玩转ChatGPT:Auto-GPT项目部署与测评
一、Auto-GPT简介
最近,以ChatGPT为代表的超大规模语言模型火出了圈,各种二次开发项目也是层出不穷。
这周在AI圈炸街的是Auto-ChatGPT,在GitHub上已经61.4K的点赞了。
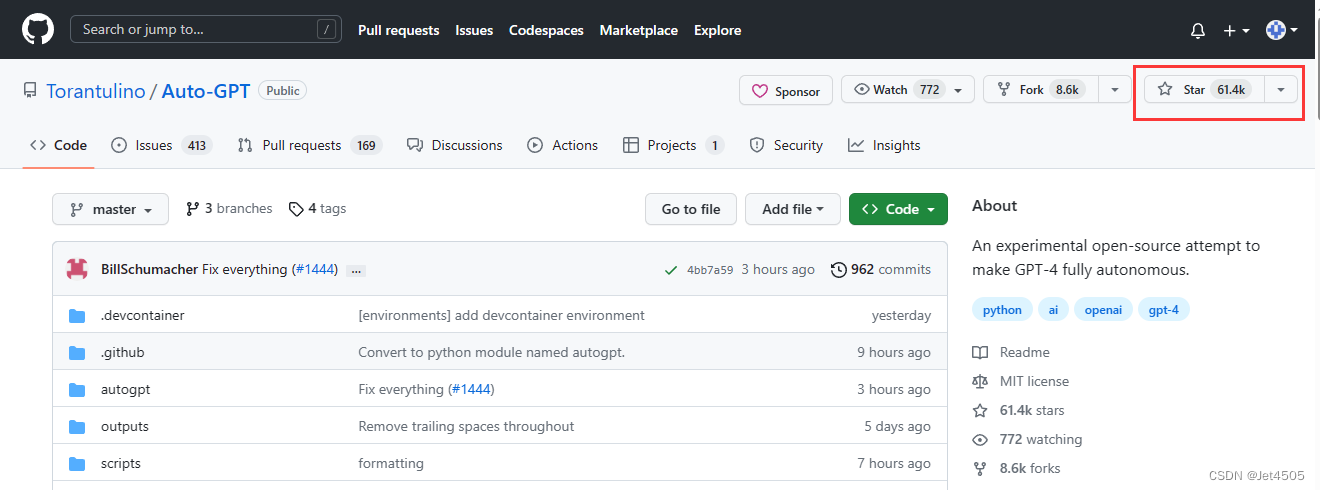
项目地址:https://github.com/Torantulino/Auto-GPT
用项目的原话介绍:“Auto-GPT是一个实验性的开源应用程序,展示了GPT-4语言模型的能力。这个程序由GPT-4驱动,自主地开发和管理企业,以增加净值。作为GPT-4完全自主运行的第一个示例之一,Auto-GPT推动了AI的可能性边界。”
小Chat是我们的得力助手,但在使用它完成任务的时候,我们需要使用“咒语”来唤醒它的神奇力量。如果你输入的“咒语”不够合适,小Chat就会抗拒你,然后你只能继续寻找合适的“咒语”,直到小Chat心情好为止。但如果你成功施展了合适的“咒语”,小Chat就会跟你打成一片,愉快地回答你的问题。接下来,你只需要不断使用“咒语”向它提问,直到你完成了任务。这个过程,叫做“人在回路”,熟悉不,这个概念就是在《流浪地球2》的彩蛋中,MOSS跟图恒宇说的:“基于对丫丫意识进行人在回路的学习,balabala”。
那么,作为一个成熟的通用人工智能(Artificial General Intelligence,AGI),TA应该学会自己做迭代思考,从而达到最终地目的。比如说,导师问你:“Mp1p蛋白有什么作用?”,作为一个成熟地科研狗,你大概率就会去百度、谷歌、Pubmed找相关文献资料,然后自己出个一二三条。
