专业爬虫框架 -- scrapy初识及基本应用
scrapy基本介绍
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。
但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。
因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
Scrapy架构
百度上找到的Scrapy架构图:
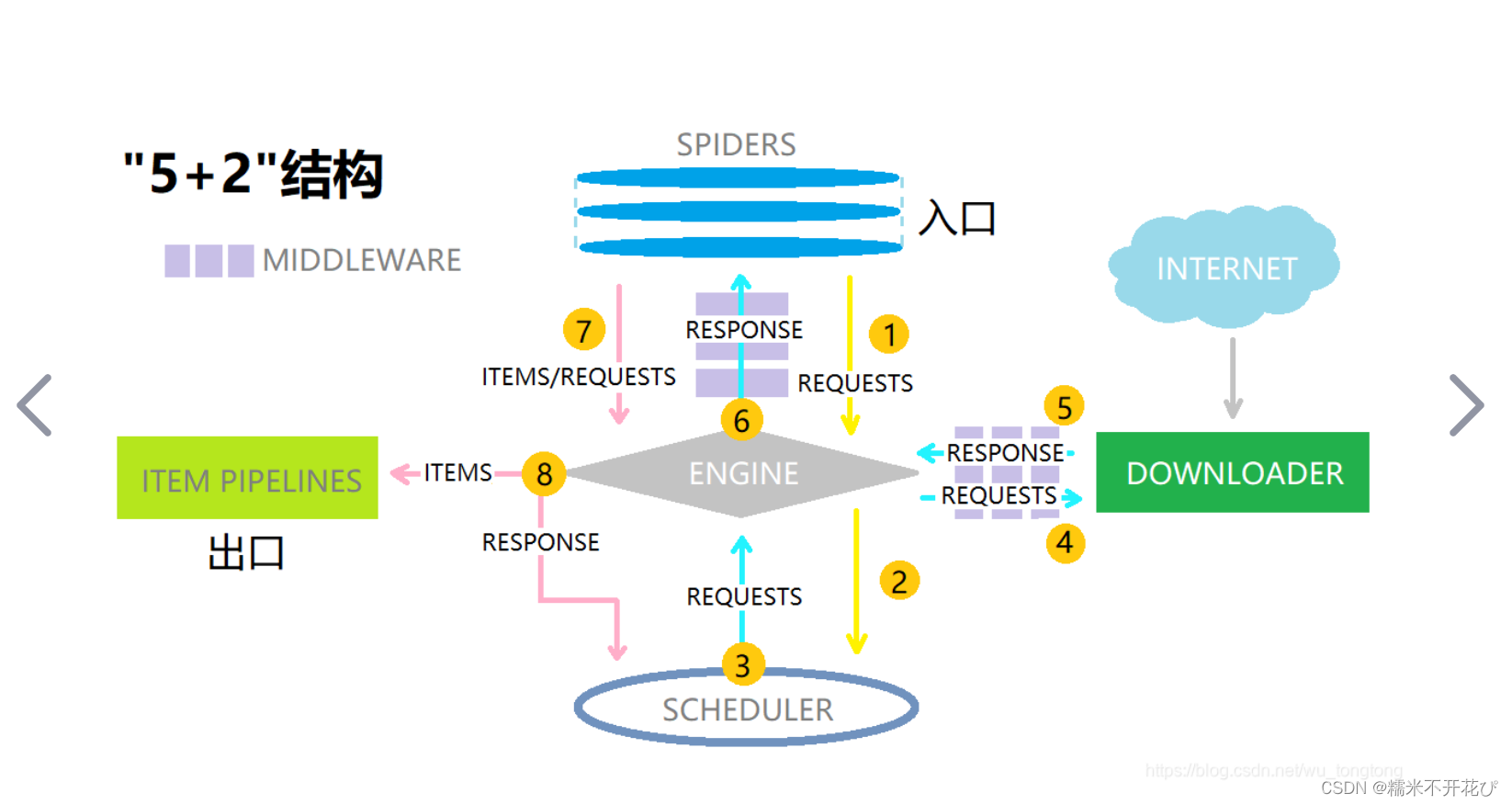
1、引擎(Engine):
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
------>>>
2、调度器(Scheduler):
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址------>>>
3、下载器(Dowloader):
用于下载网页内容, 并将网页内容返回给Engine,下载器是建立在twisted这个高效的异步模型上的------>>>
4、爬虫(Spiders):
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求------>>>
5、项目管道(Item Pipelines):
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从Engine传到Downloader的请求request,已经从Downloader传到Engine的响应response。------>>>
6、爬虫中间件(Spider Middlewares):
位于Engine和SPIDERS之间,主要工作是处理Spiders的输入(即responses)和输出(即requests)
Scrapy安装
windows安装命令:pip3 install scrapy
依赖项安装:
pip3 install lxml
pip3 install whee
pip3 install pyopenssl
依赖项如果已经安装的可以跳过
官网链接:ghttps://docs.scrapy.org/en/latest/topics/commands.htmlscrapy官网链接:ghttps://docs.scrapy.org/en/latest/topics/commands.html
scrapy框架使用及命令详解
常用命令
查看帮助
scrapy -h
scrapy <command> -h有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要
Global commands
startproject #创建项目
genspider #创建爬虫程序
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本Project-only commands
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
edit #编辑器,一般不用
parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确
bench #scrapy bentch压力测试对于爬虫而言,我们需要关心及常用的命令就三个:
startproject创建项目、 genspider创建爬虫程序、crawl启动爬虫
创建项目
手动新建一个“day23”的文件夹,进入Teminal终端
scrapy startproject Newspro #Newspro是项目名称回车执行后就会自动帮我“day23”的文件夹下创建Newspro
ps:这里项目名称如果写成News pro,day23下父级目录会叫pro,然后是子级目录News
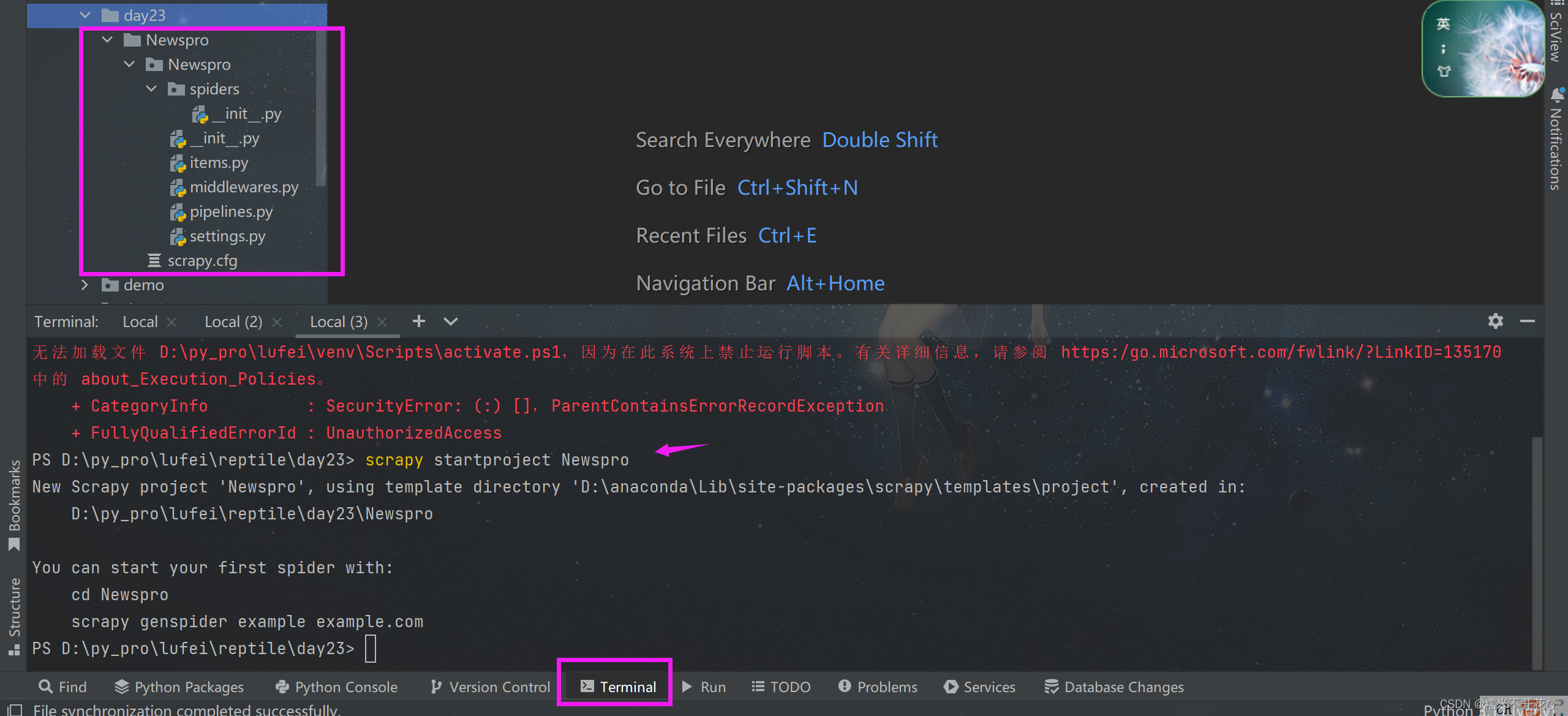
文件目录:

文件说明:
● scrapy.cfg:项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中。
● items.py:设置数据存储模板,用于结构化数据,如:Django的Model
● pipelines:数据处理行为,如:一般结构化的数据持久化
● settings.py:配置文件,如:递归的层数、并发数,延迟下载等。强调:配置文件的选项必须大写否则视为无效,正确写法USER_AGENT='xxxx'
● spiders:爬虫目录,如:创建文件,编写爬虫规则
创建爬虫程序
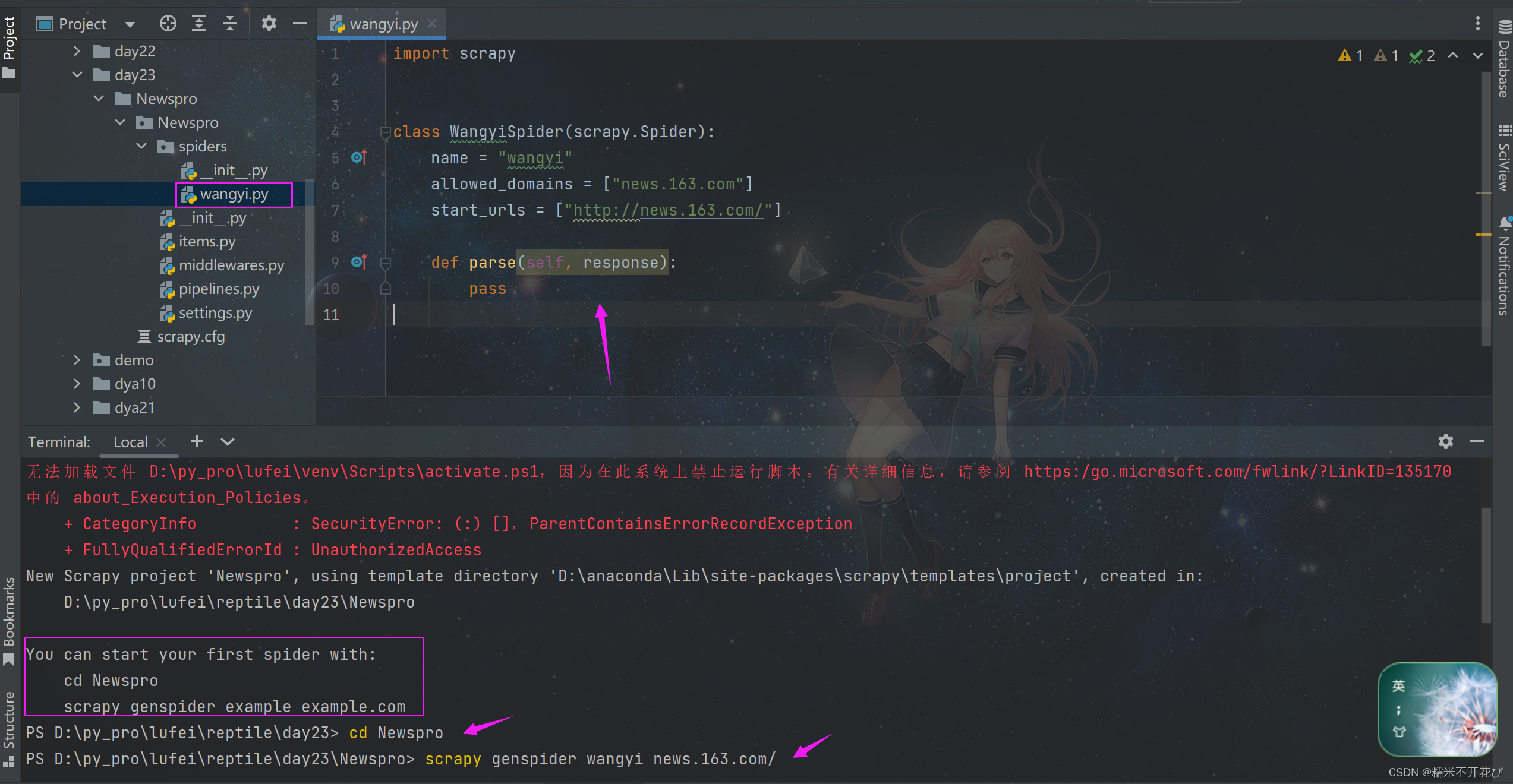
上一步Teminal终端中创建完项目之后,已经提示需要先cd Newspro,开始创建爬虫程序:
cd Newspro #进入项目文件夹
scrapy genspider wangyi news.163.com/ #创建爬虫程序1即告诉Teminal终端:
我要用scrapy框架,创建(genspider)一个叫"wangyi"的爬虫程序,"news.163.com/"是要爬取的url,可以省略https://
可以看到在Spiders文件夹下,就自动帮我们生成了一个"wangyi.py"的文件,并且文件中自动写好了一个类,以及一些配置参数。
当然如果是老手也可以自己手动创建模块,但是小白的话更推荐用命令创建,不然模块中少写了参数,就会导致一些bug……
另外需要注意:里面的parse方法,parse这个方法名不能改,这是框架自带的回调函数
再创建一个环球新闻网的模块:也自动生成了一个"huanqiu.py"的模块
模块中的域名默认是按照http进行拼的,如果不对,也可以手动改成https
scrapy genspider huanqiu huanqiu.com
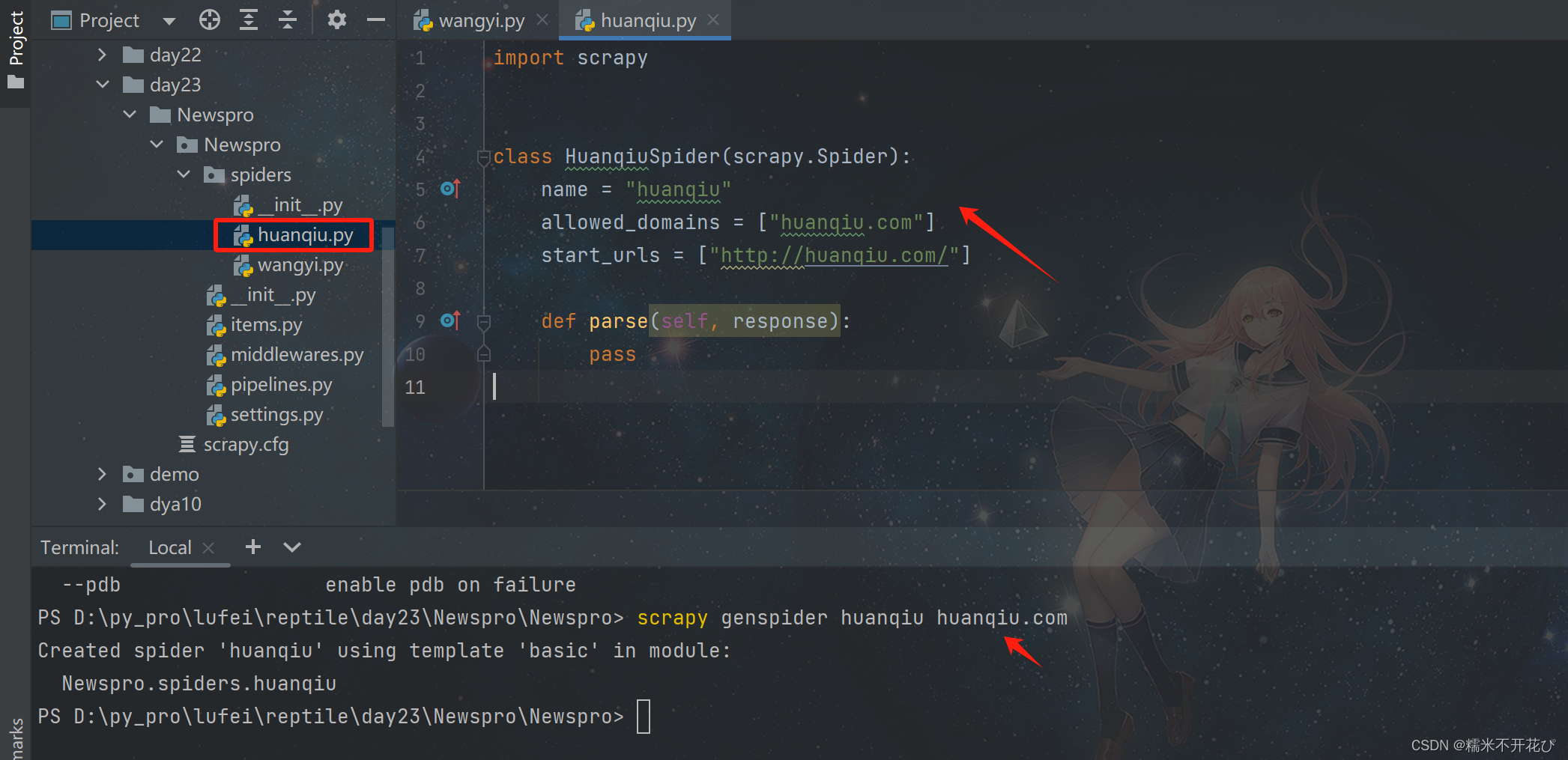
在做爬虫的时候,我们可能不止爬取一个网站,规范是:
将它们全部放在'Spiders'文件夹下,每一个要爬取的网站建立单独一个模块,然后在模块里完善具体的爬虫逻辑和解析逻辑。
完整的创建项目 -> 创建爬虫程序代码如下:
scrapy startproject Newspro #Newspro是项目名称
cd Newspro #进入项目文件夹
scrapy genspider wangyi news.163.com #创建爬虫程序1
scrapy genspider huanqiu huanqiu.com #创建爬虫程序2Spider类详解
Spiders是定义如何抓取某个站点(或一组站点)的类,包括如何执行爬行(即跟随链接)以及如何从其页面中提取结构化数据(即抓取项目)。
换句话说,Spiders是您为特定站点(或者在某些情况下,一组站点)爬网和解析页面定义自定义行为的地方。
=====================================================================
① 生成初始的Requests来爬取第一个URLS,并且标识一个回调函数;
第一个请求定义在start_requests()方法内,默认从start_urls列表中获得url地址来生成Request请求,默认的回调函数是parse方法。回调函数在下载完成返回response时自动触发
parse不能改名,必须叫parse
------->>>
② 在回调函数中,解析response并且返回值
返回值可以4种:
包含解析数据的字典
Item对象
新的Request对象(新的Requests也需要指定一个回调函数)
或者是可迭代对象(包含Items或Request)------->>>
③ 在回调函数中解析页面内容
通常使用Scrapy自带的Selectors,但很明显你也可以使用Beutifulsoup,lxml或其他你爱用啥用啥。------->>>
④ 最后,针对返回的Items对象将会被持久化到数据库
通过Item Pipeline组件存到数据库:https://docs.scrapy.org/en/latest/topics/item-pipeline.html#topics-item-pipeline)
