xxljob学习笔记01(小滴课堂)













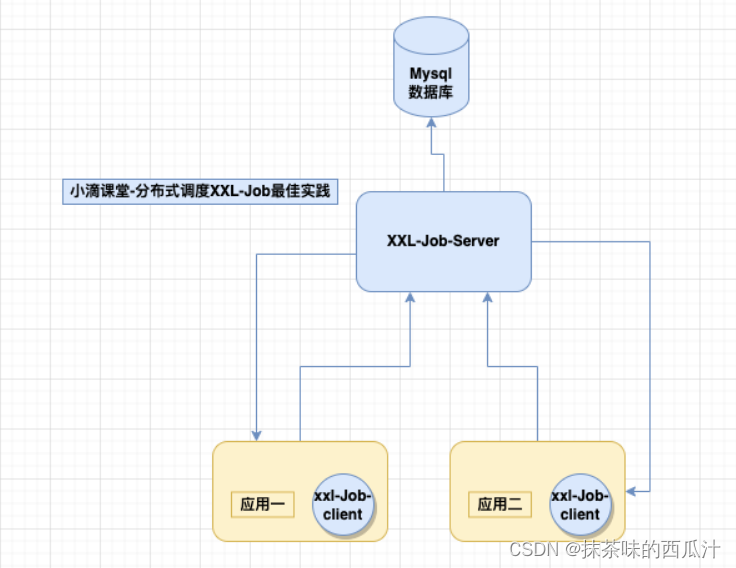
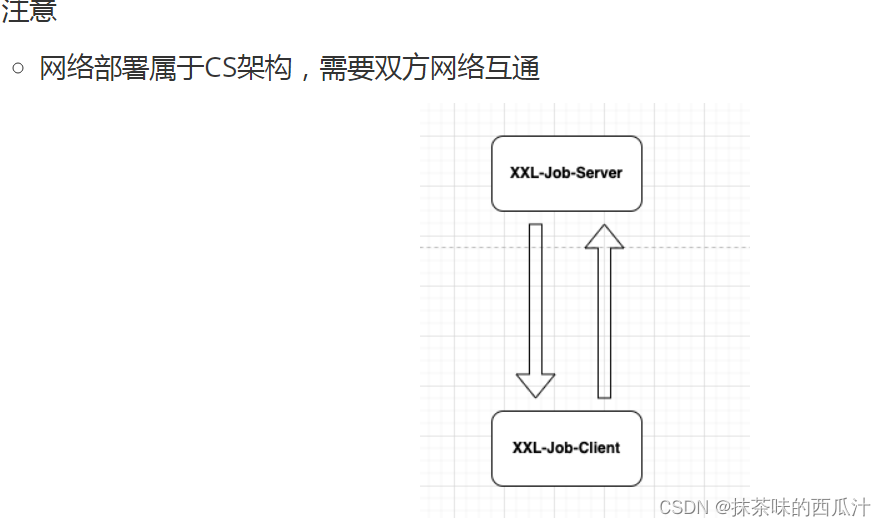
分布式调度xxl-job源码部署和数据库建立:

在idea中打开安装包:


创建数据库:
建表:
在项目里:
在navicat里运行语句即可:
修改数据库地址和用户名,密码:

配置令牌,不然谁都可以访问。
运行:



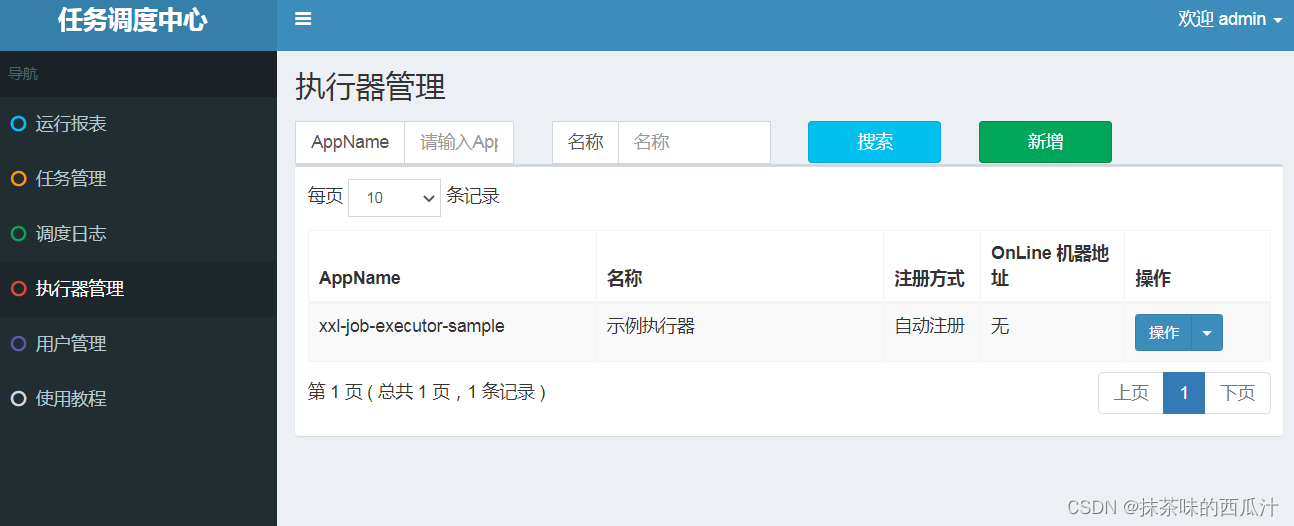
我们自己去创建一个执行器:
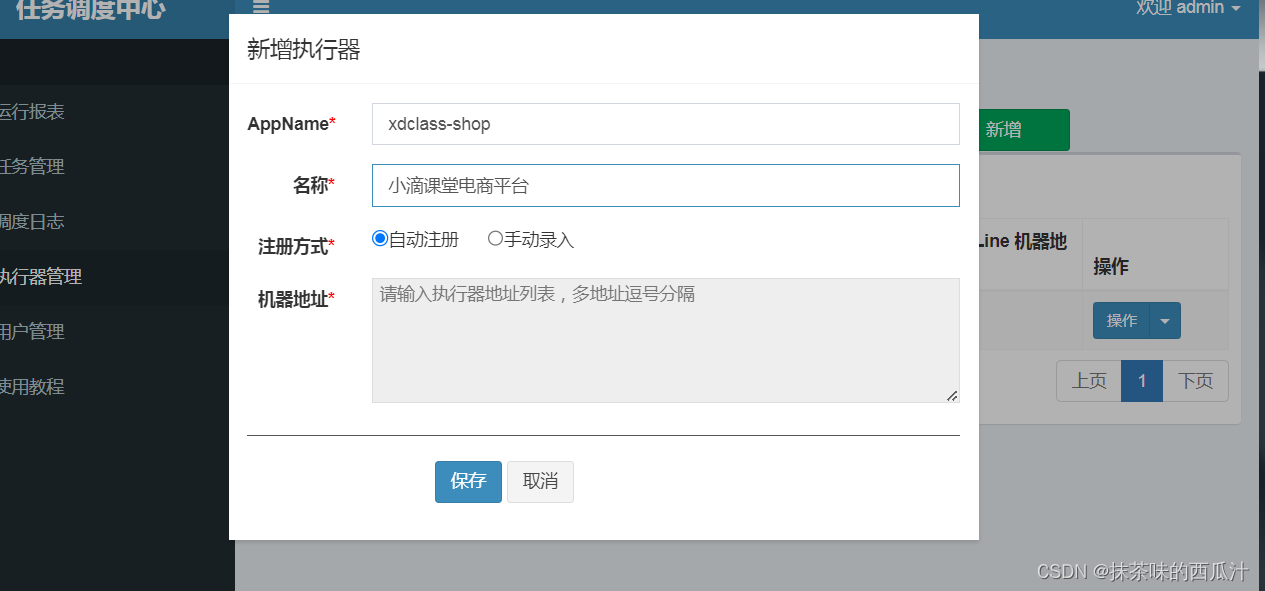
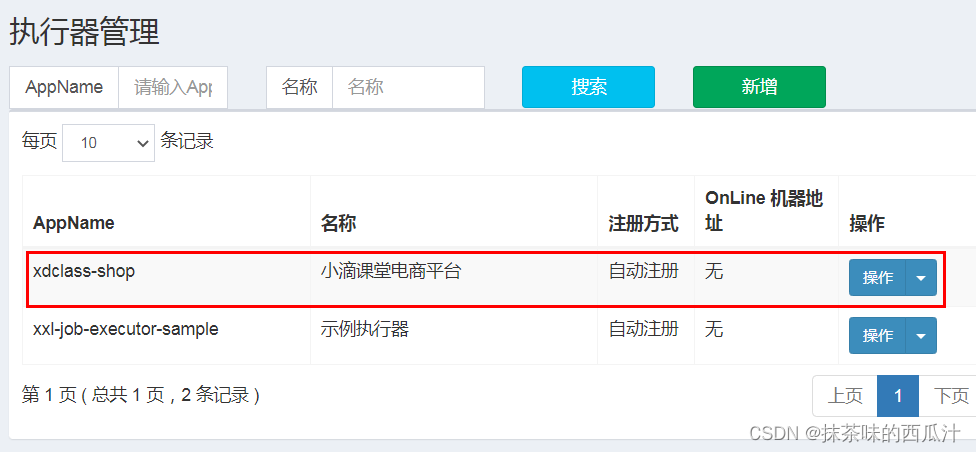
然后我们去新增任务: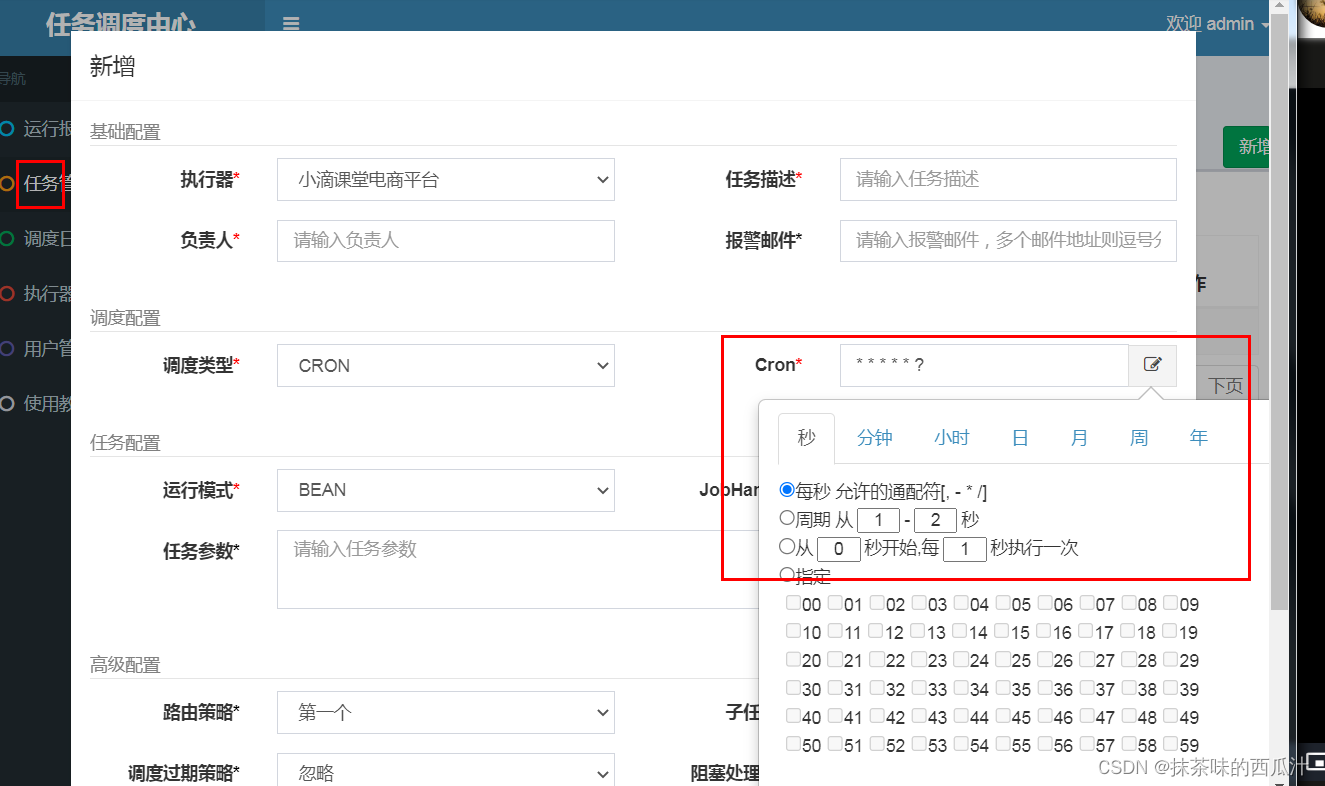
可以选择我们的定时需求规则。
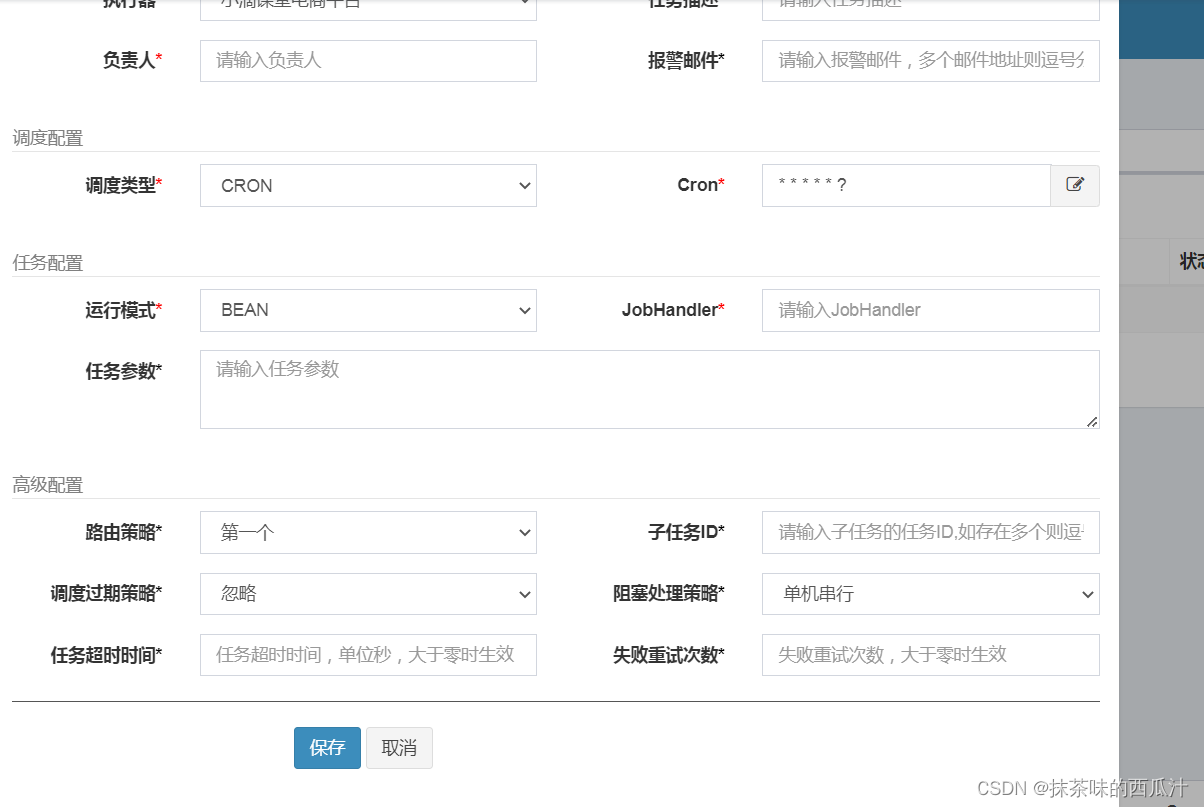
可以进行很多的配置。



调度日志,可以看到调度记录。
用户管理:


新建SpringBoot项目整合xxl-job:

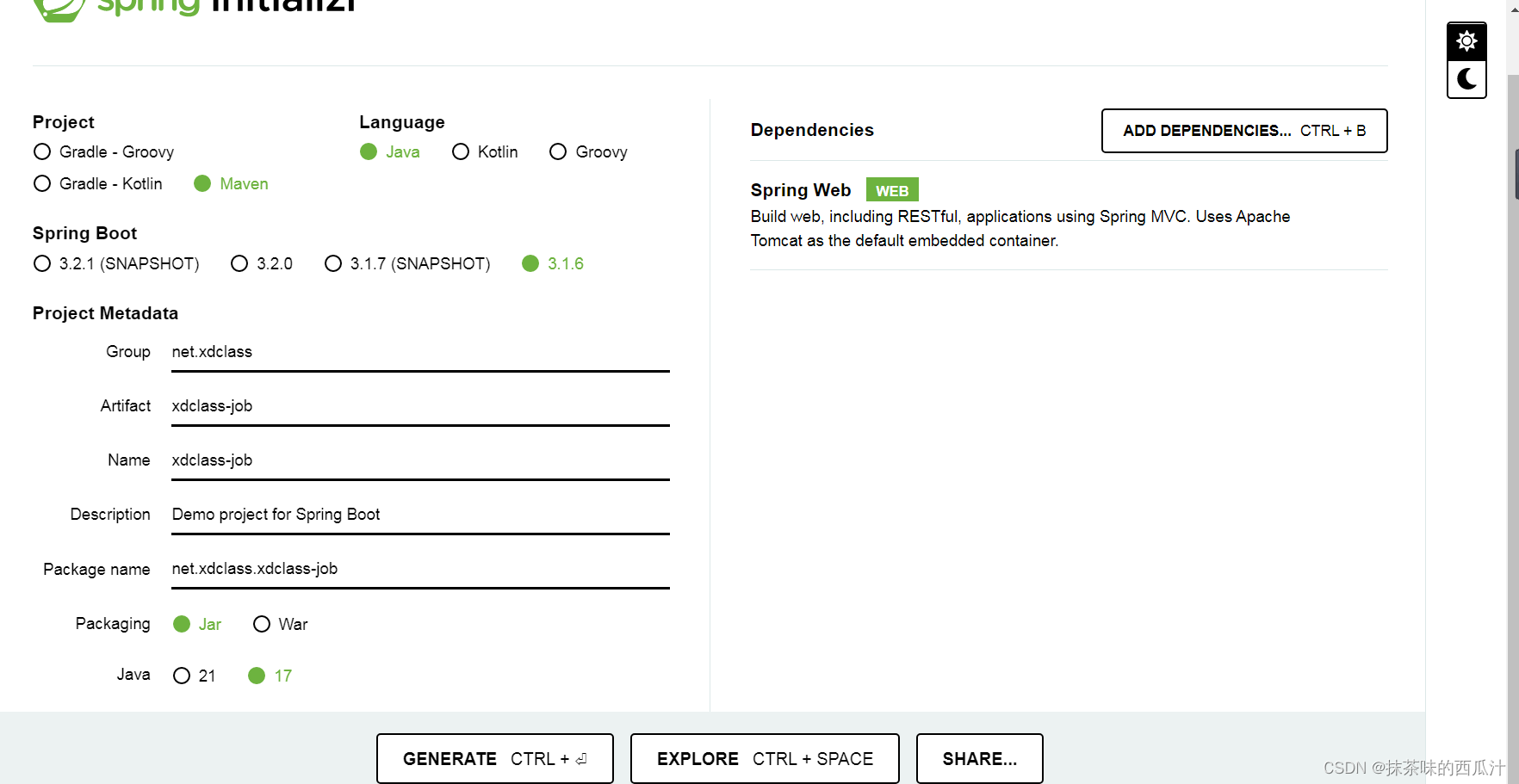
我们后面会更改jdk和springboot的版本。

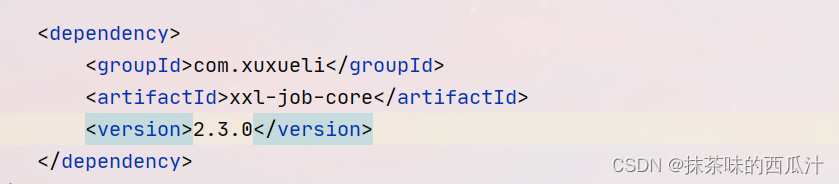
添加xxljob依赖。
添加logback日志文件。
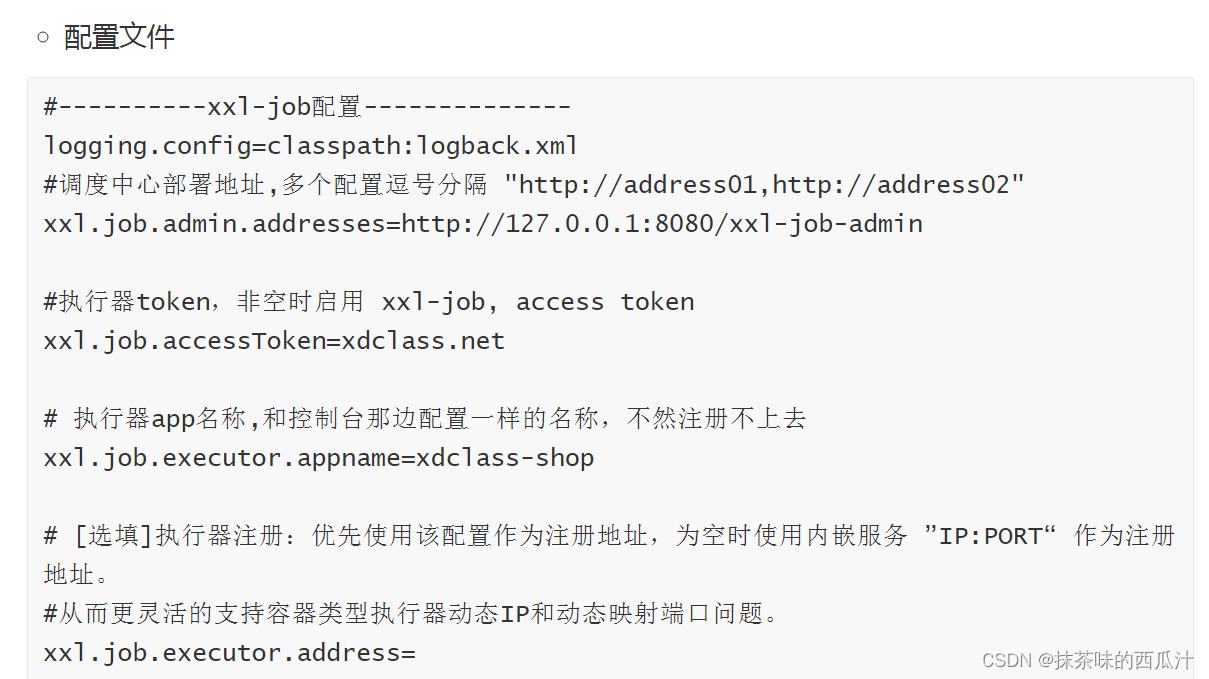
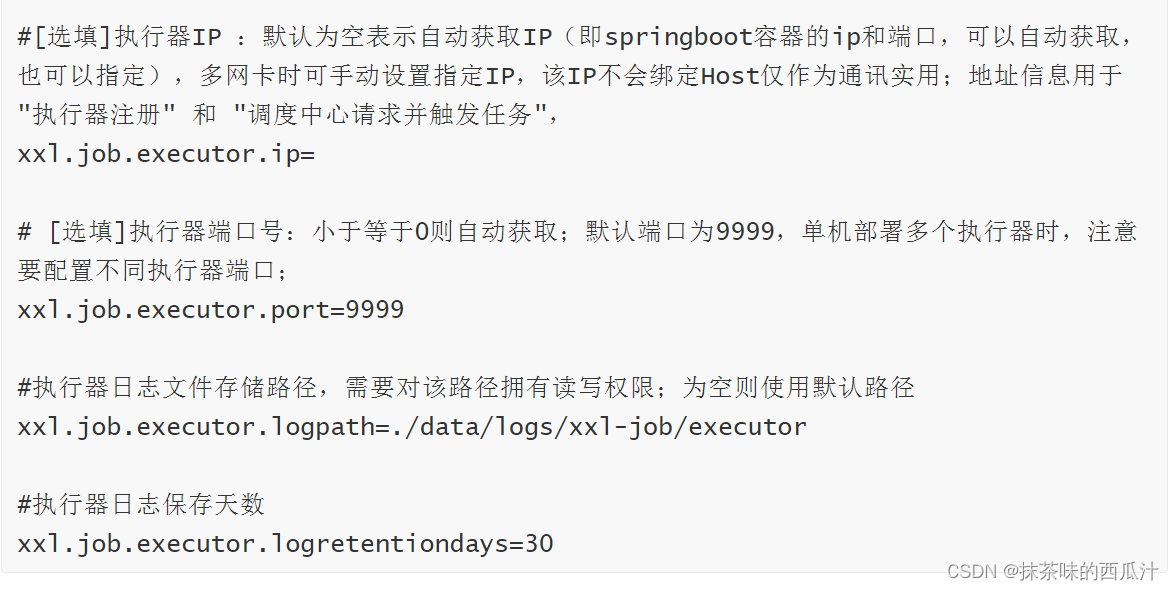
修改配置文件:
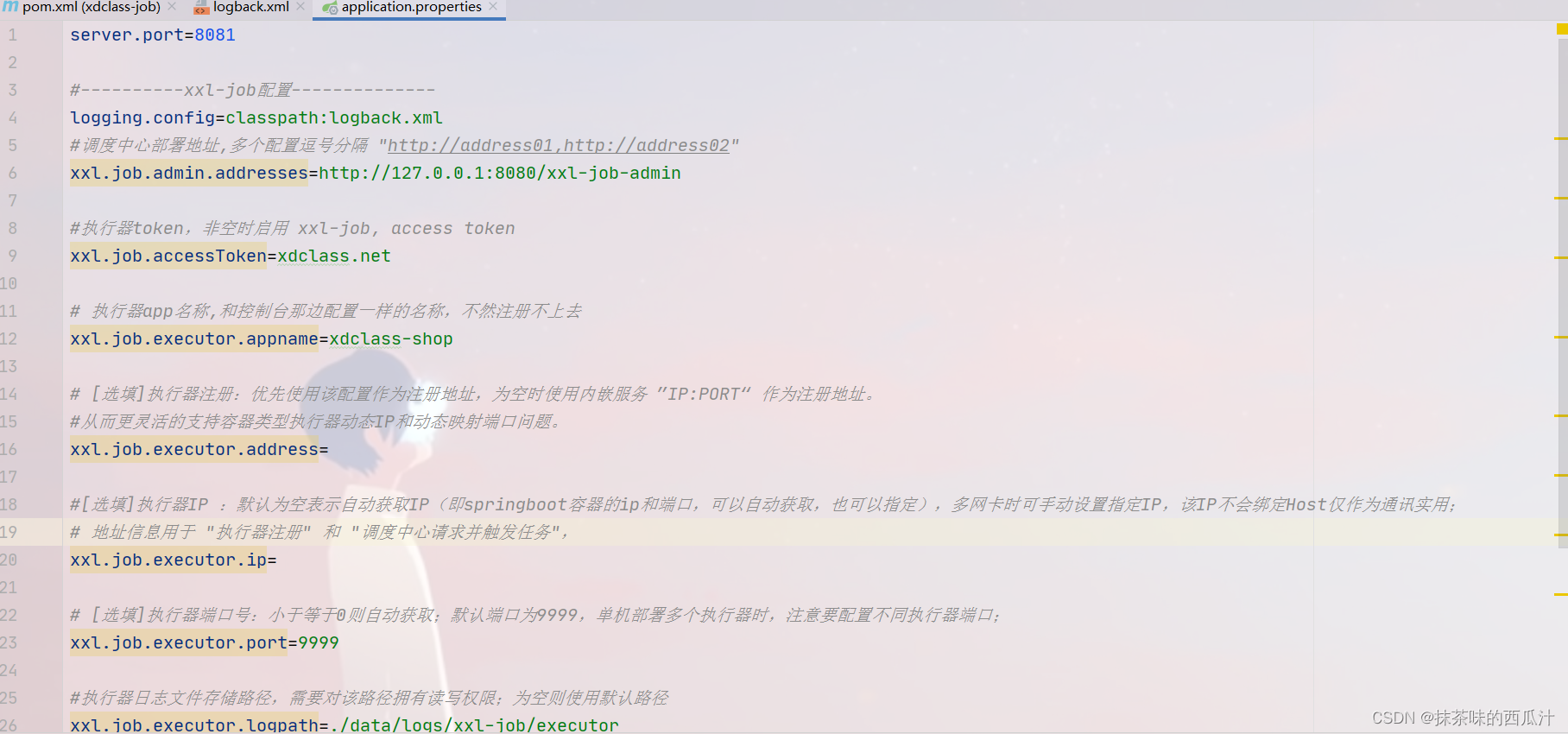