而这就是Auto-GPT项目想要做的:让人工智能能够像人类一样,通过自我迭代思考来完成任务。因此它具有如下特性:
(1)接入互联网:得会上网,能够通过搜索和信息收集获取各种知识。
(2)长短期内存管理:得有好的记忆力,能够对重要的信息进行长期存储,同时也能快速访问短期内存,方便及时处理任务。
(3)GPT-4文本生成:还需要有文笔,能够使用GPT-4生成高质量的文本,如文章、邮件等。
(4)访问流行网站和平台:要像人类一样,了解最新的时事和热门话题,就必须知道访问哪些流行的网站和平台。
(5)GPT-3.5文件管理:最后,还得会整理文件,像GPT-3.5一样,能够高效地进行文件存储和管理。
二、Auto-GPT部署
先说明部署的必备条件:
- 网络通畅;
- 有小Chart的账号(因为要用到OpenAI的API Key),不需要PLUS账号;
- 安装Python 3.8以上(我的是基于Anaconda环境)。
以上,缺一不可。
可选项目:
- PINECONE的API Key(记忆功能);
- GOOGLE_API_KEY和CUSTOM_SEARCH_ENGINE_ID(接入谷歌引擎);
第一步 下载项目
(a)这个简单,直接去项目的网址进行下载即可: “Code”——“Download ZIP”;
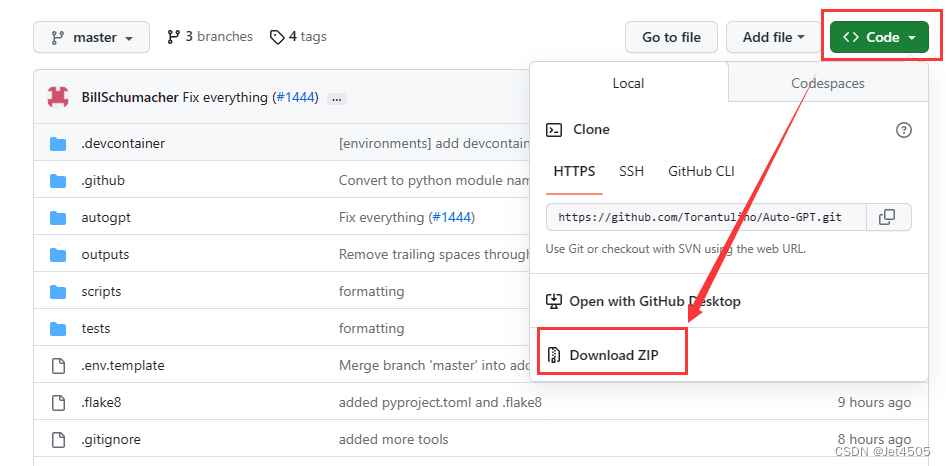
(b)解压到一个路径,最好是全英文的路径,比如我的是:E:\Auto-GPT\Auto-GPT-master-0415;
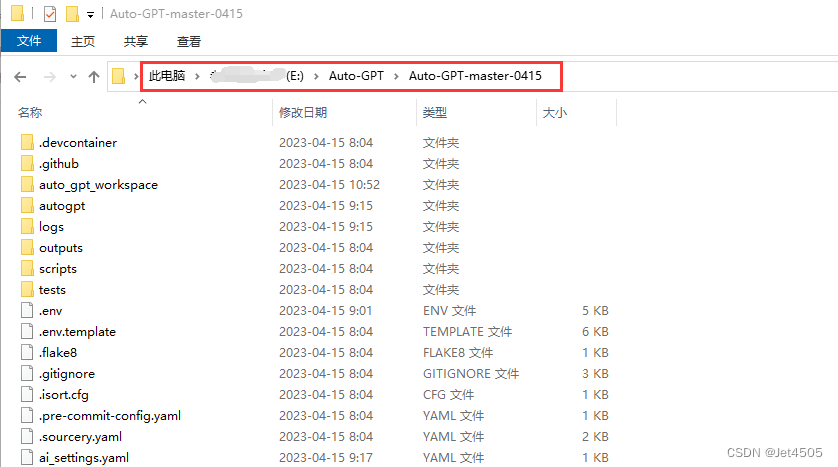