或者导出到不同的文件(通过Feed exports:https://docs.scrapy.org/en/latest/topics/feed-exports.html#topics-feed-exports)
启动爬虫程序
获取网易新闻的html信息,修改添加"wangyi.py"模块中的代码:
import scrapy
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址,可以放多个
#回调函数,解析方法
def parse(self, response):
#windos系统记得写encoding="utf8",不然写入的会是一个空文件
with open("new163..html","w",encoding="utf8") as f:
f.write(response.text)启动爬虫程序方式1:Teminal在终端输入以下代码
ls
scrapy crawl wangyi #crawl启动的意思,后面跟上要启动的模块名
回车之后,会输出很多日志,日志跑完,就会出现一个"new163"的html文件,说明执行成功
html文件可以直接用浏览器打开,就是网页新闻的页面
如果不想看到这一堆日志,可以在启动文件的时候,加上--nolog
一般刚开始调试的时候不建议关闭日志,否则哪里写错了,也看不到报错信息
scrapy crawl wangyi --nolog #启动网易模块,且不显示日志每次都得在终端输入命令还是有点麻烦,所以也有另一种启动方式
启动爬虫程序方式2:通过run来执行启动
scrapy框架没有自带的这个功能,我们可以创建一个py脚本文件
在项目的根目录下进行创建一个py文件,例如我的项目文件名叫"Newspro",就是在它下面创建
运行以下代码,也可以进行启动爬虫程序
from scrapy.cmdline import execute
#['scrapy', 'crawl', '文件名']
execute(['scrapy', 'crawl', 'wangyi'])
#需要关闭日志的话,加上"--nolog"即可
# execute(['scrapy', 'crawl', 'wangyi',"--nolog"])项目使用--scrapy实战案例详解
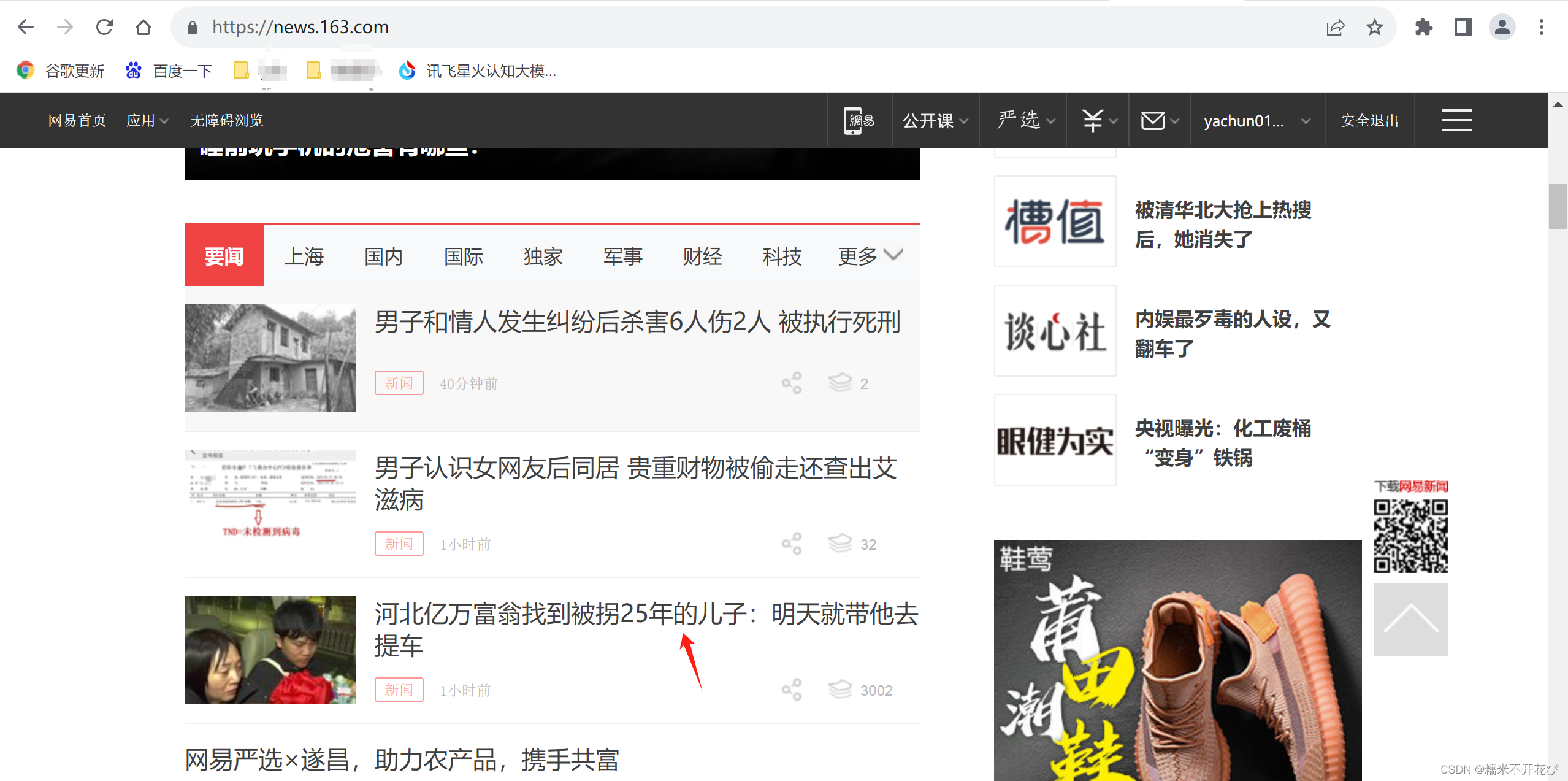
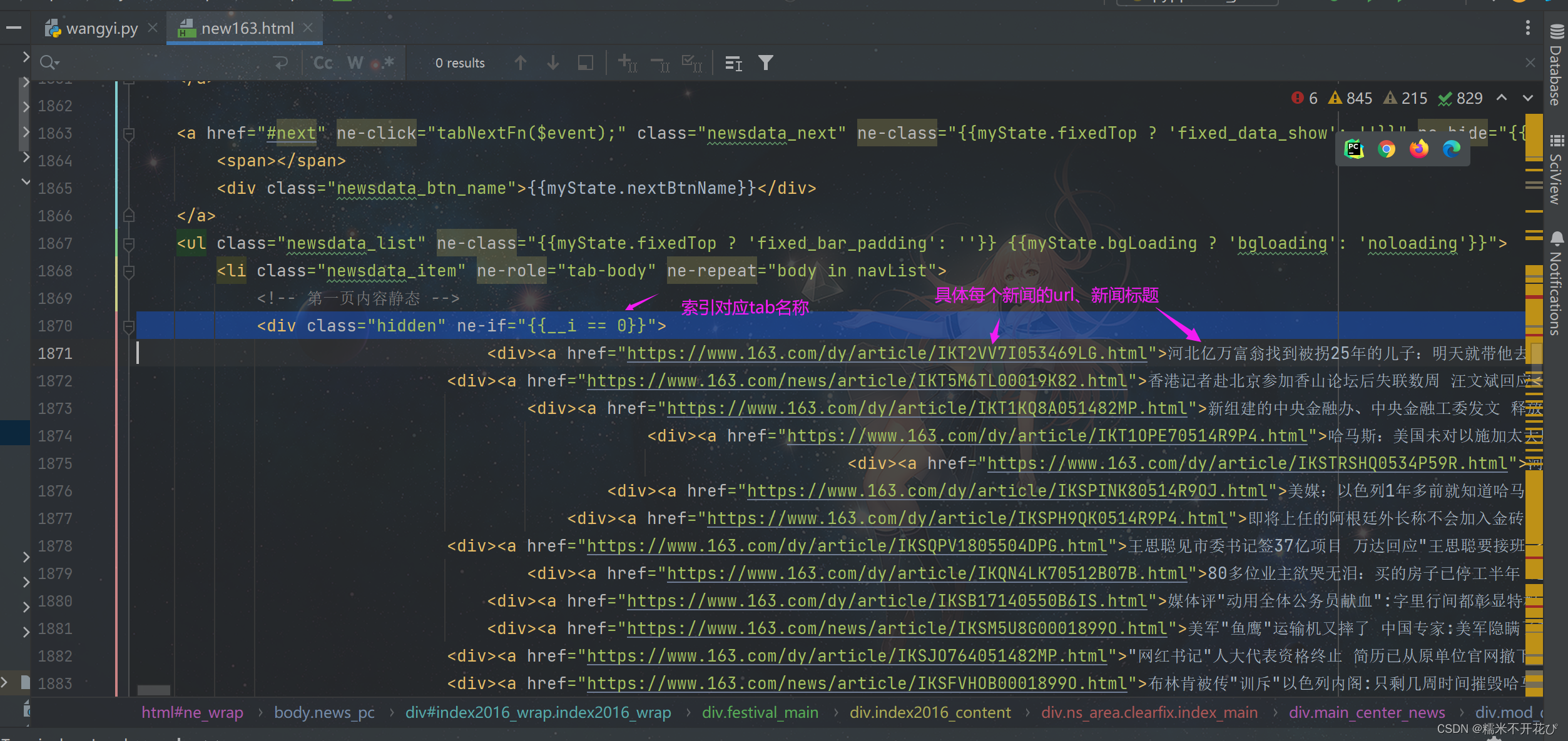
基于前面创建的Newspro项目下的'wangyi.py'模块,批量爬取网易新闻首页板块tab的15个新闻分类里的所有新闻标题,如下截图圈出的板块:
-------------------------------------------------------------------------------------------------------------------------
当鼠标悬浮在tab标题上时,悬浮在不同标题会自动切换显示对应内容,说明此时非当前tab标题下的内容被隐藏了,浏览器并没有真正对服务器发起访问请求,比如说这个15个tab标题分类下,每个分类有100条新闻,那么总共就是1500条新闻,都在第一次的请求响应中。
通过之前爬取下来的html文件对比:
通过对比html文件就可以看出,响应信息只是放在不同位置
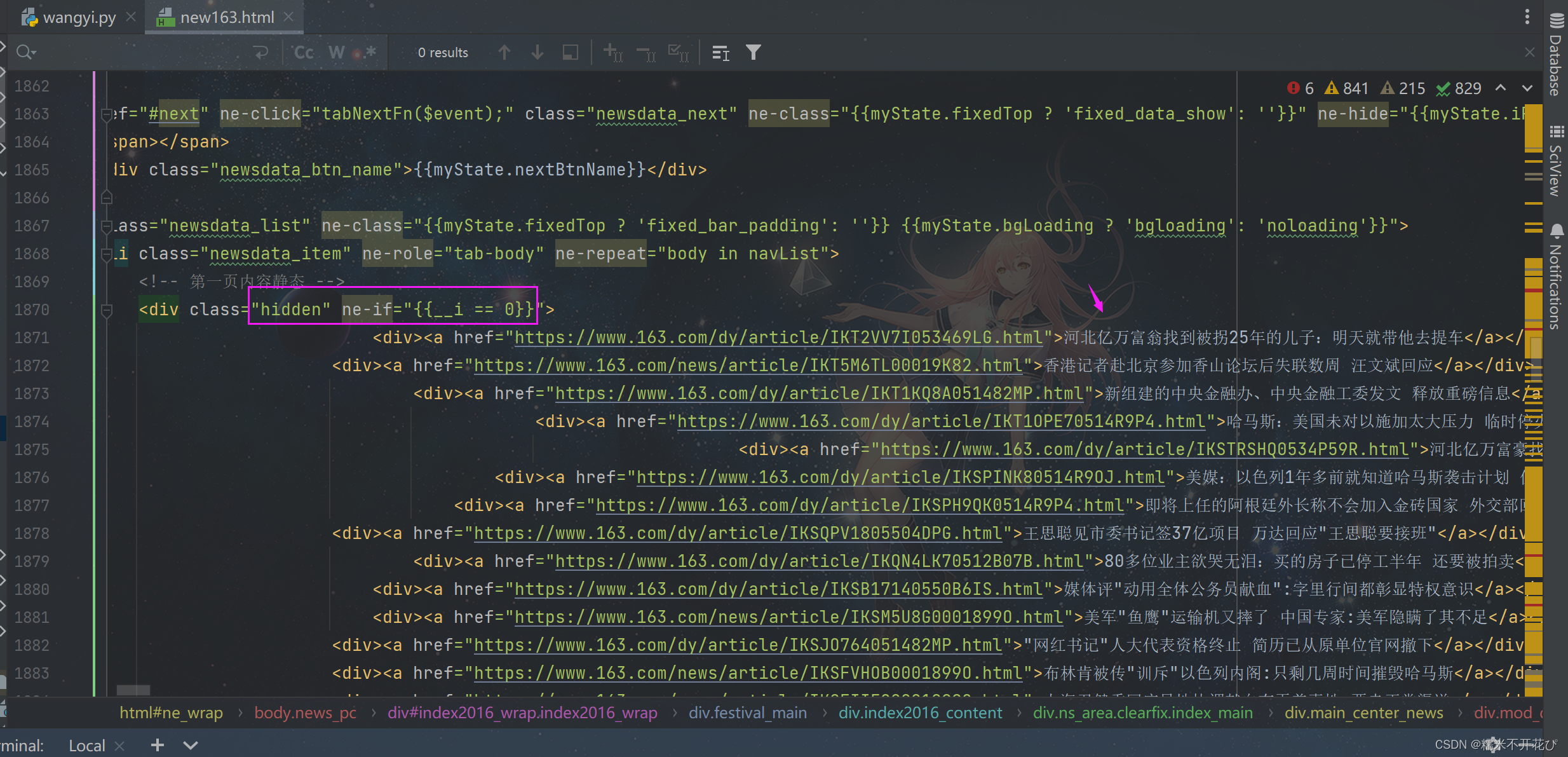
⑴ 批量爬取网易新闻标题
明确完整的爬取需求:
① tab板块中15个分类的所有新闻分类(即tab名称)
② 所有的新闻标题
③ 以及所有的新闻内容
=====================================================================
通过之前爬取下来的首页信息的html文件中可以看出,目前能拿到的是tab名称和新闻标题
新闻内容需要请求具体每个新闻的url,所以分三步来实现:
第一步:先来完成首页最容易获取的信息:解析新闻标题
第二步:解析tab分类名称
第三步:最后爬取具体的所有新闻内容,请求所有新闻的url进行获取