注:
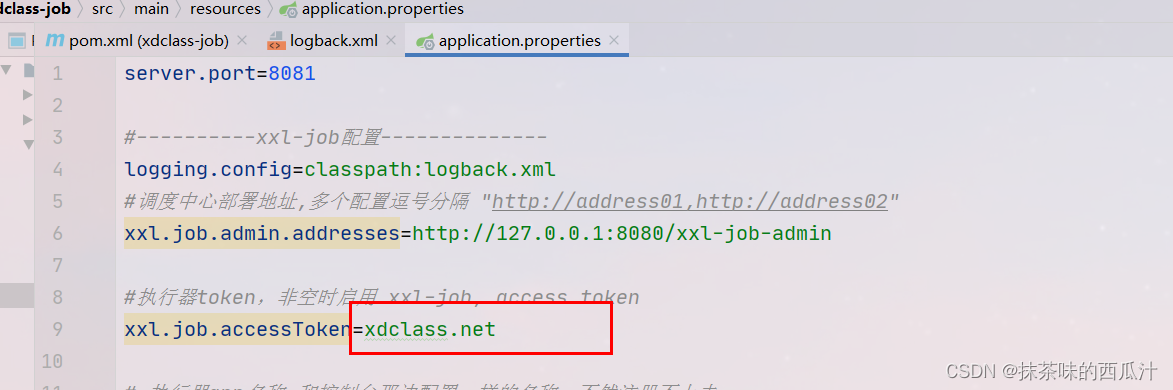
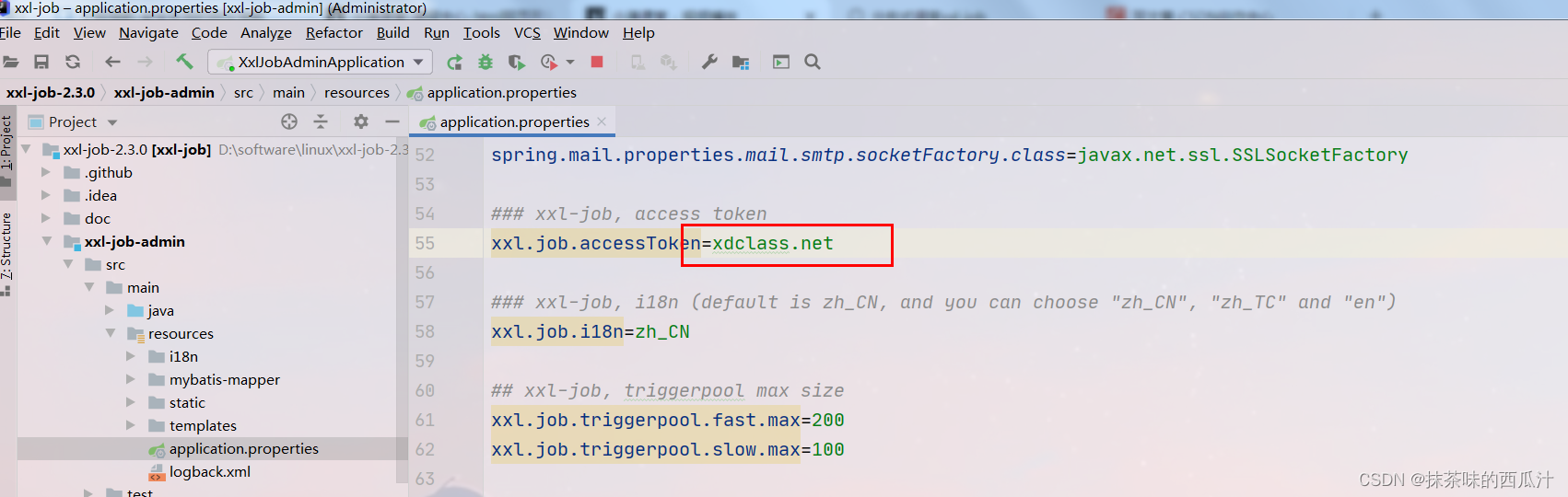
要和我们xxl-job-admin的token保持一致。
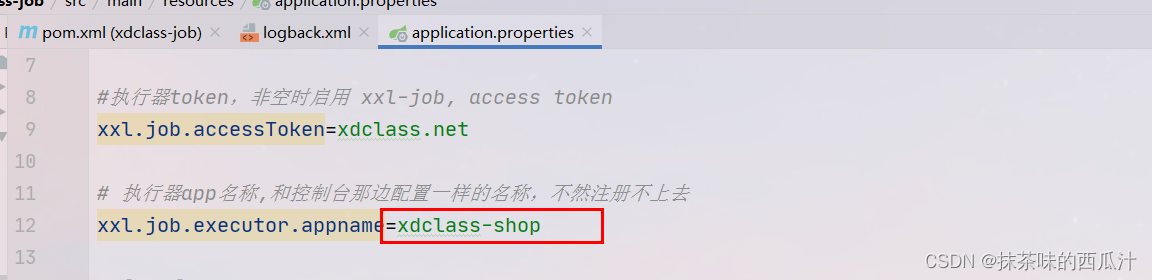
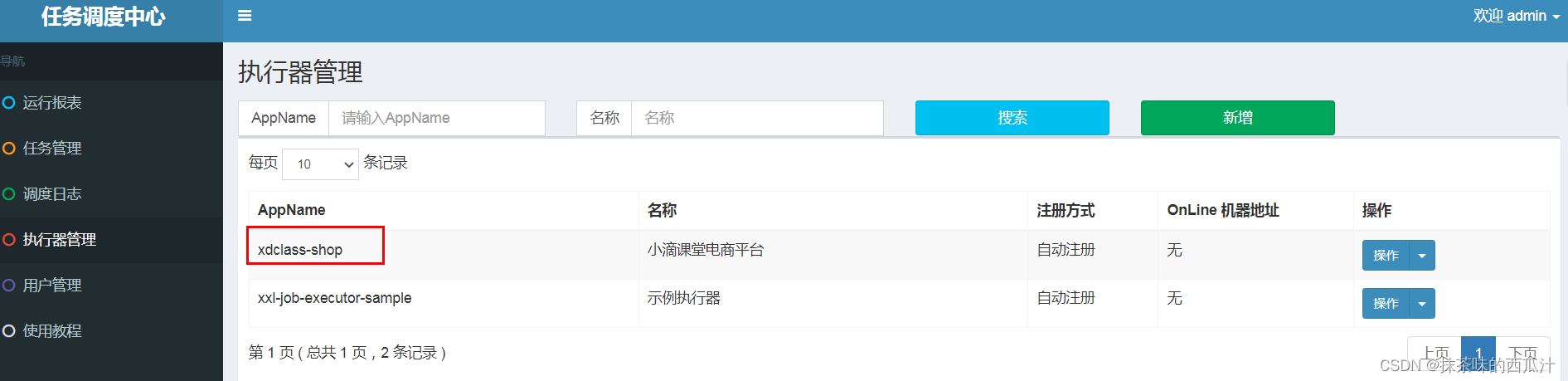
要和平台上的appName一致。
然后我们要去新增一个配置文件,去把我们的配置文件读出来:
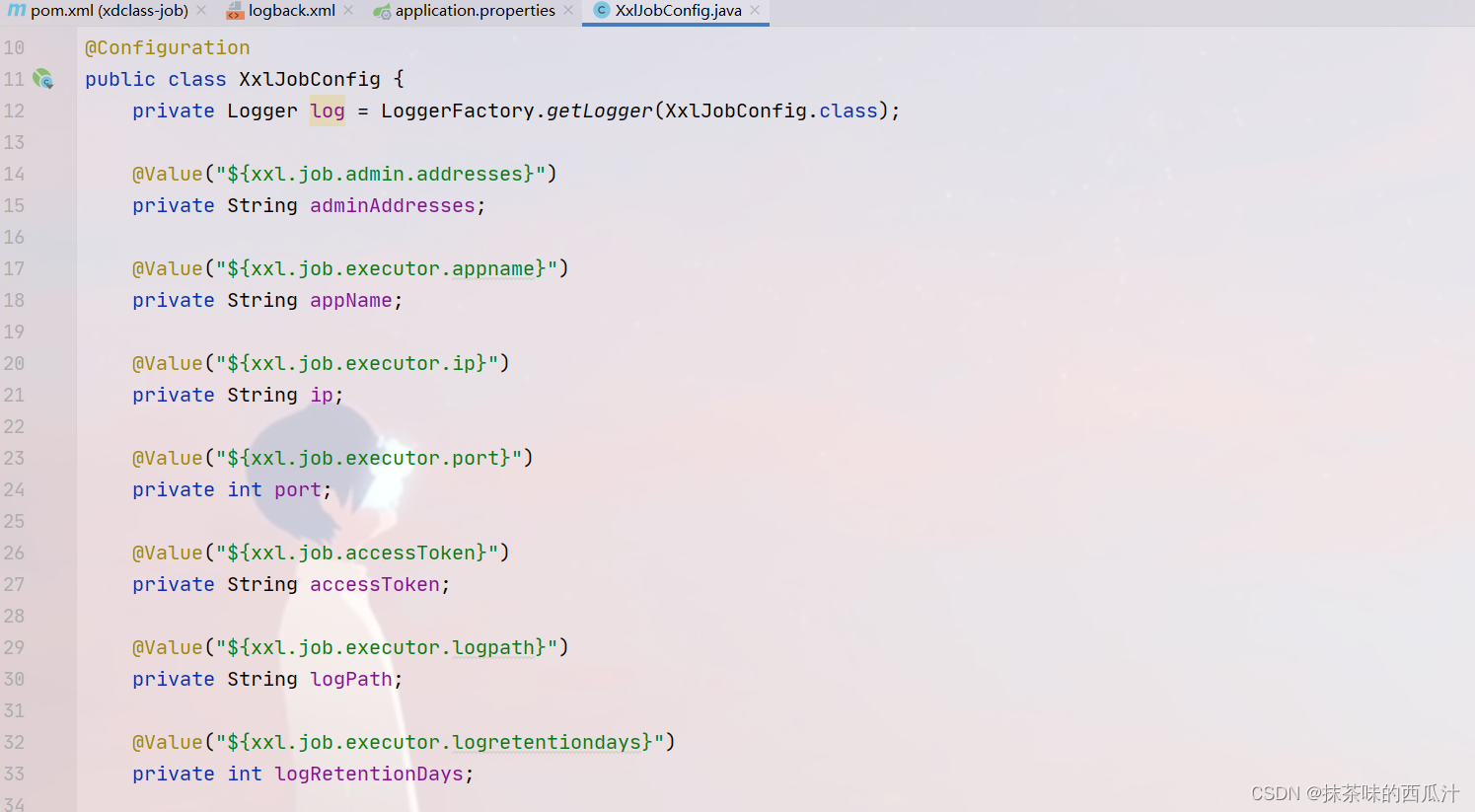
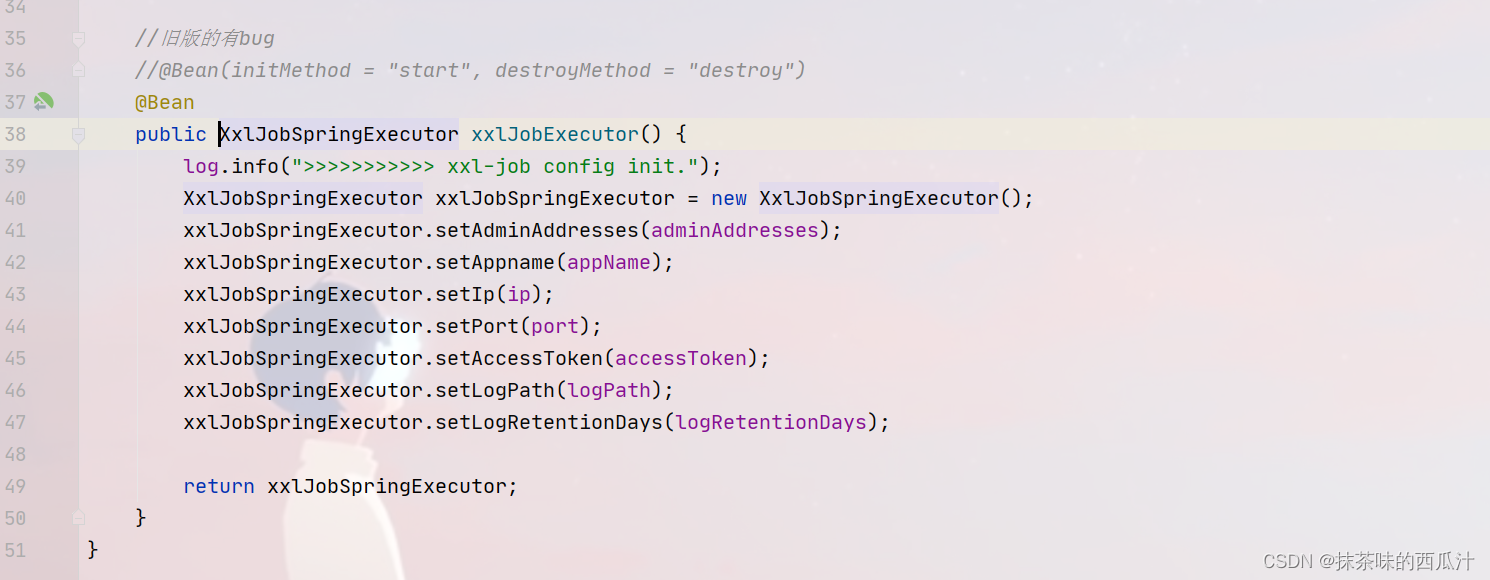
这里就是把配置文档中的信息读出来。直接使用官方文档中即可。
创建你的第一个XXL-Job分布式调度任务

