【云原生Prometheus篇】Prometheus PromQL语句详解 1.0
文章目录
- 一、前言
- 1.1 Prometheus的时间序列
- 1.1.1 指标名称
- 1.1.2 标签
- 1.1.3 使用的注意事项
- 1.2 样本数据格式
- 1.3 Prometheus 的聚合函数
- 二 、PromQL 理论部分
- 2.1 PromQL简介
- 2.2 PromQL的数据类型
- 2.3 时间序列选择器
- 2.3.1 瞬时向量选择器 (Instant Vector Selectors)
- Part1 定义
- Part2 构成
- Part3 怎么定义瞬时向量选择器?
- Part4 注意事项
- 2.3.2 区间向量选择器 (Range Vector Selectors)
- Part1 定义和工作原理
- Part2 时间范围
- 2.3.3 偏移向量选择器
一、前言
1.1 Prometheus的时间序列
Prometheus 中,每个时间序列都由指标名称(Metric Name)和标签(Label)来唯一标识。
格式: <metric_name>{<label_name>=<label_value>, ...}
1.1.1 指标名称
通常用于描述系统上要测定的某个特征。
例如,prometheus_http_requests_total 表示接收到的 HTTP 请求总数。
1.1.2 标签
键值型数据,附加在指标名称之上,从而让指标能够支持多纬度特征;可选项。
双下划线的标签(例如 __address__ )是 Prometheus 系统默认标签,是不会显示在 /metrics 页面里面的;
| 常见的系统默认标签 | |
|---|---|
__address__ | 当前 target 实例的套接字地址 : |
__scheme__ | 采集当前 target 上指标数据时使用的协议(http 或 https) |
__metrics_path__ | 采集当前 target 上的指标数据时使用 URI 路径,默认为 /metrics |
__param_<name> | 传递的 URL 参数中第一个名称为 的参数的值 |
__name__ | 此标签是标识指标名称的预留标签,能够使用标签选择器对指标名称进行过滤 |
1.1.3 使用的注意事项
1)指标名称和标签的特定组合代表着一个时间序列
不同的指标名称自然代表着不同的时间序列;而指标名称相同,但标签不同的组合也代表着不同的时间序列。
2)尽可能地保持标签的稳定性
PromQL支持基于定义的指标维度进行过滤和聚合,更改任何标签值(包括添加或删除标签),都会创建一个新的时间序列。
如果标签不稳定,很可能会创建新的时间序列,更甚者会生成一个动态的数据环境,并使得监控的数据源难以跟踪,从而导致建立在该指标之上的图形、告警及记录规则变得无效。
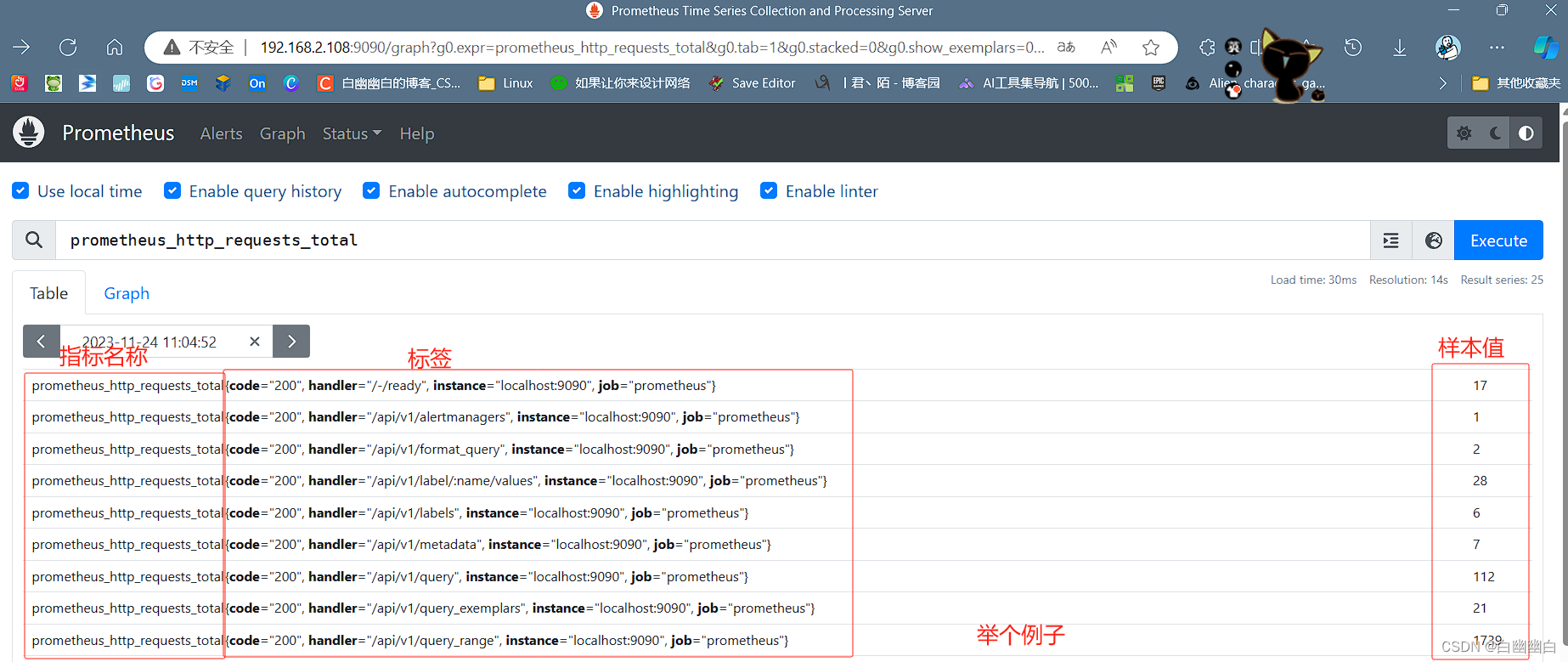
1.2 样本数据格式
Prometheus 的每个数据样本由两部分组成,毫秒精度的时间戳 和 float64 格式的数据。
prometheus_http_requests_total{code="200", handler="/targets", instance="localhost:9090", job="prometheus"} @1434317560885 28
prometheus_http_requests_total{code="200", handler="/targets", instance="localhost:9090", job="prometheus"} @1434317561483 35
| || | | | |
---------- 指标名称 -------- ------------------------ 标签 --------------------------------------------- -- 时间戳 -- 样本值
1.3 Prometheus 的聚合函数
| 内置函数 | 描述 | 示例查询 |
|---|---|---|
| sum() | 对样本值求和 | sum(my_metric) |
