10.Yarn概述
如果说HDFS是存储,则Yarn就是cpu和内存,mapreduce就是程序。
1.基础架构
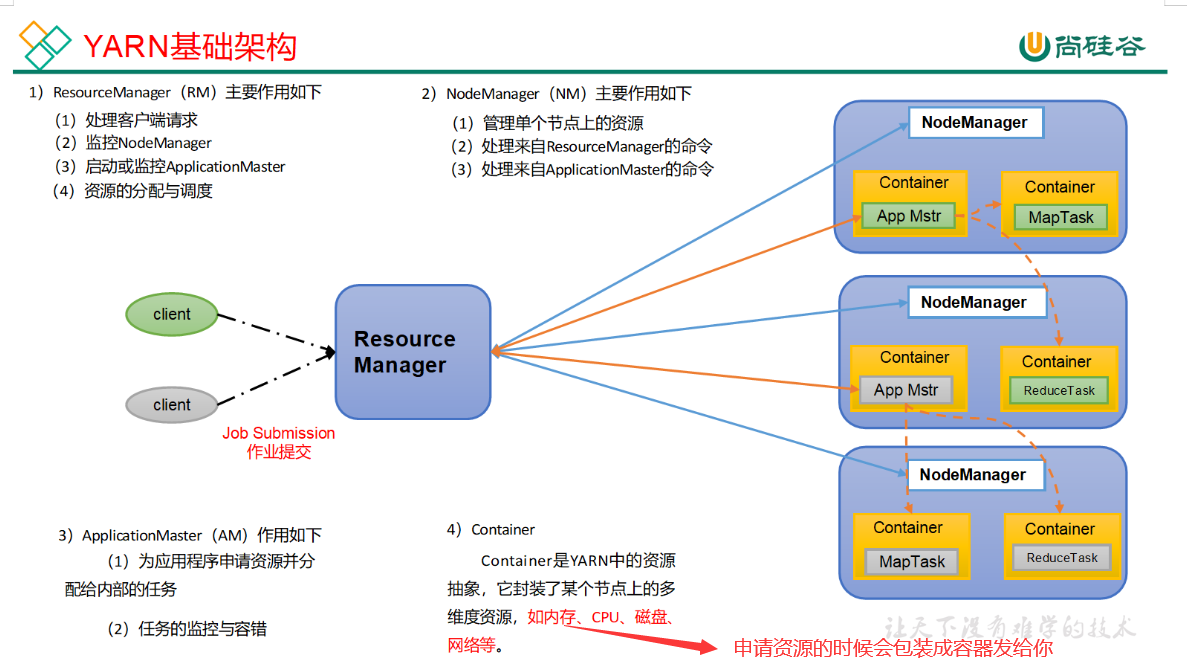
复习:
1.Container就是一个容器,其中封装了需要使用的内存与cpu
2.每当提交一个job,就会产生一个appMaster(总指挥),app Master负责其他container里面的MapTask和ReduceTask.
3.NodeManager是一个开关,真正跑任务的是appMaster.
2.Yarn工作机制
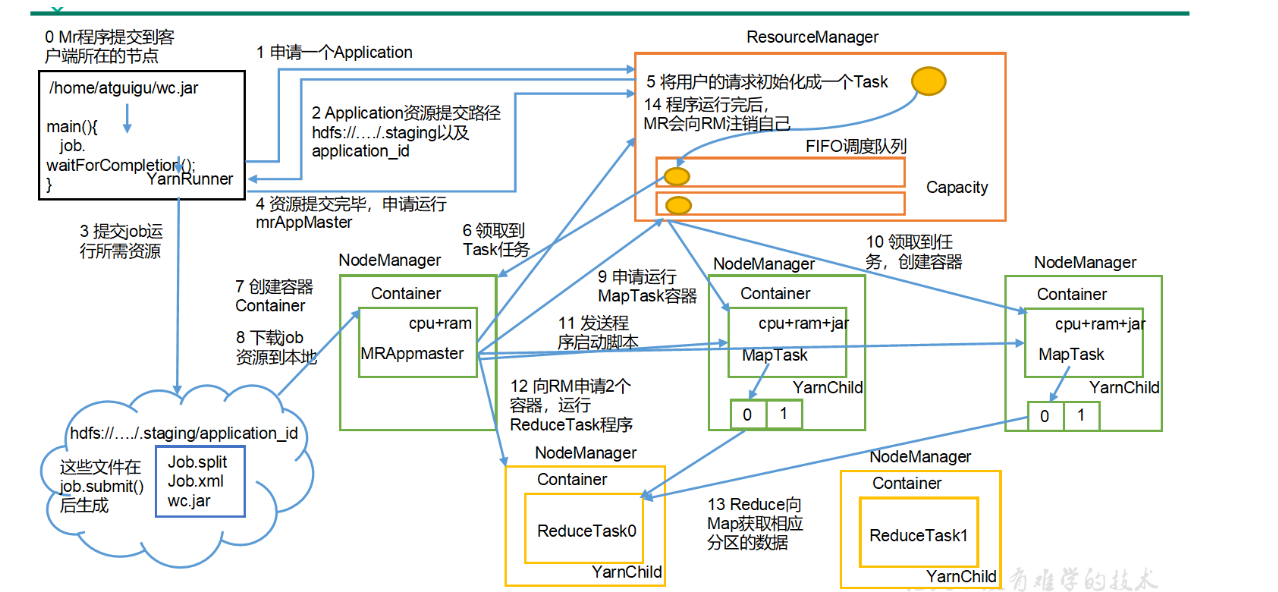
步骤解读:
- (0)MR程序提交到客户端所在的节点。
- (1)YarnRunner向ResourceManager申请一个Application。
- (2)RM将该应用程序的资源路径返回给YarnRunner。
- (3)该程序将运行所需资源提交到HDFS上。
- (4)程序资源提交完毕后,申请运行mrAppMaster。
- (5)RM将用户的请求初始化成一个Task。
- (6)其中一个NodeManager领取到Task任务。