1.新建job包,并创建定时任务类:

我们新建了定时任务,就要在平台上去添加我们对应的执行任务:
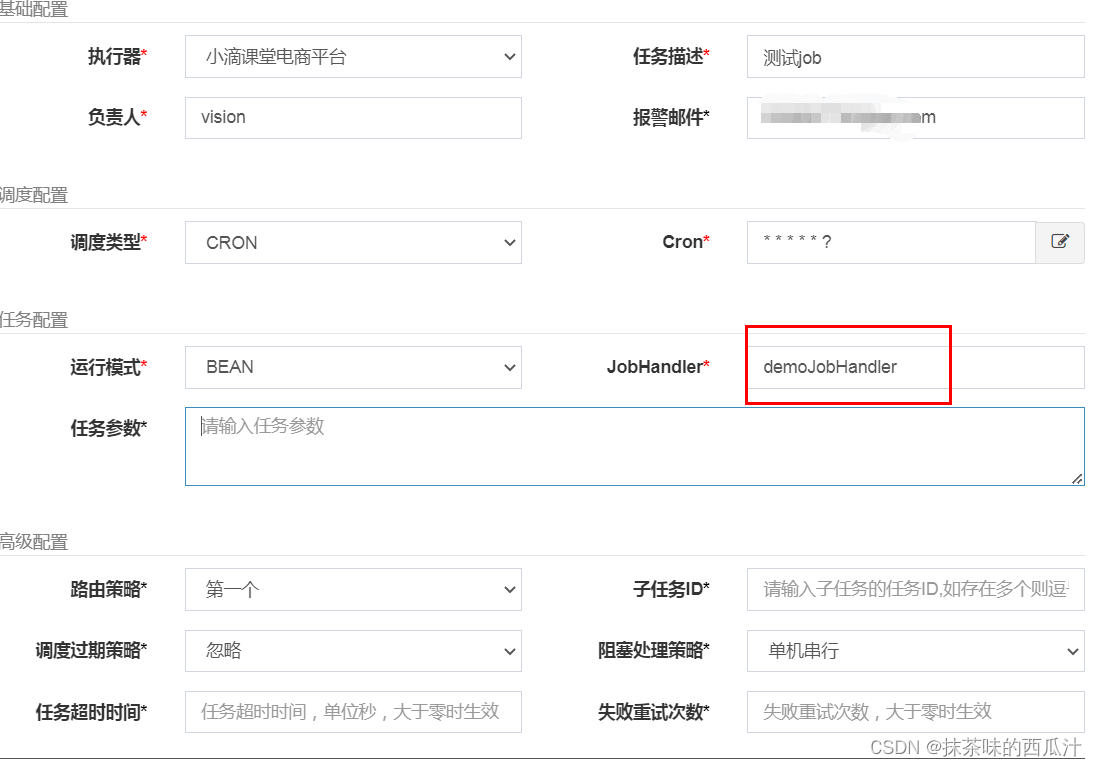
我们创建的是每秒执行一次。