| min() | 求取样本值中的最小值 | min(my_metric) |
| max() | 求取样本值中的最大值 | max(my_metric) |
| avg() | 对样本值求平均值 | avg(my_metric) |
| count() | 对分组内的时间序列进行数量统计 | count(my_metric) |
| stddev() | 对样本值求标准差,帮助了解数据的波动大小 | stddev(my_metric) |
| stdvar() | 对样本值求方差,是求取标准差过程中的中间状态 | stdvar(my_metric) |
| topk() | 返回最大的 k 个样本值及其时间序列 | topk(5, my_metric) |
| bottomk() | 返回最小的 k 个样本值及其时间序列 | bottomk(5, my_metric) |
| quantile() | 返回指定百分位数的样本值 | quantile(0.90, my_metric) |
| count_values() | 对样本值等于指定值的时间序列进行计数 | count_values(my_metric, “value_1”) count_values(my_metric, “value_2”) |
●topk() :逆序返回分组内的样本值最大的前 k 个时间序列及其值,即最大的 k 个样本值
●bottomk() :顺序返回分组内的样本值最小的前 k 个时间序列及其值,即最小的 k 个样本值
●quantile() :分位数,用于评估数据的分布状态,该函数会返回分组内指定的分位数的值,即数值落在小于等于指定的分位区间的比例
●count_values() :对分组内的时间序列的样本值进行数量统计,即等于某值的样本个数
二 、PromQL 理论部分
2.1 PromQL简介
PromQL(Prometheus Query Language)是 Prometheus 内置的数据查询语言,支持用户进行实时的数据查询及聚合操作。
| 概念回顾 | |
|---|---|
| 时间序列 | 简称时序,也就是监控指标数据,指某个监控指标在多维度标签条件下的表达式 |
| 样本值 | <指标名称>{<标签key1>=<值1>, <标签key2>=<值2>, ....} |
| 格式 | 某个时间序列在某个时间戳下的监控指标的具体数值 |
2.2 PromQL的数据类型
| 数据类型 | 描述 | |
|---|---|---|
| 瞬时向量 | Instant vector | 特定或全部的时间序列集合上,具有相同时间戳的一组样本值 |
| 区间向量 | Range vector | 特定或全部的时间序列集合上,在指定的同一时间范围内的所有样本值 |
| 标量数据 | Scalar | 一个浮点型的数据值 |
| 字符串 | String | 一个字符串,支持使用单引号、双引号进行引用 |
2.3 时间序列选择器
PromQL表达式 可使用 时间序列选择器 来过滤出所需的样本值。
用户可使用向量选择器表达式来挑选出,给定指标名称下的所有时间序列或部分时间序列的即时样本值,或至过去某个时间范围内的样本值,前者称为瞬时向量选择器,后者称为区间向量选择器。
2.3.1 瞬时向量选择器 (Instant Vector Selectors)
Part1 定义
瞬时向量选择器可以返回 0 个、1 个或多个时间序列上在给定时间戳(instant)上的各自的一个样本。
Part2 构成
| 构成 | 描述 | |
|---|---|---|
| 指标名称 | 可选 | 用于限定特定指标下的时间序列,即负责过滤指标 |
| 标签选择器 | 可选 | 用于过滤时间序列上的标签;定义在 {} 之中 |
瞬时向量选择器 通过<指标名称>{<标签key1><匹配操作符><值1>, ....} 表达式,得到时间序列在当前时间戳下的样本值。
| 标签选择器支持的匹配操作符 | 描述 |
|---|---|
= | 完全相等 |
!= | 不相等 |
=~ | 正则表达式匹配 |
!~ | 正则表达式不匹配 |
Part3 怎么定义瞬时向量选择器?
