Prefix-Tuning 论文概述
Prefix-Tuning 论文概述
- 前缀调优:优化生成的连续提示
- 前言
- 摘要
- 论文十问
- 实验
- 数据集
- 模型
- 实验结论
- 摘要任务
- 泛化性能
前缀调优:优化生成的连续提示
前言
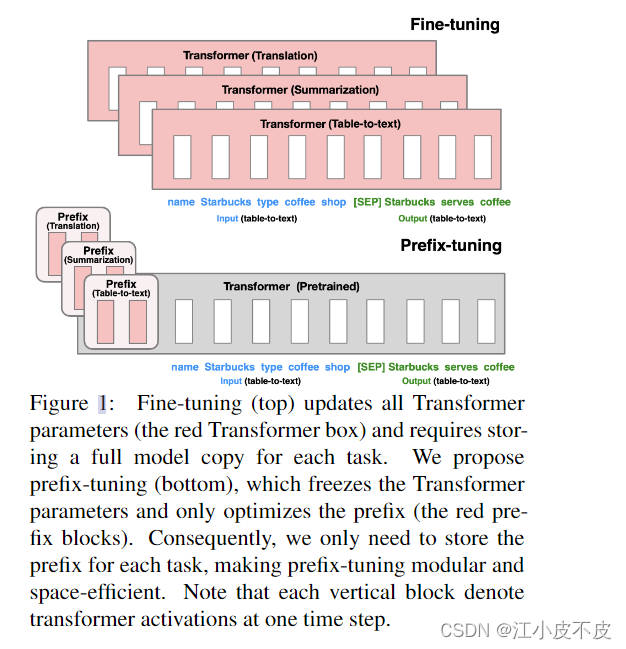
大规模预训练语言模型(PLM)在下游自然语言生成任务中广泛采用fine-tuning的方法进行adaptation。但是fine-tuning需要更新模型所有的参数,对于每个任务都需要保存一份完整的模型拷贝,存储成本很高。文章提出prefix-tuning方法,其只优化一个小的连续任务特定向量(称为prefix),KEEP 语言模型参数固定。该方法受prompting的启发,允许后续token参考这个prefix,就像参考一系列“虚拟token”。
文章将prefix-tuning应用于GPT-2在表格到文本生成任务和BART在摘要任务上。结果显示,只学习0.1%的参数,prefix-tuning获得与fine-tuning相当的性能;在低数据设置下,prefix-tuning优于fine-tuning;在extrapolation设置下评估泛化能力时,prefix-tuning也优于fine-tuning。
Prefix-tuning是一个轻量级的fine-tuning替代方法,大大减少了每个任务的存储成本。它通过优化一个小的、连续的、任务特定的prefix来steering一个固定的语言模型完成下游生成任务。
摘要
微调是利用大型预训练语言模型执行下游任务的事实上的方法。然而,它修改了所有语言模型参数,因此需要为每个任务存储完整副本。
在本文中,我们提出了前缀调优,这是自然语言生成任务微调的一种轻量级替代方案,它保持语言模型参数冻结,但优化了所有连续的特定于任务的向量(称为前缀)。前缀调整从提示中汲取灵感,允许后续令牌关注该前缀,就好像它是"虚拟令牌"一样。
我们将前缀调整应用于 GPT-2 以生成表到文本,并将前缀调整应用于 BART 以进行摘要。我们发现,通过仅学习 0.1% 的参数,前缀调整在完整数据设置中获得了相当的性能,在低数据设置中优于微调,并且更好地推断出训练期间未见过的主题的示例。
论文十问
- 论文试图解决什么问题?
这篇论文试图解决大型预训练语言模型微调所带来的存储成本问题。
- 这是否是一个新的问题?
这是一种新提出的问题。过去关注更多的是大型预训练语言模型微调的计算成本。
- 这篇文章要验证一个什么科学假设?
主要是提出 prefix tuning 这一方法来解决大型预训练语言模型微调中的存储问题。
- 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
相关研究包括轻量级微调方法、提示学习等。值得关注的研究员包括文章作者李香丽(Xiang Lisa Li)和梁培杰(Percy Liang)。
- 论文中提到的解决方案之关键是什么?
文章提出的关键解决方案是 prefix tuning,只优化一个小的连续任务特定向量(prefix),保持PLM参数固定。
- 论文中的实验是如何设计的?