在平台可以看到我们的定时任务。



启动:
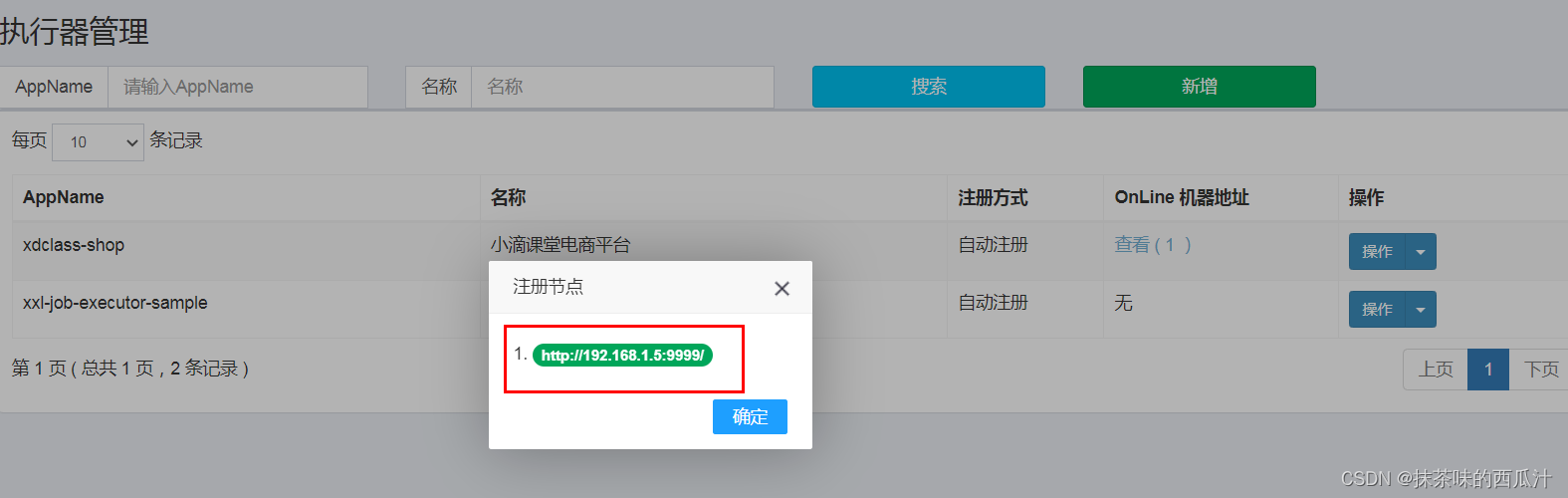
可以查看到注册节点。
我们的任务就连接上去了。
简介:执行和分析第一个XXL-Job分布式调度任务
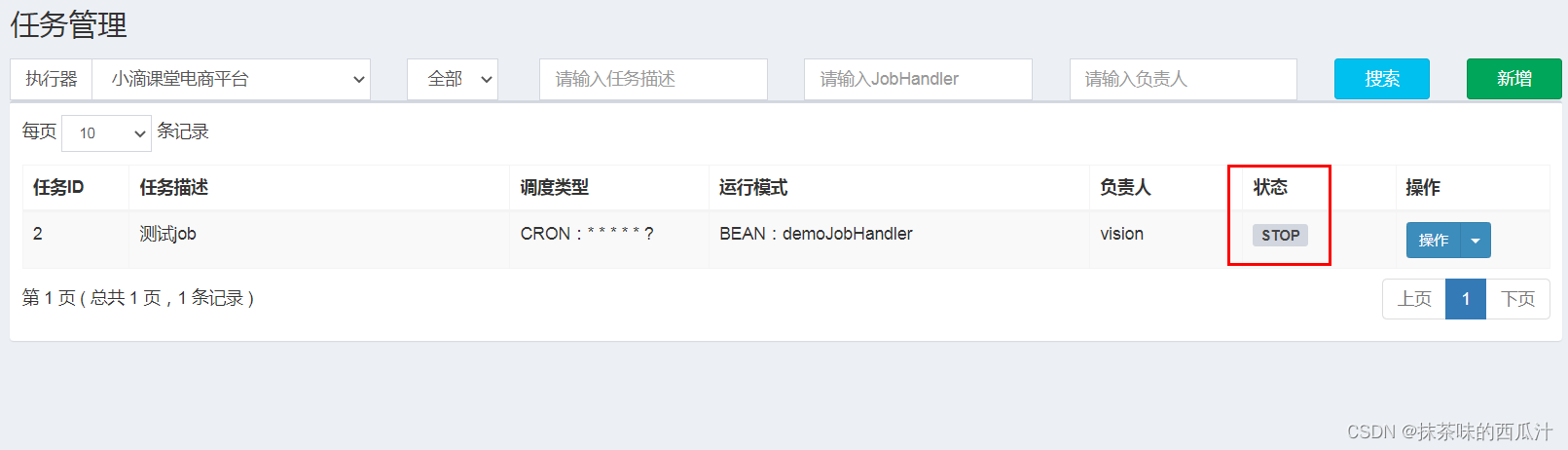
我们可以看到这边还是一个stop的状态。
那我们怎么能让他执行呢?
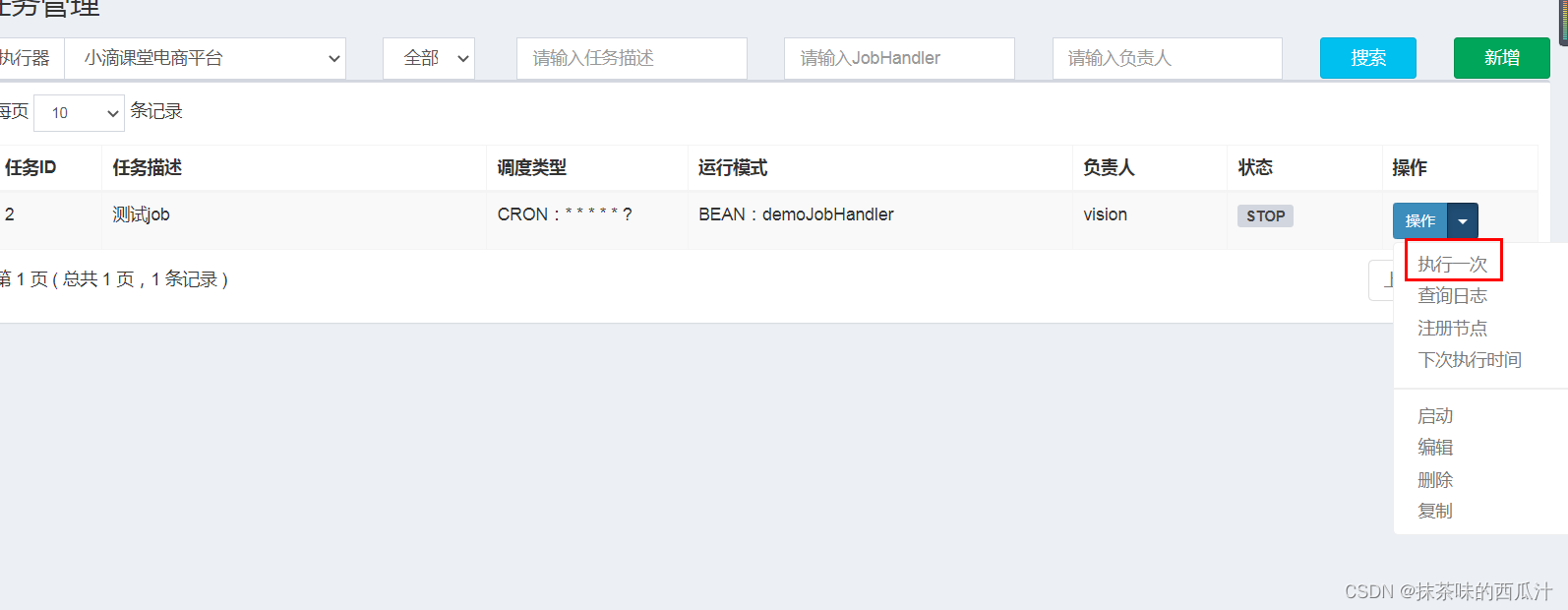



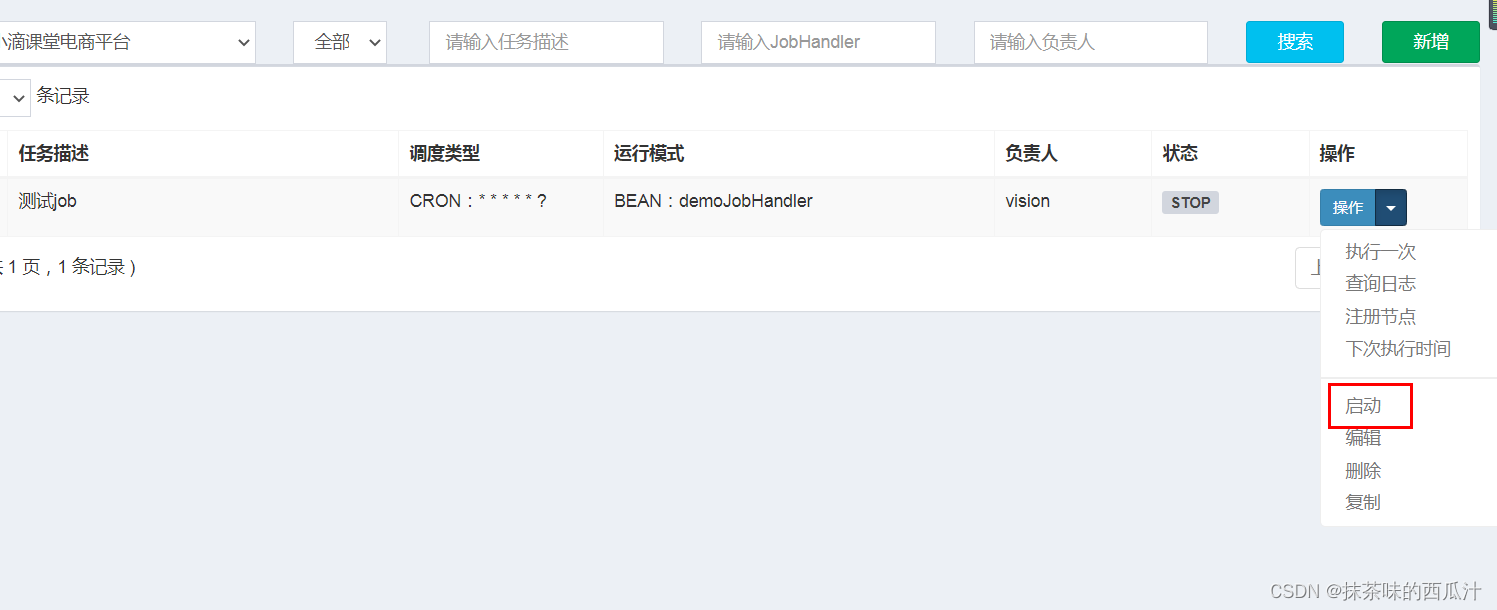
我们可以看到这里还是stop状态。我们也可以给它设置让他一直处于执行状态:
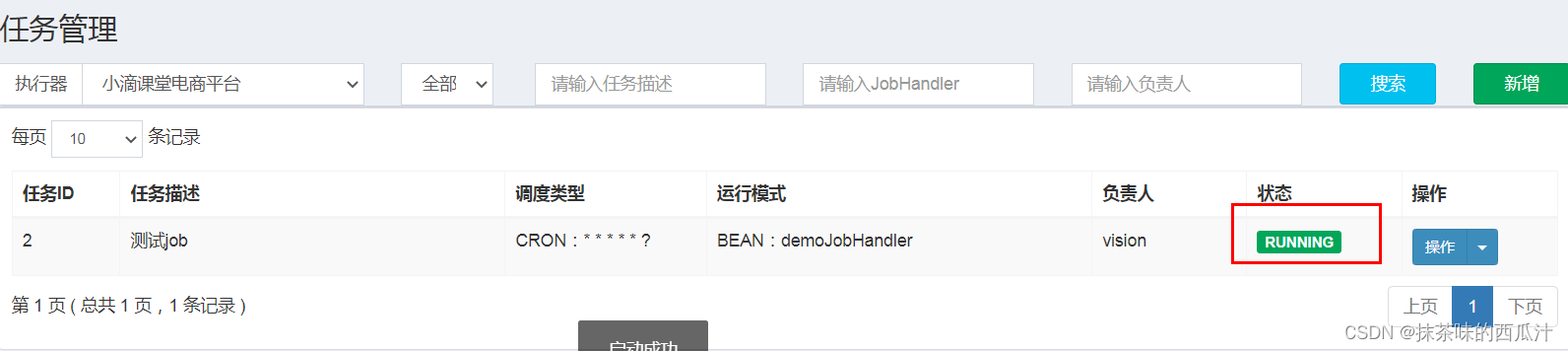