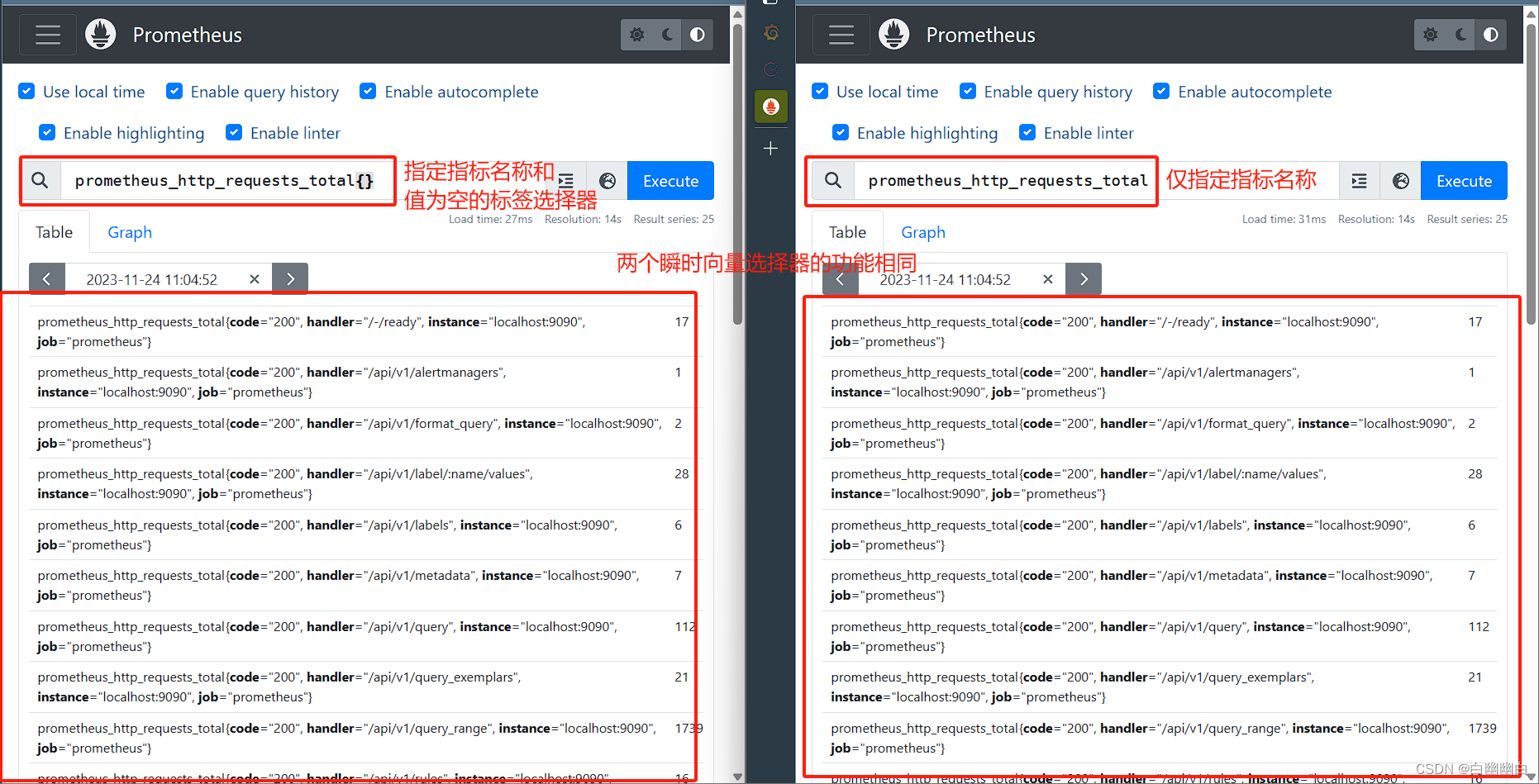
定义瞬时向量选择器时,以上两个部分应该至少给出一个,因此存在以下三种组合。
组合一: 仅给定指标名称,或在标签名称上使用了空值的标签选择器
返回给定的指标下,所有时间序列各自的即时样本。
#举个例子
#都是用于返回这个指标下各时间序列的即时样本
prometheus_http_requests_total 和 prometheus_http_requests_total{}
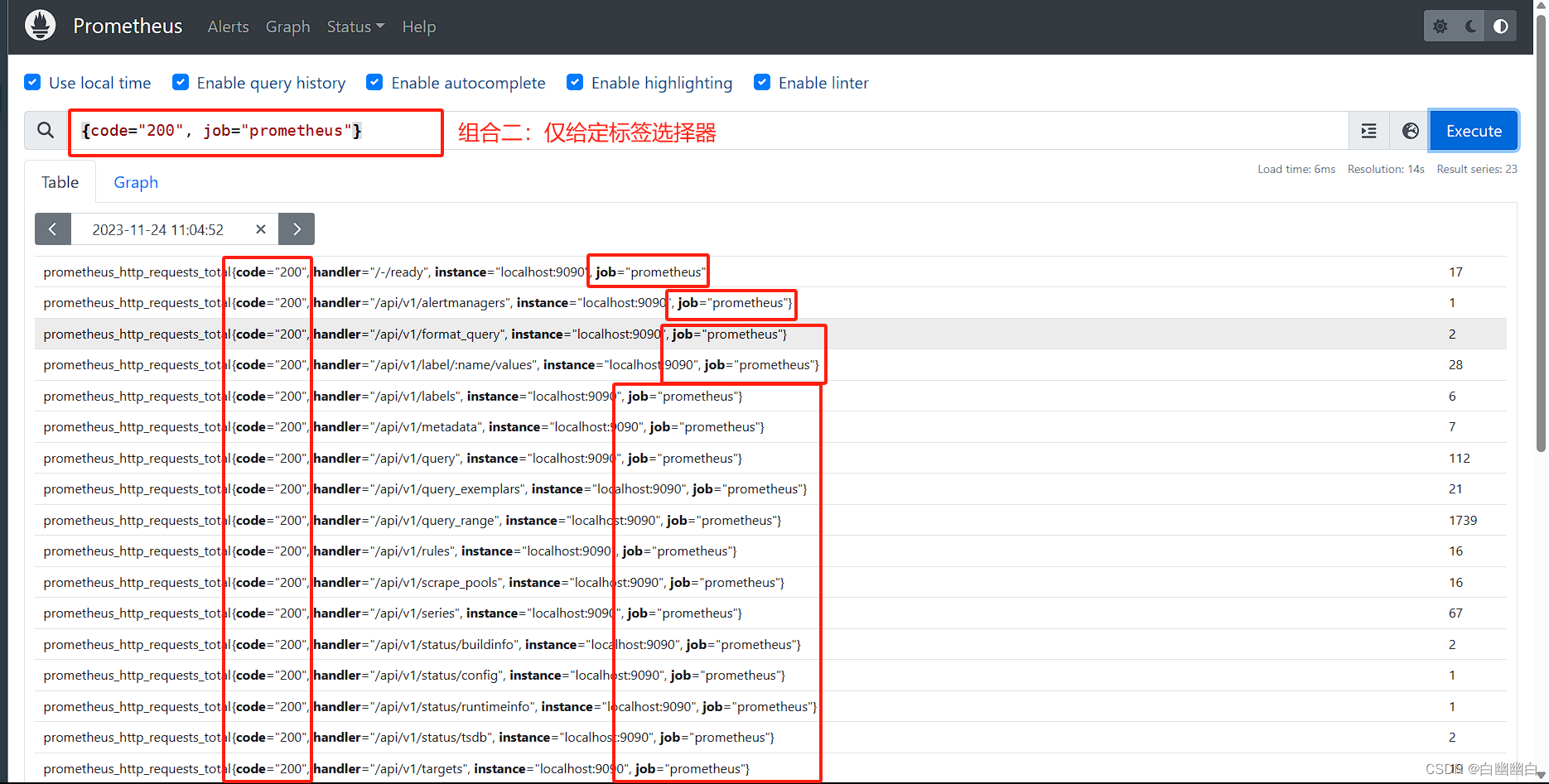
组合二: 仅给定标签选择器
返回所有符合给定的标签选择器的,所有时间序列上的即时样本。
#举个例子
