9.Join的应用
1.reduceJoin的应用
案例:将两个表合并成一个新的表
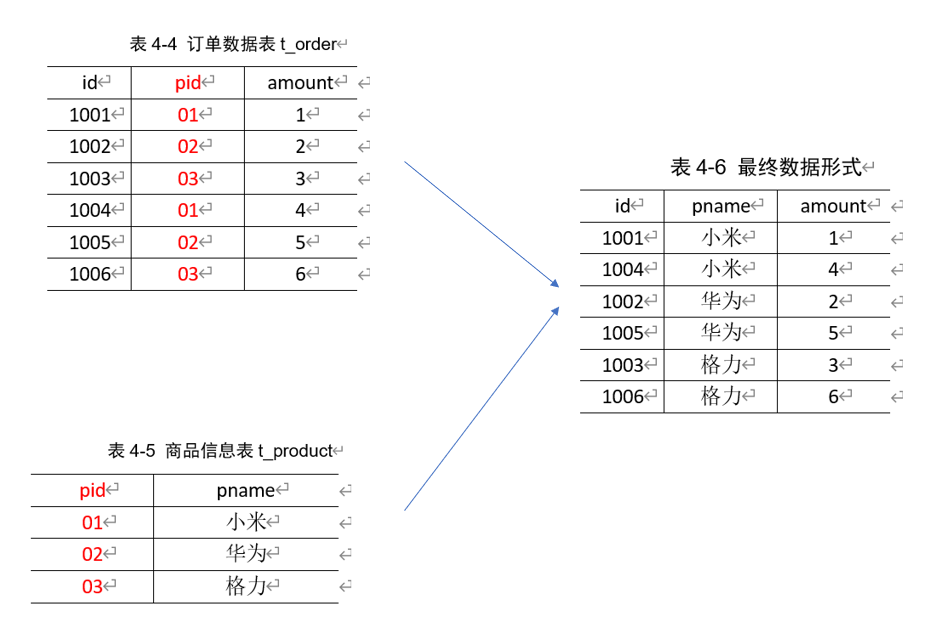
需求分析:通过将关联条件作为Map输出的key(此处指pid),将两表满足Join条件的数据并携带数据所来源的文件信息,发往同一个ReduceTask,在Reduce中进行数据的串联
思路:
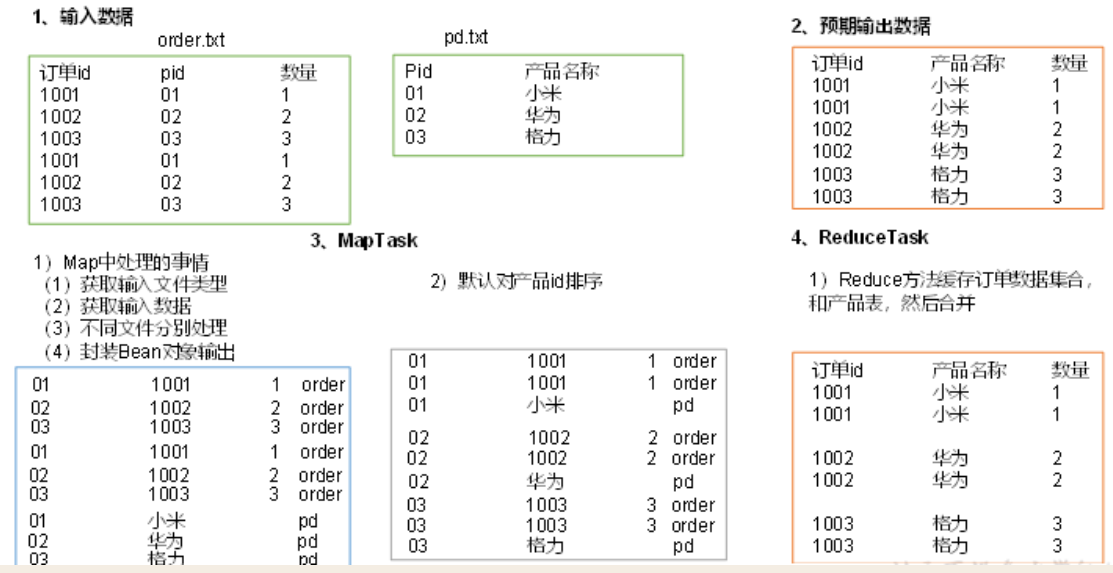
map:
将输入数据统一封装为一个Bean,此Bean包含了商品表和订单表的所有公共和非公共属性,相当于进行了全外连接,并新增加一个属性——文件名称,以区分数据是来自与商品表还是订单表,便于在reduce阶段数据的 处理;map输出的key是pid,value是bean