第二步 安装python依赖库
(a)项目需要的依赖库,都在这个名为“requirements.txt”的文件夹里了,打开看,共是26个;

(b)记得先安装Anaconda,打开Anaconda Prompt (anaconda),输入代码:
conda create -n gptac_venv python=3.9 #生成一个名为gptac_venv的环境,我的python版本是3.9注释:这里用旧图了,跟之前一样的步骤
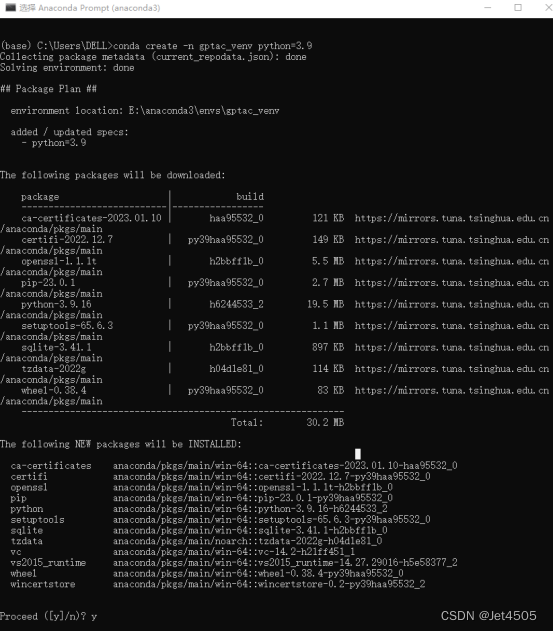
这里选y;

这样就是安装成功了。
(c)进入新建立的环境,输入代码:
conda activate gptac_venv注释:这里用旧图了,跟之前一样的步骤

可以看到,前面括号的base变成了gptac_venv,也就是从基础环境(base)切换到了我们刚新建的新环境(gptac_venv),接下来就在这个新环境里面安装依赖库。
(d)安装依赖库,首先把路径切换到之前存项目的路径:E:\Auto-GPT\Auto-GPT-master-0415,操作就是:
输入“e:”——回车,进入到E盘——输入“cd E:\Auto-GPT\Auto-GPT-master-0415”——回车,搞定;注意:我装autogpt环境是jet_gpt哈,上面之所以是gptac_venv,是因为懒,用的旧图。

接着输入代码:
python -m pip install -r requirements.txt回车开始安装。
需要安装的东西很多,个人经验:跟网速有关,我是开魔法的。
安装成功的话,全程白字没有报错。要是有红字报错,各位八仙过海各显神通吧。