{code="200", job="prometheus"}

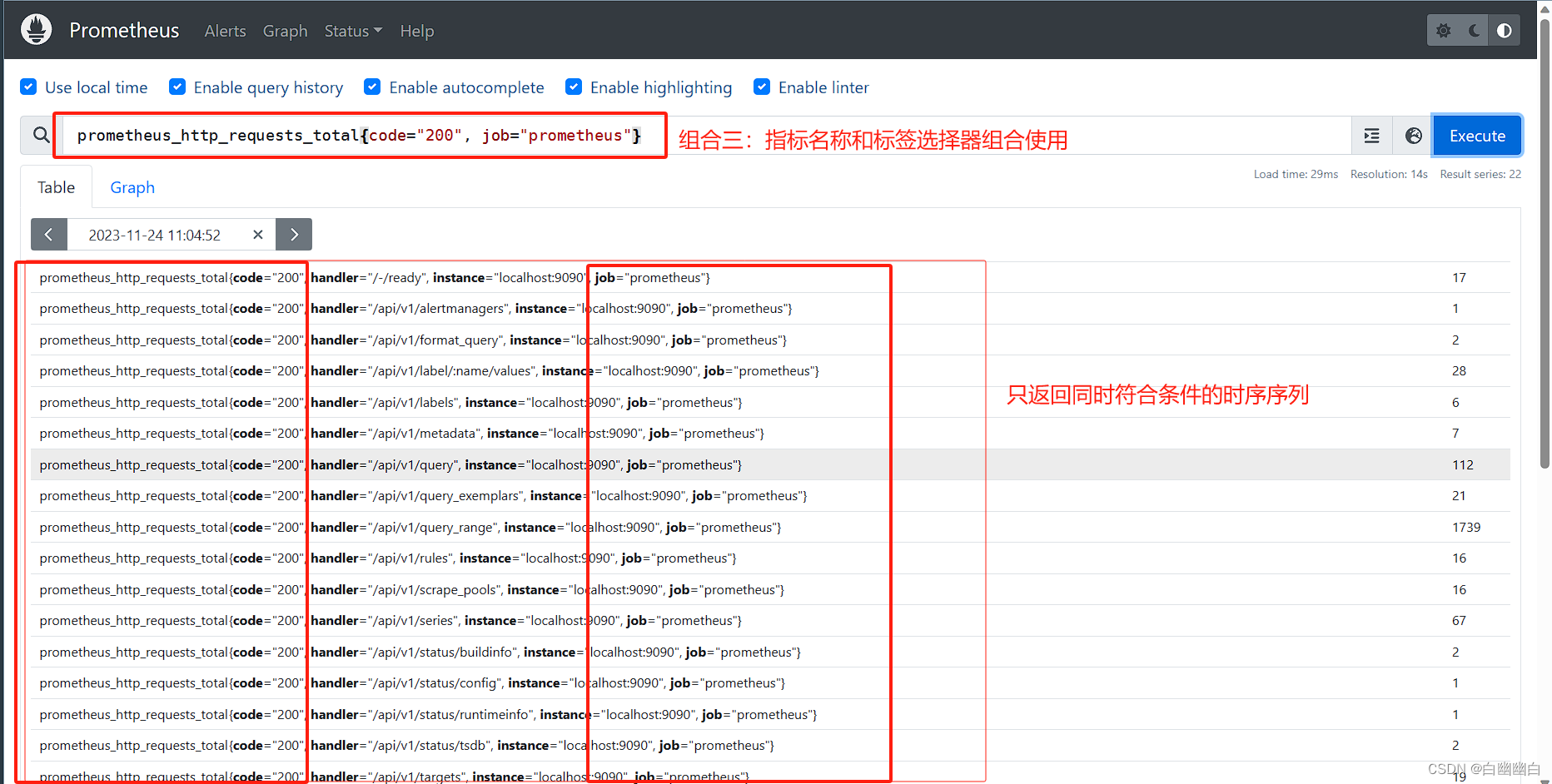
组合二: 指标名称和标签选择器的组合
返回给定的指标下的,且符合给定的标签过滤器的所有时间序列上的即时样本
#举个例子
prometheus_http_requests_total{code="200", job="prometheus"}
用于返回这个指标 code 为 200, 并且 job 为 prometheus 的时间序列的即时样本
Part4 注意事项
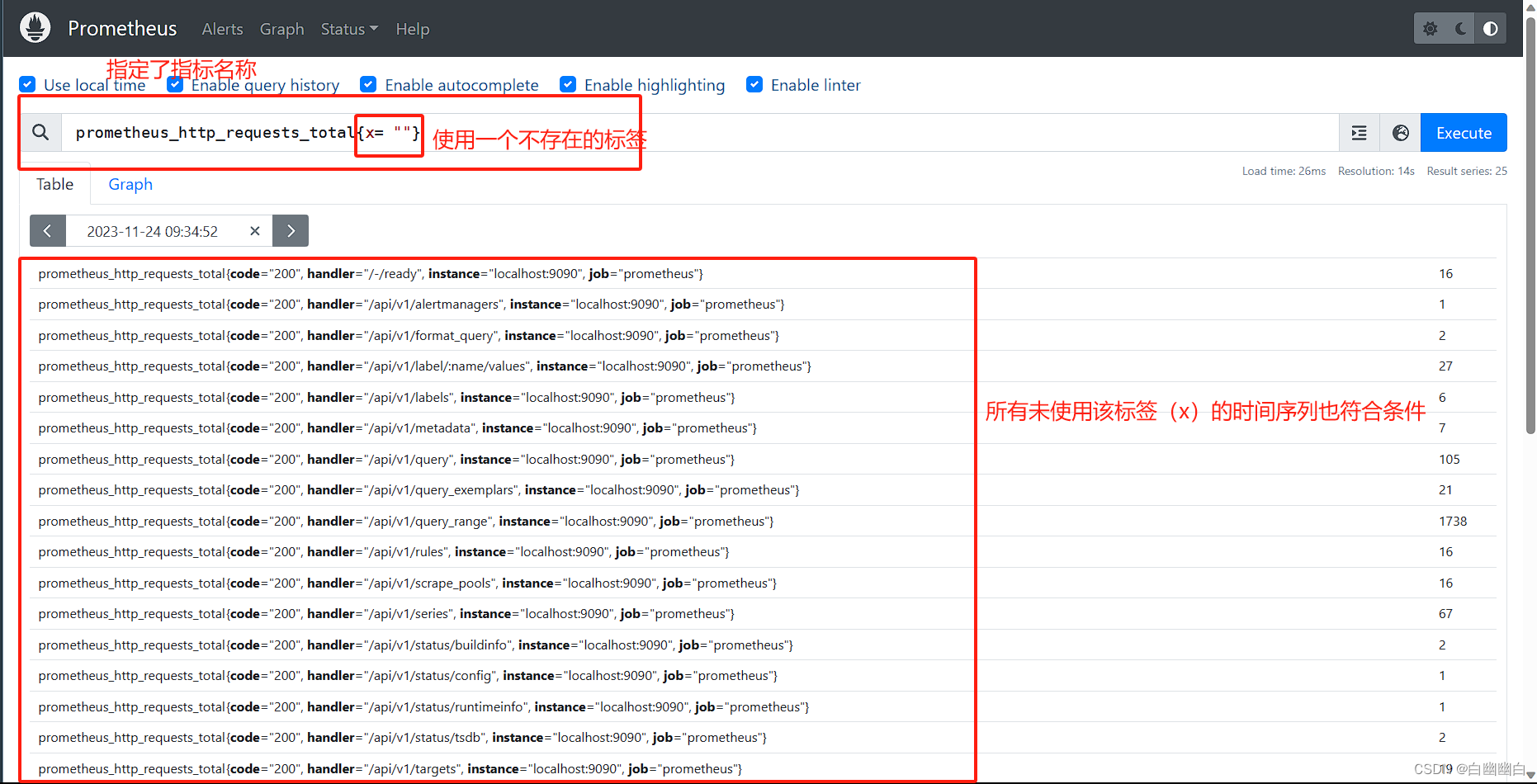
1)匹配到空标签值的标签选择器时,所有未定义该标签的时间序列同样符合条件;
