【C语言:数据在内存中的存储】
文章目录
- 1.整数在内存中的存储
- 1.1整数在内存中的存储
- 1.2整型提升
- 2.大小端字节序
- 2.1什么是大小端
- 2.2为什么有大小端之分
- 3.整数在内存中的存储相关题目
- 题目一
- 题目二
- 题目三
- 题目四
- 题目五
- 题目六
- 题目七
- 4.浮点数在内存中的存储
- 4.1浮点数存的过程
- 4.2浮点数取得过程

在这之前呢,我们已经学习了C语言的很多知识了,可是你是否有过这样的疑问?
- 各种类型的数据在内存中是如何存储的?
- 有的数据为何在内存中是反着放的?能正着放吗?
- 为什么有的浮点数不是自己想要的?
带着这些问题,我们来看下面的内容:
1.整数在内存中的存储
1.1整数在内存中的存储
我们都知道,整数在内存中是以二进制的形式存储的,但具体是怎么存的?
- 整数的2进制表示方法有三种,即原码、反码和补码。
- 三种表示方法均有符号位和数值位两部分,符号位都是⽤0表⽰“正”,⽤1表⽰“负”,最⾼的⼀位是被当做符号位,剩余的都是数值位。
- 正整数的原、反、补码都相同。
- 负整数的三种表示方法各不相同。
- 原码:直接将数值按照正负数的形式翻译成⼆进制得到的就是原码。
- 反码:将原码的符号位不变,其他位依次按位取反就可以得到反码。
- 补码:符号位不变,其它位按位取反,再+1就得到补码。
对于整形来说:数据在内存中其实存放的是补码。
为什么呢?
在计算机系统中,数值⼀律⽤补码来表⽰和存储。
原因在于,使⽤补码,可以将符号位和数值域统⼀处理;同时,加法和减法也可以统⼀处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
1.2整型提升
数据的二进制表示形式在内存中是要存够32个比特位的,那么对于char、short类型的数据在内存中又是如何存储的呢?答案是:整型提升
C语言中整型算术运算总是⾄少以缺省整型类型的精度来进行的。
为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型提升。
整型提升的意义:
- 表达式的整型运算要在CPU的相应运算器件内执⾏,CPU内整型运算器(ALU)的操作数的字节⻓度⼀般就是int的字节⻓度,同时也是CPU的通⽤寄存器的⻓度。因此,即使两个char类型的相加,在CPU执⾏时实际上也要先转换为CPU内整型操作数的标准⻓度。
- 通⽤CPU(general-purposeCPU)是难以直接实现两个8⽐特字节直接相加运算(虽然机器指令中可能有这种字节相加指令)。所以,表达式中各种⻓度可能⼩于int⻓度的整型值,都必须先转换为int或unsignedint,然后才能送⼊CPU去执⾏运算。
char a,b,c;
//.......
a = b + c;
在这一过程中,b和c先被提升为普通整型,然后再进行运算
加法运算执行完成后,此时先会发生截断,再存储到a中。
那么如何进行整型提升呢?
有符号整数提升是按照变量的数据类型的符号位来提升的⽆符号整数提升,⾼位补0
- 负数的整形提升
char c1 = -1;
1000001 -原码
11111110 -反码
11111111 -补码
变量c1的⼆进制位(补码)中只有8个⽐特位:
1111111
因为 char 为有符号的 char
所以整形提升的时候,⾼位补充符号位,即为1
提升之后的结果是:
11111111111111111111111111111111
- 正数的整形提升
char c2 = 1;
00000001 -原码、反码、补码
变量c2的⼆进制位(补码)中只有8个⽐特位:
00000001
因为 char 为有符号的
char 所以整形提升的时候,⾼位补充符号位,即为0
提升之后的结果是:
00000000000000000000000000000001
//⽆符号整形提升,⾼位补0
2.大小端字节序
2.1什么是大小端
当我们了解了整数在内存中存储后,我们调试看⼀个细节:
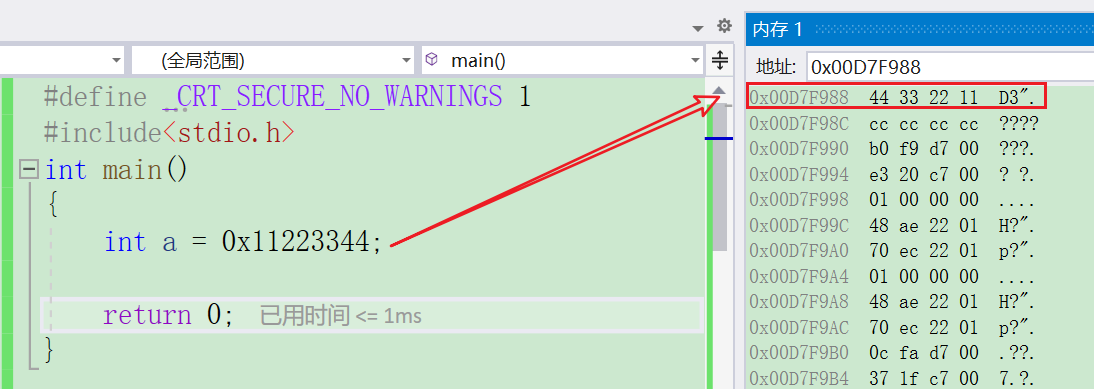
调试的时候,我们可以看到在a中的 0x11223344 这个数字是按照字节为单位,倒着存储的。这是为什么呢?
