2.1 Linux C 编程
一、Hello World
1、在用户根目录下创建一个C_Program,并在这里面创建3.1文件夹来保存Hellow World程序;
2、安装最新版nvim
①sudo apt-get install ninja-build gettext cmake unzip curl
②sudo apt install lua5.1
③git clone https://github.com/neovim/neovim
④ 进入neovim cd neovim
⑤ 输入下面代码
make CMAKE_BUILD_TYPE=Release sudo make install
3、安装Nerd Font
① 输入wget https://github.com/ryanoasis/nerd-fonts/releases/download/v3.0.2/FiraMono.zip
② 安装unar, sudo apt install unar
③ 解压文件 unar FiraCode.zip
④之后按照下图操作

4、配置nvim.lazy
① git clone https://github.com/LazyVim/starter ~/.config/nvim;
② cd nvim进入nvim;
③ 输入nvim 既可开始安装lazy nvim;
5、打出Hellow World
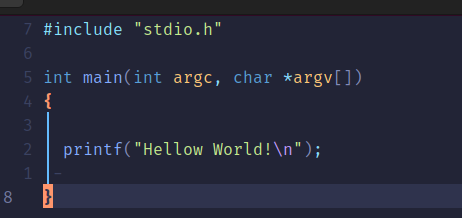
6、安装gcc、g++、make
① 直接安装 build-essential sudo apt-get install build-essential
② 查看GCC编译器的版本号 gcc -v
![]()
7、编译main.c
① 使用gcc编译器来编译文件 gcc mian.c

这个 a.out 就是编译生成的可执行文件。
② 执行文件 ./a.out

③ 指定可执行文件名字 gcc main.c -o mian

二、GCC 编译器
1.gcc命令
命令格式 gcc[选项] [文件名字]
主要选项:
-c :只编译不链接为可执行文件,编译器将输入的.c 文件编译为.o 的目标文件。
-o :<输出文件名>用来指定编译结束以后的输出文件名,如果使用这个选项的话 GCC 默认编译出来的可执行文件名字为 a.out。
-g :添加调试信息,如果要使用调试工具(如 GDB)的话就必须加入此选项,此选项指示编译的时候生成调试所需的符号信息。
-O :对程序进行优化编译,如果使用此选项的话整个源代码在编译、链接的的时候都会进行优化,这样产生的可执行文件执行效率就高。
-O2 : 比-O 更幅度更大的优化,生成的可执行效率更高,但是整个编译过程会很慢
2.编译流程
GCC 编译器的编译流程是:预处理、编译、汇编和链接。预处理就是展开所有的头文件、替换程序中的宏、解析条件编译并添加到文件中。编译是将经过预编译处理的代码编译成汇编代码,也就是我们常说的程序编译。汇编就是将汇编语言文件编译成二进制目标文件。链接就是将汇编出来的多个二进制目标文件链接在一起,形成最终的可执行文件。
三、Makefile基础
描述哪些文件需要编译、哪些需要重新编译的文件就叫做 Makefile。
1.引入Makefile
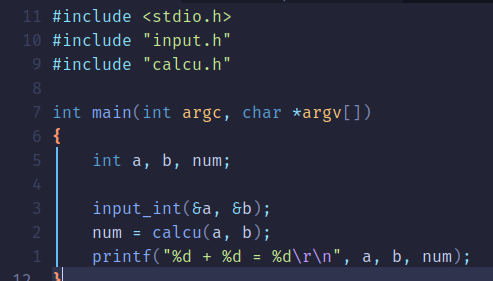
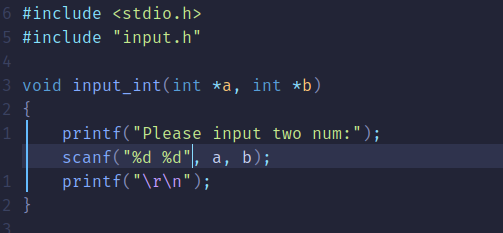
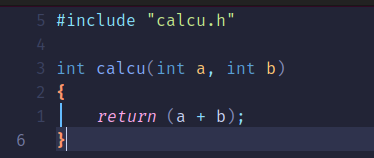
总共建立5个文件,分别是main.c、input.c、input.h、calcu.c、calcu.h,其中main.c是主体,input.c是负责接收从键盘输入的数值,calcu.c是进行任意两个数字相加。
main.c:
input.c:
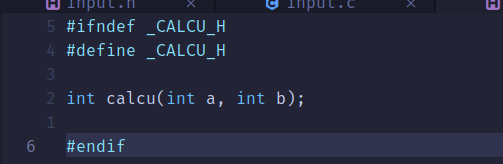
calcu.c:
input.h:
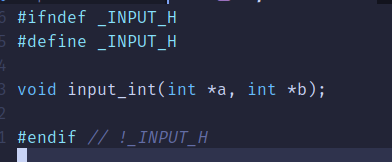
calcu.h:

编写完成后就开始用gcc来编写代码:gcc main.c calcu.c input.c -o main
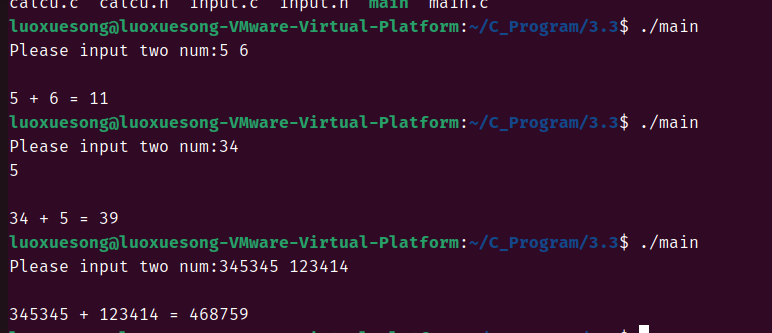
现在我们用makefile来做:
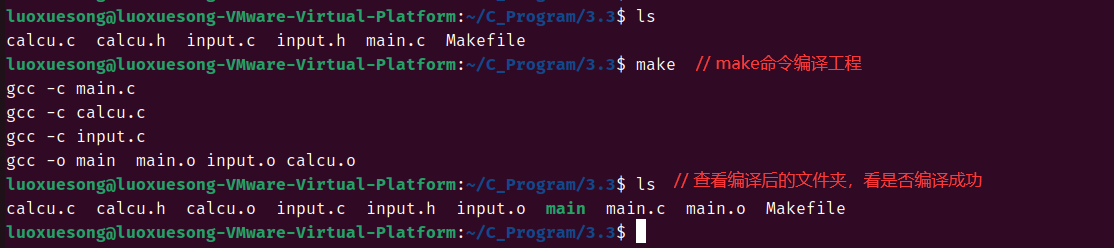
① 在工程目录下创建"Makefile"文件;

② 编写Makefile程序:
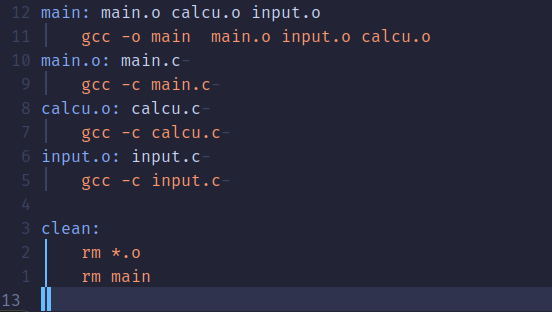
③ 使用make命令,这个命令会在当前目录下查找是否存在"Makefile"文件,如果存在就会按照Makefile文件的编译方式进行编译。
2.Makefile语法
目标···...:依赖文件集合······
命令1
命令2
.........
例如:
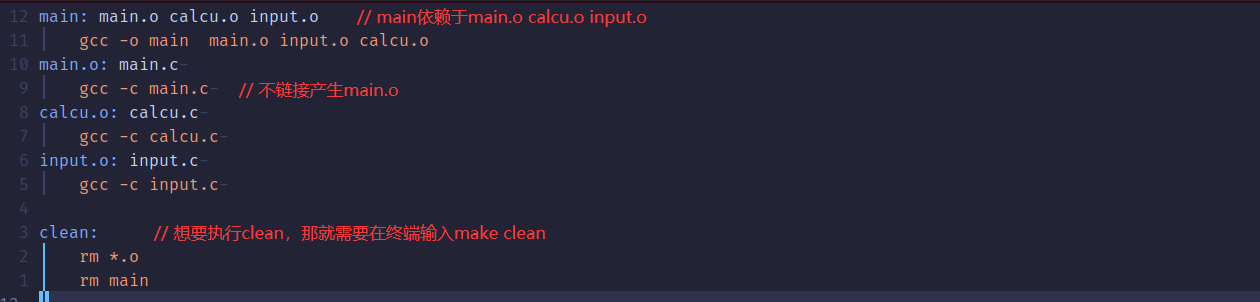
main: main.o calcu.o input.o
gcc -o main main.o input.o calcu.o这条规则的目标是 main, main.o、 input.o 和 calcu.o 是生成 main 的依赖文件,并且命令列表中的每条命令必须以TAB键开始,不能使用空格。