#举个例子
prometheus_http_requests_total{x= ""}
#该指标名称上所有未使用该标签(x)的时间序列也符合条件
2)正则表达式将执行完全锚定机制,它需要匹配指定的标签的整个值;
3)向量选择器至少要包含一个指标名称,或者至少有一个不会匹配到空字符串的标签选择器;

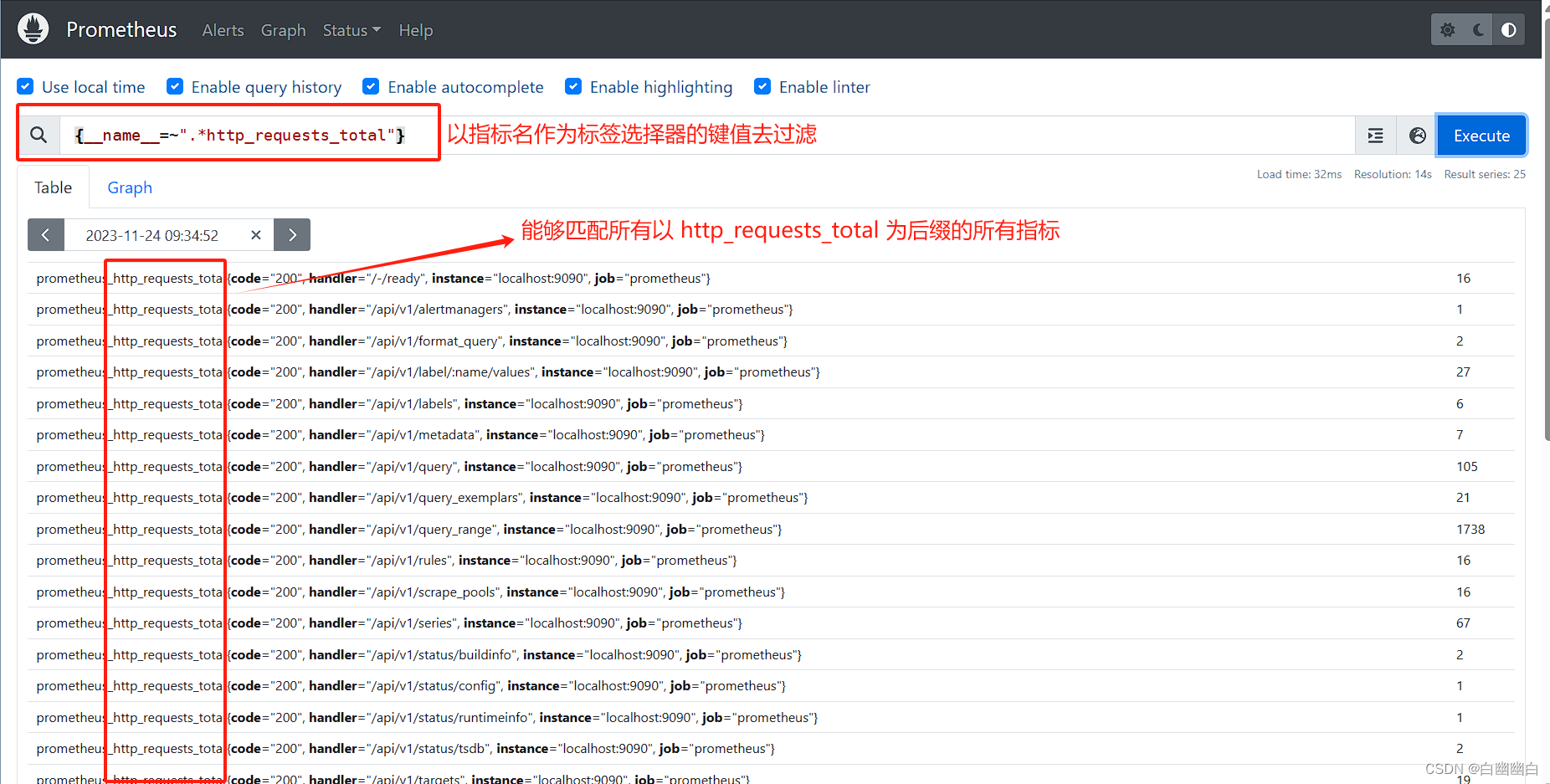
4)使用 name 做为标签名称,还能够对指标名称进行过滤;
#举个例子
{__name__=~".*http_requests_total"} 能够匹配所有以 http_requests_total 为后缀的所有指标
2.3.2 区间向量选择器 (Range Vector Selectors)
