什么是机器学习
前言
机器学习(Machine Learning, ML)是一个总称,用于解决由各位程序员自己基于 if-else 等规则开发算法而导致成本过高的问题,想要通过帮助机器 「发现」 它们 「自己」 解决问题的算法来解决 ,而不需要程序员将所有规则都输入机器,明确告诉机器该怎么做。
机器学习概念
机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出决定或预测”。也就是说计算机利用以获取的数据得出某一模型,然后利用此模型进行预测的一种方法,这个过程跟人的学习过程有些类似,比如人获取一定的经验,可以对新问题进行预测。

可以看到,神经网络只是机器学习中的一部分,除了神经网络,机器学习还有着许多其他的算法。机器学习在多年的发展中逐步丰富,已经被人们开发出了许多中算法
- K 近邻(KNN)
- K 均值(K-Means)
- 支持向量机(SVM
- 随机森林(RandomForest)
- 逻辑回归(Logistic Regression)
- 神经网络(Neural Network)
- 其它
机器学习的分类
机器学习按照学习的方式可以分为
- 有监督学习通常指的是所有数据都含有特征 X 和标签 Y,有标准答案指导机器进行学习;
- 无监督学习指的是只有特征 X,没有特定的标签 Y,设计一定的规则让机器进行学习;
- 半监督学习指的是所有数据都有特征 X,但一部分数据含有标签 Y,一部分没有,需要通过联合没有标签和有标签的数据进行学习;
- 强化学习指的是可以通过外界或人为规定的奖励来指导机器进行下一步的行为。
无监督学习:例如聚类的算法,即把特征值相同的归为一类,或者降维
半监督学习: 一般通过聚类算法把无标签特征值和有标签特征值相同归为一类,并打上标签.然后使用有监督的学习方式学习
强化学习: 某种意义上也可以理解为一定的有监督,但其又不是完全将奖励值作为学习目标,并且一般是实时的,基于概率去抽样下一步行为的,所以又有着一定的区别。,例如阿尔法围棋和无人驾驶
按照工作的方式可以分为
-
批量学习(离线学习):Batch Learning,输入大量学习资料,机器学习算法学习训练出模型,将模型投入到生产中,模型不会发生变化;
- 优点:简单,只需要学习一次算法就可以,在生产过程中不需要修改模型;
- 缺点:无法随着环境变化而变化模型;
- 解决方案:定时重新批量学习,但是每次重新批量学习时,运算量巨大;在某些环境变化非常快的情况下,甚至是不可能的;
-
在线学习:Online Learning,机器学习算法的流程不变,只不过每次输入样例时,能够获取正确结果,并将此结果给到机器学习算法,改进模型,不断循环;

- 优点:及时反映新的环境变化;
- 缺点:新的数据带来不好的变化;新的数据不准确、质量不高,带来不好的变化,错误的结果;解决方案:需要加强对数据进行监控,及时对异常数据进行检测;
- 其他:也适用于数据量巨大,完全无法批量学习的环境。
对于算法模型本身分类
-
参数学习:对数据概率分布进行建模,有一种最为直接的方法就是先假设这个分布是服从某个特定分布的,比如高斯分布,泊松分布等等,当然这些分布中有些未知参数需要我们求得,而这些参数也正是决定了这个分布的形状的.求解通常根据现有的样本数据集进行,这个参数集 Θ \Theta Θ是一个有限的集合.
推出一个结论就是,在参数化模型的框架下,无论我接下来观察到多少数量的数据,哪怕是无限多个数据,我模型的参数量都只有固定数量多个,那便是 Θ \Theta Θ。也就是说,用有界的参数量(复杂度)对无界的(数据量)的数据分布进行了建模。
-
非参数学习:和参数化模型截然相反的是,对数据分布不进行任何的假设,只是依赖于观察数据,对其进行拟合。换句话说,其认为数据分布不能通过有限的参数集 Θ \Theta Θ进行描述,但是可以通过无限维度的参数 Θ \Theta Θ进行描述,无限维度也就意味着其本质就是一个函数 f ( . ) ∈ R ∞ f(.) \in \R^\infty f(.)∈R∞.
通常,实际中的模型是对这个无限维度参数集的近似,比如神经网络中的参数,虽然参数量通常很大,也有万有拟合理论保证其可以拟合函数,但是其只是对无限维度数据的近似而已。由于非参数化模型依赖于观察数据,因此参数集 Θ \Theta Θ能捕获到的信息量随着观察数据集的数量增加而增加,这个使得模型更加灵活。
机器学习的应用
机器学习的不同模型解决不同应用场景的问题

