【MySQL】数据表的增删查改

1、CRUD的解释
C:Create增加
R:Retrieve查询
U:Update更新
D:Deleta删除
2、添加数据
2.1 添加一条记录
添加数据是对表进行添加数据的,表在数据库中,所以还是得先选中数据库,选中数据库还在进行一些表得操作
现在我们有一张 student 表,里面有两个属性分别为:id和name

接下来我们就给student这个表进行添加数据
选中数据库
对表进行添加一行数据:insert into 表名 values(列,列,......);

注:
在SQL中,单引号和双引号都表示字符串,SQL没有字符类型,只有字符串类型
SQL中得符号都是英文状态下的
values括号中的内容,个数和类型都要和表的结构匹配
2.2 添加指定列的数据
首先我们来看student表的结构

如果我们只对一个列进行添加数据,那么另一个列默认为NULL
选中数据库
对表进行添加指定列的数据:insert into 表名 (列名) values (数据);

添加完后我们可以通过查询表看表里面内容

注:如果相对多个指定列进行添加元素,用逗号分隔即可
2.3 添加多条记录
选中数据库
对表进行添加多条记录:insert into 表名 values (列,列,......), (列,列,......), ......;

添加完后我们也可以通过查询表看表里面内容

一次插入多条数据和一条一条的插入数据,哪个效率更高呢?
答:当然是一次插入多条数据的效率高,因为 MySQL 是一个“客户端服务器”结构的程序,每次插入数据的时候都要通过网络访问、发起网络请求和返回网络响应,数据库服务器把数据保存在硬盘上每次都要访问硬盘,这些都有一定的时间开销,所有一次插入多条数据比一条一条插入数据的效率要高
3、查询数据
在数据库中没有查看整张表的操作,只有对表进行查询的操作
只要对表进行增删改操作,一般都会用查询看对表的增删改操作是否成功
查询操作不仅仅可以对指定条件的数据进行查看操作,还可以通过查询查看整张表
3.1 全列查询
全列查询就是查看整张表的数据
选中数据库
查询整张数据表:select * from 数据表

注:*是通配符,代表所有的列
当表中数据非常多的时候,建议不用全列查询。因为服务器中存了很多的数据,此处的查询操作就会遍历所有的数据,把数据从硬盘中读取处理,通过网卡来进行发送。如果数据量非常大,那么就容易把硬盘IO吃满或者把网络带宽吃满!此时当有用户想要访问这个服务器,可能就会因为io和带宽吃满了,而无法正常访问
3.2 指定列查询
指定列查询就是查询指定的列
选中数据库
指定列查询:select 列名 from student;

注:当查询多个列时,列名用逗号分隔
3.3 查询列为“表达式”
查询列为表达式就是对列进行一个简单的运算
假设我们现在有个分数表score:

现在我们就对这个表进行查询列为表达式
选中数据库
列为表达式的查询:select 表达式列名 from 表;

注:进行表达式查询的时候,查询的结果只不过是一个“临时表”,这个临时表不会写入到硬盘中,所以当我们进行表达式查询的时候,不必担心原来的表会被改变
3.4 给查询结果的列指定别名
当采用列为表达式的查询的时候,默认列名为表达式

列名为表达式的时候,就会造成列名不美观,为了让列名美观就可以指定别名
选中数据库
方法一:
给查询结果的列指定别名:select 表达式列名 别名 from 表名;

方法一是将表达式列名和别名用空格进行分隔的,这样写别名,容易看错
方法二:
给查询结果的列指定别名:select 表达式列名 as 别名 from 表名;

方法二是将表达式列名和别名用as隔开,这样就更清晰,不容易看错。虽然可以将 as 省略变成方法一的格式,但是不推荐
3.5 对查询的相同数据进行去重
去重就是把有重复的记录,合并成一个
有一个 score 成绩表

我们现在对 score这个表进行查询姓名这一列

大家可以看到姓名查询的时候,有两个姓名为赵六。但是我们现在只想显示一个赵六,此时就可以用到去重
选中数据库
对查询结果去重:select distinct 列名 from 表名;

