OpenCV快速入门:图像分析——图像分割和图像修复
文章目录
- 前言
- 一、图像分割
- 1.1 漫水填充法
- 1.1.1 漫水填充法原理
- 1.1.2 漫水填充法实现步骤
- 1.1.3 代码实现
- 1.2 分水岭法
- 1.2.1 分水岭法原理
- 1.2.2 分水岭法实现步骤
- 1.2.3 代码实现
- 1.3 GrabCut法
- 1.3.1 GrabCut法原理
- 1.3.2 GrabCut法实现步骤
- 1.3.3 代码实现
- 1.4 Mean-Shift法
- 1.4.1 Mean-Shift法原理
- 1.4.2 Mean-Shift法实现步骤
- 1.4.3 代码实现
- 二、图像修复
- 2.1 图像修复原理
- 2.1.1 Telea方法
- 2.1.2 Navier-Stokes方法
- 2.1.3 代码实现
- 2.2 修补算法
- 2.2.1 修补算法原理
- 2.2.2 修补算法实现步骤
- 2.2.3 OpenCV代码实现
- 2.2.3.1 方形补丁修补
- 2.2.3.2 圆形补丁修补
- 总结
前言
OpenCV(Open Source Computer Vision Library)作为一个开源的计算机视觉和机器学习软件库,提供了丰富的图像处理功能,使得图像分析变得更加高效和易于实现。本篇博客旨在提供一个关于OpenCV中图像分割和图像修复技术的入门指南,从基本原理到代码实现,简要覆盖这些技术的关键方面。

一、图像分割
图像分割是图像处理中的一项重要技术,它涉及将图像划分为多个部分或区域,以便更容易地分析和处理。
1.1 漫水填充法
1.1.1 漫水填充法原理
漫水填充 (Flood Fill)算法基于区域生长的概念。它从图像中的一个点(种子点)开始,然后向所有与该点相连的、颜色/强度相似的区域扩展。
1.1.2 漫水填充法实现步骤
- 选择一个种子点。
- 检查相邻像素是否属于同一区域(基于颜色/强度相似度)。
- 如果相邻像素符合条件,则包括它,并继续向外扩展。
- 重复此过程直到无法扩展。
1.1.3 代码实现
import cv2
import numpy as np
# 读取图像
image = cv2.imread('tulips.jpg')
# 创建一个与图像大小相同的掩码(mask),并初始化为全0
mask = np.zeros((image.shape[0] + 2, image.shape[1] + 2), dtype=np.uint8)
# 定义填充的起始点
start_point1 = (100, 100) # 开始填充的坐标
start_point2 = (420, 200) # 开始填充的坐标
# 定义填充颜色
fill_color = (0, 0, 0) # 黑色
# 定义颜色容差范围
tolerance = (160, 160, 160, 160) # 上下左右的容差
# floodFill函数的参数
flood_fill_flags = 4
flood_fill_flags |= 255 << 8
flood_fill_flags |= cv2.FLOODFILL_FIXED_RANGE
# 调用floodFill函数
image_fill = image.copy()
cv2.floodFill(image_fill, mask, start_point1, fill_color, tolerance, tolerance, flood_fill_flags)
cv2.floodFill(image_fill, mask, start_point2, fill_color, tolerance, tolerance, flood_fill_flags)
# 显示结果
mask_img = cv2.merge([mask,mask,mask])
# 获取图像的高度和宽度
height, width ,channel= image.shape
