【SpringCloud】设计原则之单一职责与服务拆分
一、设计原则之单一职责
设计原则很重要的一点就是简单,单一职责也就是所谓的专人干专事
一个单元(一个类、函数或微服务)应该有且只有一个职责
无论如何,一个微服务不应该包含多于一个的职责
职责单一的后果之一就是职责单位(微服务、类、接口、函数)的数量剧增
据说 Amazon、Netflix 这些采用微服务架构的网站一个小功能就会调用几十上百个微服务
但相比较于每个函数都是多个业务逻辑或职责功能的混合体的情况,维护成本还是低很多的
SRP(单一职责原则) 中的 “单一职责” 是个比较模糊的概念
对于函数,它可能指单一的功能,不涉及复杂逻辑
对于类或接口,它可能指对单一对象的操作,也可能是指对该对象单一属性的操作
总而言之,单一职责原则就是为了让代码逻辑更加清晰,可维护性更加好,定位问题更快的一种设计原则
单一职责的优点:
- 类的复杂性降低,实现什么职责都有清晰明确的定义
- 可读性提高,复杂性降低
- 可维护性提高,可读性提高
变更引起的风险降低,变更是必不可少的,若接口的单一职责做得好,一个接口修改只对相应的实现类有影响,对其他的接口无影响,这对系统的扩展性、维护性都有非常大的帮助
实施单一职责的目的:
- 以类来隔离需求功能点,这样当一个点的需求发生变化时,不会影响别的类的逻辑,这个和设计模式中的开闭原则类似,对扩展持开放态度,对修改持关闭态度
- 是一个原子模块级的粒度,至于原子的粒度到底是什么样的,应该因业务而异,设计过程中同时考虑业务的扩展,所以这就要求在设计的过程中,必须有业务专家共同参与,共同规避风险
- 粒度小、灵活、复用性强,方便更高级别的抽象
每个微服务单独运行在独立的进程中,能够实现松耦合,并且独立部署
二、设计原则之服务拆分
拆分粒度不应该过分追求细粒度,要考虑适中,不能过大或过小
按照单一职责原则和康威定律,在业务域、团队和技术上平衡粒度
拆分后的代码应该是易控制、易维护的,业务职责也是明确单一的
AKF 立方体是一个叫 AKF 公司的技术专家抽象总结的应用扩展的三个维度
理论上按照这三个扩展模式,可以将一个单体应用无限扩展
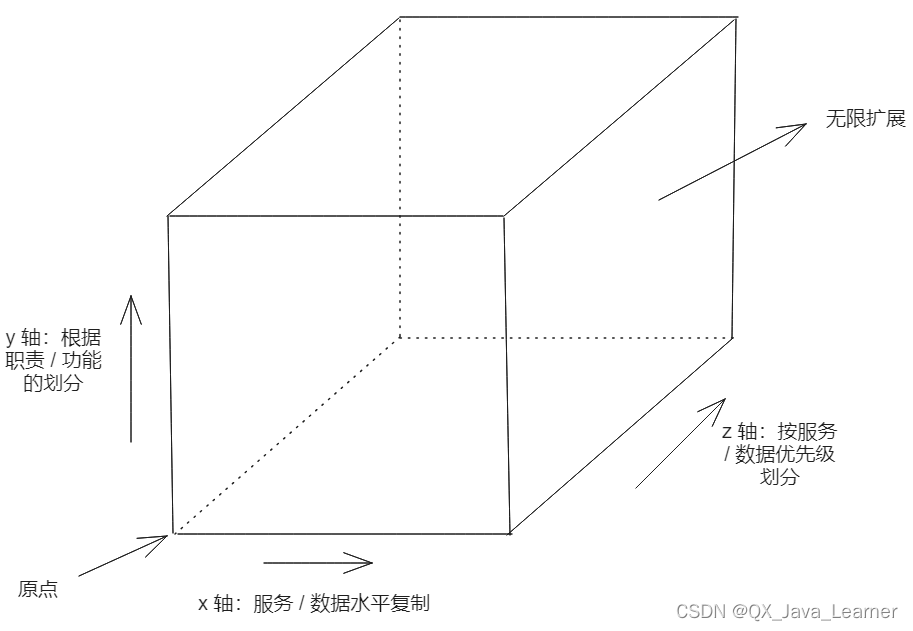
AKF 扩展立方体
- x轴:水平复制,即在负载均衡服务器后增加多个 Web 服务器
- y轴:功能分解,将不同职能的模块分成不同的服务。从 y 轴方向扩展,才能将巨型应用分解为一组不同的服务,例如,订单管理中心、商品信息管理中心等
- z轴: 对数据库的扩展,即分库分表(分布是将关系紧密的表放在一台数据库服务器上,分表是因为一张表的数据太多,需要将一张表的数据通过 Hash 放在不同的数据库服务器上)
三个维度的扩展对比如表:
| 纬度 | 优点 | 缺点 | 场景 |
|---|---|---|---|
| x 轴扩展 | 成本最低,实施简单 | 受指令集多少和数据集多少的约束。当单个产品或应用过大时,服务响应变慢,无法通过 x 轴的水平扩展提高速度 | 发展初期,业务复杂度低,需要增加系统容量 |
| y 轴扩展 | 可以解决指令集和数据集的约束,解决代码复杂度问题,可以实现隔离故障,可以提高响应时间,可以使团队聚焦更利于团队成长 | 成本相对较高 | 业务复杂,数据量大,代码耦合度高,团队规模大 |
| z 轴扩展 | 能解决数据集的约束,降低故障风险,实现渐进交付,可以带来最大的扩展性 | 成本最昂贵,且不一定能解决指令集的问题 | 用户指数级快速增长 |
下面看一下 AKF 的拆分实践:
- 拆分应用
x 轴:从单体系统或服务,水平克隆出许多系统,通过负载均衡分配请求
y 轴: 面向服务分割,基于功能或服务分割,例如,电商网站可以将登录、搜索、下单等服务进行 y 轴拆分,每一组在进行 x 轴的扩展
z 轴: 面向查找分割,基于用户、请求或数据分割,例如,可以将不同产品的 SKU 分到不同的搜索服务,可以将用户哈希到不同的服务等
- 拆分数据库
x 轴:从单库水平克隆为多个库上读,一个库写,通过数据库的自我复制实现,要允许一定的读写时延
y 轴:根据不同的信息类型分割为不同的数据库,即分库,例如,产品库、用户库等
z 轴: 按照一定算法进行分片,例如,将搜索按照 MapReduce 的原理进行分片,把 SKU 的数据按照不同的哈希值进行分片存储,每个分片在进行 x 轴冗余
要做好微服务的分层:梳理和抽取核心应用、公共应用,作为独立地服务下沉到核心和公共能力层,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求
对于服务的拆分,要使用迭代演进的方式,不能一次性完成所有服务的拆分,需要确保团队可接受,粒度适中,同时需要考虑 API 的版本兼容性
不能单纯的以代码量来对服务拆分的成果进行评估
MapReduce 原理参考文章: MapReduce基本原理(详解!)_mapreduce工作原理-CSDN博客
参考资料:《微服务架构实战》—— 张锋
一 叶 知 秋,奥 妙 玄 心