- (7)该NodeManager创建容器Container,并产生MRAppmaster。
- (8)Container从HDFS上拷贝资源到本地。
- (9)MRAppmaster向RM 申请运行MapTask资源。
- (10)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
- (11)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
- (12)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
- (13)ReduceTask向MapTask获取相应分区的数据。
- (14)程序运行完毕后,MR会向RM申请注销自己。
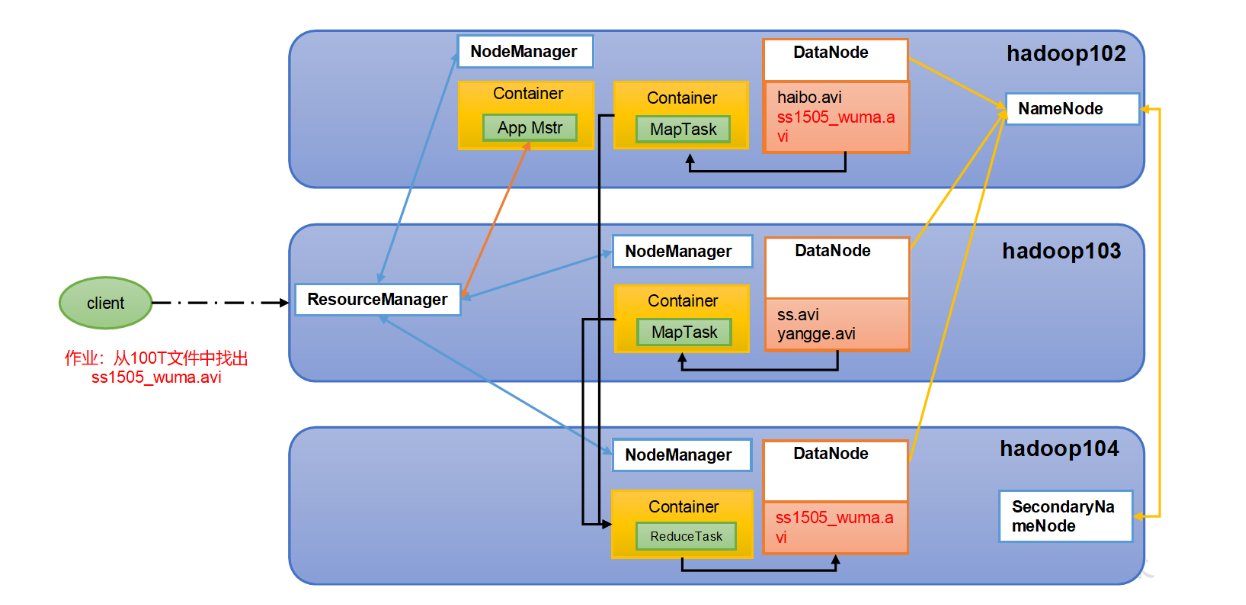
3.Hadoop三驾马车的关系
4.Yarn调度器
hadoop默认调度器有三种:先进先出调度器,容量调度器,公平调度器
1.FIFO
先进先出调度器
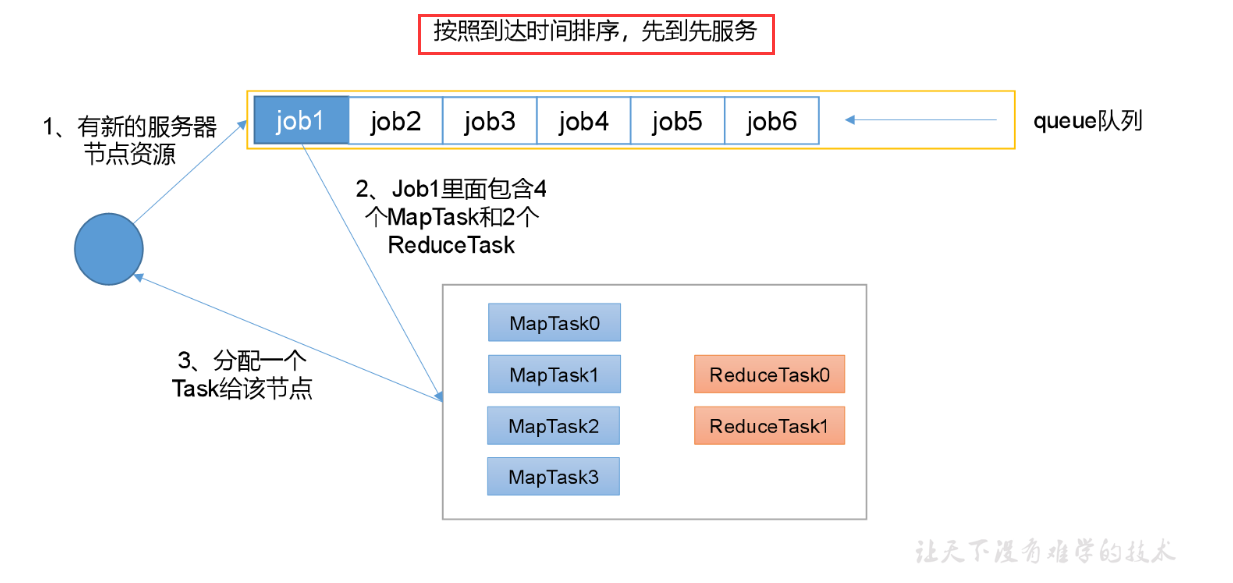
缺点:任务先到先执行,没有任务优先级一说
2.Capacity Scheduler
容量调度器