现在正式开始实现第一步:解析新闻标题
解析新闻标题 (错误示范)
先打开浏览器 -> f12进行元素xpath定位,先找到新闻标题对应的素:
//div[@class="news_title"]/h3/a/text()

import scrapy
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址
#回调函数,解析方法
def parse(self, response):
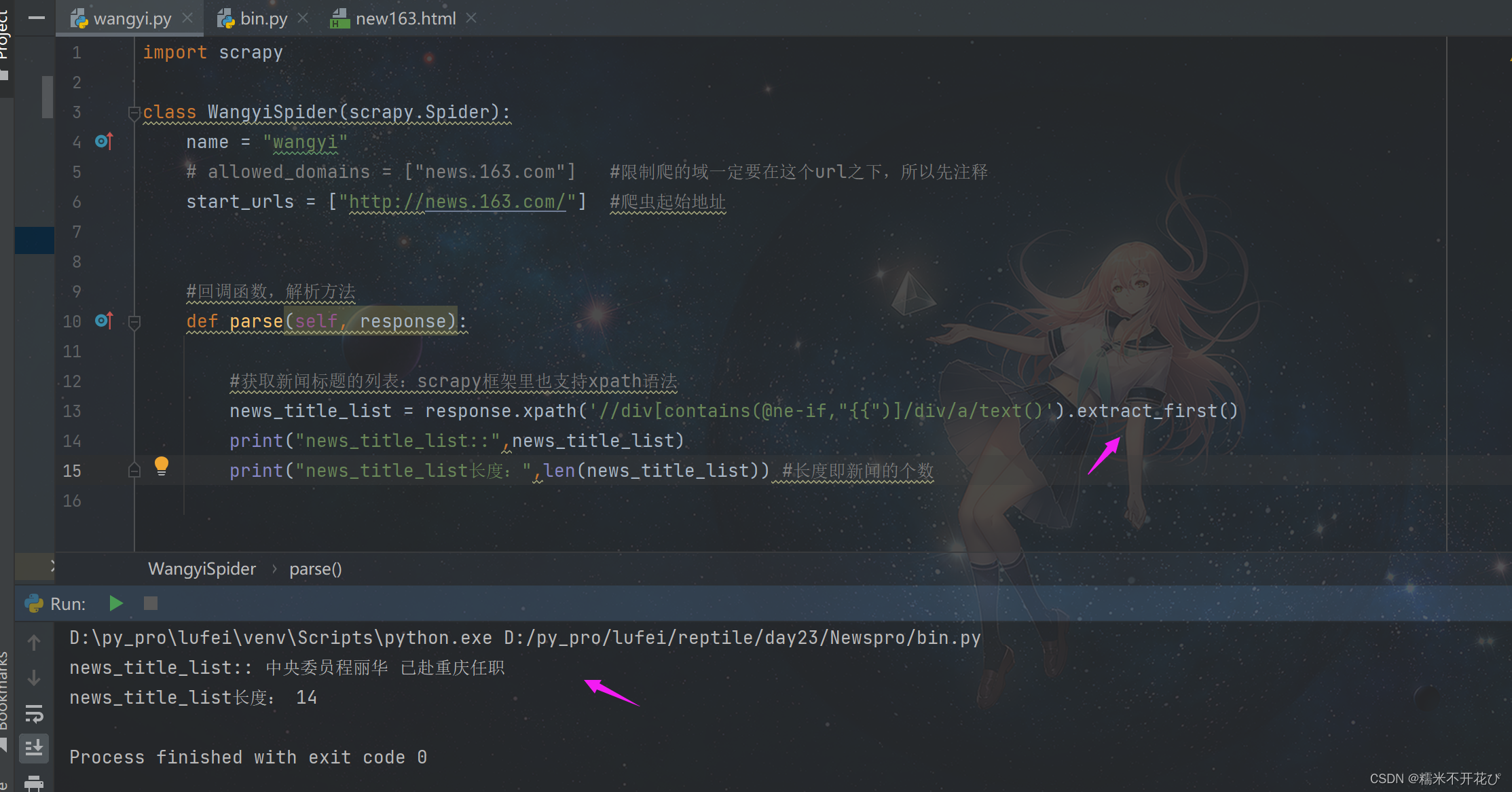
#获取新闻标题的列表:scrapy框架里也支持xpath语法
news_title_list = response.xpath('//div[@class="news_title"]/h3/a')
print("news_title_list::",news_title_list)
print("news_title_list长度:",len(news_title_list)) #长度即新闻的个数然后在bin模块的脚本文件中启动(关闭了日志):
bin文件执行完成之后,发现wangyi.py文件的输出并没有返回预期的信息
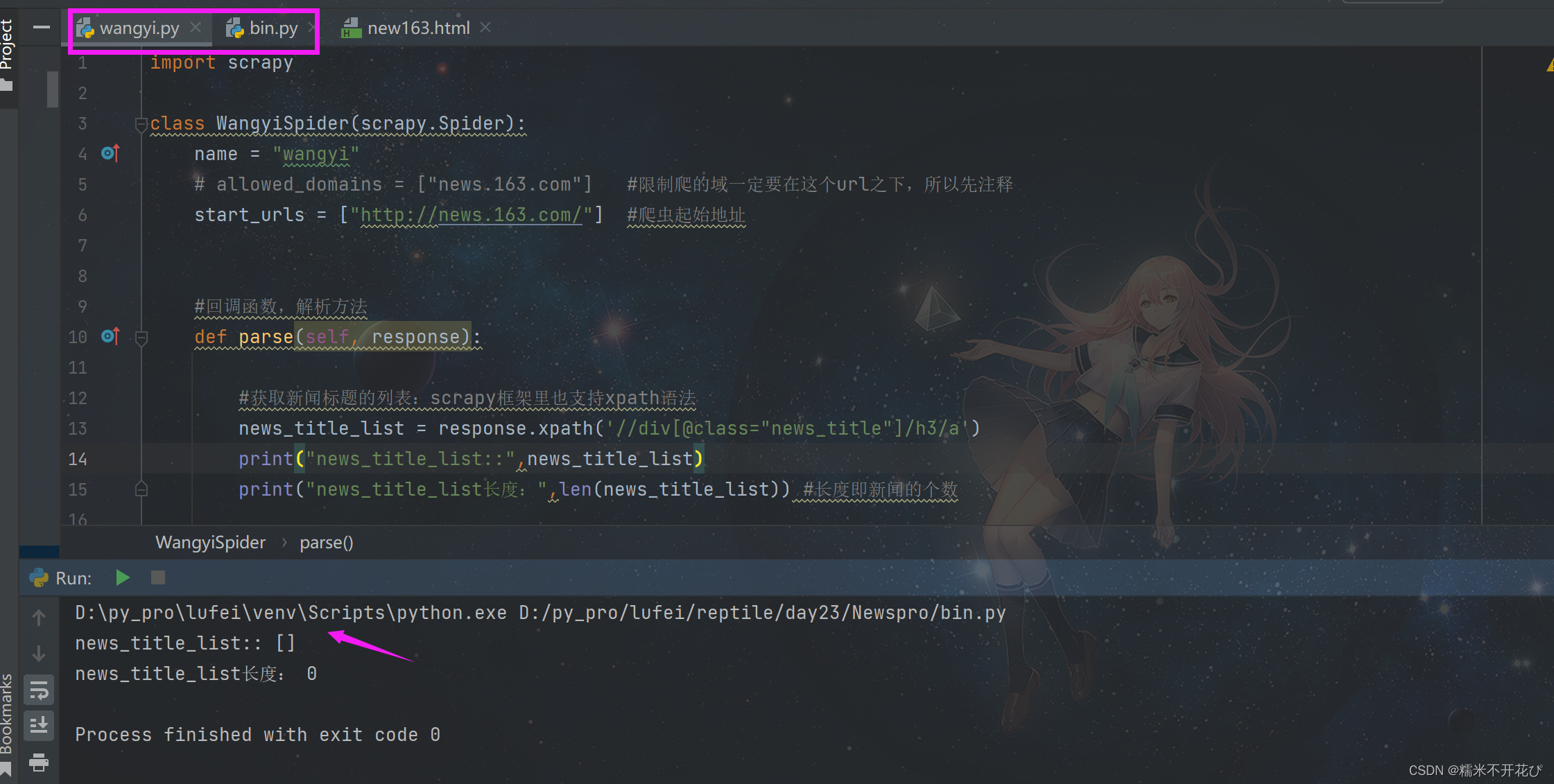
重新开启日志,再run一下:发现有报错

在上面的网页新闻f12元素中是能够找到新闻标题的,说明定义的xapth规则是没问题的
但是为什么解析不出来数据呢?这是一个坑,极大可能性是,在f12中我们看到的数据,是js渲染的,js把数据渲染到对应的标签里了
所以解决办法是:我们要先去看之前爬取下来的html文件,找到对应的hidden隐藏的属性值
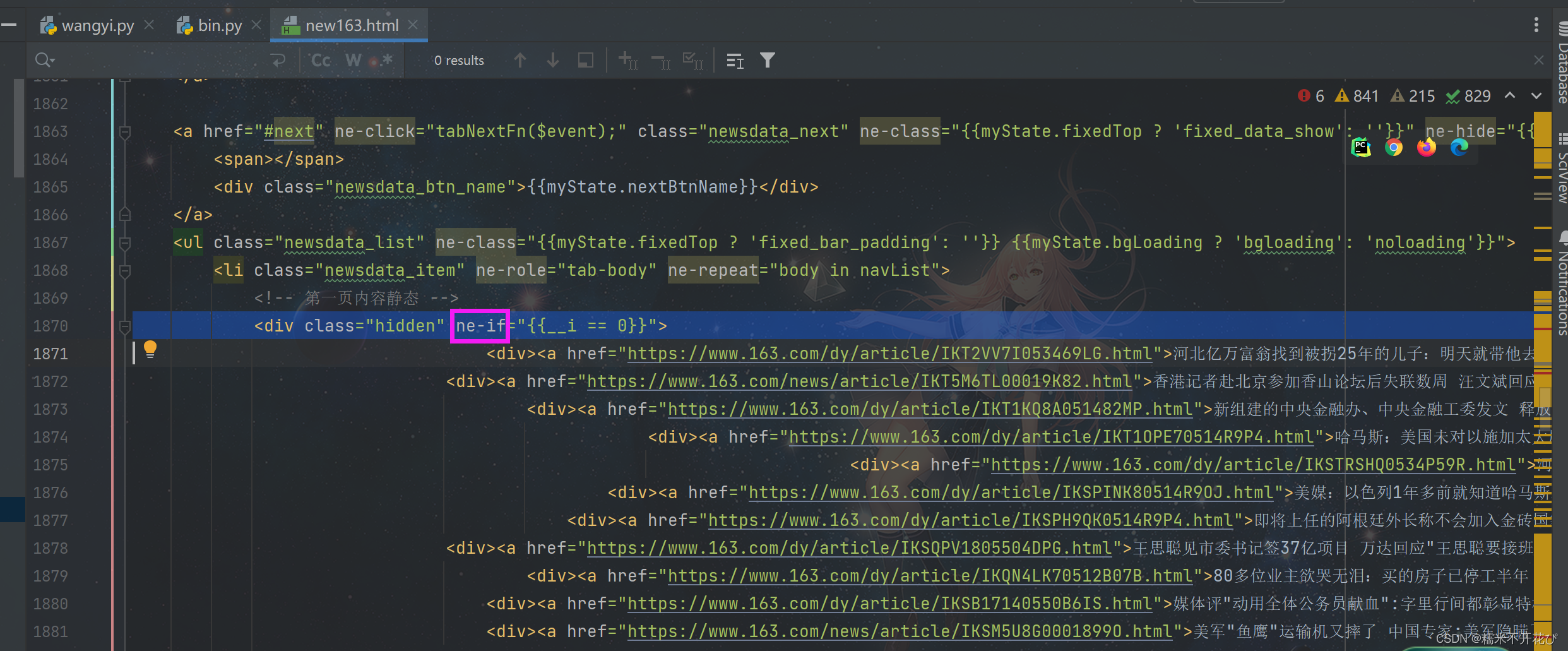
解析新闻标题 (正确示范):重新修改代码
import scrapy
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址
#回调函数,解析方法
def parse(self, response):
#获取新闻标题的列表:scrapy框架里也支持xpath语法
news_title_list = response.xpath('//div[contains(@ne-if,"{{")]/div/a/text()')
print("news_title_list::",news_title_list)
print("news_title_list长度:",len(news_title_list)) #长度即新闻的个数重新run一下bin文件:这次有返回信息,说明解析成功
但是框架自动帮我们用Selector封装了一个data,将新闻标题放在data中
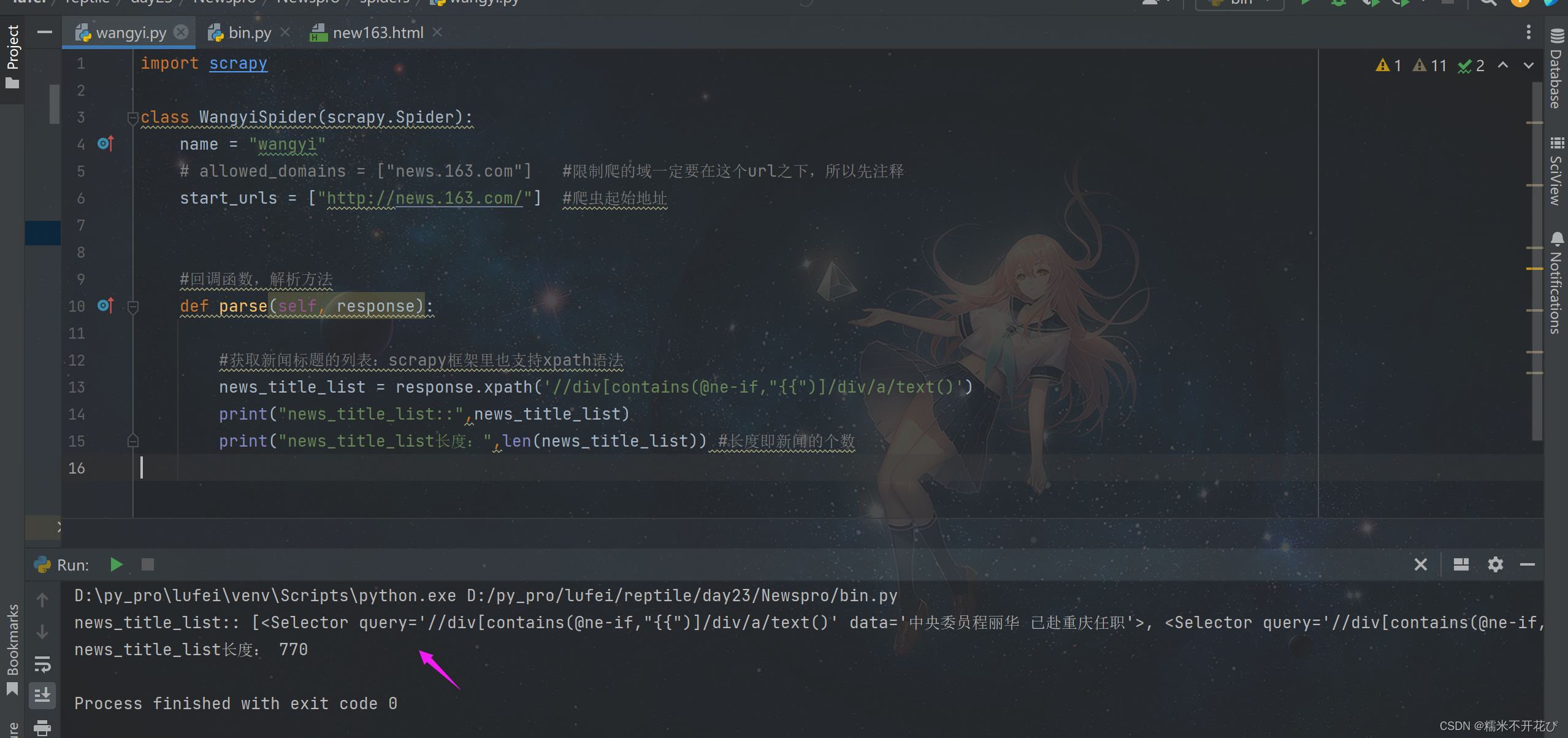
我们只想要新闻标题,所以使用extract()进行提取:直接加在xapth后面就行
import scrapy
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址
#回调函数,解析方法
def parse(self, response):
#获取新闻标题的列表:scrapy框架里也支持xpath语法
news_title_list = response.xpath('//div[contains(@ne-if,"{{")]/div/a/text()').extract()
print("news_title_list::",news_title_list)
print("news_title_list长度:",len(news_title_list)) #长度即新闻的个数
重新run一下bin文件:这样就提取出了text值,即所有的新闻标题

extract()还有一个方法:extract_first(),值提取第一个
总结一下两个提取方法:
extract():提取Selector对象里的所有的data的text属性值extract_first():提取Selector对象里的data的第一个text属性值,即索引为0的text