- 分类是我们知道有哪些组,然后对数据进行判断,判断这些数据到底是预先知道的那些组。举个很简单的例子,比如我们在军训排队时要求男生一组,女生一组,这就是一种分类,我们提前知道要分那些组,然后通过一种算法对输入的数据判定,来分类到已知的类别下,这个就是分类,所以分类属于监督学习方法
- 聚类是实现不知道这批数据有哪些类别或标签,然后通过算法的选择,分析数据参数的特征值,然后进行机器的数据划分,把相似的数据聚到一起,所以它是无监督学习;
- 回归在统计学角度,指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。它是对有监督的连续数据结果的预测,比如通过一个人过去年份工资收入相关的影响参数,建立回归模型,然后通过相关的参数的变更来预测他未来工资收入。
- 降维就是去除冗余的特征,降低特征参数的维度降低,用更加少的维度来表示特征
学习环境
- 语言:Python3
- 框架:scikit-learn,基于 SciPy 构建的机器学习 Python 模块
- IDE: jupyter Notebook 可以图形输出,文档编写
- 其它: matolotlib 画图工具,numpy科学计算的基础库
K近邻
我们通过“ K近邻”算法,来了解机器学习的流程.
学习算法原理
K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。

如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。
如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
距离的度量
定义中所说的最邻近是如何度量呢?我们怎么知道谁跟测试点最邻近。这里就会引出我们几种度量俩个点之间距离的标准。

特征归一化
首先举例如下,我用一个人身高(cm)与脚码(尺码)大小来作为特征值,类别为男性或者女性。我们现在如果有5个训练样本,分布如下:
A [(179,42),男]
B [(178,43),男]
C [(165,36)女]
D [(177,42),男]
E [(160,35),女]
很容易看到第一维身高特征是第二维脚码特征的4倍左右,那么在进行距离度量的时候,我们就会偏向于第一维特征。这样造成俩个特征并不是等价重要的,最终可能会导致距离计算错误,从而导致预测错误。
所以我们应该让每个特征都是同等重要的,归一化公式如下:
- 方法一:最小-最大规范化(0-1归一化)

- 方法二:零-均值规范化(z-score标准化)

对一个数值特征来说,很大可能它是服从正态分布的。标准化将这个正态分布调整为均值为0,方差为1的标准正态分布而已.更好保持了样本间距.当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。
超参数K
k如何选值,如果我们选取较小的k值,那么就会意味着我们的整体模型会变得复杂,容易发生过拟合!