# 创建一个新的图像,高度和宽度各增加一
new_height = height + 2
new_width = width + 2
image_origin = np.zeros((new_height, new_width, channel), dtype=np.uint8)
# 将原始图像复制到新图像中
image_origin[:height, :width] = image
image_flood = np.zeros((new_height, new_width, channel), dtype=np.uint8)
# 将原始图像复制到新图像中
image_flood[:height, :width] = image_fill
cv2.imshow('Flood Filled Image', cv2.hconcat([image_origin,image_flood, mask_img]))
cv2.waitKey(0)
cv2.destroyAllWindows()

cv2.floodFill 函数用于实现漫水填充算法,即填充一个连通区域的颜色或图案。这个函数非常适合于图像分割、对象检测和图像编辑等任务。下面是对 cv2.floodFill 函数参数和功能的简要介绍:
def floodFill(image, mask, seedPoint, newVal, loDiff=None, upDiff=None, flags=None)
image: 输入/输出图像。这是一个单通道或三通道的8位或浮点图像。除非设置了
FLOODFILL_MASK_ONLY标志,否则此函数会修改输入图像。mask: 操作掩码,应该是一个单通道8位图像,比输入图像宽2个像素,高2个像素。这是一个输入和输出参数,因此在使用前需要初始化。漫水填充不能穿过掩码中非零的像素。例如,边缘检测器的输出可以作为掩码,以阻止填充穿过边缘。
seedPoint: 开始点。这是漫水填充开始的像素位置。
newVal: 重新绘制域像素的新值。
loDiff 和 upDiff: 分别代表最大下限和上限的亮度/颜色差异。这些参数决定了填充颜色与周围像素颜色的最大允许差异。
rect: 可选的输出参数,函数设置为重新绘制域的最小边界矩形。
flags: 操作标志。前8位包含连接值,4代表只考虑四个最近邻像素(那些共享边的像素),8代表将考虑八个最近邻像素(那些共享角的像素)。接下来的8位(8-16位)包含用来填充掩码的值(默认值为1)。例如,4 | (255 << 8) 将考虑4个最近邻居,并用255的值填充掩码。
这个函数通过比较像素与其邻居或种子点的颜色/亮度差异来确定哪些像素属于同一连接组件,并将这些像素填充为新的颜色或值。在实际应用中,需要根据具体的图像和需求调整参数,以达到最佳的填充效果。
1.2 分水岭法
1.2.1 分水岭法原理
分水岭(Watershed)算法模拟地理学中的水流原理。在图像中,任何灰度值可以看作高度,算法模拟雨水流入低洼地区,形成不同的“湖泊”,每个湖泊代表图像的一个分割区域。
1.2.2 分水岭法实现步骤
- 对图像应用边缘检测,例如使用Canny算法。
- 应用距离变换。
- 应用分水岭算法分割图像。
1.2.3 代码实现
import cv2
import numpy as np
# 读取图像
image = cv2.imread('tulips.jpg')
# 转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用阈值化来标记前景区域
_, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 去除噪声
kernel = np.ones((7, 7), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# 确定背景区域