第三步 配置OPENAI_API_KEY
(a)确保网络通畅(最重要);
(b)OpenAI API Key 生成,进入网址,登陆账号:
https://platform.openai.com/account/api-keys![]() https://platform.openai.com/account/api-keys
https://platform.openai.com/account/api-keys
点击“Create new secret key”——弹出窗口——复制出你的Key。
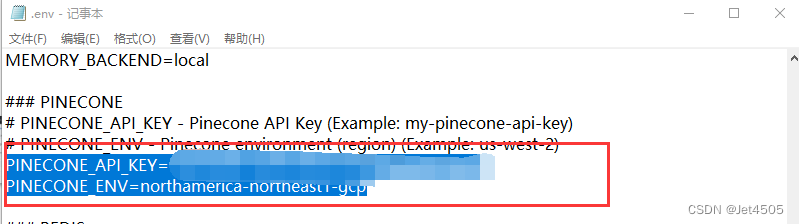
(c)找到项目文件中的.env.template文件,改名为.env文件,并用记事本打开项目文件的,填入你的API KEY:
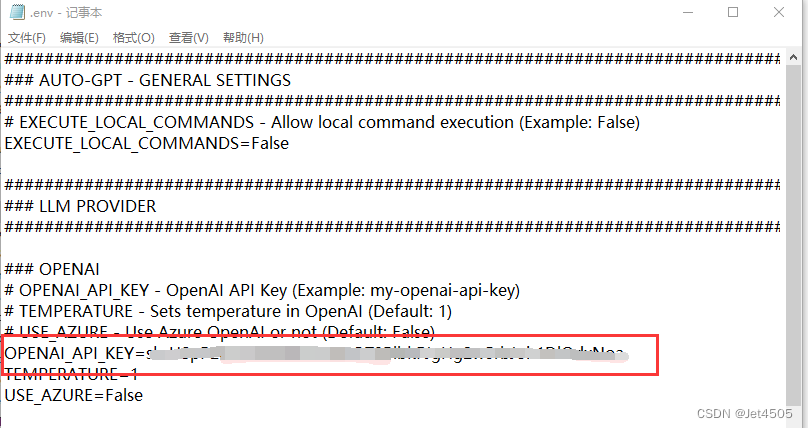
注意:这里的API不需要双引号:“”。
第四步 配置PINECONE_API_KEY
(a)确保网络通畅(最重要);
(b)Pinecone API Key 生成,进入网址,注册,登陆账号:
Vector Database for Vector Search | PineconeThe #1 vector database. Search through billions of items for similar matches to any object, in milliseconds. It’s the next generation of search, an API call away.![]() https://login.pinecone.io/
