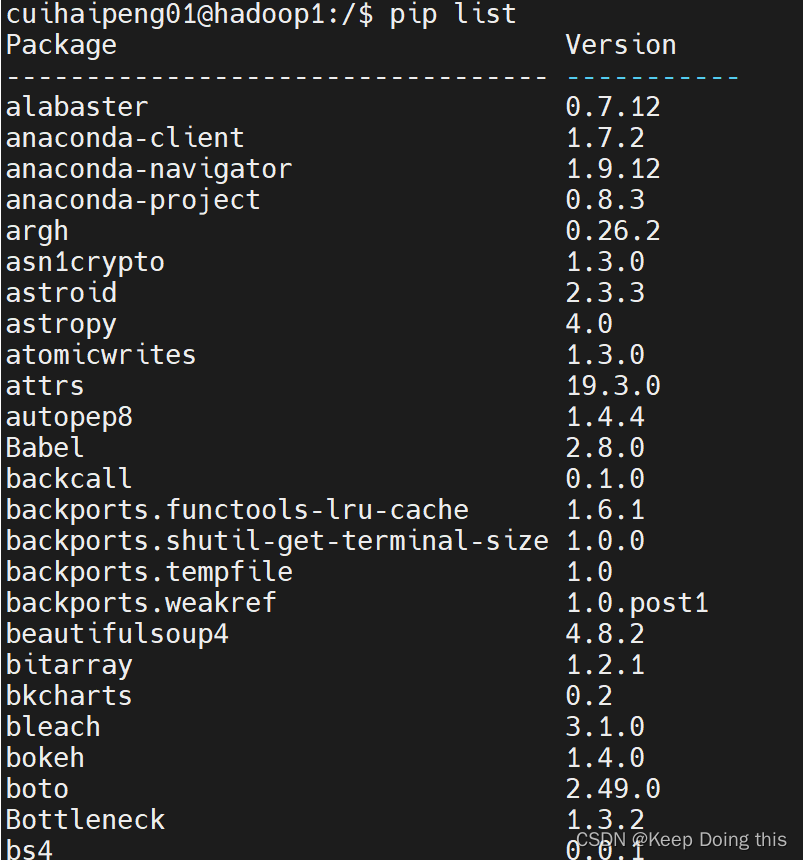
2.检查是否导入pyspark库
用pip list命令查看python库
解决方案:
发现没有pyspark库,于是发现了问题所在,于是有了下面的问题
(这里一定要指定版本:对应自己的spark版本就可以,比如spark2.3.1 那就下载 pyspark2.3.1)
用pip install pystark 发现报错,即使带了镜像也有问题,后来查资料说是因为资源库在国外用了
解决方法:国内的资源库
pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com pyspark==2.3.1发现还是不行,报别的错误了

解决方法:下载finspark库和requests库
pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com findsparkpip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com requests
最后再次执行:
pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com pyspark==2.3.1安装成功

再次执行pyspark
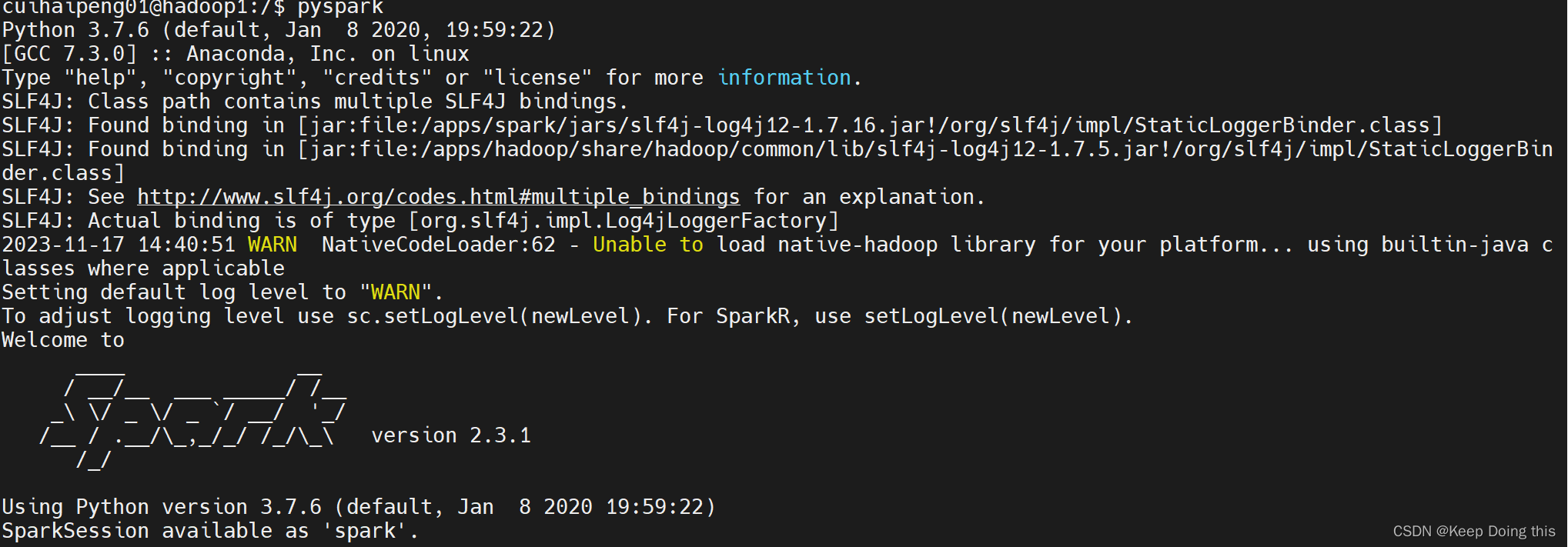
这里发现一个警告,但是查看~/.bashrc下发现配置是没有问题的
#hadoop