sure_bg = cv2.dilate(opening, kernel, iterations=6)
# 确定前景区域
dist_transform = cv2.distanceTransform(opening, cv2.DIST_L2, 5)
_, sure_fg = cv2.threshold(dist_transform, 0.8 * dist_transform.max(), 255, 0)
# 找到未知区域
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg, sure_fg)
# 标记标签
_, markers = cv2.connectedComponents(sure_fg)
# 增加1以确保背景不是0,而是1
markers = markers + 1
# 标记未知区域为0
markers[unknown == 255] = 0
# 应用分水岭
cv2.watershed(image, markers)
image[markers == -1] = [255, 255, 255]
# 遍历所有的标记
for marker in np.unique(markers):
if marker == 0 or marker == -1:
# 忽略背景和边界
continue
# 创建一个掩码,使得当前标记区域为白色,其他区域为黑色
mask = np.zeros(gray.shape, dtype=np.uint8)
mask[markers == marker] = 255
# 应用掩码到原始图像
segmented_image = cv2.bitwise_and(image, image, mask=mask)
# 显示提取的区域
cv2.imshow(f'Segmented area {marker}', segmented_image)
# 显示结果
cv2.imshow('Segmented Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
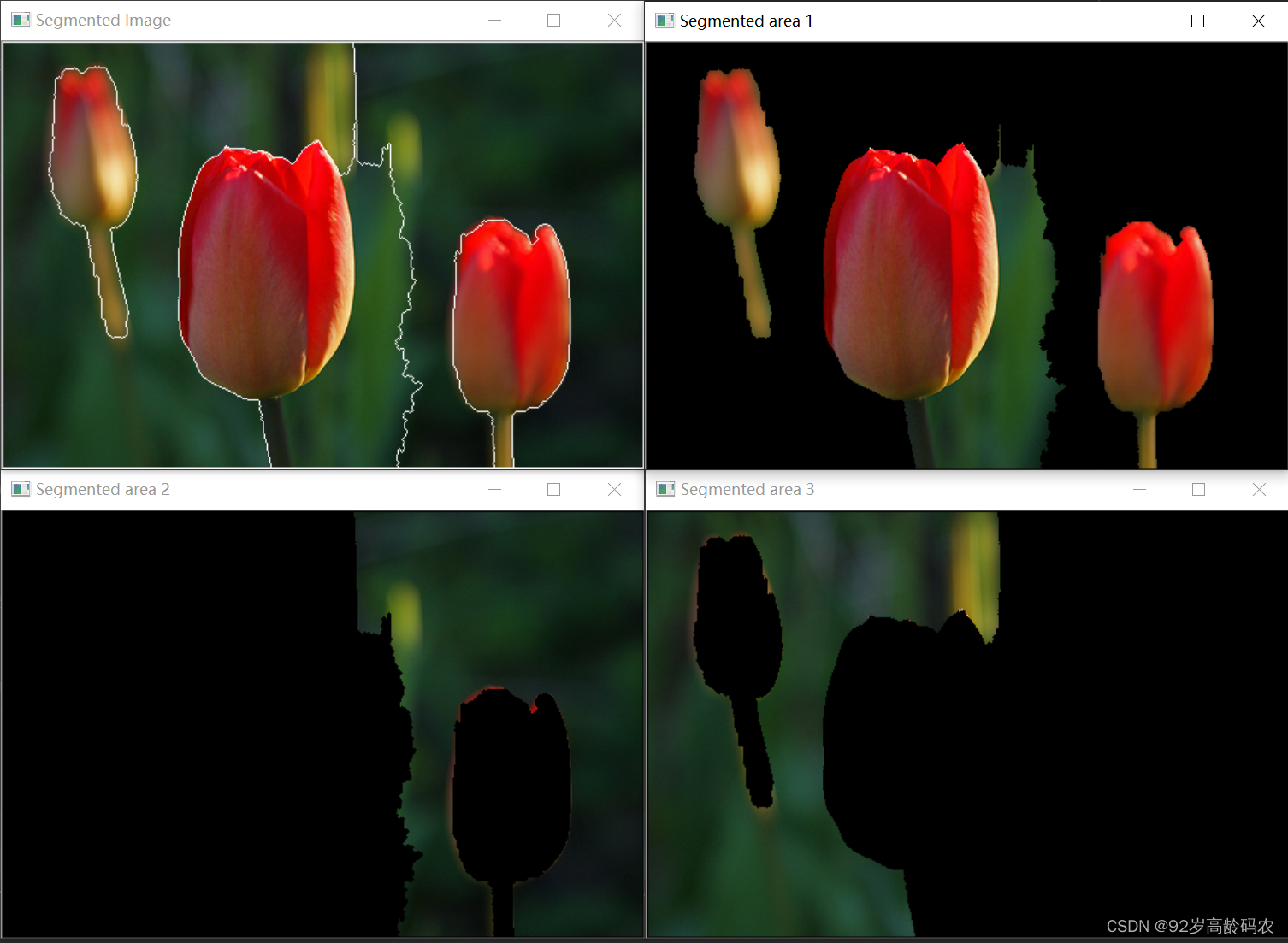
cv2.watershed 用于基于标记的图像分割的函数,实现了一种变体的分水岭算法。这个函数的关键功能是将图像分割成多个区域,这些区域基于提供的标记来确定。
def watershed(image, markers)
image: 输入参数。这是一个8位的3通道图像,即一般的彩色图像。这个图像是要应用分水岭算法进行分割的图像。
markers: 输入/输出参数。这是一个32位单通道图像,代表标记。它的大小应该与
image相同。在输入时,markers图像中应该有正值(>0)标记出预期分割区域的大致轮廓。每个区域由一个或多个连接组件表示,像素值为1、2、3等。函数处理后,markers中的每个像素将被设置为其所属“种子”组件的值,或在区域边界处被设置为-1。
- 正值(>0): 表示不同的对象或区域。
- 零值(0): 表示这些像素的归属尚未确定,需要算法来定义。
- 负值(-1): 在函数输出中,这表示不同区域之间的边界。
cv2.watershed 函数的目的是根据提供的标记,将图像分割成不同的区域。这对于图像分割、对象识别和计算机视觉应用特别有用。在实际应用中,通常需要先对图像进行预处理(如边缘检测、阈值化等),然后生成合适的标记图像,最后应用这个函数进行分割。
1.3 GrabCut法
1.3.1 GrabCut法原理
GrabCut是一种基于图论的图像分割方法,使用用户定义的前景和背景区域来初始化分割。算法通过迭代方式优化每个像素属于前景或背景的概率。
1.3.2 GrabCut法实现步骤
- 用户定义前景和背景区域。
- 算法初始化并迭代更新每个像素的标签(前景或背景)。