https://login.pinecone.io/
点击“API key”——弹出窗口;
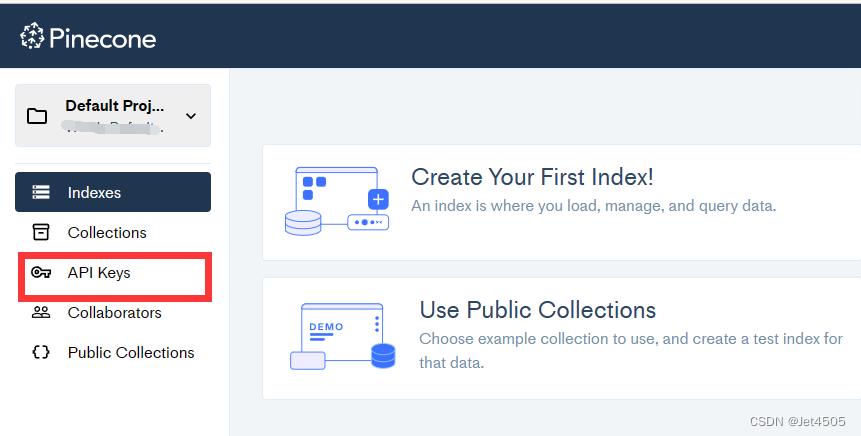
复制出你的PINECONE_API_KEY(Vaule)和PINECONE_ENV(Environment);
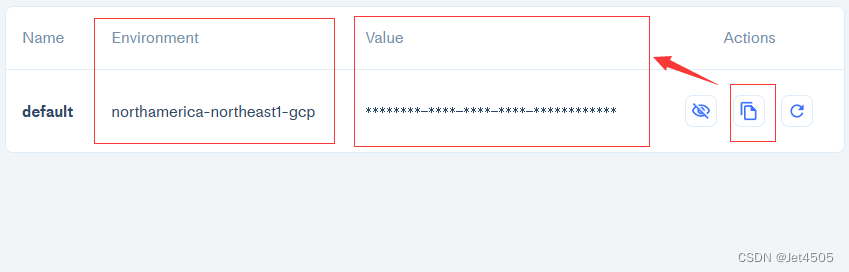
分别填入.env文件:
第四步 配置GOOGLE搜索引擎
这里主要需要填入2个东西:GOOGLE_API_KEY以及CUSTOM_SEARCH_ENGINE_ID。
(a)确保网络通畅(最重要);
(b)Googel API Key 生成,进入网址,注册,登陆账号:
https://console.cloud.google.com/welcome?project=high-unity-383319&pli=1![]() https://console.cloud.google.com/welcome?project=high-unity-383319&pli=1
https://console.cloud.google.com/welcome?project=high-unity-383319&pli=1
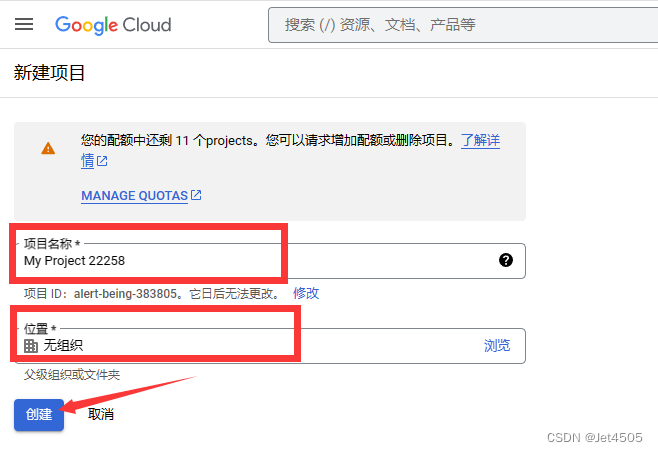
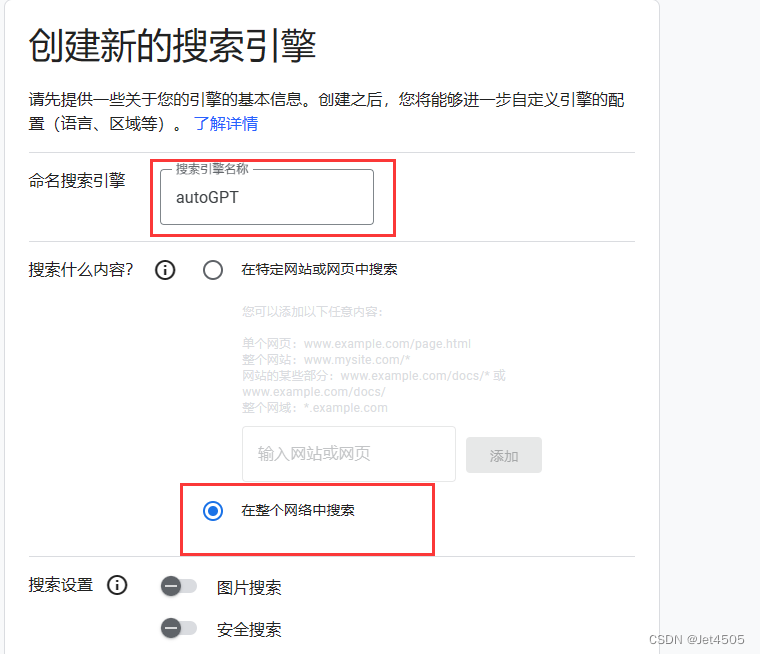
(c)创造一个无组织的最新项目:
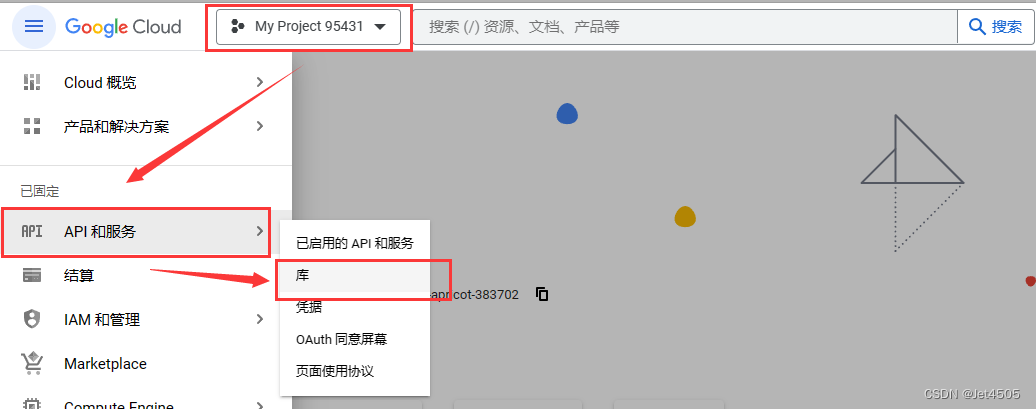