我们可以看到每隔一秒,就打印一次。
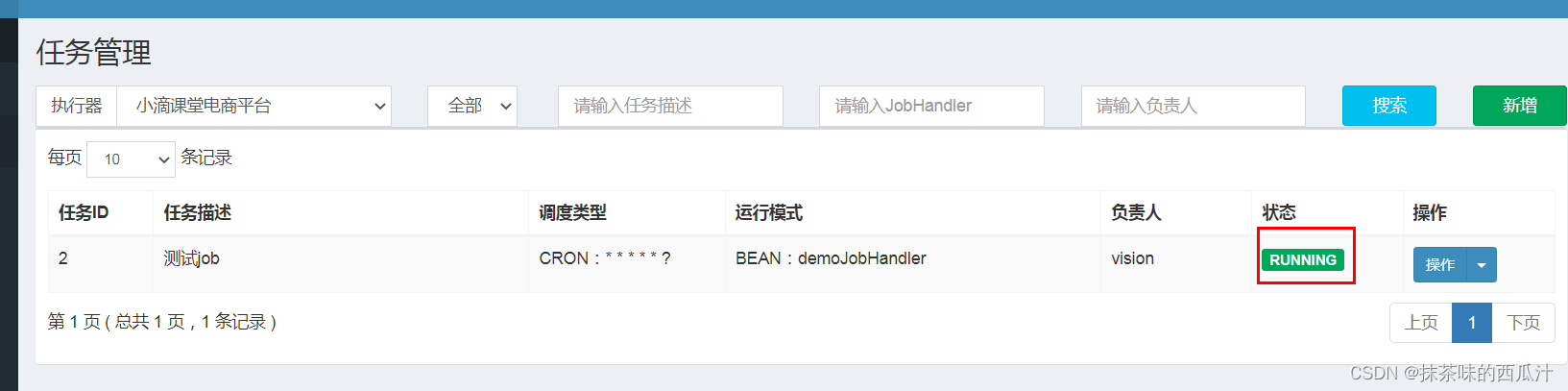
状态也一直都是运行状态。
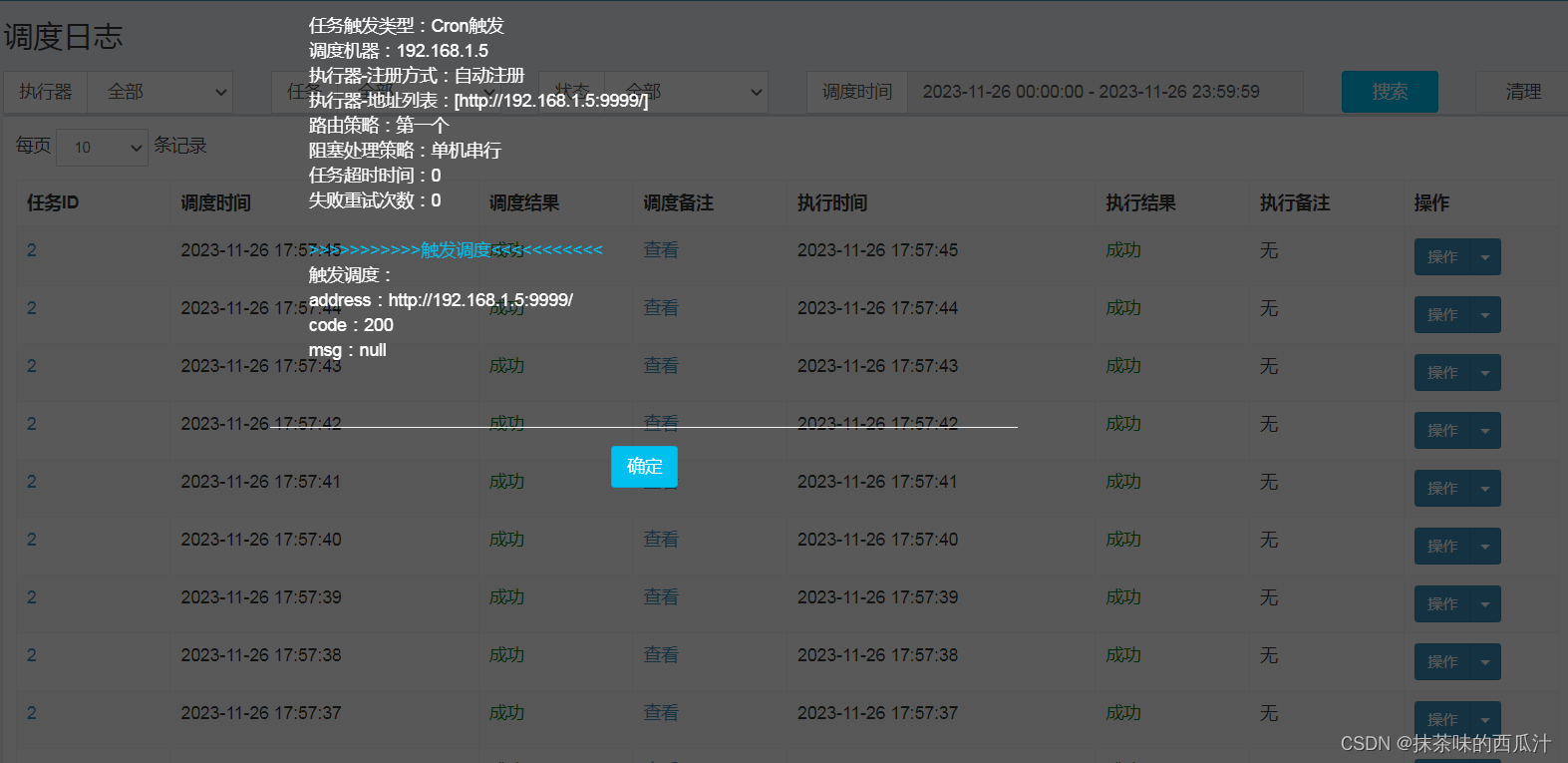
也可以在我们的调度日志中查看到相关的详细信息。
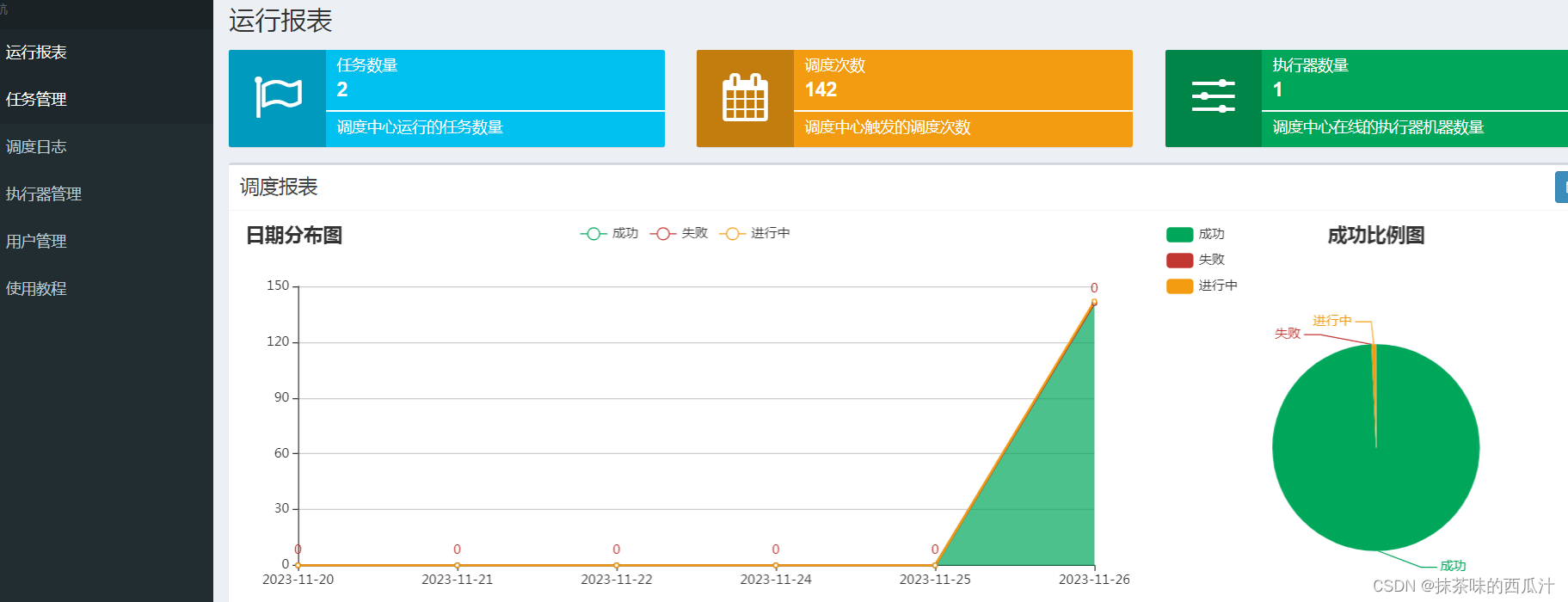
以及报表数据。
实际工作中也是如此,我们只需要在方法中去调用我们的service方法即可。
执行器多节点部署和调度策略讲解实战