- 使用GMM(高斯混合模型)对颜色分布建模。
- 利用图割算法优化像素标签。
1.3.3 代码实现
import cv2
import numpy as np
# 读取图像
image = cv2.imread('tulips.jpg')
# 定义前景和背景模型
mask = np.zeros(image.shape[:2], np.uint8)
bgdModel = np.zeros((1, 65), np.float64)
fgdModel = np.zeros((1, 65), np.float64)
# 定义矩形(用户定义的前景区域)
rect = (100, 50, 200, 300)
# 应用GrabCut
cv2.grabCut(image, mask, rect, bgdModel, fgdModel, 1, cv2.GC_INIT_WITH_RECT)
# 提取前景和可能的前景区域
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8')
image = image * mask2[:, :, np.newaxis]
# 显示结果
cv2.imshow('GrabCut Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
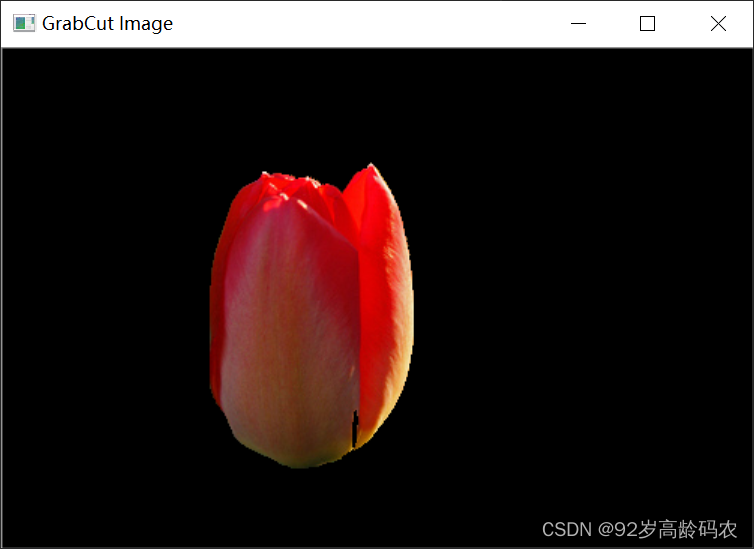
cv2.grabCut 实现了 GrabCut 算法,这是一种用于图像分割的迭代算法。GrabCut 算法可以有效地从图像中分离前景(目标对象)和背景。
def grabCut(img, mask, rect, bgdModel, fgdModel, iterCount, mode=None)
img: 输入参数。这是一个8位的3通道图像,即一般的彩色图像。这个图像是要应用 GrabCut 算法的对象。
mask: 输入/输出参数。这是一个8位单通道的掩码图像。掩码的元素可以是
GrabCutClasses中的一个,表示像素的不同分类(如明确的背景、可能的背景、明确的前景、可能的前景)。当mode设置为GC_INIT_WITH_RECT时,函数会初始化这个掩码。rect: 输入参数,表示包含分割对象的感兴趣区域(ROI)。当
mode == GC_INIT_WITH_RECT时使用此参数。ROI 外的像素被标记为“明确的背景”。bgdModel: 输入/输出参数。这是用于背景模型的临时数组。处理同一图像时不应修改它。
fgdModel: 输入/输出参数。这是用于前景模型的临时数组。处理同一图像时不应修改它。
iterCount: 输入参数,表示算法应该执行的迭代次数。
mode: 输入参数,操作模式,可以是
GrabCutModes中的一个。常见模式包括GC_INIT_WITH_RECT(使用矩形初始化)和GC_INIT_WITH_MASK(使用掩码初始化)。
cv2.grabCut 函数的主要用途是通过迭代方式将图像中的目标对象与背景分离。这在图像编辑、计算机视觉和对象识别等领域非常有用。函数的实现方式是先用一个矩形粗略地标记出感兴趣的对象,然后算法迭代地改进前景和背景的分割。
1.4 Mean-Shift法
1.4.1 Mean-Shift法原理
Mean-Shift算法是一种基于特征空间分析的非参数密度估计技术。在图像分割的上下文中,它通常用于基于颜色的聚类。
1.4.2 Mean-Shift法实现步骤
- 在特征空间(例如颜色空间)中选择一个窗口。
- 计算窗口内所有点的均值。
- 移动窗口到均值位置。
- 重复步骤2和3,直到收敛。
1.4.3 代码实现
import cv2
# 读取图像
image = cv2.imread('tulips.jpg')
# 转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用Canny边缘检测
edges = cv2.Canny(gray, 50, 150)