3.Fair Scheduler
公平调度器

关于缺额的解释:
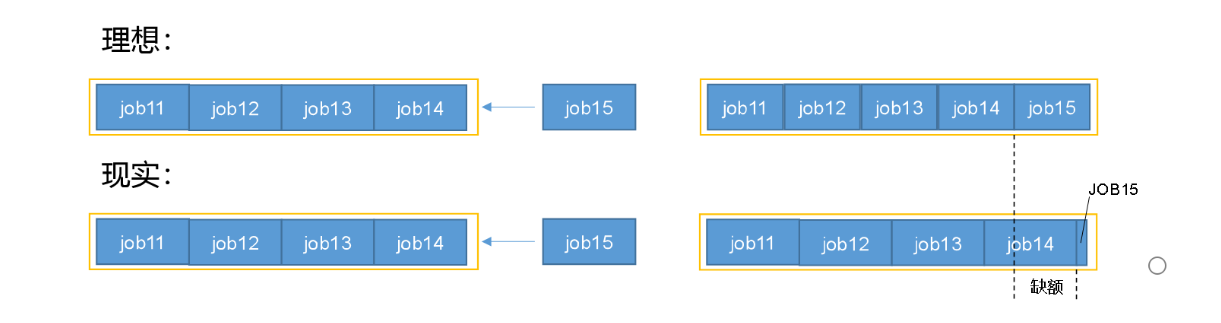
如上图,一个队列有20%的资源,跑四个任务,每个任务占比5%;这时候新加入一个任务,
理论上是五个人评价分配资源,但是实际上,当job5想要加入的时候,前面4个已经开始跑了,job5并不会里面得到资源。所以
某一时刻上,一个job应该获得的资源和实际获得资源的差据叫缺额
调度器会优先为缺额大的job分配资源:也就是说前面job释放的资源会优先提供给job5.但是每一个job都会有最小资源的保证
只要一直向缺额大的job分配资源,最终整个资源会达到动态平衡的状态
ps.理论上的资源也不是平均分的,而是根据job的需求和优先级(权重)确定

ps.资源调度器的修改在yarn-default.xml文件中:

5.Yarn常见配置
在yarn-site.xml里面配置,套用以下格式去改
<property>
<name> 需要添加的名称 </name>
<value> 需要添加的值 </value>
</property>
1.ResourceManager性能相关

2.Yarn集群资源配置(NodeManager)
2.1 自动配置(用的少)
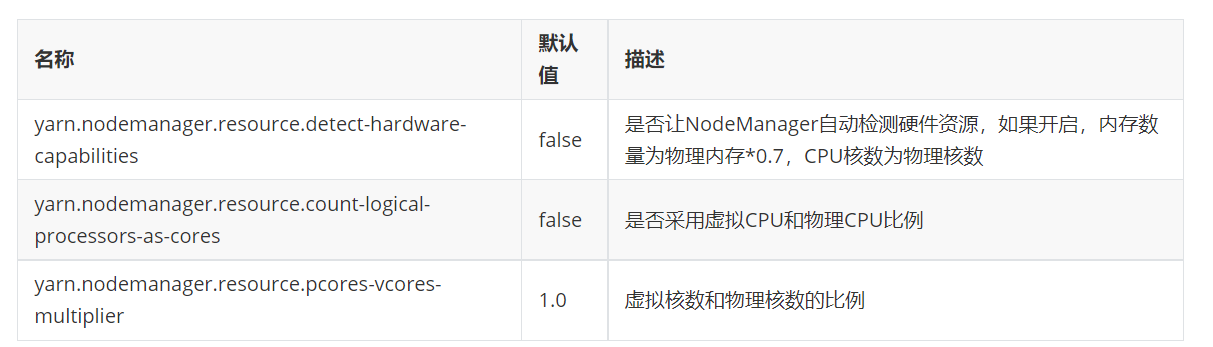
ps.虚拟核数就是骗yarn,让他以为job有更多资源
2.2 手动配置