shuffle:
根据pid对bean进行排序,所有pid相同的数据都会被聚合到同一个key下,发往同一个reducetask
reduce:
对同一个pid下所有的bean,首先要区分出它们是来自于哪个表,是商品表还是订单表。如果是商品表,数据只有一条,保存其中的pname属性;如果是订单表,数据有多条,用保存的pname属性替换pid属性,并输出
代码:
(1)创建表格合并后的Order类
public class OrderPd implements Writable {
private String id; //订单id
private String pid; //产品id
private int amount; //产品数量
private String pname; //产品名称
private String flag; //判断是order表还是pd表的标志字段
}一键生成set/get/构造函数(略过)
重写toString():
@Override
public String toString() {
return id + "\t" + pname + "\t" + amount;
}
将这五个特征序列化:
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(pid);
out.writeInt(amount);
out.writeUTF(pname);
out.writeUTF(flag);
}
反序列化:
public void readFields(DataInput in) throws IOException {
this.id = in.readUTF();
this.pid = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.flag = in.readUTF();
}
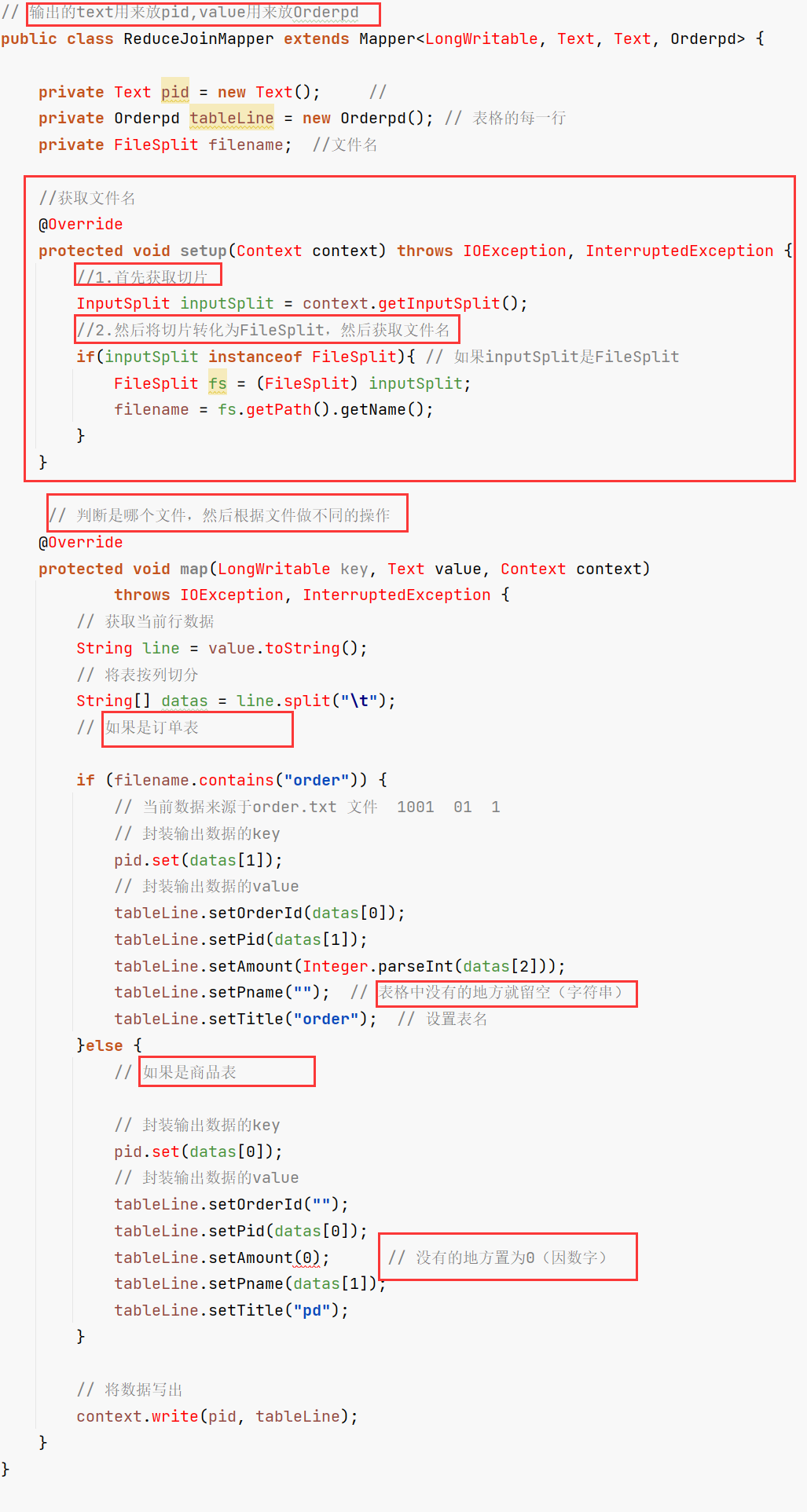
(2)编写mapper类:将两个表上下拼接到了一起
思路:先获取文件名,然后根据不同的文件名执行不同的操作
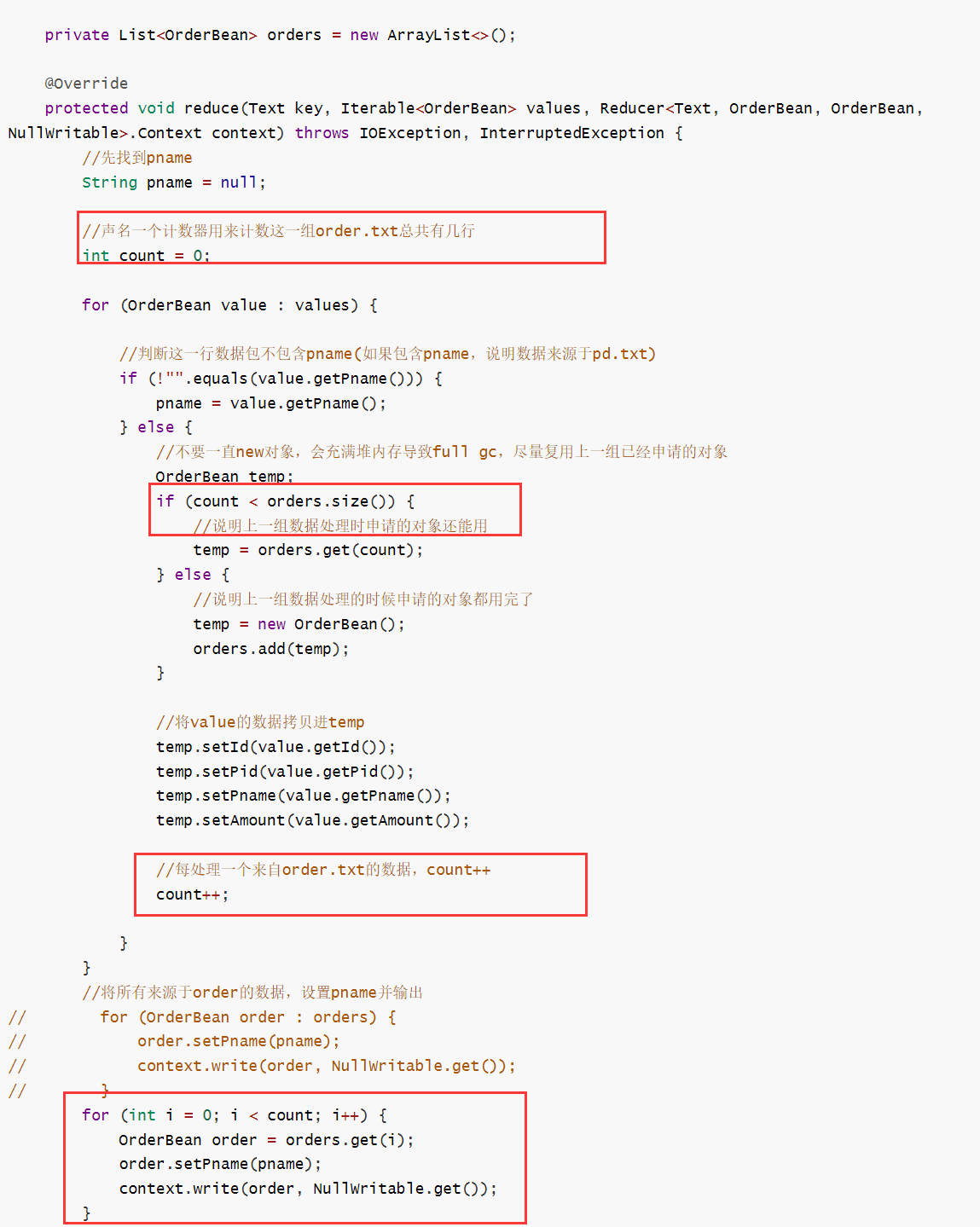
(3)编写reducer类:将一组的数据完成join
接受的key就是pid,value就是orderpd,输出的就只有orderpd.