# Mean-Shift 参数
spatial_radius = 20 # 空间窗口大小
color_radius = 40 # 颜色窗口大小
max_pyramid_level = 2 # 金字塔层数
# 应用Mean-Shift算法
result = cv2.pyrMeanShiftFiltering(image, spatial_radius, color_radius, max_pyramid_level)
# 转换为灰度图
gray = cv2.cvtColor(result, cv2.COLOR_BGR2GRAY)
# 应用Canny边缘检测
result_edges = cv2.Canny(gray, 50, 150)
# 显示结果
img_edges = cv2.merge([edges,edges,edges])
img_result_edges = cv2.merge([result_edges,result_edges,result_edges])
cv2.imshow('Mean-Shift Segmentation', cv2.vconcat([
cv2.hconcat([image, img_edges]),
cv2.hconcat([result,img_result_edges])
]))
cv2.waitKey(0)
cv2.destroyAllWindows()
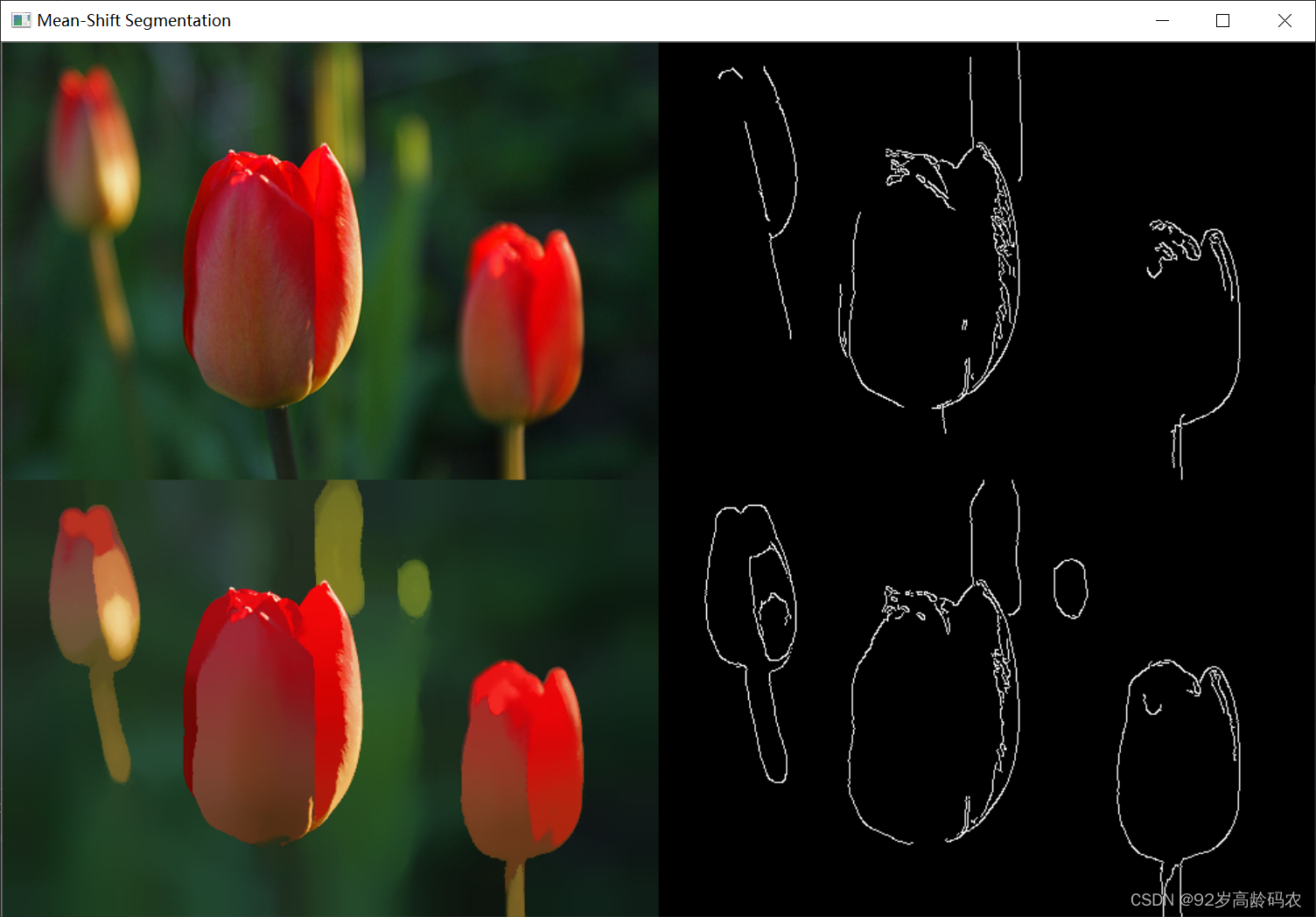
cv2.pyrMeanShiftFiltering 用于执行图像分割的 Mean-Shift 算法的函数。这个函数主要用于平滑图像的颜色梯度,同时保留边缘信息,从而对图像进行“平面化”处理。以下是对 cv2.pyrMeanShiftFiltering 函数的参数和功能的简要介绍:
def pyrMeanShiftFiltering(src, sp, sr, dst=None, maxLevel=None, termcrit=None)
src: 输入参数,源图像。这是一个8位的3通道图像,即一般的彩色图像。
sp: 输入参数,空间窗口半径。这个参数决定了像素邻域的大小。在此邻域内进行Mean-Shift迭代。
sr: 输入参数,颜色窗口半径。这个参数决定了颜色空间中像素邻域的大小,用于在颜色空间内聚类。
dst: 输出参数,目标图像。这是处理后的图像,格式和大小与源图像相同。
maxLevel: 可选输入参数,金字塔的最大层级。当这个值大于0时,算法首先在金字塔的最小层上执行,然后结果被传播到更大的层上。
termcrit: 可选输入参数,终止条件。它决定了Mean-Shift迭代何时停止。
cv2.pyrMeanShiftFiltering 函数的主要功能是对图像进行分割和平滑处理,同时保留边缘。在空间和颜色空间中,函数对每个像素进行迭代,直到满足终止条件。这个过程可以帮助去除图像的细节和噪声,同时保留主要的结构信息。这种方法在图像分割和对象识别等应用中非常有用。在实际使用时,sp 和 sr 参数需要根据具体的应用场景和图像内容进行调整。
二、图像修复
在图像处理领域,图像修复是一项至关重要的技术,它涉及修复图像中的损坏部分或去除不需要的对象。
2.1 图像修复原理
图像修复 (Inpainting)是一种用于修复图像中损坏区域的技术。它通过分析周围的像素来重建缺失或损坏的部分。OpenCV提供了两种主要的Inpainting技术:Telea方法和Navier-Stokes方法。
2.1.1 Telea方法
Telea方法是一种基于快速行进算法的图像修复技术。这种方法的核心思想是从损坏区域的边缘开始,逐步向内部填充,直到整个区域被修复完毕。
原理