其实超过⼀个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分为⼤端字节序存储和⼩端字节序存储,下⾯是具体的概念:
⼤端(存储)模式:是指数据的低位字节内容保存在内存的⾼地址处,⽽数据的⾼位字节内容,保存在内存的低地址处。
⼩端(存储)模式:是指数据的低位字节内容保存在内存的低地址处,⽽数据的⾼位字节内容,保存在内存的⾼地址处。
2.2为什么有大小端之分
那为什么会有大小端之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着⼀个字节,⼀个字节为8bit 位,但是在C语言中除了8 bit 的char 之外,还有16 bit 的 short 型,32 bit 的 long 型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于⼀个字节,那么必然存在着⼀个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:⼀个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么0x11 为⾼字节, 0x22 为低字节。
- 对于⼤端模式,就将 0x11 放在低地址中,即 0x0010 中,0x22 放在⾼地址中,即 0x0011 中。
- ⼩端模式, 0x11 放在高地址中,即 0x0011 中,0x22 放在低地址中,即 0x0010 中。
- 我们常⽤的 X86 结构是⼩端模式,⽽KEIL C51则为⼤端模式。很多的ARM,DSP都为⼩端模式。有些ARM处理器还可以由硬件来选择是⼤端模式还是⼩端模式。
下面给出一道真题:
设计⼀个⼩程序来判断当前机器的字节序。(10分)
#include <stdio.h>
int check_sys()
{
int i = 1;
return (*(char*)&i);//char 类型之访问一个字节
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("⼩端\n");
}
else
{
printf("⼤端\n");
}
return 0;
}
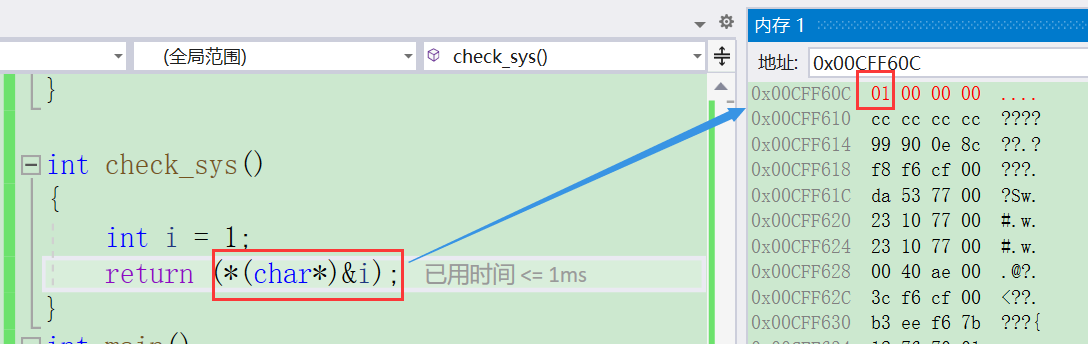
当前使用的VS编译器,正是小端存储。
当学习了共用体的知识后,还可以这样来设计,是不是很巧妙呀。
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;
}
3.整数在内存中的存储相关题目
题目一
int main()
{
//10000000000000000000000000000001 -1的原码
//11111111111111111111111111111110 反码
//11111111111111111111111111111111 补码
//放进char类型数中,发生截断
//仅保留后8位
char a = -1;
//a : 11111111
//发生整型提升,有符号数,按符号位提升