export HADOOP_HOME=/apps/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
于是直接在ubuntu上执行了pyspark进行测试
创建test.py
import findspark
findspark.init()
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("spark://cuihaipeng01:7077").setAppName("My App").set("spark.ui.port", "4050")
sc = SparkContext(conf = conf)
logFile = "file:///apps/spark/README.md"
logData = sc.textFile(logFile, 2).cache()
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))这里的 "spark://cuihaipeng01:7077"是我指定的spark-master,因为我搭建的是四台主机,一台master和三台slave
本地的可以是local
启动pyspark后重新打开一个终端执行文件
python3 ~/test.py
在jupyter notebook上执行pyspark程序:
重新打开一个终端执行
jupyter notebook
执行过程:
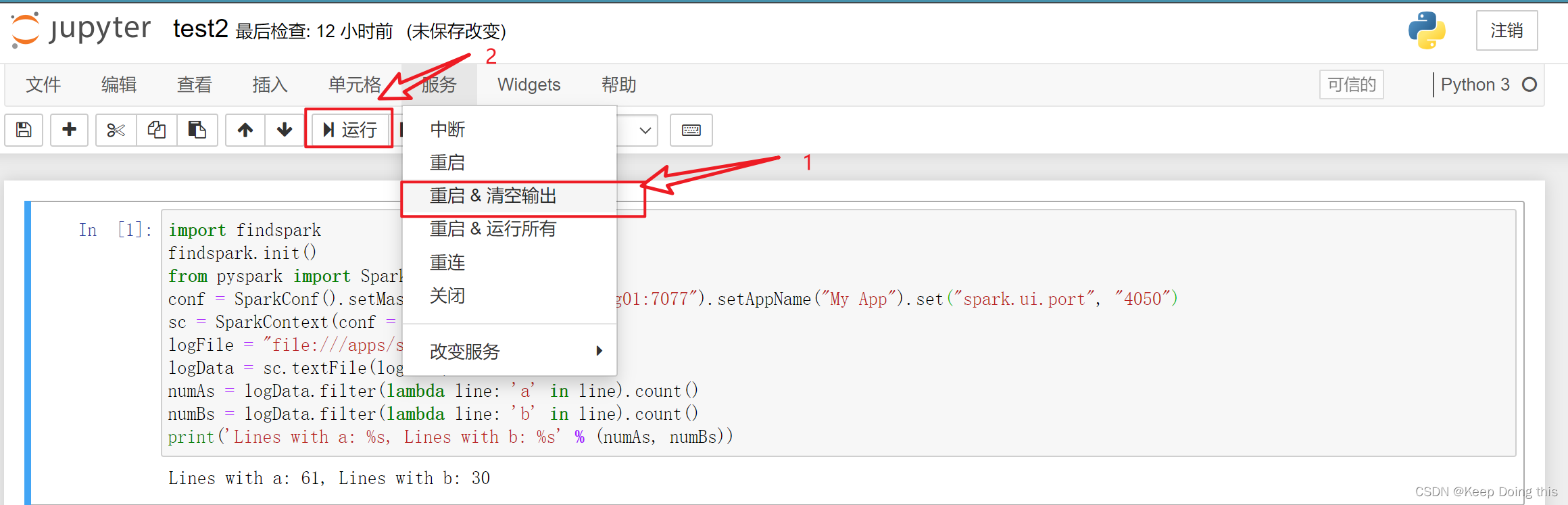
执行成功