Telea方法的关键在于它如何选择用于填充缺失区域的像素值。它考虑到了边缘周围像素的信息,并基于这些信息来估计缺失像素的最佳值。具体而言,该方法依赖于周围像素的几何距离和光强差异来计算修复值。
应用
Telea方法非常适合于修复小到中等大小的损坏区域。由于其基于边缘信息进行填充,因此在修复裂缝或小孔等缺陷时表现尤为出色。
2.1.2 Navier-Stokes方法
Navier-Stokes方法是另一种流行的图像修复技术。它基于流体动力学中的Navier-Stokes方程,适用于重建更大区域的图像。
原理
这种方法将图像修复问题视为一个流体动力学问题,其中图像的每个像素都被视为流体粒子。它利用Navier-Stokes方程来模拟流体粒子的运动,从而估算缺失区域的像素值。
应用
Navier-Stokes方法特别适用于大面积损坏的修复,例如修复破损的古老照片或艺术作品中的大片缺失部分。该方法能够有效地重建图像的结构和纹理信息,使修复后的区域与周围环境融合得更自然。
2.1.3 代码实现
import cv2
import numpy as np
def inpaint_image(image, mask, inpaint_radius=3):
restored_telea = cv2.inpaint(image, mask, inpaint_radius, cv2.INPAINT_TELEA)
restored_ns = cv2.inpaint(image, mask, inpaint_radius, cv2.INPAINT_NS)
return restored_telea, restored_ns
# 加载图像
image = cv2.imread('tulips.jpg')
# 创建第一个掩模,用于模拟损坏的区域
mask1 = np.zeros(image.shape[:2], np.uint8)
mask1[40:60, 50:550] = 255 # 水平损坏区域
mask1[60:260, 300:320] = 255 # 垂直损坏区域
mask1[200:220, 100:300] = 255 # 水平损坏区域
# 创建第二个掩模,用于模拟损坏的区域
mask2 = np.zeros(image.shape[:2], np.uint8)
cv2.circle(mask2, (395, 215), 80, 255, -1) # 圆形损坏区域
# 应用掩模,模拟损坏
damaged_image1 = image.copy()
damaged_image1[mask1 == 255] = [0, 0, 0]
damaged_image2 = image.copy()
damaged_image2[mask2 == 255] = [0, 0, 0]
# 使用封装的函数进行修复
restored_telea1, restored_ns1 = inpaint_image(damaged_image1, mask1)
restored_telea2, restored_ns2 = inpaint_image(damaged_image2, mask2)
# 显示结果
horizontal_stack1 = np.hstack((damaged_image1, restored_telea1, restored_ns1))
horizontal_stack2 = np.hstack((damaged_image2, restored_telea2, restored_ns2))
vertical_stack = np.vstack((horizontal_stack1, horizontal_stack2))
cv2.imshow('Restored Image Telea and Navier-Stokes', vertical_stack)
cv2.waitKey(0)
cv2.destroyAllWindows()