思路:先找到一行中的pname,然后将来自order中的数据设置pname并输出

ps.以上的reducer类存在优化空间,因为创建临时变量的时候需要不断的new新空间,浪费大量内存,因此做出已下改进:每处理一次对象,就用之前申请的那个对象
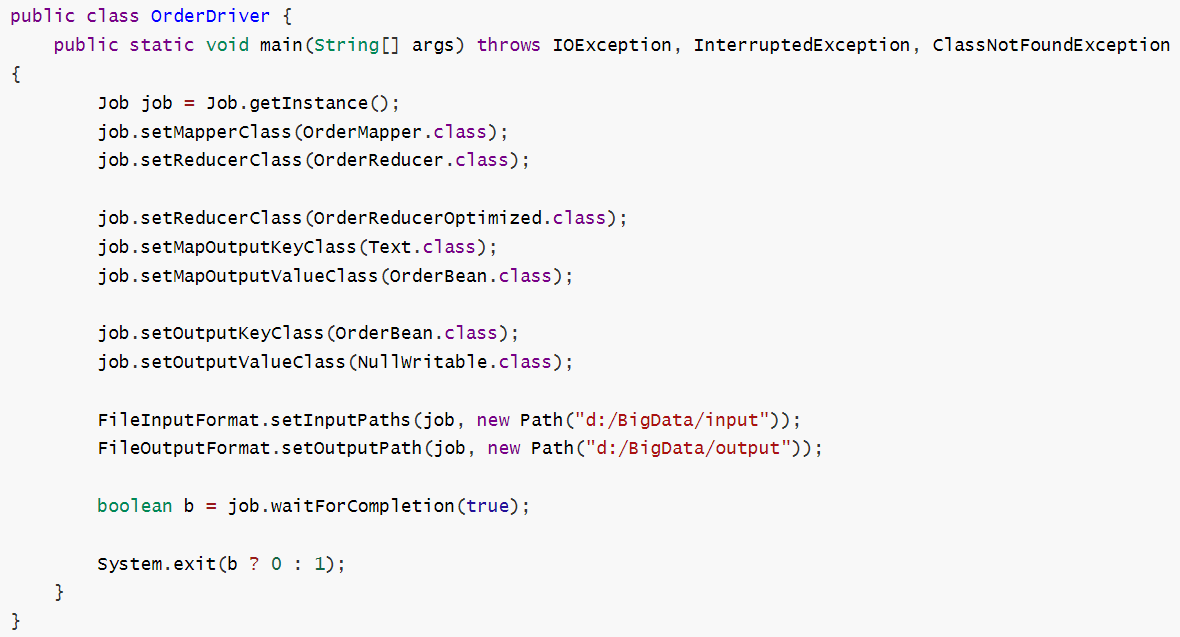
(4)编写driver类:
2.Mapjoin的应用
定义:
没有reduce过程,所有的工作都在map阶段完成,极大减少了网络传输和io的代价。如何实现:
上述的join过程可以看作外表与内表的连接过程,外表是订单表,外表大,外表是处理的对象;内表是商品表,内表小,内表是写进内存的对象。所以可以把内表事先缓存于各个maptask结点,然后等到外表的数据传输过来以后,直接用外表的数据连接内表的数据并输出即可
