大数据Hadoop-HDFS_架构、读写流程
大数据Hadoop-HDFS
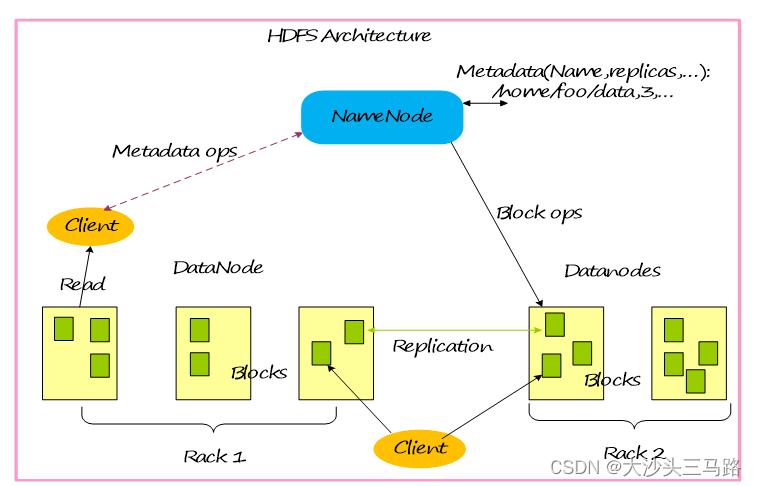
基本系统架构
HDFS架构包含三个部分:NameNode,DataNode,Client。
NameNode:NameNode用于存储、生成文件系统的元数据。运行一个实例。
DataNode:DataNode用于存储实际的数据,将自己管理的数据块上报给NameNode ,运行多个实例。
Client:支持业务访问HDFS,从NameNode ,DataNode获取数据返回给业务。多个实例,和业务一起运行。
HDFS数据写入流程
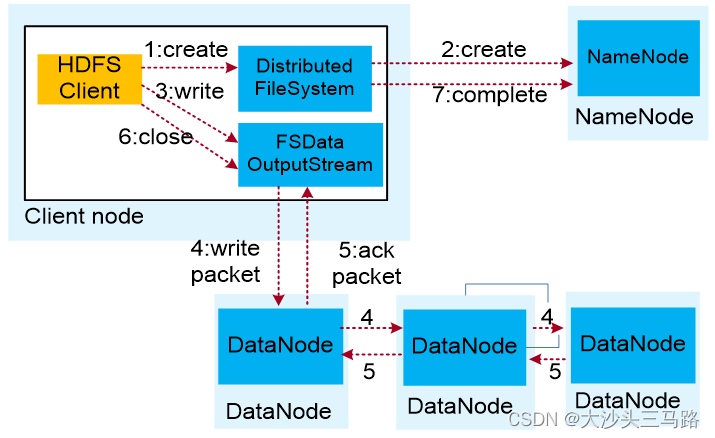
HDFS数据写入流程如下:
(1)业务应用调用HDFS Client提供的API,请求写入文件。
(2)HDFS Client联系NameNode,NameNode在元数据中创建文件节点。
(3)业务应用调用write API写入文件。
(4)HDFS Client收到业务数据后,从NameNode获取到数据块编号、位置信息后,联系DataNode,并将需要写入数据的DataNode建立起流水线。完成后,客户端再通过自有协议写入数据到DataNode1,再由DataNode1复制到DataNode2, DataNode3。
(5)写完的数据,将返回确认信息给HDFS Client。
(6)所有数据确认完成后,业务调用HDFS Client关闭文件。
(7)业务调用close, flush后HDFS Client联系NameNode,确认数据写完成,NameNode持久化元数据。
HDFS数据读取流程
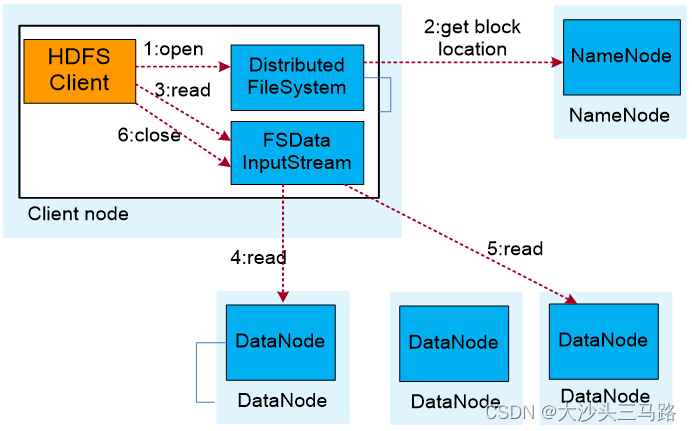
HDFS数据读取流程如下:
(1)业务应用调用HDFS Client提供的API打开文件。
(2)HDFS Client联系NameNode,获取到文件信息(数据块、DataNode位置信息)。
(3)业务应用调用read API读取文件。
(4)HDFS Client根据从NameNode获取到的信息,联系DataNode,获取相应的数据块。(Client采用就近原则读取数据)。
(5)HDFS Client会与多个DataNode通讯获取数据块。
(6)数据读取完成后,业务调用close关闭连接。