3.Yarn容器资源配置
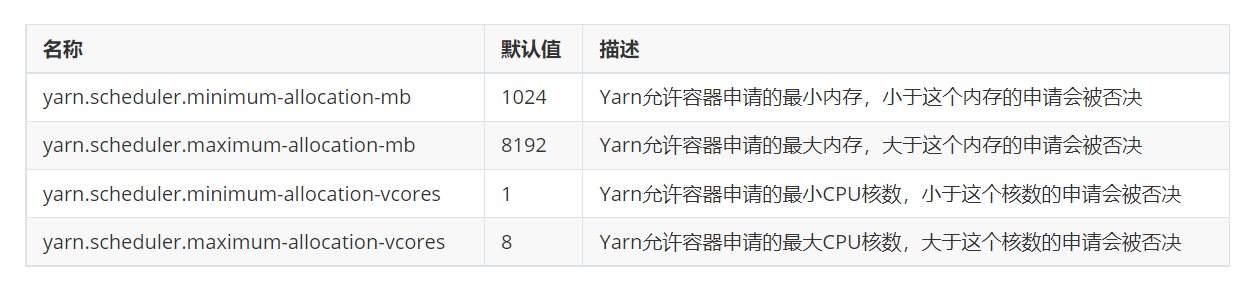
4.Yarn容器内存限制

ps.2.1的意思就是我允许你申请1G内存,但是你最大可以申请到2.1G的虚拟内存
5.容量调度器相关配置

ps.为什么默认值是0.1而不是1:如果appMaster占用的资源太多,那么mapTask和reduceTask的运行就会有问题
6. 多队列配置

多对列的使用案例:
ps.容量调度器只有一条Default队列,是一条单队列的调度器,在实际使用中会出现单个任务阻塞整个队列的情况。因此就需要我们按照业务种类配置多条任务队列。
在capacity-scheduler.xml进行如下配置:
ps.就是把defualt的内容复制一下,改成hive,然后修改value即可
1.指定多队列,增加hive队列
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,hive</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
2.降低default队列资源额定容量为40%,提升hive队列资源额定容量为60%
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>60</value>
</property>
3.配置hive队列的其他属性
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
</property>
<!-- 指定hive队列的资源最大容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value></value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name>
<value>*</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name>
<value>*</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name>
<value>-1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name>
<value>-1</value>
</property>
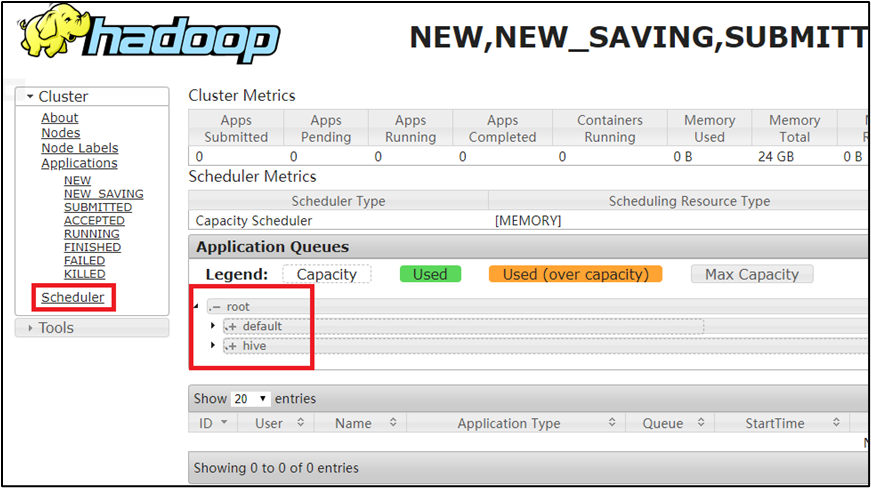
配置完成后,将hadoop102的配置同步到其他两台机器:
xsync / opt/ module/hadoop-3.1.3/ etc/hadoop/最后重启集群即可
结果如下:
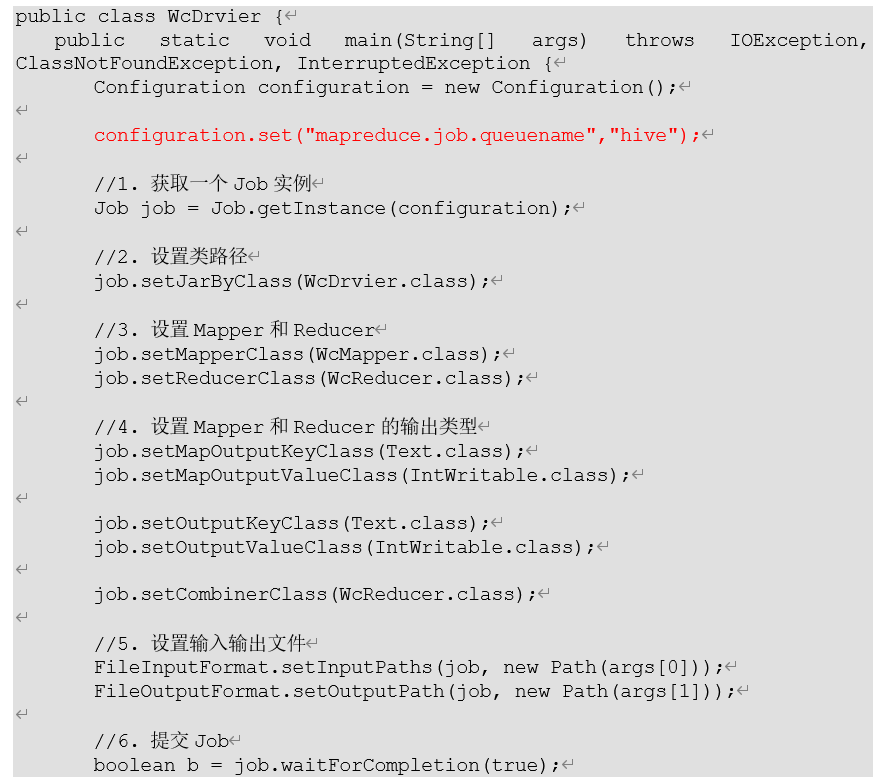
4. 最后在driver中声明
5.提交命令
向default提交命令:
hadoop jar \
/opt/module/hadoop-3.1.3\
/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar \
wordcount \
/input \
/xxx3向hive提交命令:
hadoop jar \
/opt/module/hadoop-3.1.3\
/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar \
wordcount \
-Dmapreduce.job.queuename=hive \
/input \
/xxx4