循环神经网络RNN及其变体LSTM、GRU
1. 背景
RNN(Recurrent Neural Networks)
CNN利用输入中的空间几何结构信息;RNN利用输入数据的序列化特性。
2. SimpleRNN单元
传统多层感知机网络假设所有的输入数据之间相互独立,但这对于序列化数据是不成立的。RNN单元用隐藏状态或记忆引入这种依赖,以保存当前的关键信息。任一时刻的隐藏状态值是前一时间步中隐藏状态值和当前时间步中输入值的函数
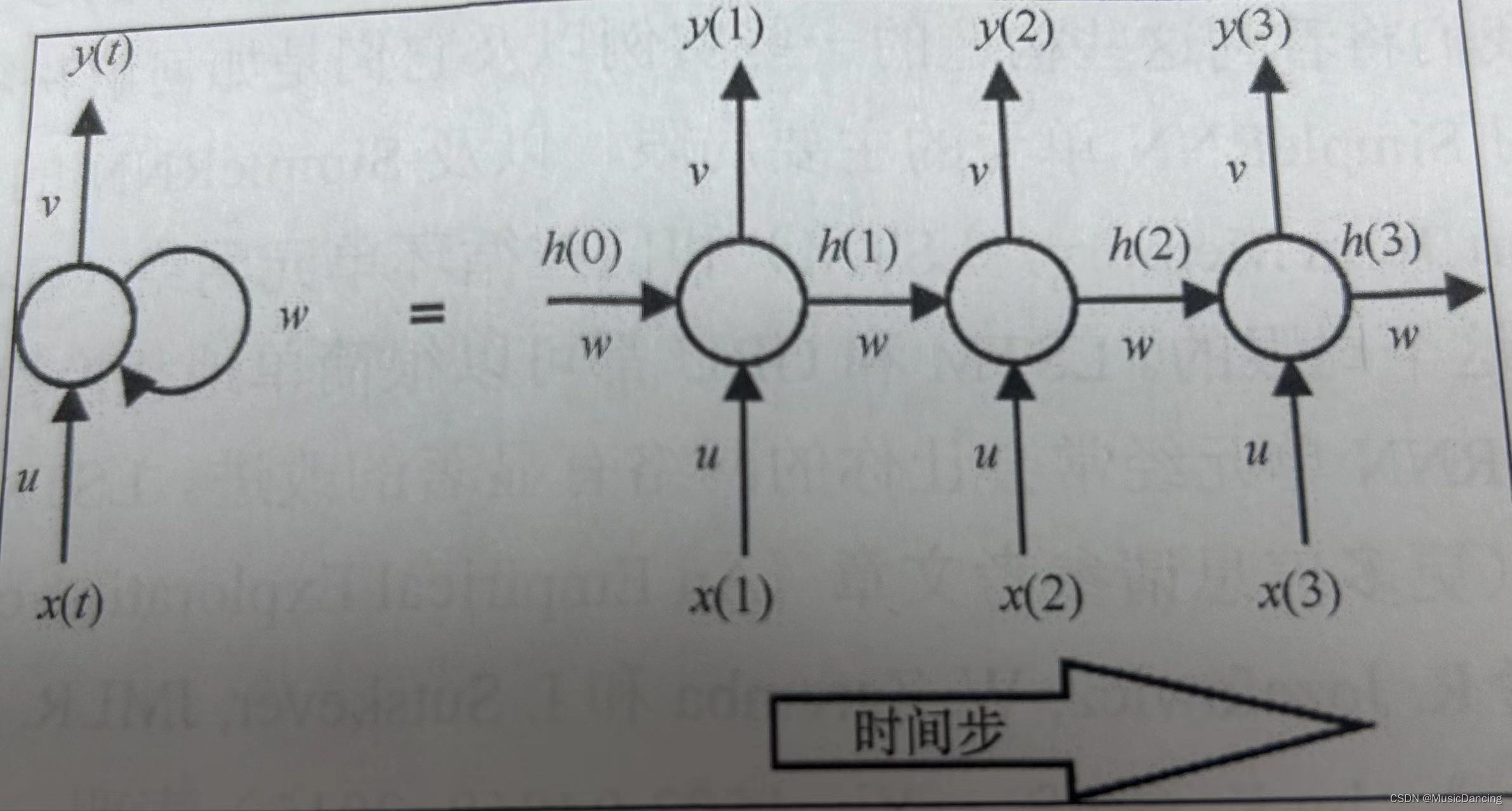
在所有时间步上共享相同的权重向量(U、V、W),极大地减少了RNN网络需要学习的参数个数。其t时间步输出
选择tanh作为激活函数,是因为它的二阶导数衰减到0非常缓慢,这保持了激活函数的线性域的斜度,并帮助防止梯度消失问题。
