种群和种群之间连接的设计
我们知道神经元的创建方式是以种群为基础的,一个种群内的所有神经元的参数都一样,而种群与种群之间的连接也是随机概率的。所以我们首先应该设计一个Population的结构,考虑其需要的元素有神经元gid集合和种群好,所设计数据结构如下:
 创建神经元为
创建神经元为
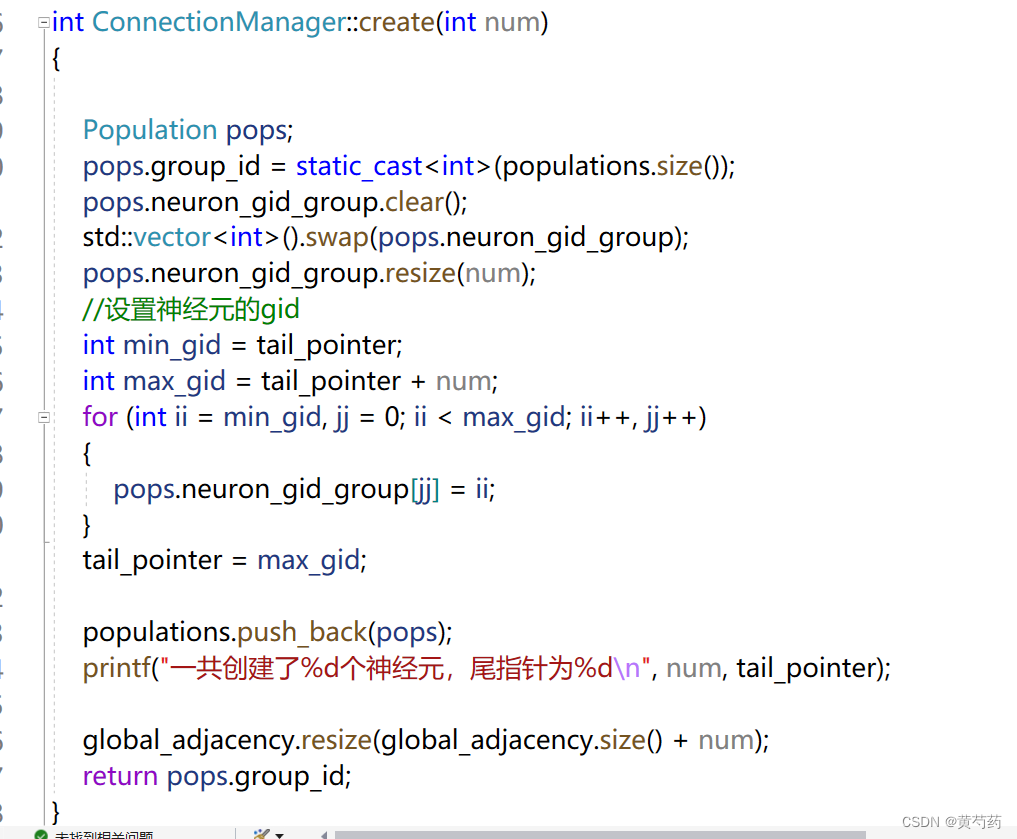
在创建神经元的同时给每一个神经元附上一个gid。
在连接两个神经元群落时,需要设置连接点概率
void ConnectionManager::connect(int source_group_id, int target_group_id,double connection_probability)
{
//获取源种群和目标的神经元gid的集合
std::vector<int> source_neuron_group = populations[source_group_id].neuron_gid_group;
std::vector<int> target_neuron_group = populations[target_group_id].neuron_gid_group;
//打乱两个数组,保证随机性
std::random_shuffle(source_neuron_group.begin(), source_neuron_group.end());
std::random_shuffle(target_neuron_group.begin(), target_neuron_group.end());
// 根据连接概率和目标种群的神经元数量随机生成连接数量
std::default_random_engine generator;
generator.seed(rand01());
std::binomial_distribution<> gen(target_neuron_group.size(), connection_probability);
for (int ii = 0; ii < source_neuron_group.size(); ii++)
{
int index = source_neuron_group[ii]; //原神经元的gid
int num_connections = gen(generator);//连接数量
// 设置随机位置
int rand_conn = static_cast<int>(rand01() * target_neuron_group.size());
if (num_connections == 0)
continue;
//调整邻接表大小
//global_adjacency[index].resize(global_adjacency[index].size() + num_connections);
if ((num_connections + rand_conn) > target_neuron_group.size())
{
int diff = target_neuron_group.size() - rand_conn;
global_adjacency[index].insert(global_adjacency[index].end(), target_neuron_group.end() - diff, target_neuron_group.end());
num_connections = num_connections - diff;
global_adjacency[index].insert(global_adjacency[index].end(), target_neuron_group.begin(), target_neuron_group.begin() + diff);
}
else
{
global_adjacency[index].insert(global_adjacency[index].end(), target_neuron_group.begin() + rand_conn, target_neuron_group.begin() + num_connections + rand_conn);
}
}
}创建的邻接表存储在名为global_adjacency中,在主函数中创建神经元和突触
int group1 = kernel().conn_manger.create(2);
int group2 = kernel().conn_manger.create(2);
//int group3 = kernel().conn_manger.create(10);
kernel().conn_manger.connect(group1, group2, 1.0);
//kernel().conn_manger.connect(group2, group3, 0.3);
就可以实现群落的是神经元的创建和连接。