当指定多个列的时候,则要求所有列都相同才算重复
3.6 对查询结果进行排序
还是 score 这张表,表的内容如下:

3.6.1 升序排序
选中数据库
对查询结果进行升序排序:select 列名 from 表名 order by 列名 asc;

asc 是升序排序,当不写 asc 的时候默认也是升序排序
3.6.2 降序排序
选中数据库
对查询结果进行降序排序:select 列名 from 表名 order by 列名 desc;

desc 降序排序
desc 不是查看表的结构嘛,为什么有可以用作降序排序?
答:这个纯属巧合,一个是 describe 的缩写,一个是 descend 的缩写
注:如果排序的列中有 NULL,则将 NULL 视为“最小值”
3.6.3 针对表达式列名的别名进行排序
选中数据库
针对表达式列名的别名进行排序:select 表达式列名 as 别名 from 表名 order by 别名 asc/desc;
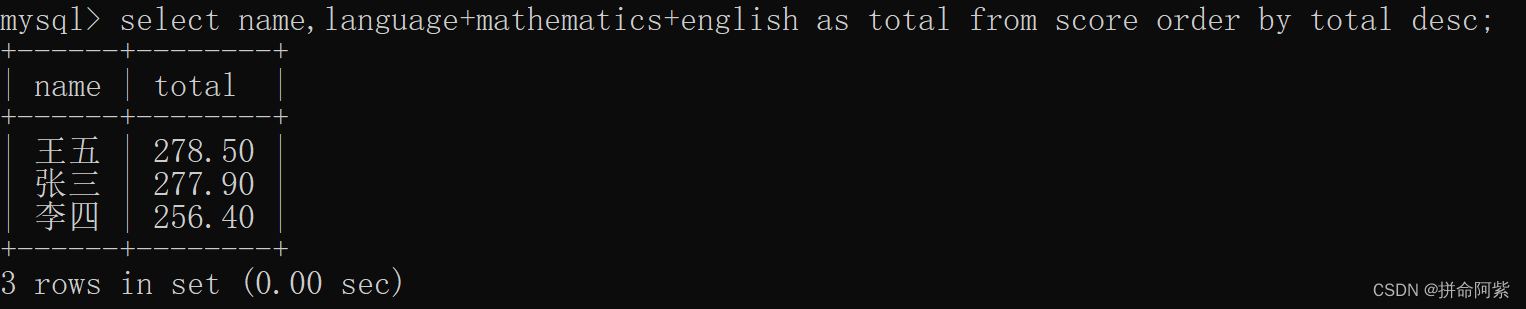
注:SQL中 NULL 和任何值进行运算结果还是 NULL
3.6.4 采用多个列进行排序
选中数据库
多个列进行排序:select * from 表名 order by 列名 asc/desc,列名 asc/desc;

当采用多个列进行排序的时候,先以第一个列为准,如果第一个列值相同,再比较第二个列
3.7 条件查询
条件查询就是针对查询结果,按照一定的条件进行筛选
3.7.1 运算符
比较运算符:
运算符 | 说明 |
>,>=,<,<= | 大于,大于等于,小于,小于等于 |
= | 等于,NULL不安全,例如:NULL=NULL结果是NULL |
<=> | 等于,NULL安全,例如:NULL<=>NULL的结果是TRUE |
!=,<> | 不等于 |
between a0 and a1 | 范围匹配,[a0,a1],如果a0<=value<=a1,返回TRUE |
in(option,...) | 如果是option中的任意一个,返回TRUE |
is null | 是NULL |
is nut null | 不是NULL |
like | 模糊匹配,%表示任意多个(包括0个)任意字符,表示任意一个字符 |
逻辑运算符:
运算符 | 说明 |
and | 多个条件必须都为TRUE,结果才为TRUE |
or | 任意一个条件为欸TRUE,结果才为TRUE |
not | 条件为TRUE,结果为FALSE |
注:
where 条件可以使用表达式,但是不能使用别名
and 的优先级高于or,再同时使用时,需要使用小括号包裹优先执行的部分
TRUE可以用 1 表示,FALSE可以用 0表示
3.7.2基本查询
现在有一张 score 表:

现在我们需要查询language语文成绩低于90分的同学
选中数据库
基本查询:select * from 表名 where 列名 < 值;

假设我们现在需要查询三门成绩总和小于270的同学
选中数据库
基本查询:select * from 表名 where 表达式 < 270;

3.7.3 and 和 or
1、and
and 是条件都成立的情况下,结果才为true
现在我们查询 language 和english成绩都在90分以上的同学
选中数据库
and 条件查询:select * from 表名 where 列名 > 值 and 列名 > 值;

2、or
or 表达式只要有一个成立,结果就为 true
查询mathematics和english只要有一门大于90的同学
选中数据库
or条件查询: select * from 表名 where 列名 > 值 or 列名 > 值;

3.7.4 范围查询
between ... and ...
between a0 and a1:表示查询范围在 [a0,a1] 这个区间内
假设我们现在查询mathematics成绩在80~90内的同学信息
选中数据库
范围查询:select * from 表名 where 列名 between 值 and 值;

in
in(值,...):当数据和in括号里的值相同时,则为true
现在有一张学生表:

现在查询年龄成绩为 16,19,23的同学信息
选中数据库
范围查询: select * from 表名 where 列名 in(值,值,...);

3.7.5 模糊查询
%:匹配任意0个或多个字符
_:匹配一个任意字符
我们现在有这样一张student表:

现在我们要查询所有姓赵的同学,因为我们不知道姓赵的同学名有几个字,所有此时就需要用 % 去匹配零个或多个字符
选中数据库
模糊查询(%):select * from 表名 where 列名 like '赵%';

如果我们现在要查询姓赵,名只有一个字的,此时可以用_来进行匹配
选中数据库
模糊查询(_):select * from 表名 where 列名 like '赵_';

查询姓赵,名只有两个字的
选中数据库
模糊查询(_):select * from 表名 where 列名 like '赵__';

3.8 分页查询
分页查询是采用 limit 来实现的,通过这个分页查询可以先至查询结果的数量
选中数据库
分页查询:select * from 表名 limit 值;

limit 后面的值,表示这次查询最大结果的数量
搭配 offset 就可以指定从第几条开始进行筛选了,offset 的值从0开始计算
选中数据库
分页查询:select * from 表名 limit 值 offset 值;

这个查询表示从第二个开始向后查询三个数据
因为 offset 的值是从 0 开始计算的,所有第一项是0,第二项是 1,...
4、修改数据
上述的条件查询不仅仅可以搭配 select 使用,还可以搭配 updata/delete使用,对应的条件的用法,也是一样的
现在有一张student表:

现在我们要将赵小六的名字改为赵小七
选中数据库
修改数据:update 表名 set 列名 = 值 where 条件;

接下来我们就通过查询表,看看赵小六是否改为了赵小七

修改操作是会修改表里面的内容的,修改完成之后就会持久生效
updata修改多个列时,多个列之间用逗号个隔开,如:update 表名 set 列名 = 值,列名 = 值 where 条件;
update 还可以搭配 order by 和 limit 等子句来进行使用
5、删除数据
现在我们有一张student表:

现在我们要将这张表里面的赵小七这一行给删除
选中数据库
删除数据:delete from 表名 where 条件;

6、总结
插入 insert:
插入一行:insert into 表名 values (值,值,值,...);
插入指定列:insert into 表名 (列名,列名,列名,...) values (值,值,值,...);
插入多行:insert into 表名 values (值,值,值,...),(值,值,值,...),(值,值,值,...),......;
查询 select:
全列查询:select * from 表名;
指定列查询:select 列名 from 表名;
带表达式的查询:select 表达式 from 表名;
带别名的查询:select 列名/表达式 as 别名 from 表名;
去重查询:select distinct 列名 from 表名;
排序查询:select 列名 from 表名 order by 列名/表达式/别名 asc/desc;
条件查询:select 列名 from 表名 where 条件;
修改update:
update 表名 set 列名 = 值 where 条件;
删除 delete:
delete from 表名 where 条件;