先停止这个:

我们去执行第二个执行器:

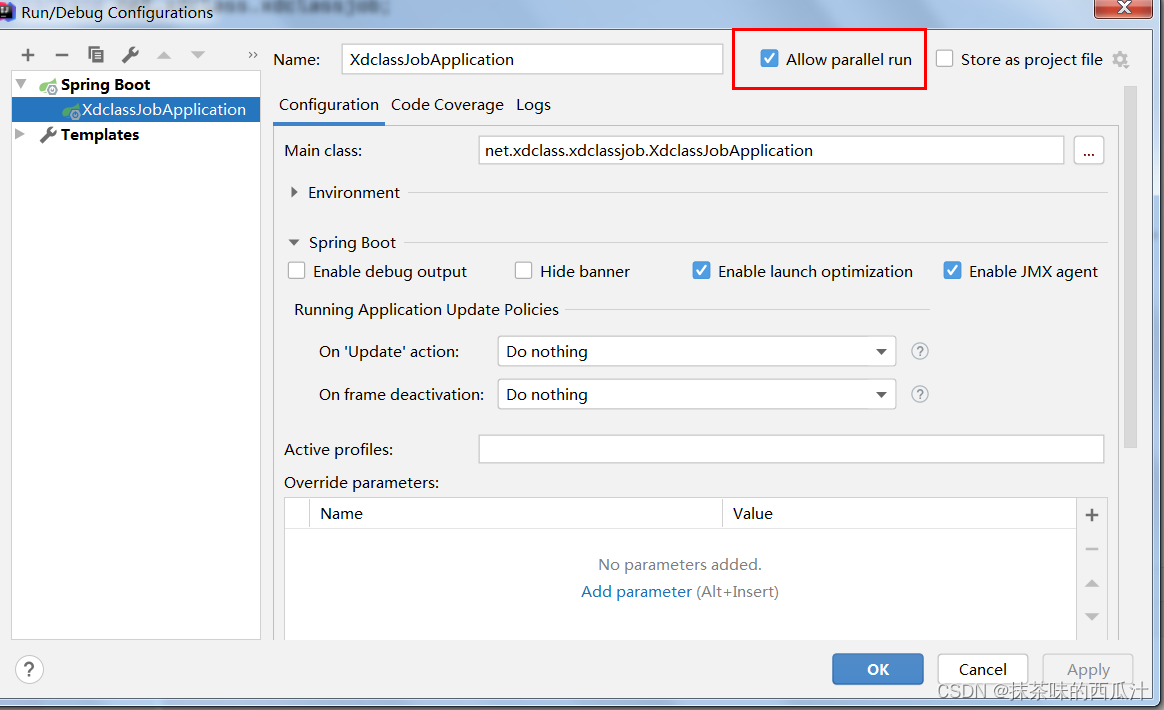
勾选这个可以取消单例模式。
同理我们再启动一个,服务的端口号和执行器的端口号分别设置为8083,9997.
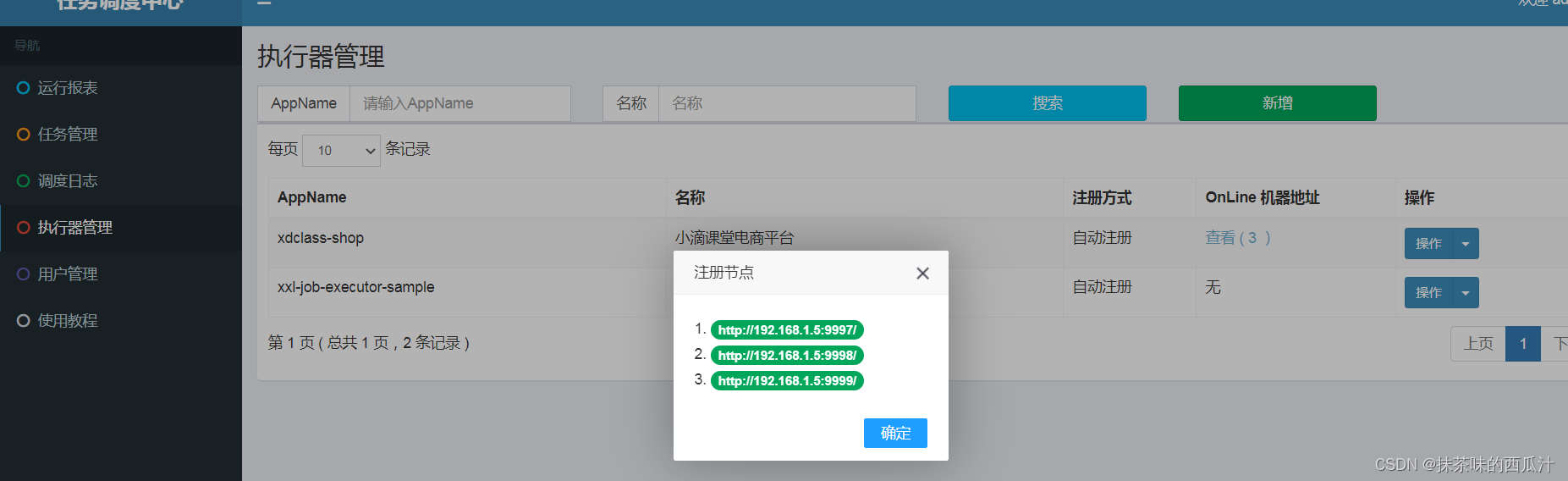
我们可以看到3个注册节点。

编辑策略: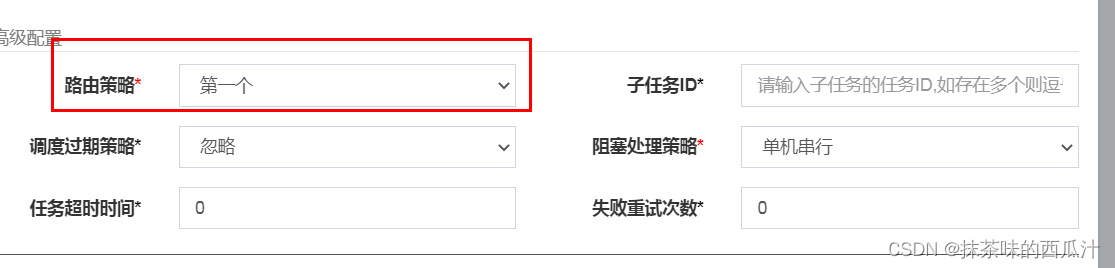
路由策略选择第一个。
我们去启动它。

只有第一个启动了。
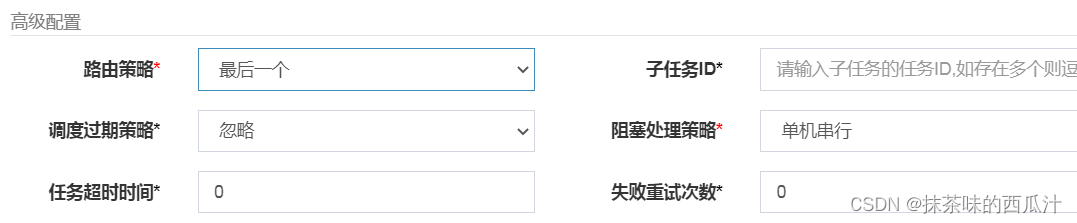
选择最后一个。

就只有最后一个会执行。
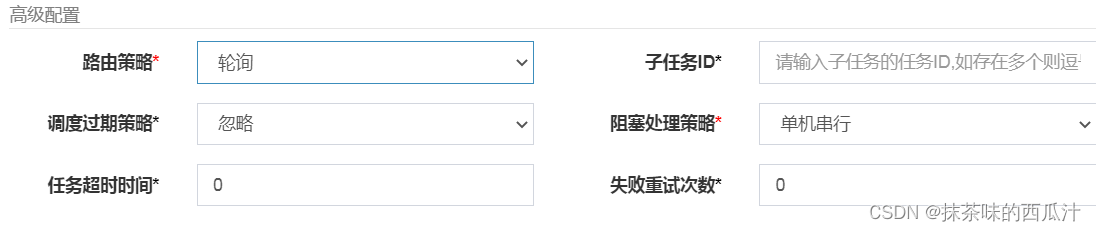
我们给它改成轮询。
每一个都会轮流执行。