AntDB“超融合+流式实时数仓”——打造分布式数据库新纪元
(一)
前言
据统计,在信息化时代的今天,人们一天所接触到的信息量,是古人一辈子所能接收到的信息量的总和。当今社会中除了信息量“多”以外,人们对信息处理的“效率”和“速度”的要求也越来越高。譬如,对于很多企业决策者来说,在当前的经济形势下需要尽一切可能降本增效。过去每周看看经营报表的习惯,现在慢慢转变为利用实时可视化的方式来随时分析企业当前的经营状况。
数据库作为信息的核心载体,在过去的半个世纪中,基本设计理念一直是“请求发送+结果返回”的模式。这个机制直接被Apache Storm、Spark Streaming、Flink等流处理框架所借用。
但是,所有对实时数据处理的能力,都是建立在数据库引擎之外的。真正与数据贴合最为紧密的数据库产品,在过去的20年中并没有充分发挥自己的能力。它们还在使用最传统的方式对记录进行一条条预处理,需要经常从外部实时调取额外数据进行手工关联,对开发和运维的负担极大。
因此,数据库融入流式数据处理能力,通过SQL+触发器对实时数据的处理逻辑与拓扑进行定义,是这几年行业中提出的全新课题。
近几年,国外多家企业开始了这方面的尝试,力争大幅度降低未来实时应用的开发难度与运维复杂性。实际上,国内也已经有厂商基于自身技术积累,和对未来应用场景的准确把握,逐步将流式数据处理能力融入到数据库产品中。亚信科技AntDB数据库就是其中具有典型性的代表,也是国内为数不多的,率先研发并具备“超融合+流式实时数仓”能力的数据库。
(二)
超融合架构,打造分布式数据库新纪元
上一个十年,数据规模大,查询复杂度高、关联度高的金融与互联网行业高速发展,助推了国产数据库的“分布式”和“云化”过程。分布式数据库具有平滑扩展、高可靠、低成本等特性优点;而“云化”则有利于降低数据库运维成本,灵活调度资源。
这个十年,“数智化转型”是推动经济社会从“量增”到“质变”的快速路。用户对数据库的需求日益精细化,从技术底层支撑多业务的系统架构,将越来越受到企业侧的青睐。在此背景下,多引擎数据库的融合能力开始出现,HTAP、湖仓一体、流批一体等都是这个趋势的先行者,即超融合。
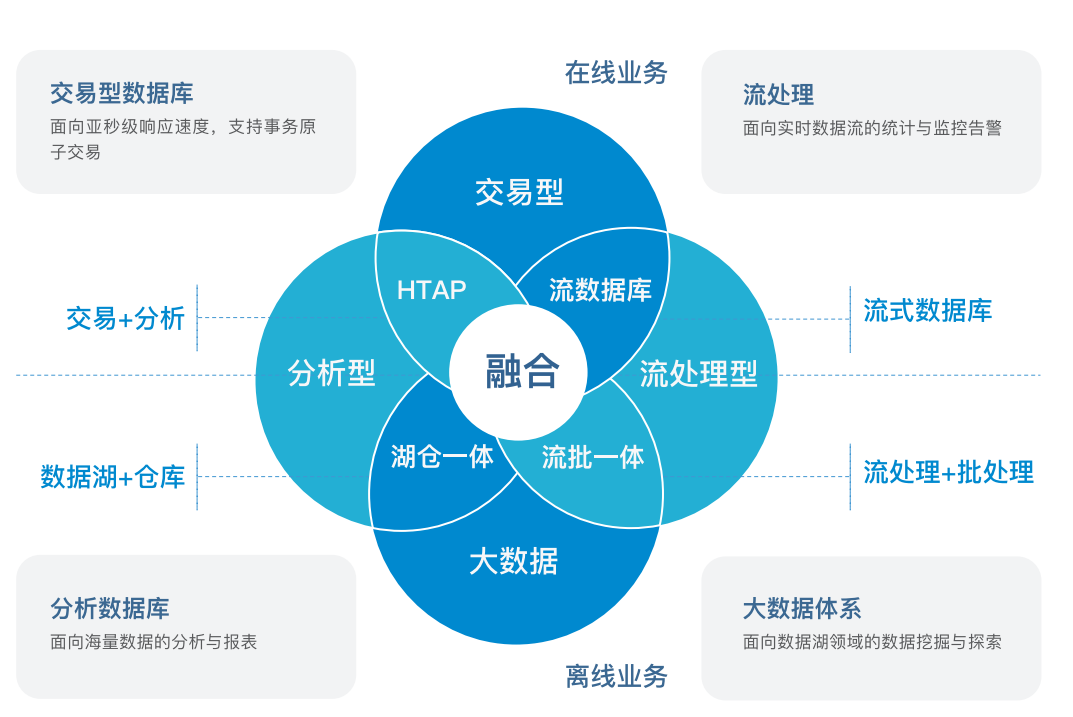
图:AntDB数据库超融合框架
亚信科技AntDB数据库提出了全新的“超融合”理念,即融合多引擎、多能力,满足企业越发复杂的混合负载场景与混合数据类型业务需求。AntDB的“超融合”框架,能够充分利用分布式数据库引擎的架构优势,在HTAP概念上进行进一步拓展,将时序存储、流处理执行以及向量化分析等多引擎进行统一架构封装。
在同一个数据库集群支持多种业务模型,支持多样化的数据需求,大大降低业务系统的复杂性,实现统一框架下的“一站式数据管理”。
关于AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。