思路:

1)在driver中设置加载缓存文件,这样每个maptask就可以获取到该文件 ; 设置reducetask个数为0,去除reduce阶段,对应到这个需求就是遍历order表的时候,把pd表做成一个map写入缓存中方便随时调用拿到pname
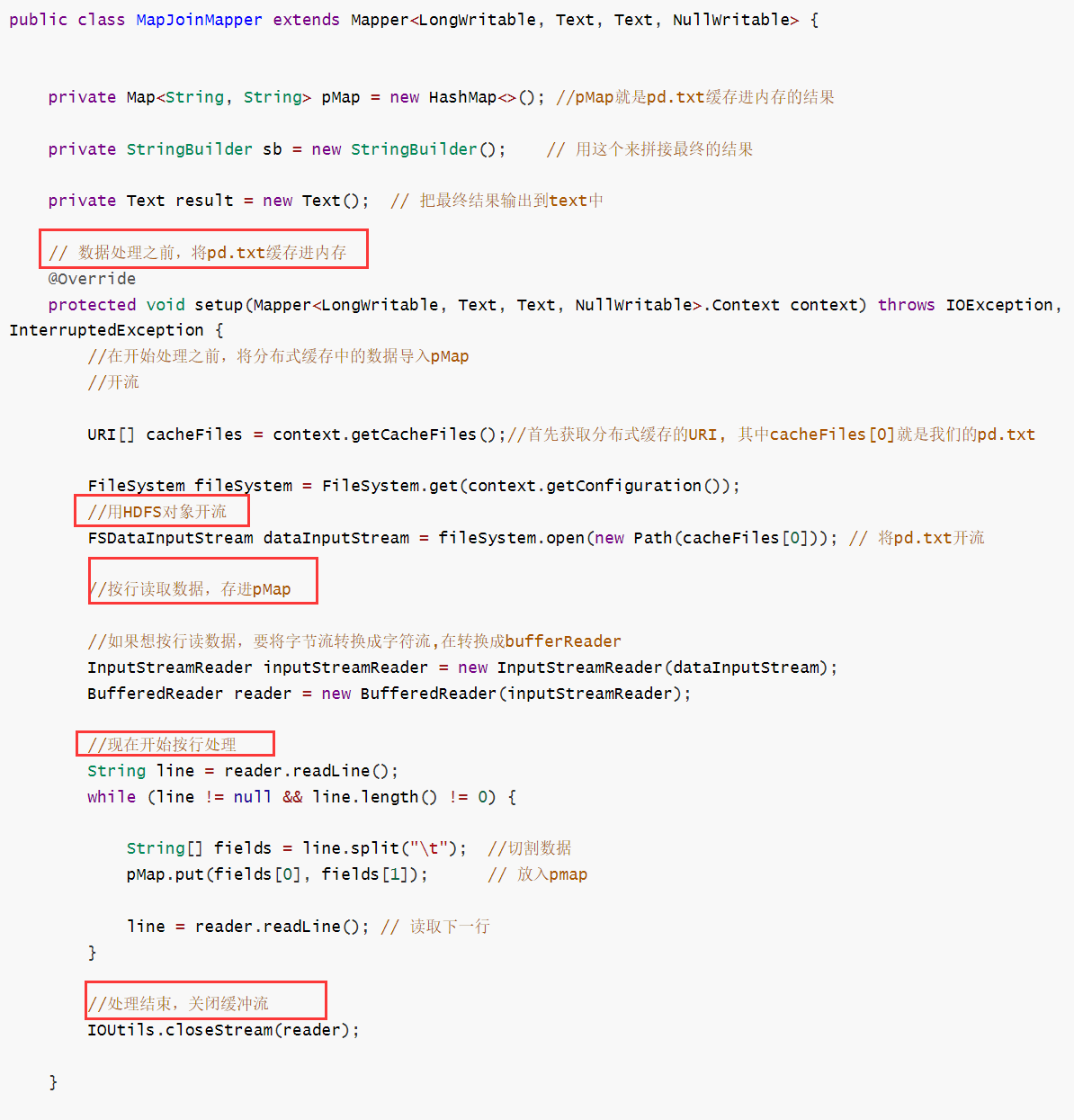
2)在setup方法中读取缓存文件,并将结果以kv的形式存入hashmap,k是pid,v是pname
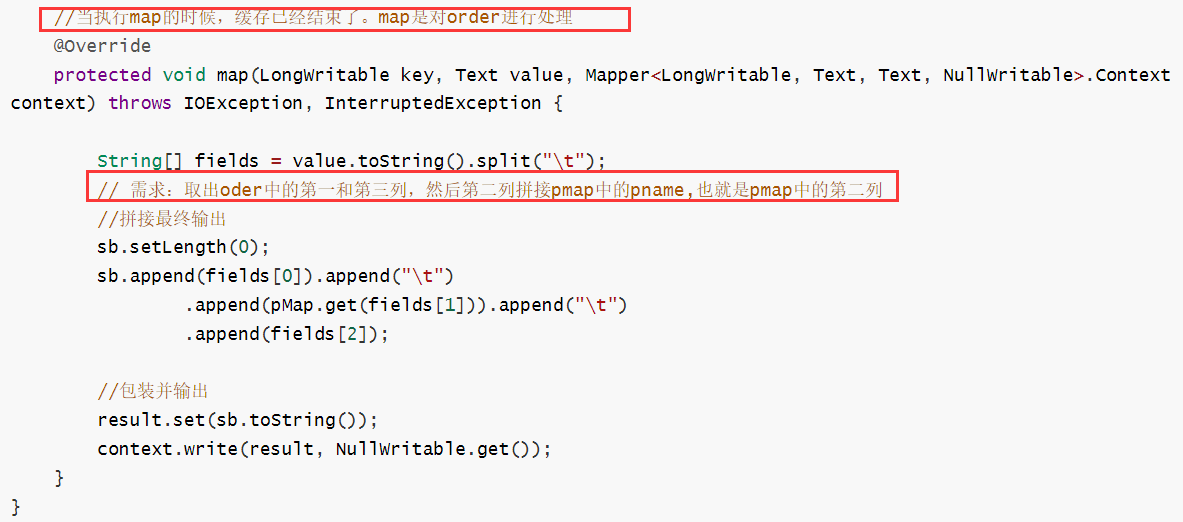
3)在map方法中,根据pid,通过hashmap找到pname,替换pid,写出结果
代码:
(1)mapper类
(2)driver类