上图中有俩类,一个是黑色的圆点,一个是蓝色的长方形,现在我们的待分类点是红色的五边形。很容易我们能够看出来五边形离黑色的圆点最近,k又等于1,那太好了,我们最终判定待分类点是黑色的圆点。
相反,如果我们选取较大的k值(k=15), 同样待分类点也是黑色
k值既不能过大,也不能过小.通常采取交叉验证法来选取最优的k值.k也被称为超参数
同相的距离公式中的p,也是要通过实验来验证,也是超参数
相对的还有模型参数,即算法运算过程中学习的参数
流程实施
## 导入库
import numpy as np
# 加载莺尾花数据集
from sklearn import datasets
# 导入KNN分类器
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
## 数据导入
# 导入莺尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 得到训练集合和验证集合, 8: 2
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
## 模型训练,参数的意思是使用欧式距离,k=5
clf = KNeighborsClassifier(n_neighbors=5, p=2, metric="minkowski")
## 使用训练集合,训练数据
clf.fit(X_train, y_train)
## 模型预测,把测试集数据转入得到预测结果
X_pred = clf.predict(X_test)
## 预测结果传入得到准确率
acc = sum(X_pred == y_test) / X_pred.shape[0]
print("预测的准确率ACC: %.3f" % acc)
-
业务场景分析就是将我们的业务需求、使用场景转换成机器学习的需求语言,然后分析数据,选择算法的过程。这个是机器学习的准备阶段,主要包括以下3点:
-
业务抽象:莺尾花图区分
-
数据准备:提取莺尾花的特征

-
选择算法:使用KNN算法。
-
-
数据处理就是数据的选择和清洗的过程,数据准备好后,确定了算法,确定了需求,就需要对数据进行处理,数据处理的目的就是尽可能降低对算法的干扰。在数据处理中我们会经常用到
-
去噪 : 将数据分成训练和测试集, 然后通过调节超参数,选出准确率是高的

-
归一: 将数据统一标准化
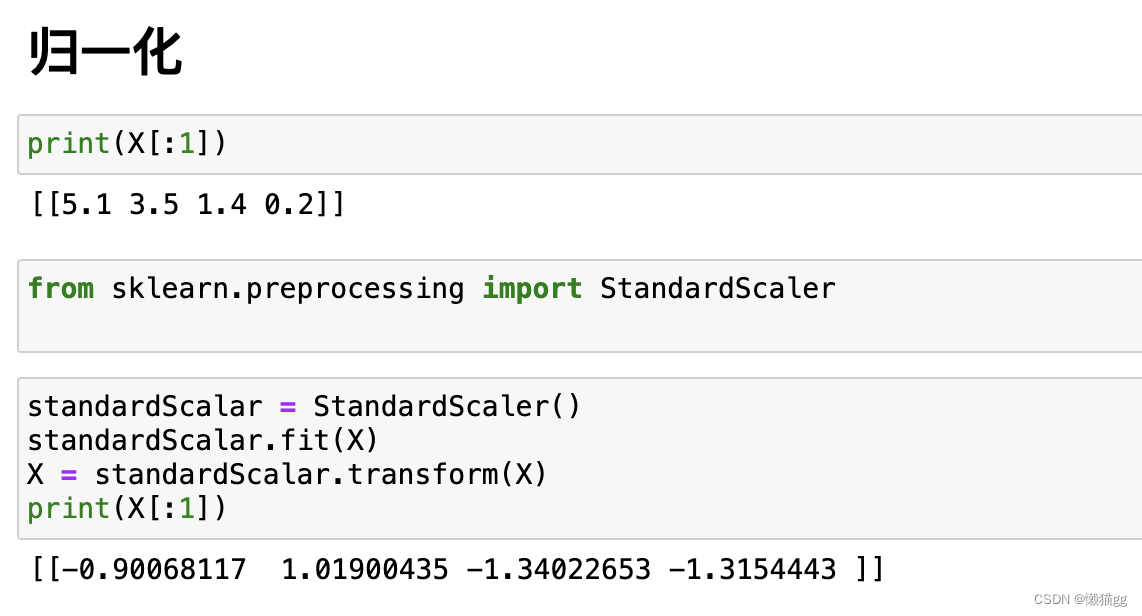
-
-
特征工程就是对处理完成后的数据进行特征提取,转换成算法模型可以使用的数据。
主要参考
《如何入门机器学习?有哪些值得分享的学习心得?》
《Jupyter Notebook介绍、安装及使用教程》
《什么是机器学习》
《一文搞懂k近邻(k-NN)算法(一)》
《python/scikit-learn 机器学习实战 原理/代码:KNN (K近邻算法)》