//11111111111111111111111111111111 --补码
//10000000000000000000000000000001 -- 原码
signed char b = -1;
//b : 11111111
//发生整型提升,有符号数,按符号位提升
//11111111111111111111111111111111 --补码
//10000000000000000000000000000001 -- 原码
unsigned char c = -1;
//c : 11111111
//发生整型提升,无符号数,补0
//00000000000000000000000011111111 -- 补码 == 原码
printf("a=%d,b=%d,c=%d", a, b, c); //%d,十进制形式打印有符号整数,会发生整型提升
//a=-1,b=-1,c=255
return 0;
}
题目二
int main()
{
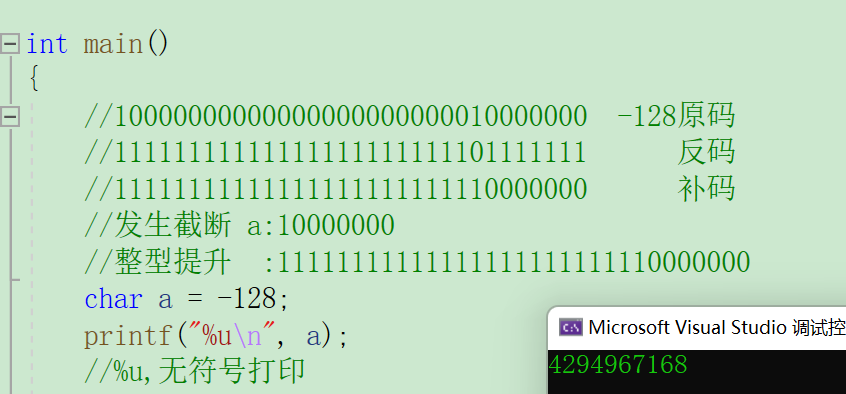
char a = -128;
printf("%u\n",a);
return 0;
}
在做题之前,我们要知道-128能放进一个char类型的数中吗?

从图中,我们可以清楚的看出char类型的取值范围,因此,a中可以放下、
题目三
int main()
{
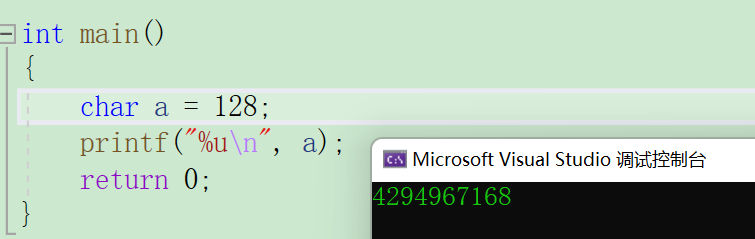
char a = 128;
printf("%u\n", a);
return 0;
}
在这里,我们知道char类型的取值范围是 -123~ 127 ,是存不下128的,存到127再加1就变成了-128,那和上一题的结果就一样了。
题目四
此题注意:\0的ascll码值就是0
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
//a: -1,-2,-3...-128 127,126,125....3,2,1,0
//共255个数
printf("%d", strlen(a));
return 0;
}
题目五
此题,注意变量 i 的值是无符号char ,范围是 0 ~ 255,那就打印255个hello world ?
255+1 = 0 又变回去了,因此此处是死循环
unsigned char i = 0;
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");
}
return 0;
}
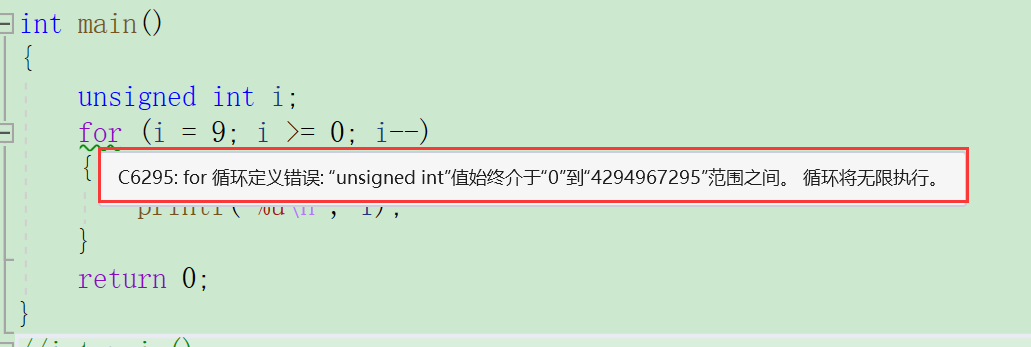
题目六
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
}
题目七
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
//4,2000000
return 0;
}

4.浮点数在内存中的存储
先看以下这个题目
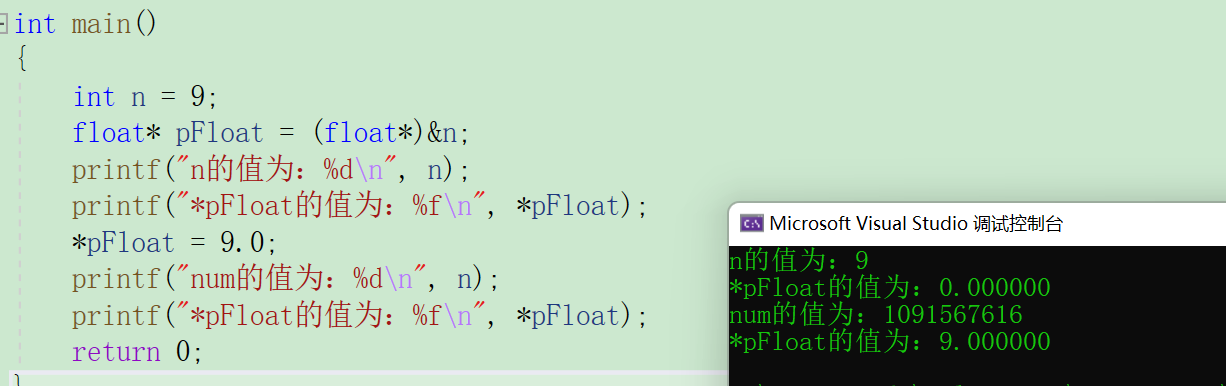
我们发现结果跟我们想的并不一样,原因是什么呢?