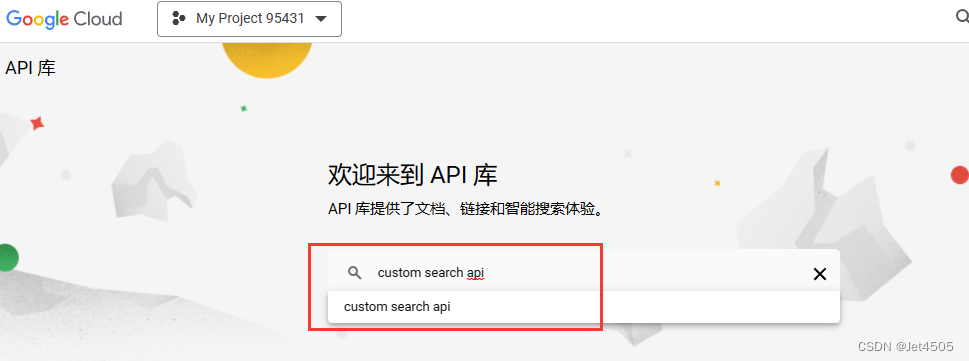
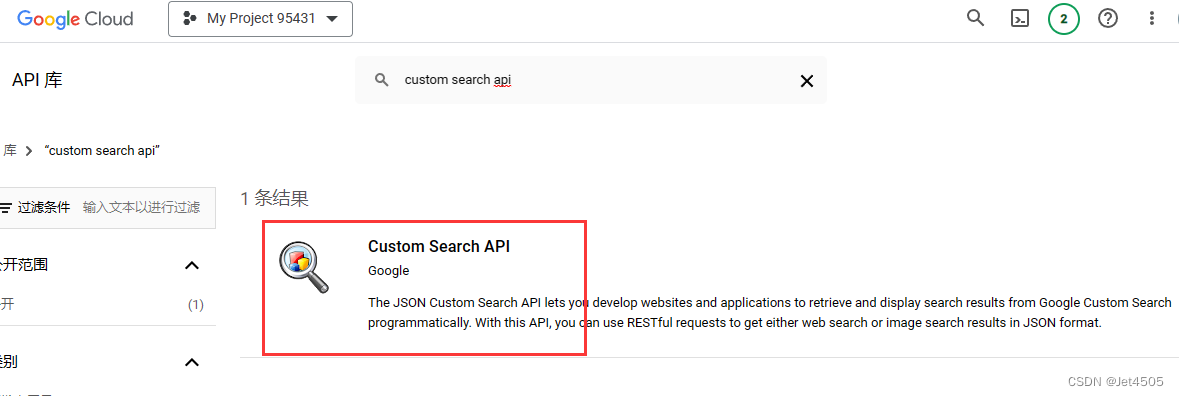
(d)输入 custom search api,之后选 管理 > 凭据 > 创建凭据 > API密钥
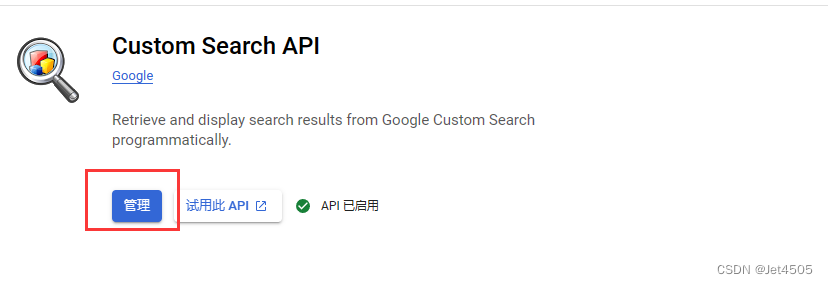

(e)这个就是GOOGLE_API_KEY;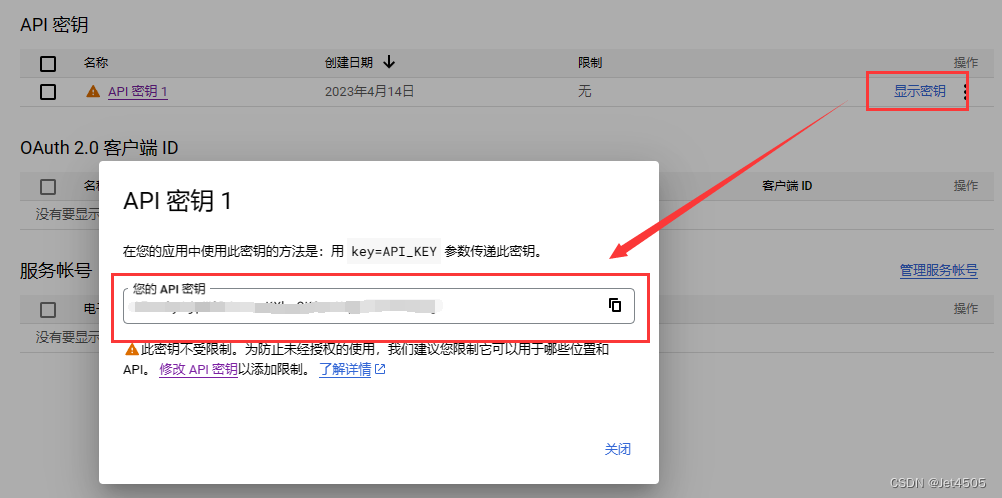 然后来看USTOM_SEARCH_ENGINE_ID 的ID:
然后来看USTOM_SEARCH_ENGINE_ID 的ID:
(a)确保网络通畅(最重要);
(b)CUSTOM_SEARCH_ENGINE_ID 生成,进入网址:
https://programmablesearchengine.google.com/about/![]() https://programmablesearchengine.google.com/about/
https://programmablesearchengine.google.com/about/
(c)CUSTOM_SEARCH_ENGINE_ID 生成,进入网址:

(d)复制好CUSTOM_SEARCH_ENGINE_ID。

最后,打开.env文件,输入GOOGLE_API_KEY以及CUSTOM_SEARCH_ENGINE_ID:
第五步 运行程序
还是打开刚才的Anaconda Prompt (anaconda),切换到新建的环境,以及项目路径: 输入代码:
输入代码:
python -m autogpt --gpt3only回车!