3. 梯度消失与梯度爆炸
3.1 产生原因
时延反向传播BPTT(Backpropagation Through Time):因为参数是所有时间步共享的,所以每个输出的梯度不只依赖当前的时间步,也依赖之前的时间步。
在正向传播中,网络在每个时间步产生预测,并将它与标签比较,来计算损失L(t);
在反向传播中,关于参数U、V和W的损失梯度在每个时间步上计算,并用梯度之和来更新参数。
一个隐藏状态关于它前一个隐藏状态的梯度小于1,跨多个时间步反向传播后,梯度的乘积就会变得越来越小,这就导致了梯度消失问题的出现;反之,梯度比1大很多,会导致梯度爆炸。
3.2 影响
(1)梯度消失的影响是:相距较远的时间步上的梯度对学习过程没有任何用处,因此RNN不能进行大范围依赖的学习。梯度消失问题在传统NN上也会发生,只是对于RNN网络可见性更高,因为RNN趋于拥有更多的层(时间步),而反向传播在这些层是必然发生的。
(2)梯度爆炸更容易被检测到,梯度会变得非常大以至于不再是数字,训练过程也将崩溃。
3.3 解决方案
(1)缓解梯度消失问题的方法:
1. W权重向量的适当初始化;
2. 使用ReLU替代tanh层;
3. 使用非监督方法与训练网络;
4. 使用LSTM或GRU架构。
(2)梯度爆炸问题可以通过在预定义的阈值上进行梯度裁剪来控制。
4. LSTM长短期记忆网络
LSTM机构被设计成处理梯度消失问题以及更高效的学习长期依赖。LSTM时间步t隐藏状态的转换(4个层:3个门(i,f,o)+内部隐藏状态g),如下图所示:
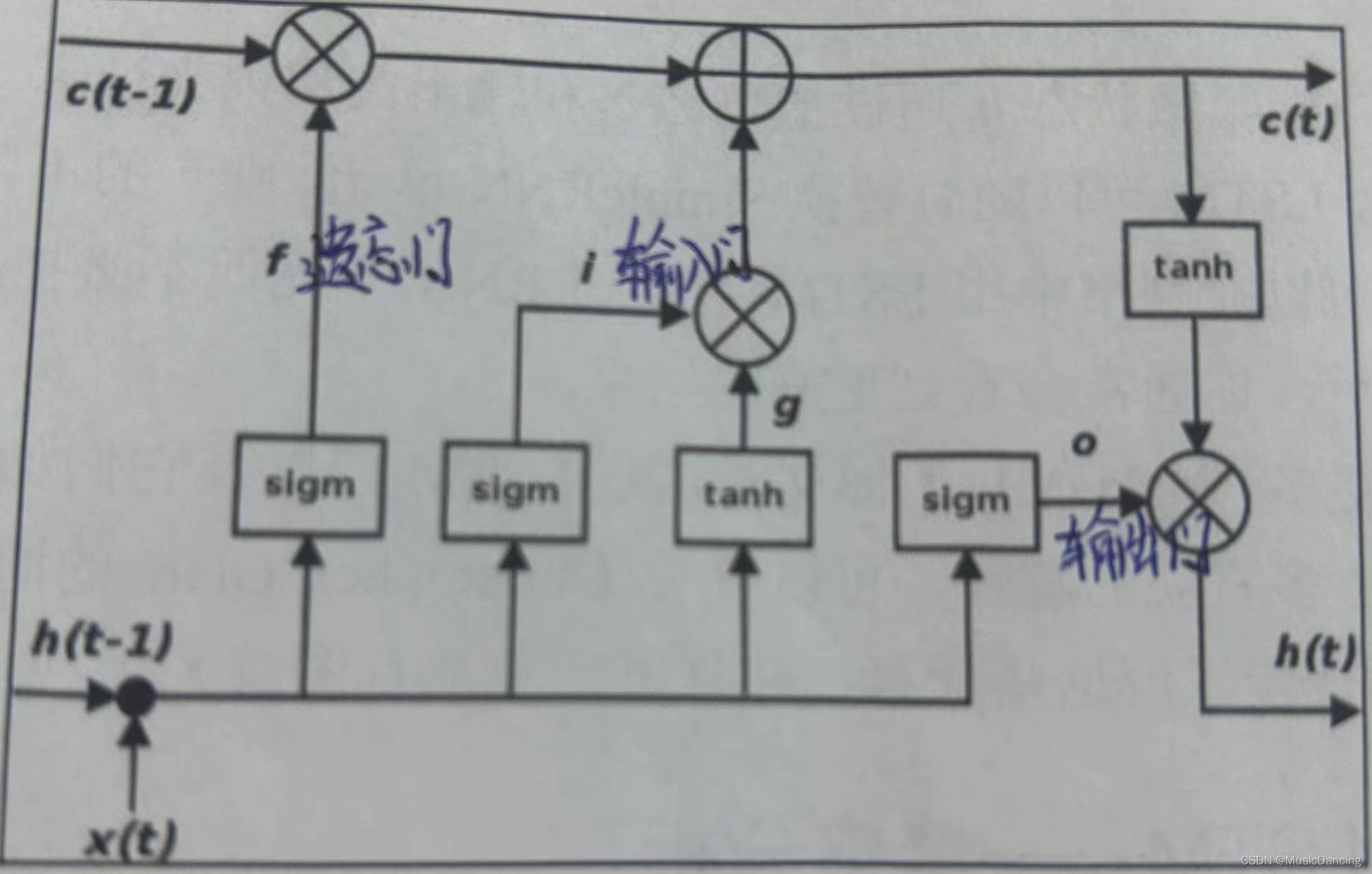
遗忘门定义了前一状态 的多少部分可以通过;