⑵ 爬取新闻分类+标题+链接
上面爬取新闻标题时,是对这个项目的初探
但是有个问题就是:只能获取到所有的新闻标题,没有新闻tab分类
=====================================================================
所以,我们重新转换一下思路:
❶ 先建立每个tab分类名称的关系映射字典 -> 在回调函数中写解析内容的代码:
这次直接提取网页新闻首页html文件中的分类title,也就是ne-if这个属性值
由于有15个分类板块,这里先取其中6个分类,进行循环15次,只返回在字典表中存在的
import scrapy
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址
#建立一个tab分类名称关系映射字典:
cate_mun_map = {
"{{__i == 0}}" : "要闻" , "{{__i == 1}}": "上海",
"{{__i == 3}}" : "国内" , "{{__i == 2}}": "国际",
"{{__i == 4}}" : "独家" , "{{__i == 5}}": "军事",
# "{{__i == 6}}" : "财经" , "{{__i == 7}}": "科技",
# "{{__i == 8}}" : "体育" , "{{__i == 9}}": "娱乐",
# "{{__i == 10}}": "时尚" , "{{__i == 11}}": "汽车",
# "{{__i == 12}}": "房产" , "{{__i == 13}}": "航空",
# "{{__i == 14}}": "健康"
}
#回调函数,解析方法
def parse(self, response):
#方式1:获取新闻标题的列表,scrapy框架里也支持xpath语法
# news_title_list = response.xpath('//div[contains(@ne-if,"{{")]/div/a/text()').extract_first()
# print("news_title_list::",news_title_list)
# print("news_title_list长度:",len(news_title_list)) #长度即新闻的个数
#方式2:获取标题和类别
cate_mun__list = response.xpath('//*[contains(@ne-if,"{{")]/@ne-if').extract()
print("cate_mun__list:",cate_mun__list)
for cate_mun in cate_mun__list:
#判断cate_mun是否在字典映射表中,只返回有的;循环15次,只拿符合条件的
if cate_mun in self.cate_mun_map:
#需要爬取的板块:
cate_mun = self.cate_mun_map.get(cate_mun)
print(cate_mun)run以下bin文件:取到了6个分类

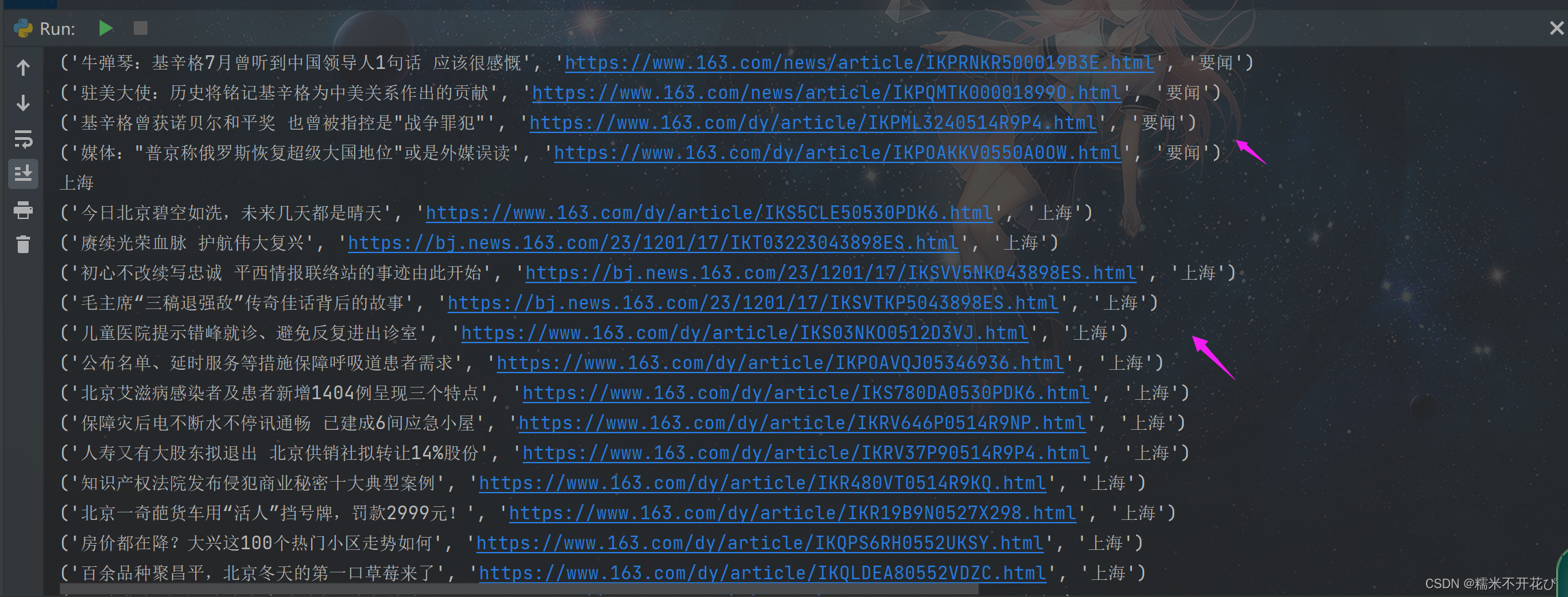
❷ 根据这6个分类,紧接着去循环爬取新闻标题和url:
这样就能将每个分类下的tab名称和新闻标题及url关联上
就相当于在上面代码中进行循环嵌套
import scrapy
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址
#建立一个tab分类名称关系映射字典:
cate_mun_map = {
"{{__i == 0}}" : "要闻" , "{{__i == 1}}": "上海",
"{{__i == 3}}" : "国内" , "{{__i == 2}}": "国际",
"{{__i == 4}}" : "独家" , "{{__i == 5}}": "军事",