cv2.inpaint 用于修复图像中的选定区域的函数。它基于图像的邻域信息来重建图像的损坏或不希望的部分。这个函数特别适合用于去除扫描照片中的灰尘和划痕,或从静态图像或视频中去除不需要的对象。
def inpaint(src, inpaintMask, inpaintRadius, flags, dst=None)
src: 输入参数,源图像。这应该是一个8位、16位无符号或32位浮点的单通道或三通道图像。
inpaintMask: 输入参数,修复掩模。这是一个8位单通道图像,非零像素指示需要修复的区域。
inpaintRadius: 输入参数,圆形邻域的半径。每个待修复点考虑的邻域大小由此半径决定。
flags: 输入参数,修复方法。可以是以下两种之一:
- INPAINT_NS: 基于 Navier-Stokes 的方法。
- INPAINT_TELEA: Alexandru Telea 提出的方法。
dst: 输出参数,与源图像大小和类型相同的输出图像。
cv2.inpaint 函数通过考虑待修复区域边界附近的像素来重建选定的图像区域。该方法可用于修复小的图像区域,例如去除图像中的小斑点或遮挡物。它通过估算损坏区域周围的颜色和强度分布,以合理的方式填充这些区域,从而达到修复的效果。
在实际应用中,需要根据具体问题选择合适的修复半径和方法。例如,较小的半径适用于小面积的修复,而较大的半径可能更适合广泛区域的修复。同样,两种不同的方法(INPAINT_NS 和 INPAINT_TELEA)在不同类型的图像和损坏情况下可能会有不同的效果。
2.2 修补算法
2.2.1 修补算法原理
修补(Patching)算法通过选取图像中未损坏的区域并用其覆盖损坏部分来进行修复。这种方法对于去除图像中的小对象或缺陷特别有效。
2.2.2 修补算法实现步骤
- 选择一个图像的未损坏区域作为补丁。
- 选择需要修复的区域。
- 将补丁应用到损坏的区域。
2.2.3 OpenCV代码实现
2.2.3.1 方形补丁修补
import cv2
import numpy as np
# 加载图像
image = cv2.imread('tulips.jpg')
# 创建掩模,用于模拟损坏的区域
mask2 = np.zeros(image.shape[:2], np.uint8)
cv2.circle(mask2, (395, 215), 80, 255, -1) # 圆形损坏区域
# 应用掩模,模拟损坏
damaged_image = image.copy()
damaged_image[mask2 == 255] = [0, 0, 0]
# 选择一个补丁区域
# 注意:这里的坐标(x1, y1, x2, y2)需要根据您的图像进行调整
x1, y1, x2, y2 = 20, 20, 140, 150 # 补丁区域的坐标
patch = image[y1:y2, x1:x2]
# 确定损坏区域的坐标
# 这里我们使用与圆形损坏区域相同的坐标
dx1, dy1, dx2, dy2 = 395 - 80, 215 - 80, 395 + 80, 215 + 80
# 确保补丁和损坏区域的大小相同
patch_resized = cv2.resize(patch, (dx2 - dx1, dy2 - dy1))
# 应用补丁
restored_image = damaged_image.copy()
restored_image[dy1:dy2, dx1:dx2] = patch_resized
# 显示修复后的图像
cv2.imshow('Restored Image', cv2.hconcat([image, damaged_image,restored_image]))
cv2.waitKey(0)
cv2.destroyAllWindows()

2.2.3.2 圆形补丁修补
import cv2
import numpy as np