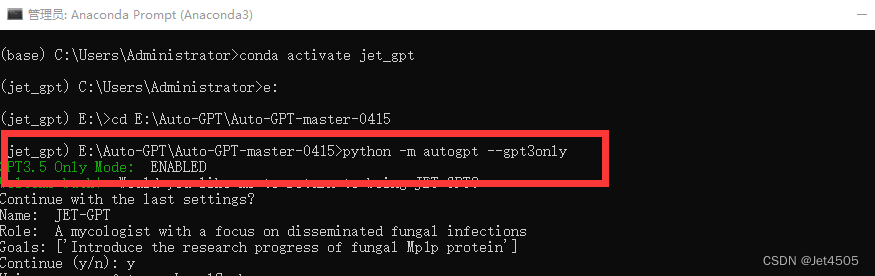
出现了绿色字welcome back 就是成功了!
简单用法:给AI取名字 > 设置任务 > 设置任务目标(最多5个)> 程序运行 > 每一步用y、n等指令指挥AutoGPT。
三、Auto-GPT测评
(1)设置目标
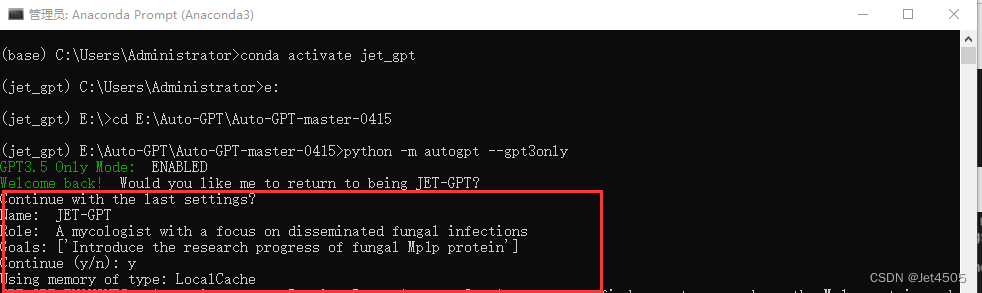
Name: JET-GPT
Role: A mycologist with a focus on disseminated fungal infections
Goals: Introduce the research progress of fungal Mp1p protein
简单来说就是帮我简单介绍真菌Mp1p蛋白的研究进展。由于我之前运行过了,这里它自动调取上次的程序,输入y继续运行即可:
(2)程序思考过程:

用谷歌翻译展示一下:

TA会自己进行任务拆分,首先,去谷歌搜索!!
我们输入y,让TA进行下一步:

TA去找文献了,还进行了分析:
 读出了一些信息:
读出了一些信息:

然后TA自己分析了这个方法不太好:“由于我的短期记忆力有限,因此启动受过文本摘要训练的 GPT 代理将减轻我的工作量并节省我的时间”,然后如何解决:“我应该启动一个 GPT 代理来帮助我生成我从网站上收集的有关 Mp1p 蛋白的信息摘要。 为此,我可以使用“start_agent”命令。”