# "{{__i == 6}}" : "财经" , "{{__i == 7}}": "科技",
# "{{__i == 8}}" : "体育" , "{{__i == 9}}": "娱乐",
# "{{__i == 10}}": "时尚" , "{{__i == 11}}": "汽车",
# "{{__i == 12}}": "房产" , "{{__i == 13}}": "航空",
# "{{__i == 14}}": "健康"
}
#回调函数,解析方法
def parse(self, response):
#方式1:获取新闻标题的列表,scrapy框架里也支持xpath语法
# news_title_list = response.xpath('//div[contains(@ne-if,"{{")]/div/a/text()').extract_first()
# print("news_title_list::",news_title_list)
# print("news_title_list长度:",len(news_title_list)) #长度即新闻的个数
#方式2:获取标题和类别
cate_mun__list = response.xpath('//*[contains(@ne-if,"{{")]/@ne-if').extract()
print("cate_mun__list:",cate_mun__list)
for cate_mun in cate_mun__list:
#判断cate_mun是否在字典映射表中,只返回有的;循环15次,只拿符合条件的
if cate_mun in self.cate_mun_map:
#需要爬取的板块:
cate_title = self.cate_mun_map.get(cate_mun)
print(cate_title)
#爬取每一个板块的新闻标题:
# response.xpath('//*[contains(@ne-if,"{{__i == 0}},{{__i == 1}}")/div/a')
#不能写死i==0,==1,所以用他对应的cate_mun来做循环:
news_selector_list = response.xpath(f'//*[contains(@ne-if,"{cate_mun}")]/div/a')
for news_selector in news_selector_list:
news_title = news_selector.xpath("text()").extract_first()
news_link = news_selector.xpath("@href").extract_first()
print((news_title,news_link,cate_title))
再run一下bin文件:就得到了每个新闻分类下所有的新闻标题+每个新闻链接
⑶ 批量爬取新闻内容
根据上面取到的新闻分类、新闻标题、新闻链接
接下来还差最后一步:爬取到所有对应分类下的、所有新闻标题里的新闻内容
import scrapy
from scrapy.http import Request
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址
#建立一个tab分类名称关系映射字典:
cate_mun_map = {
"{{__i == 0}}" : "要闻" , "{{__i == 1}}": "上海",
"{{__i == 3}}" : "国内" , "{{__i == 2}}": "国际",
"{{__i == 4}}" : "独家" , "{{__i == 5}}": "军事",
# "{{__i == 6}}" : "财经" , "{{__i == 7}}": "科技",
# "{{__i == 8}}" : "体育" , "{{__i == 9}}": "娱乐",
# "{{__i == 10}}": "时尚" , "{{__i == 11}}": "汽车",
# "{{__i == 12}}": "房产" , "{{__i == 13}}": "航空",
# "{{__i == 14}}": "健康"
}
#回调函数,解析方法
def parse(self, response):