# 加载图像
image = cv2.imread('tulips.jpg')
# 创建掩模,用于模拟损坏的区域
mask2 = np.zeros(image.shape[:2], np.uint8)
cv2.circle(mask2, (395, 215), 80, 255, -1) # 圆形损坏区域
# 应用掩模,模拟损坏
damaged_image = image.copy()
damaged_image[mask2 == 255] = [0, 0, 0]
# 选择一个圆形补丁区域
px, py, radius = 78, 80, 70 # 原始补丁的半径
patch_mask = np.zeros(image.shape[:2], np.uint8)
cv2.circle(patch_mask, (px, py), radius, 255, -1)
# 创建原始补丁图像
original_patch = np.zeros_like(image)
original_patch[patch_mask == 255] = image[patch_mask == 255]
# 放大补丁到新半径
new_radius = 80
scale_factor = new_radius / radius
resized_patch = cv2.resize(original_patch, (0, 0), fx=scale_factor, fy=scale_factor)
# 重新创建圆形掩模以裁剪放大的补丁
resized_mask = np.zeros(resized_patch.shape[:2], np.uint8)
cv2.circle(resized_mask, (int(px*scale_factor), int(py*scale_factor)), new_radius, 255, -1)
final_patch = np.zeros_like(resized_patch)
final_patch[resized_mask == 255] = resized_patch[resized_mask == 255]
restored_image = damaged_image.copy()
# 应用放大的圆形补丁
for i in range(-new_radius, new_radius):
for j in range(-new_radius, new_radius):
if i**2 + j**2 <= new_radius**2:
restored_image[215 + i, 395 + j] = final_patch[int(py * scale_factor) + i, int(px * scale_factor) + j]
# 显示修复后的图像
cv2.imshow('Restored Image', cv2.hconcat([image, damaged_image,restored_image]))
cv2.waitKey(0)
cv2.destroyAllWindows()

总结
在本篇博客中,我们探讨了OpenCV中几种常用的图像分割方法:漫水填充法、分水岭法、GrabCut法和Mean-Shift法,以及图像修复技术:Telea方法和Navier-Stokes方法,还有修补算法。每种方法都有其独特的原理和适用场景。漫水填充法和分水岭法适用于基于区域的分割,GrabCut法适合交互式前景提取,而Mean-Shift法适用于基于密度的聚类分割。在图像修复方面,Telea方法和Navier-Stokes方法提供了强大的工具,用于修复图像中的损坏区域。
通过本篇博客,我们能够获得对OpenCV图像分割和修复技术的基本理解,并能够开始在自己的项目中应用这些技术。图像处理是一个不断发展的领域,随着技术的进步,将有更多的方法和技术被开发出来。因此,持续学习和实践对于保持在该领域的领先地位至关重要。