输入门定义了当前输入 新计算出的状态的多少部分可以通过;
输出门定义了当前状态的多少部分传递给下一层;
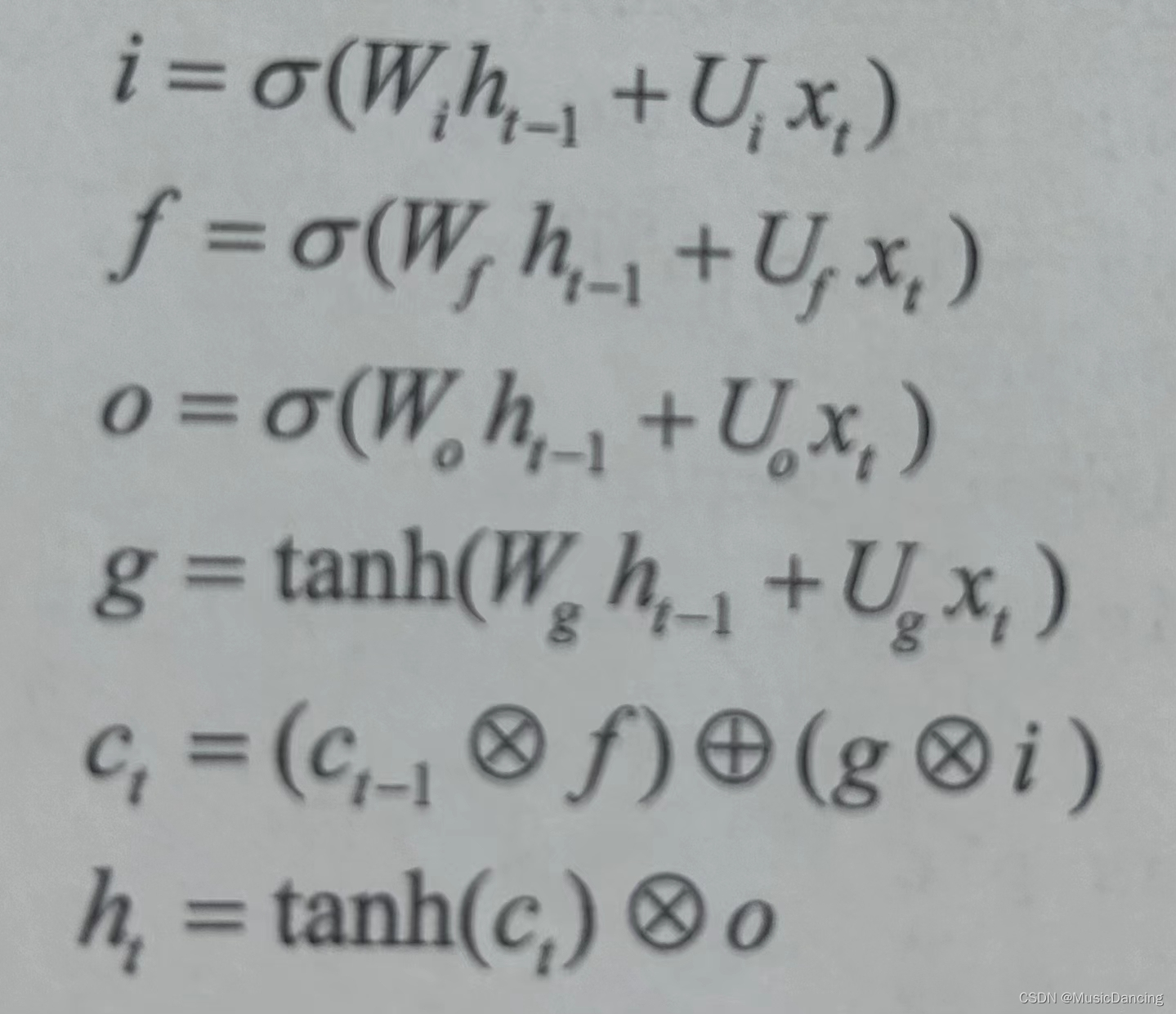
5. GRU门控循环单元网络
GRU是LSTM的一个变体,它保留了LSTM对梯度消失问题的抗力,但它内部结构更加简单,更新隐藏状态时需要的计算也更少,因此训练的更快。GRU单元的门如下:
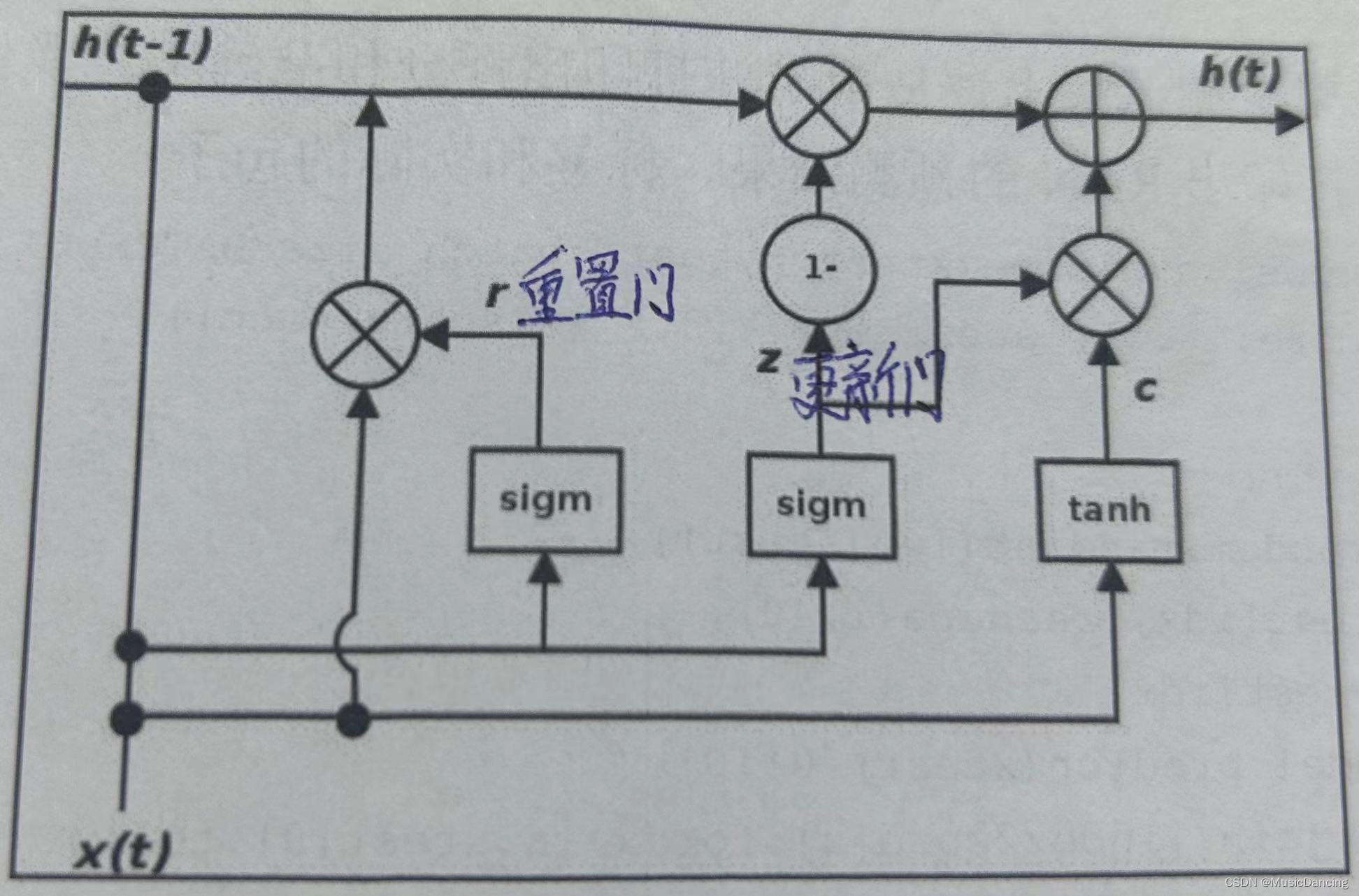
更新门z定义了保留多少部分上一记忆;
重置门r定义了如何把新的输入和上一记忆结合起来;
和LSTM不同,GRU没有持久化的单元状态。

GRU和LSTM具有同样出色的性能,GRU训练起来更快并且需要较少的数据就可以泛化,
但在数据充足的情况下,LSTM卓越的表示能力可能会产生更好的结果。
6. 双向RNN
双向RNN是彼此互相堆叠的两个RNN,它们从相反的方向读取输入。每个时间步的输出将
基于两个RNN的隐藏状态。
7. 有状态RNN
RNN可以是有状态的,它能在训练中维护跨批次的状态信息,即为当前批次的训练数据计算
的状态值,可以用作下一批次训练数据的初始隐藏状态。
优点:更小的网络或更少的训练时间;
缺点:需要负责使用反映数据周期性的批大小来训练网络,并在每个训练期后重置状态。
另外,因为数据呈现的顺序与有状态网络相关,在网络训练期间数据不能被移动。
1. 需要选择一个反映数据周期性的批大小,因为有状态RNN会将本批数据和下一批排列对齐,所以选择合适的批大小会让网络学得更快。
2. 需要手动控制模型、循环训练模型至要求的轮数。每次迭代训练模型一轮,状态信息跨批次保留。每轮训练后,模型的状态需要手动重设。