强化学习------时序差分(Temporal-Difference Learning)
简介
时序差分方法(Temporal-Difference Learning)简称TD算法是强化学习中非常经典的一种方法,Sarsa算法和Q-learning算法都是基于时序差分这种方法的。
强化学习分为基于模型和不基于模型的方法
- 基于模型的方法:是一种通过建立对环境的模型来预测状态和行动结果,然后基于这些预测来制定最优策略的方法在基于模型的强化学习中,智能体会尝试建立一个对环境的内部模型,该模型可以预测在给定状态下采取某个行动后可能产生的下一个状态,以及相应的奖励。这个内部模型可以是一个确定性模型,也可以是一个概率性模型。
- 不基于模型的方法:一种直接通过与环境的交互来学习最优策略的方法,而不依赖于对环境的内部模型的预测。在不基于模型的强化学习中,智能体通过与环境的交互来学习,观察采取不同行动后环境的反馈,并根据这些反馈来调整自己的策略。不基于模型的方法通常包括两个主要步骤:首先是通过与环境的交互来收集数据,然后使用这些数据来直接学习最优的策略。
总结来讲就是: 不基于模型,就基于数据
TD算法
TD算法是不基于模型的,即是基于数据的。
要的数据是什么呢?就是以下的数据:经验

就是策略
π
\pi
π产生的经验,即状态s、奖励r、下一状态s…这种序列。
TD算法的形式如下:
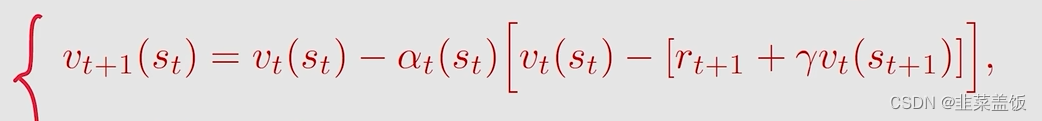
解释:
v
t
(
s
t
)
v_t(s_t)
vt(st)就是估计的state value值,state value的定义在贝尔曼方程中,可以翻看之前的文章进行查看。
首先
v
t
+
1
(
s
t
)
v_{t+1}(s_t)
vt+1(st)是对
v
t
(
s
t
)
v_t(s_t)
vt(st)的一个新的估计值,是由式子右边得到的。
r
t
+
1
+
γ
v
t
(
s
(
t
+
1
)
)
r_{t+1}+γv_t(s_(t+1))
rt+1+γvt(s(t+1))叫做TD target,实际上是希望
v
t
(
s
t
)
v_t(s_t)
vt(st)朝着TD target方向进行调整,就是更加接近于TD target,之后我们会介绍原理。
v
t
(
s
t
)
v_t(s_t)
vt(st)减去TD target,叫做TD error相当于损失值,

TD算法是怎么让
v
t
(
s
t
)
v_t(s_t)
vt(st)朝着TD target方向进行调整?
证明:
我们设TD target为
v
‾
t
\overline{v}_t
vt,则:
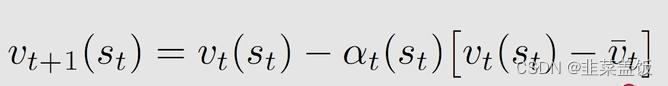
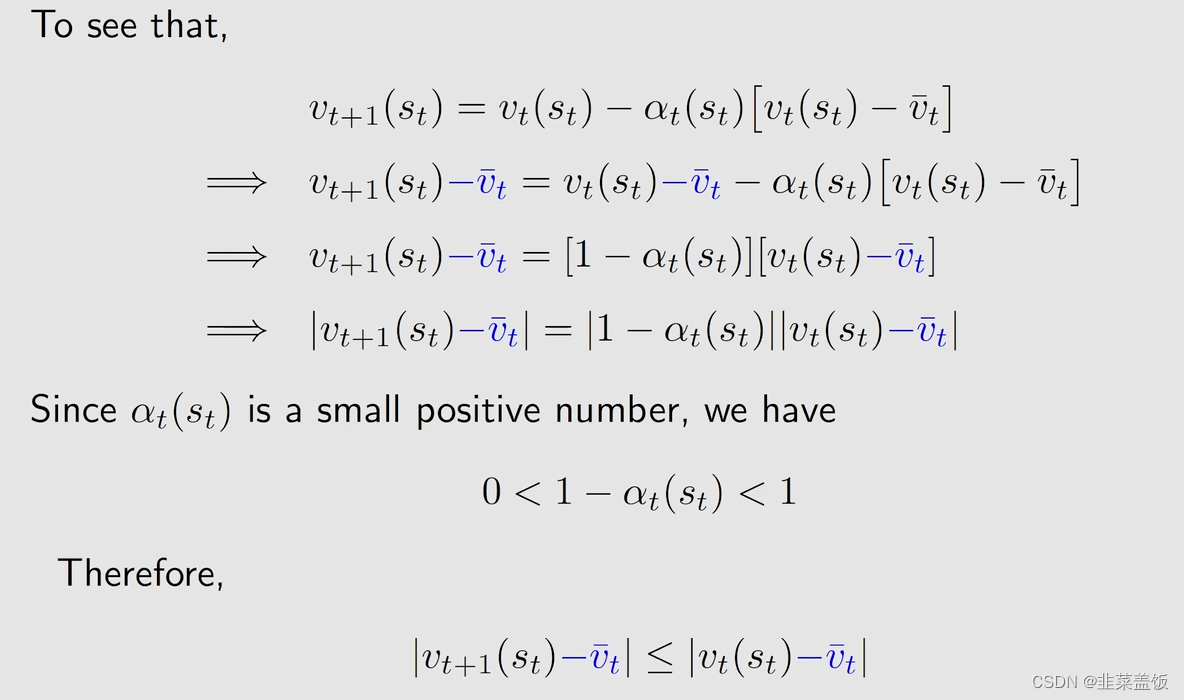
最下面这个式子表示,由
v
t
(
s
t
)
v_t(s_t)
vt(st)变成
v
t
+
1
(
s
t
)
v_{t+1}(s_t)
vt+1(st),会缩短和
v
‾
t
\overline{v}_t
vt的距离,即越来越靠近
v
‾
t
\overline{v}_t
vt,所以TD算法就是为了让
v
t
(
s
t
)
v_t(s_t)
vt(st)朝着TD target方向进行调整
TD error表示什么意思呢?
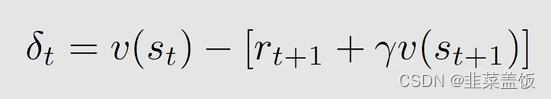
首先他表示了两个不同时间之间的差异,因为
v
s
t
v_{s_t}
vst表示t时间,
v
s
t
+
1
v_{s_{t+1}}
vst+1表示t+1的时间,这也是为什么叫做时序差分算法的原因。
其次他表示一种革新,我们的 v t ( s t ) v_t(s_t) vt(st)是一种估计值,但只这种估计可能是不准确的,这时候我们将其与新的经验( s t s_t st, r t + 1 r_{t+1} rt+1, s t + 1 s_{t+1} st+1)进行对比,产生了一个误差error,然后我们可以用这个error改进我们当前的这个估计。
TD 算法的性质
其本质就是在给定的策略下去估计state value,
并且他有如下的局限性:
- 不能估计action value
- 不能找到最优策略
不过以上两个问题,可以通过Sarsa算法以及Q-learning算法得到解决
Sarsa算法
Q-learning算法