上⾯的代码中, num 和 *pFloat 在内存中明明是同⼀个数,为什么浮点数和整数的解读结果会差别这么大?
要理解这个结果,⼀定要搞懂浮点数在计算机内部的表⽰⽅法。
根据国际标准IEEE(电气和电⼦工程协会)754,任意⼀个⼆进制浮点数V可以表示成下⾯的形式:
V = (−1) S ∗ M∗ 2E
- (−1)S 表⽰符号位,当S=0,V为正数;当S=1,V为负数
- M 表⽰有效数字,M是⼤于等于1,⼩于2的
- 2E表⽰指数位
举例来说:
⼗进制的5.0,写成⼆进制是 101.0 ,相当于 1.01×22 。
那么,按照上⾯V的格式,可以得出S=0,M=1.01,E=2。
⼗进制的-5.0,写成⼆进制是 -101.0 ,相当于 -1.01×22 。那么,S=1,M=1.01,E=2。
IEEE 754规定:
对于32位的浮点数,最⾼的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M
对于64位的浮点数,最⾼的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M

4.1浮点数存的过程
IEEE 754 对有效数字M和指数E,还有⼀些特别规定:
前⾯说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中 xxxxxx 表⽰⼩数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第⼀位总是1,因此可以被舍去,只保存后⾯的xxxxxx部分。⽐如保存1.01的时候,只保存01,等到读取的时候,再把第⼀位的1加上去。这样做的⽬的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第⼀位的1舍去以后,等于可以保存24位有效数字,更加精确。
至于指数E,情况就比较复杂:
⾸先,E为⼀个⽆符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0 ~ 255;如果E为11位,它的取值范围为0~2047。
但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存⼊内存时E的真实值必须再加上⼀个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。
⽐如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
4.2浮点数取得过程
指数E从内存中取出还可以再分成三种情况:
- E不全为0或不全为1
这时,浮点数就采⽤下⾯的规则表示:
即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第⼀位的1。
⽐如:0.5 的⼆进制形式为0.1,由于规定正数部分必须为1,即将⼩数点右移1位,则为1.0*2^(-1),其E为-1+127(中间值)=126,表⽰为01111110,⽽尾数1.0去掉整数部分为0,补⻬0到23位00000000000000000000000,则其⼆进制表⽰形式为
:0 01111110 00000000000000000000000
- E全为0
这样意味着什么?我加了一个127之后,还为0,那么你原来得值就是 -127
那就是:(-1)s *M * 2 -127 ,-127次方,这都多小了
那这时怎么办呢?浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第⼀位的1,⽽是还原为0.xxxxxx的⼩数。这样做是为了表⽰±0,以及接近于0的很⼩的数字
- E全为1
这样意味着什么?我加了一个127之后,为255,那么你原来得值就是 128
那就是:(-1)s *M * 2 128 ,128次方,这得多大呀
这是,就表⽰±⽆穷⼤(正负取决于符号位s);
了解了浮点数得存储规则后,我们再回到题目中。
为什么 9 还原成浮点数,就成了 0.000000呢?

浮点数9.0,为什么整数打印是1091567616?


现在我们是不是就弄清楚缘由了呀!
结论
- 部分浮点数在内存中是无法精确保存的
- double类型的精度比float高
- 浮点数比较大小的时候,不能直接使用 ,应该给一个精度(一个范围)