#获取标题和类别
cate_mun__list = response.xpath('//*[contains(@ne-if,"{{")]/@ne-if').extract()
print("cate_mun__list:",cate_mun__list)
for cate_mun in cate_mun__list:
#判断cate_mun是否在字典映射表中,只返回有的;循环15次,只拿符合条件的
if cate_mun in self.cate_mun_map:
#需要爬取的板块:
cate_title = self.cate_mun_map.get(cate_mun)
print(cate_title)
#爬取每一个板块的新闻标题:
# response.xpath('//*[contains(@ne-if,"{{__i == 0}},{{__i == 1}}")/div/a')
#不能写死i==0,==1,所以用他对应的cate_mun来做循环:
news_selector_list = response.xpath(f'//*[contains(@ne-if,"{cate_mun}")]/div/a')
for news_selector in news_selector_list:
news_title = news_selector.xpath("text()").extract_first()
news_link = news_selector.xpath("@href").extract_first()
print((news_title,news_link,cate_title))
'''
#根据源码照猫画虎:只要yield Request请求,就会自动帮我们将请求压缩到Scheduler、Dowloader
参数为url,去重,回调解析函数
这里的url是双层for循环下的6个新闻tab分类对应的700多个url
回调函数需要自定义,用于解析内容;回调函数是下面的parse_news_detail方法
注意:callback self的时候不要加括号
'''
yield Request(url=news_link,dont_filter=True,callback=self.parse_news_detail)
#parse_news_detail方法,相当于是框架自动来完成700多次调用和响应
def parse_news_detail(self, response):
print("response::",response)
#针对返回的response信息解析:
#提取content的text内容
content_list = response.xpath('//*[@id="content"]/div[@class="post_body"]/p/text()').extract()
#拼接内容:
content = "".join(content_list)
print("content:",content)
run以下bin文件:但是content并没有被解析出来
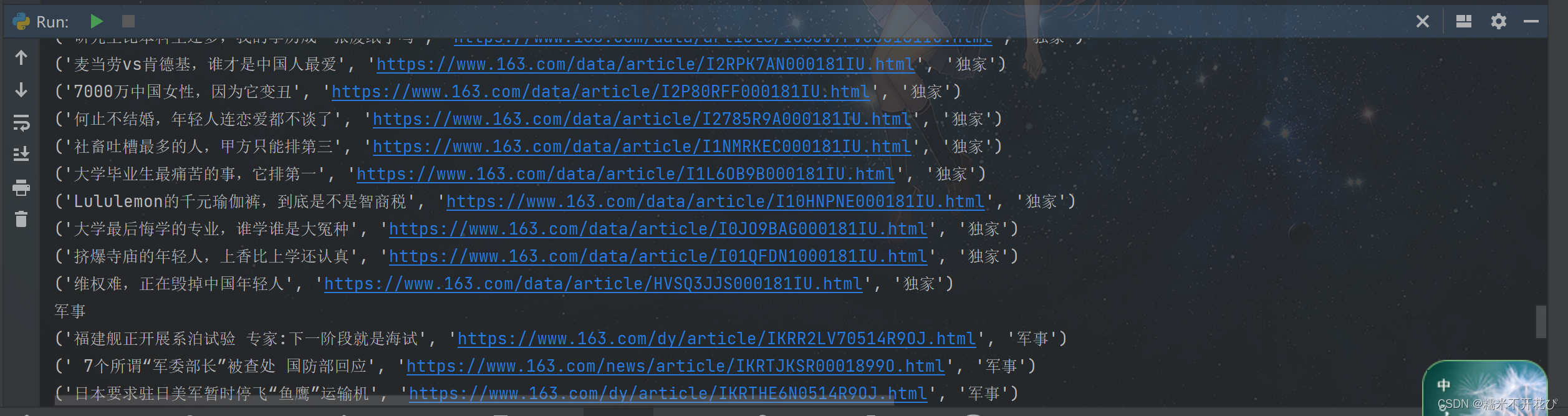
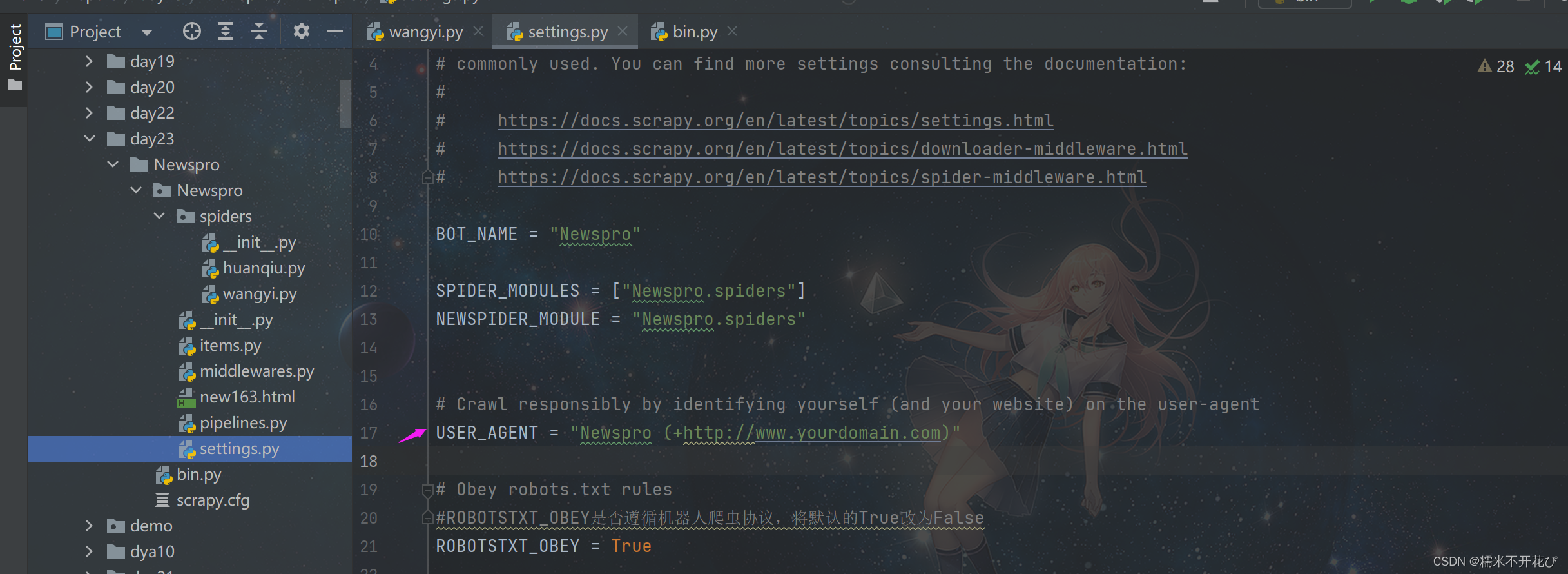
原因是爬的过程,网易需要ua头,使用框架的好处就是,不再需要我们自己添加ua头
只需要在settings.py这个配置文件中,将17行放开,代码执行的过程中,框架就会自动拿到ua帮我放进去;
另外21行,是是否遵循机器人协议,默认为True,必要的时候可以改为False不遵循,但不建议改
然后重新run以下bin文件执行代码,还有两个问题
1、新闻分类的tab名称、和新闻标题及内容是分开的
2、新闻的content为空tab名称、和新闻标题及内容

先来解决第一个问题:tab名称、和新闻标题及内容把放在一起
在yield里面加上一个框架自带的meta字典,它作用是随着yield Request请求的发送,将各自的meta写进各自的response里面,这样就简单高效完成了放在一起的关联
import scrapy