Make的执行过程:
1、make 命令会在当前目录下查找以 Makefile(makefile 其实也可以)命名的文件。
2、当找到 Makefile 文件以后就会按照 Makefile 中定义的规则去编译生成最终的目标文件。
3、当发现目标文件不存在,或者目标所依赖的文件比目标文件新(也就是最后修改时间比目标文件晚)的话就会执行后面的命令来更新目标。
3.Makefile 变量
Makefile中的变量都是字符串,类似于C语言的宏。
main: main.o calcu.o input.o
gcc -o main main.o input.o calcu.o可以将上面的代码改为以下代码:

在Makefile中,变量的引用是:$(变量名)
①赋值符 "="
使用“=”在给变量的赋值的时候,不一定要用已经定义好的值,也可以使用后面定义的值,比如如下代码:
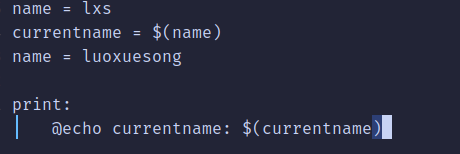

这里的echo跟c语言中的printf一样,加"@"就不会输出命令执行过程。
②赋值符 ":="
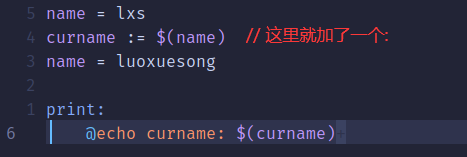

这里的":="不会使用后面定义的变量,只使用前面定义好的。
③赋值符 "?="
curname ?= luoxuesong
这句代码意思是:如果变量curname前面没有被赋值,那么变量就是"luoxuesong",如果前面已经赋值过了,那就使用前面的变量。
④变量追加 "+="
objects = main.o input.o
objects += calcu.o
有些时候需要给定义好的变量添加一些字符串进去,这时候就要使用"+="。最开始变量 objects 的值为 main.o input.o ,后面追加了一个 calcu.o ,所以最后 objects 的值为 main.o input.o calcu.o 。
4.Makefile 模式规则

模式规则中,至少在规则的目标定定义中要包涵“%”,否则就是一般规则,目标中的“%”表示对文件名的匹配,“%”表示长度任意的非空字符串,比如“%.c”就是所有的以.c 结尾的文件,类似与通配符, a.%.c 就表示以a.开头,以.c 结束的所有文件。当“%”出现在目标中的时候,目标中“%”所代表的值决定了依赖中的“%”值,使用方法如下。