Part1 定义和工作原理
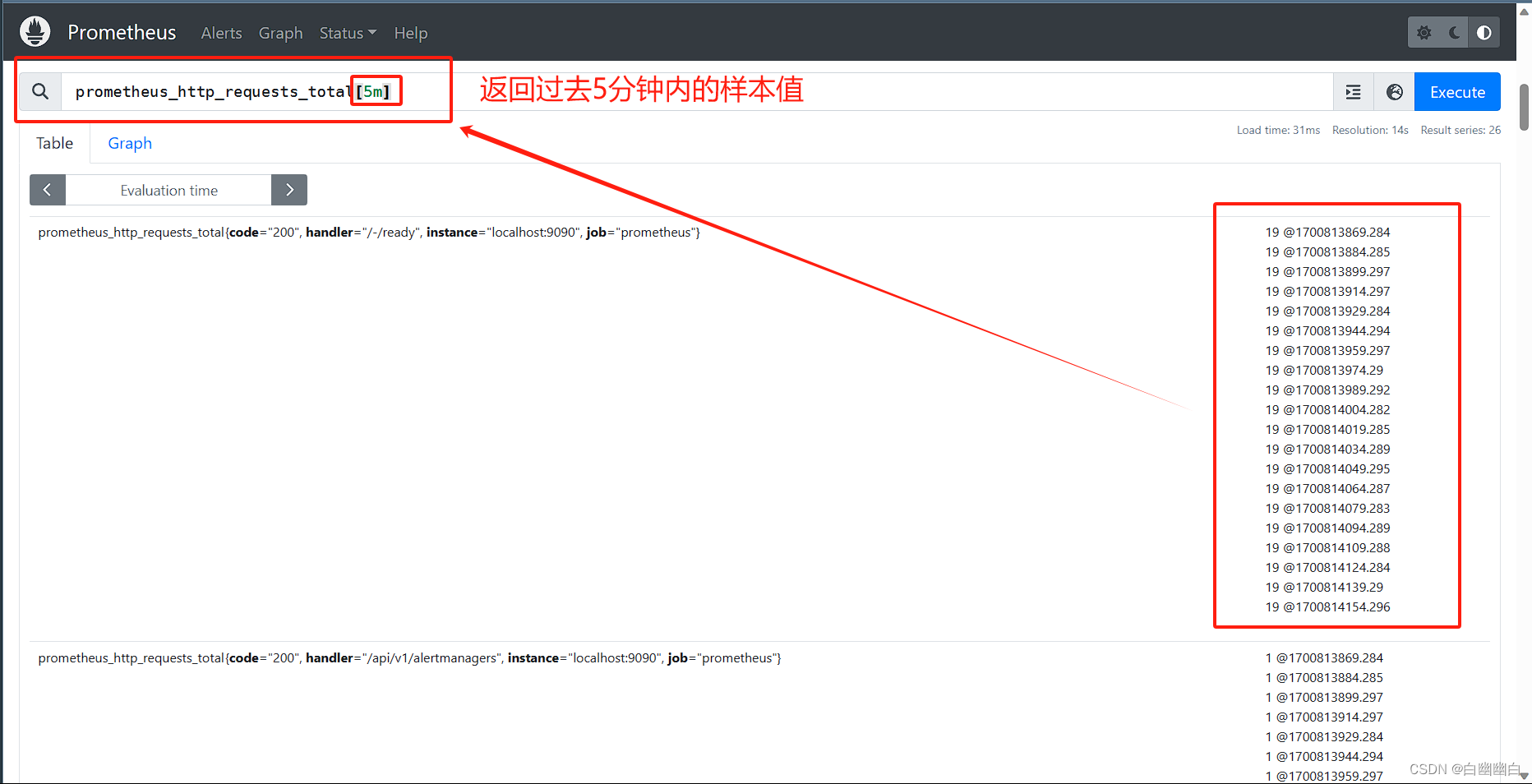
区间向量选择器 通过 <指标名称>{<标签key1>=<值1>, ....}[XX] 表达式,得到时间序列在以当前时间为基准的指定时间范围内的多个时间戳下的样本值。
区间向量选择器可以返回 0 个、1 个或多个时间序列上在给定时间范值围内的各自的一组样本。
区间向量选择器的不同之处在于,需要通过在瞬时向量选择器表达式后面,添加包含在 [ ] 里的时长,来表达需在时间时序上返回的样本所处的时间范围。
Part2 时间范围
时间范围: 以当前时间为基准时间点,指向过去一个特定的时间长度;
例如,[5m] 是指过去 5 分钟之内。
