采集工具-免费采集器下载
在当今信息时代,互联网已成为人们获取信息的主要渠道之一。对于研究者和开发者来说,如何快速准确地采集整个网站数据是至关重要的一环。以下将从九个方面详细探讨这一问题。

确定采集目标
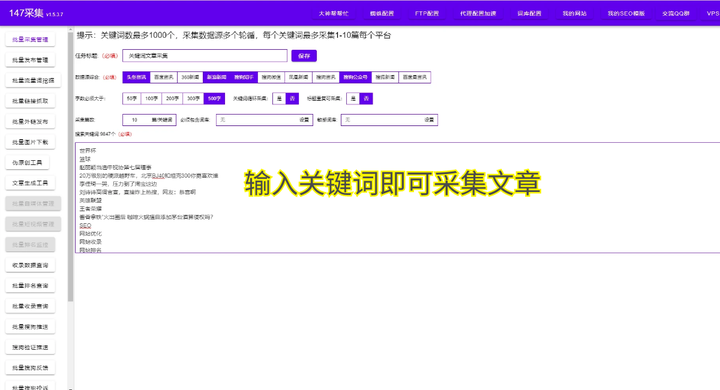
在着手采集之前,明确目标至关重要。这有助于确定采集内容和方式。比如,若想获取某电商平台所有商品信息,则需明确商品类别、属性等。
选择采集方式
不同目标可能需要不同采集方式。包括爬虫、API接口、数据抓取工具等,选择适合的方式至关重要。
编写爬虫代码
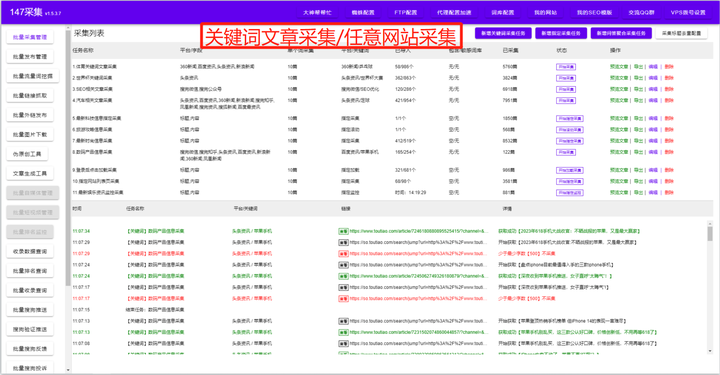
使用爬虫进行采集时,编写相应代码是必要的。通常可采用Python语言中的Scrapy框架编写爬虫程序。
设置反爬措施
为防止被网站封禁IP等风险,设置反爬措施至关重要。如设置代理IP、使用随机User-Agent等。
确定数据存储方式
采集的数据需妥善存储,可选数据库或以文件形式保存在本地。

数据清洗方式
采集的数据常含无用或重复信息,需进行清洗。可使用Python语言中的Pandas库进行数据清洗和整理。
设置定时任务
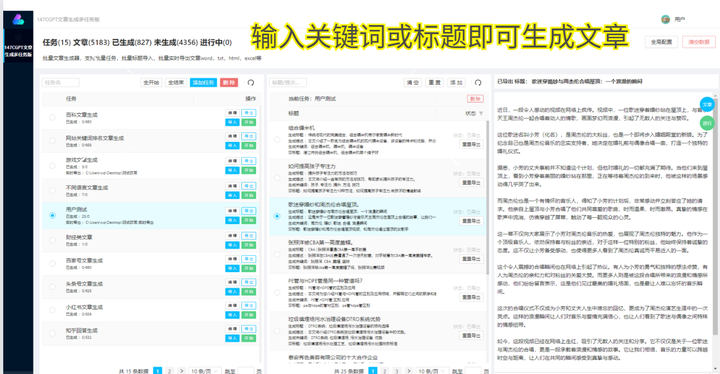
需要定期采集某网站信息,可使用Linux系统中的Crontab命令设置定时任务。
监控采集过程
持续监控程序运行情况是必要的,有助及时发现并解决问题。可使用Python语言中的Logging模块进行日志输出和监控。
优化采集效率
提高采集效率可采用多线程或多进程技术加速程序运行。对较大网站,可将爬虫程序部署至云服务器进行分布式爬取。

对于数据采集,其重要性不言而喻。在信息时代,信息的价值愈发凸显,有效获取数据对于研究、商业决策等领域至关重要。