在GPT-2和BART上分别进行表格到文本生成和摘要生成任务的实验。使用标准数据集进行评估。
- 用于定量评估的数据集是什么?代码有没有开源?
使用的数据集有E2E、WebNLG、DART、XSUM。代码开源。
- 论文中的实验及结果有没有很好地支持需要验证的科学假设?
实验结果充分验证了prefix tuning相比微调可以获得可比性能,使用的参数量只有微调的千分之一。
- 这篇论文到底有什么贡献?
主要贡献是提出prefix tuning这一参数高效的PLM适配方法。
- 下一步呢?有什么工作可以继续深入?
下一步可以研究这种方法适配的理论解释,以及在更多下游任务和更大模型上验证这种方法的有效性。
实验
数据集
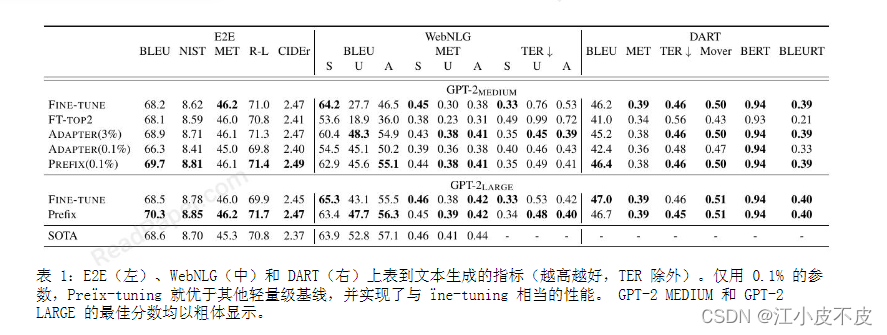
- 表格到文本生成任务使用E2E、WebNLG和DART数据集。
- 摘要任务使用XSUM数据集。
模型
- 表格到文本生成对比了fine-tuning、只fine-tune顶层2层(FT-TOP2)、adapter-tuning和prefix-tuning。
- 摘要任务对比了fine-tuning和prefix-tuning。
实验结论
- 在充分数据设置下,prefix-tuning和fine-tuning在E2E表格到文本生成任务上的性能相当;在XSUM摘要任务上prefix-tuning性能略低。
- 在低数据设置下,prefix-tuning的平均性能优于fine-tuning。
- 在 extrapolation 设置下评估泛化能力,prefix-tuning也优于fine-tuning。
- prefix-tuning只更新了0.1%的参数,远少于fine-tuning,但性能接近或超过fine-tuning。
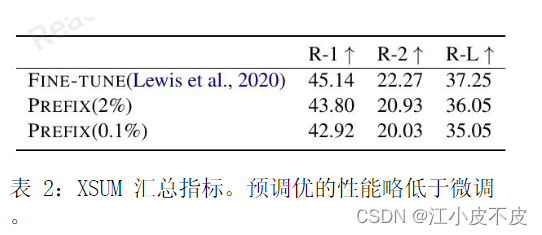
摘要任务
摘要任务结果如上表所示,prefix-tuning和全量微调还是有差距,这与文本生成任务的结果有所不同,有如下几点原因:
- XSUM数据集是三个table-to-text数据集的三倍。
- 输入的文章比table-to-text的输入长17倍。
- 摘要任务更复杂,因为需要从文本中挑选关键内容。
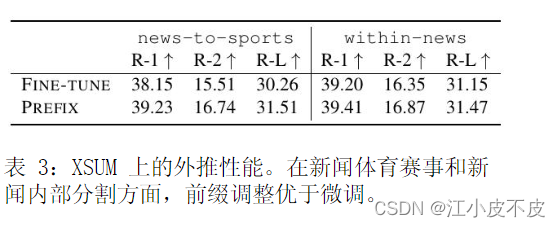
泛化性能
这里探索模型的泛化性能,即模型在未见过的主题上的数据上的表现。为此,作者对数据集进行了重新划分:
对于表格到文本任务,WebNLG数据集原本包含9个训练和验证中出现的类别(标记为SEEN),以及5个仅在测试集中出现的类别(标记为UNSEEN)。作者使用SEEN类别的数据进行训练,在UNSEEN类别的数据上进行测试,来评估模型的泛化能力。
对于摘要任务,构建了两个数据分割。第一个是news-to-sports,使用新闻文章进行训练,在体育文章上测试。第二个是within-news,使用世界、英国、商业等新闻领域的数据训练,在新闻中其它类别(如健康、技术等)的数据上测试。