特性
1)可用的时间单位有 ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)、w(周)和 y(年)
2)必须使用整数时间,且能够将多个不同级别的单位进行串联组合,以时间单位由大到小为顺序,例如 1h30m,但不能使用 1.5h
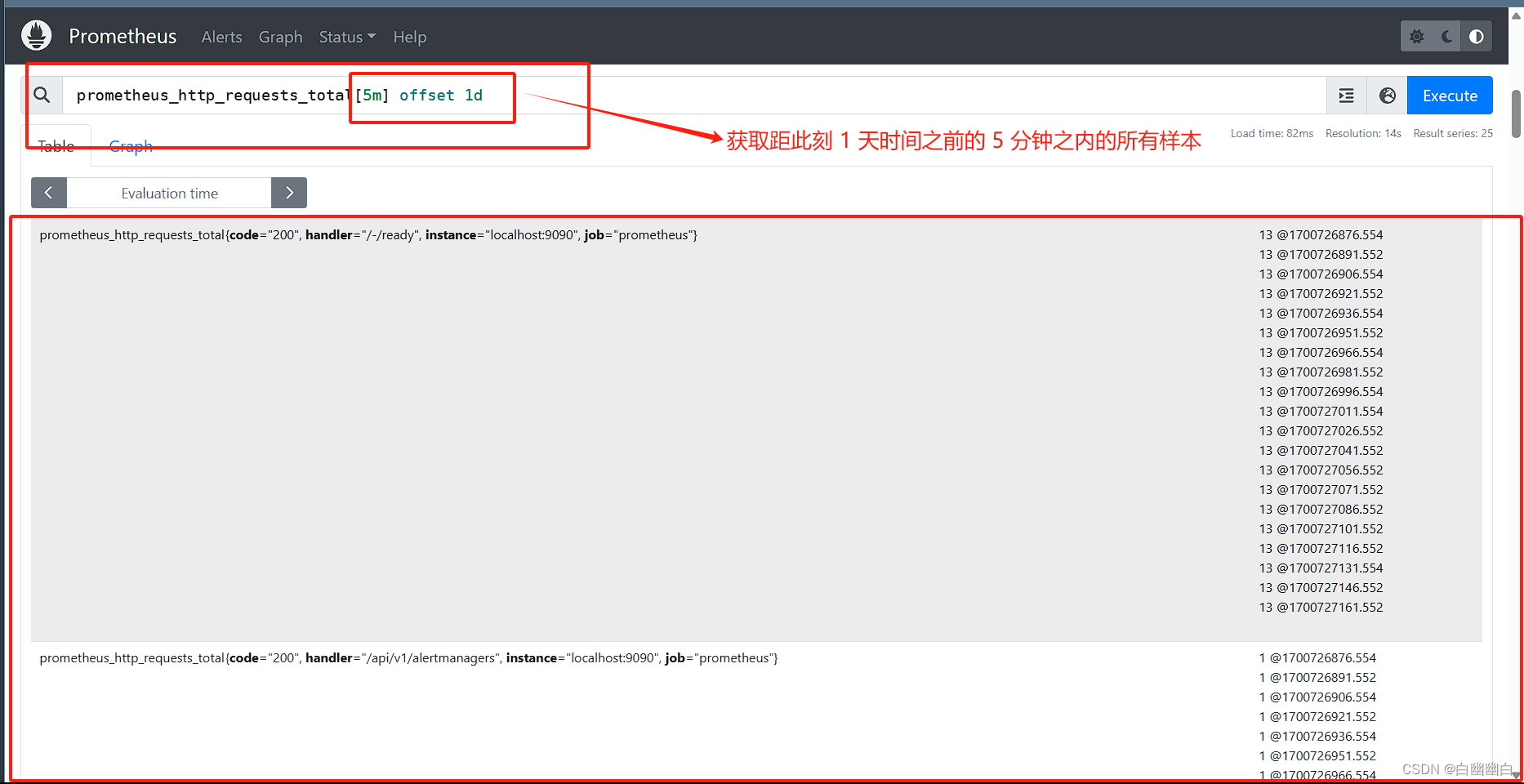
举个例子
2.3.3 偏移向量选择器
偏移修饰器紧跟在选择器后面,使用关键字 offset 来指定要偏移的量。
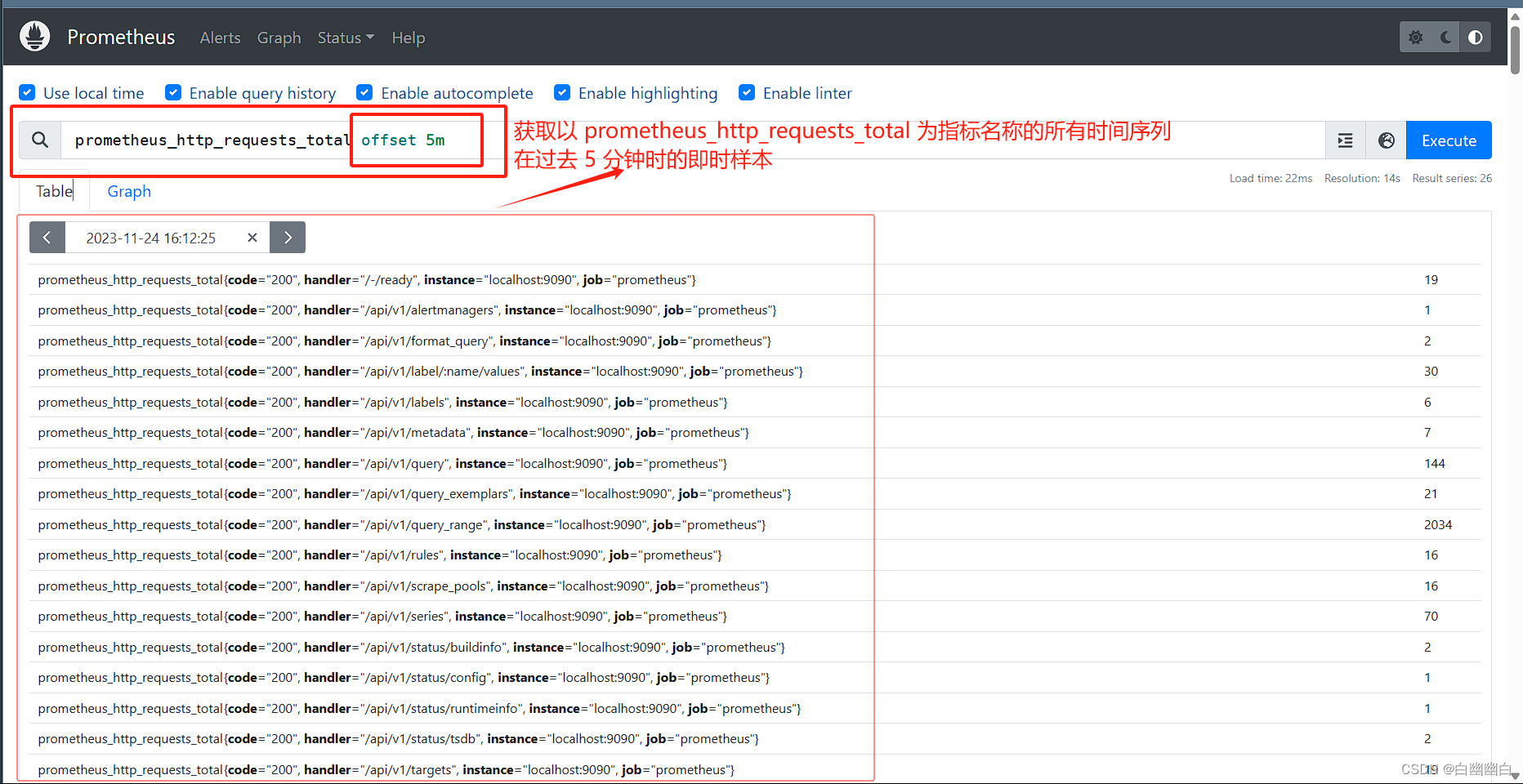
偏移向量选择器 通过 <指标名称>{<标签key1>=<值1>, ....} offset XX 表达式,得到时间序列在指定时间前的时间戳下的样本值。
#举个例子
prometheus_http_requests_total offset 5m
#表示获取以 prometheus_http_requests_total 为指标名称的所有时间序列在过去 5 分钟之时的即时样本;
偏移向量选择器 还可以通过 <指标名称>{<标签key1>=<值1>, ....}[XX] offset XX 表达式,得到时间序列在指定时间前的指定时间范围内的多个时间戳下的样本值。
#举个例子
prometheus_http_requests_total[5m] offset 1d
#表示获取距此刻 1 天时间之前的 5 分钟之内的所有样本