但是make现在还用不了。
5.Makefile 自动化变量
自动化变量: 通过一行命令来从不同的依赖文件中生成对应的目标。 这种变量会把模式中所定义的一系列的文件自动的挨个取出,直至所有的符合模式的文件都取完,自动化变量只应该出现在规则的命令中。常用的自动话变量如下。
| 自动化变量 | 描述 |
| $@ | 规则中的目标集合,在模式规则中,如果有多个目标的话,“$@”表示匹配模式中定义的目标集合。 |
| $% | 当目标是函数库的时候表示规则中的目标成员名,如果目标不是函数库文件,那么其值为空。 |
| $< | 依赖文件集合中的第一个文件,如果依赖文件是以模式(即“%” )定义的,那么“$<”就是符合模式的一系列的文件集合。 |
| $? | 所有比目标新的依赖目标集合,以空格分开。 |
| $^ | 所有依赖文件的集合,使用空格分开,如果在依赖文件中有多个重复的文件,“$^”会去除重复的依赖文件,值保留一份。 |
| $+ | 和“$^”类似,但是当依赖文件存在重复的话不会去除重复的依赖文件。 |
| $* | 这个变量表示目标模式中"%"及其之前的部分,如果目标是 test/a.test.c,目标模式为 a.%.c,那么“$*”就是 test/a.test。 |
最常用的"$@、$<和$^"。下面就用模式规则和自动化变量来实现精简Makefile。
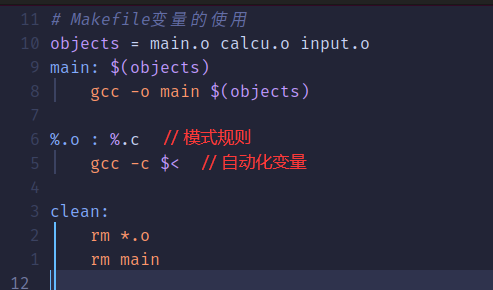
6.Makefile 伪目标
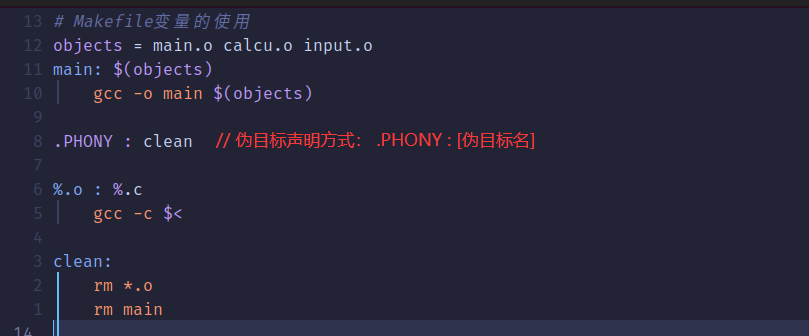
一般的目标名都是要生成的文件,而伪目标不代表真正的目标名,在执行make 命令的时候通过指定这个伪目标来执行其所在规则的定义的命令。
使用伪目标的主要是为了避免 Makefile 中定义的只执行命令的目标和工作目录下的实际文件出现名字冲突,有时候我们需要编写一个规则用来执行一些命令,但是这个规则不是用来创建文件的,比如在前面的 clean ,但如果工程目录下创建一个名为"clean"的文件,当执行make clean时, 规则因为没有依赖文件,所以目标被认为是最新的,因此后面的 rm 命令也就不会执行,我们预先设想的清理工程的功能也就无法完成。
6.Makefile 条件判断
# 语法1
<条件关键字>
<条件为真时执行的语句>
endif
# 语法2
<条件关键字>
<条件为真时执行的语句>
else
<条件为假时执行的语句>
endif关键字有4个:ifeq、ifneq、ifdef和ifndef。
ifeq就是来判断是否相等,ifneq就是来判断是否不想等。
ifeq (<参数 1>, <参数 2>)
ifeq ‘<参数 1 >’ ,‘ <参数 2>’
ifeq “<参数 1>” , “<参数 2>”
ifeq “<参数 1>” , ‘<参数 2>’
ifeq ‘<参数 1>’ , “<参数 2>”ifdef 和 ifndef 用法如下:
ifdef<变量名>
如果“变量名”的值非空,那么表示表达式为真,否则表达式为假。“变量名”同样可以是一个函数的返回值。
7.Makefile 函数
Makefile中不支持自定义函数。
函数用法如下:
$(函数名 参数集合) 或 ${函数名 参数集合}
①函数 "subst"
函数 subst 用来完成字符串替换。
命令格式: $(subst <from>,<to>,<text>)
此函数的功能是将字符串<text>中的<from>内容替换为<to>,函数返回被替换以后的字符串,例如:
$(subst lxs, LXS, my name is lxs)
这段代码的意思是:把 my name is lxs 中的 lxs 改为 LXS ,所以最后结果为 my name is LXS 。
②函数 "patsubst"
函数 patsubst 用来完成模式字符串替换。
命令格式: $(patsubst <pattern>,<replacement>,<text>)
此函数查找字符串<text>中的单词是否符合模式<pattern>,如果匹配就用<replacement>来替换掉, <pattern>可以使用包括通配符“%”,表示任意长度的字符串,函数返回值就是替换后的字符串。如果<replacement>中也包涵“%”,那么<replacement>中的“%”将是<pattern>中的那个“%”所代表的字符串。例如:
$(patsubst %.c,%.o,a.c b.c c.c)
这段代码意思是:将字符串“a.c b.c c.c”中的所有符合“%.c”的字符串,替换为“%.o”,替换完成以后的字符串为“a.o b.o c.o”。
③函数 "dir"
函数dir是获取目录。
命令格式: $(dir<names…>)
此函数用来从文件名序列<names>中提取出目录部分,返回值是文件名序列<names>的目录部分。例如:
$(dir</src/a.c>)
这段代码意思是:提取文件"/src/a.c"的目录部分,也就是"/src"。
④函数 "notdir"
函数 notdir 去除文件中的目录部分,也就是提取文件名。
命令格式: $(notdir <names…>)
例如: $(notdir </src/a.c>)
这段代码意思是:提取文件"/src/a.c"中的非目录部分,也就是文件名"a.c"。
⑤函数 "foreach"
foreach 函数用来完成循环。
命令格式: $(foreach <var>, <list>,<text>)
此函数的意思就是把参数<list>中的单词逐一取出来放到参数<var>中,然后再执行<text>所包含的表达式。每次<text>都会返回一个字符串,循环的过程中, <text>中所包含的每个字符串会以空格隔开,最后当整个循环结束时, <text>所返回的每个字符串所组成的整个字符串将会是函数 foreach 函数的返回值。
⑥函数 "wildcard"
通配符“%”只能用在规则中,只有在规则中它才会展开,如果在变量定义和函数使用时,通配符不会自动展开,这个时候就要用到函数 wildcard
命令格式: $(wildcard PATTERN…)
例如: $(wildcard *.c)
这段代码意思是:来获取当前目录下所有的.c 文件,类似“%”。