再运行一次后,给出了一些总结:

好像不太对,给它继续自我反思试一试:TA好像想到了我是想看真菌的Mp1p:

接着他继续上网找文献,然后发现读取不了文献的信息:“此模型的最大上下文长度为 4097 个标记”,没办法GPT3.5的限制。然后只能从TA已知的知识中提取信息,有可能是现编的。
到此为止,我就让TA停下来了。
总结:虽然结果不太理想,但是过程确实让人眼前一亮,毕竟处于初级阶段,而且我只能调用GPT3.5,未来提升的空间还是很大的。
四、几点注意事项
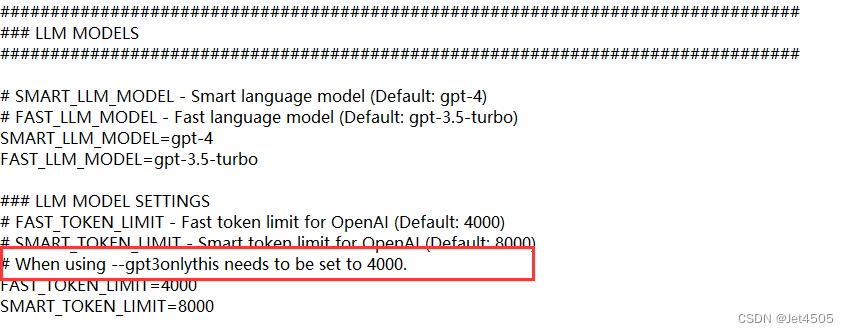
(1)关于不能联网
据说,需要在.env文件中,把这个8000改成4000。江湖传闻,供参考。
(2)关于API Key的费用
据说,调用OpenAI Key是收费的,新注册账号,至少赠送5美元,用完就无了。
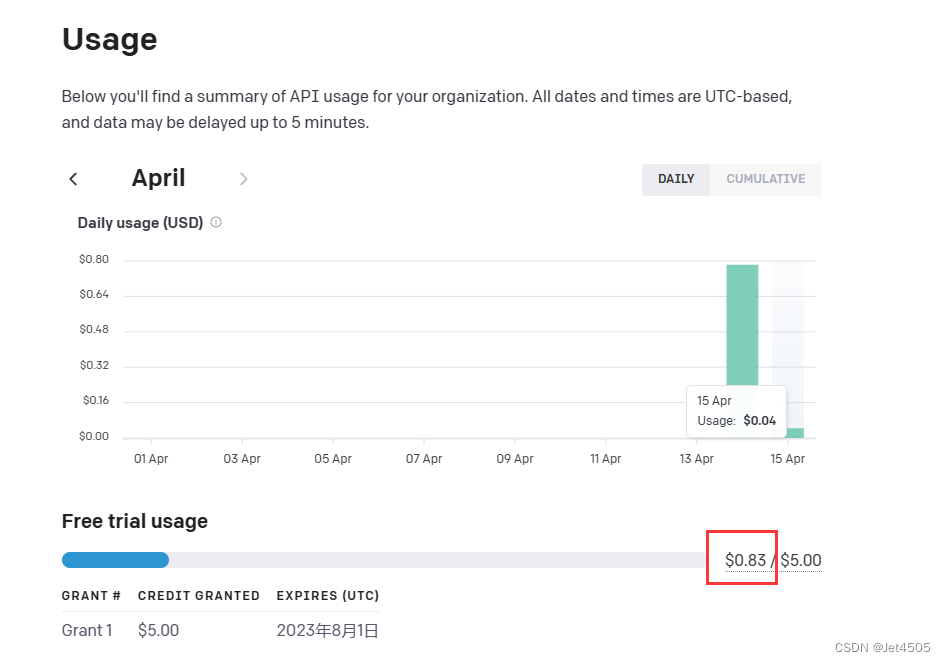
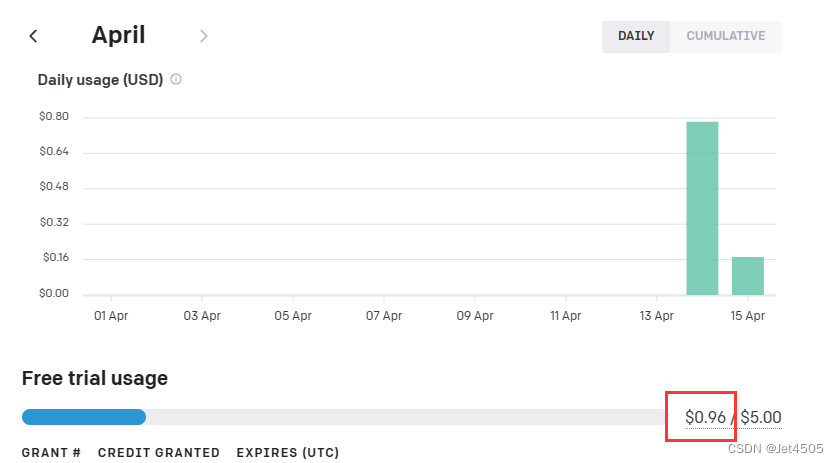
我跑了这一次花费如下,一共是0.13美元,差不多1块钱,成本还是很高的。
所以大家玩归玩,注意这是一个烧钱的过程哈!