from scrapy.http import Request
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址
#建立一个tab分类名称关系映射字典:
cate_mun_map = {
"{{__i == 0}}" : "要闻" , "{{__i == 1}}": "上海",
"{{__i == 3}}" : "国内" , "{{__i == 2}}": "国际",
"{{__i == 4}}" : "独家" , "{{__i == 5}}": "军事",
# "{{__i == 6}}" : "财经" , "{{__i == 7}}": "科技",
# "{{__i == 8}}" : "体育" , "{{__i == 9}}": "娱乐",
# "{{__i == 10}}": "时尚" , "{{__i == 11}}": "汽车",
# "{{__i == 12}}": "房产" , "{{__i == 13}}": "航空",
# "{{__i == 14}}": "健康"
}
#回调函数,解析方法
def parse(self, response):
#获取标题和类别
cate_mun__list = response.xpath('//*[contains(@ne-if,"{{")]/@ne-if').extract()
for cate_mun in cate_mun__list:
#判断cate_mun是否在字典映射表中,只返回有的;循环15次,只拿符合条件的
if cate_mun in self.cate_mun_map:
#需要爬取的板块:
cate_title = self.cate_mun_map.get(cate_mun)
#爬取每一个板块的新闻标题:
# response.xpath('//*[contains(@ne-if,"{{__i == 0}},{{__i == 1}}")/div/a')
#不能写死i==0,==1,所以用他对应的cate_mun来做循环:
news_selector_list = response.xpath(f'//*[contains(@ne-if,"{cate_mun}")]/div/a')
for news_selector in news_selector_list:
news_title = news_selector.xpath("text()").extract_first()
news_link = news_selector.xpath("@href").extract_first()
'''
#根据源码照猫画虎:只要yield Request请求,就会自动帮我们将请求压缩到Scheduler、Dowloader
参数为url,去重,回调解析函数
这里的url是双层for循环下的6个新闻tab分类对应的700多个url
回调函数需要自定义,用于解析内容;回调函数是下面的parse_news_detail方法
注意:callback self的时候不要加括号
'''
yield Request(url=news_link,dont_filter=True,
callback=self.parse_news_detail,
meta={"news_title":news_title,"cate_title":cate_title})
#parse_news_detail方法,相当于是框架自动来完成700多次调用和响应
def parse_news_detail(self, response):
news_title = response.meta.get("news_title")
cate_title = response.meta.get("cate_title")
#针对返回的response信息解析:
#提取content的text内容
content_list = response.xpath('//*[@id="content"]/div[@class="post_body"]/p/text()').extract()
#拼接内容:
content = "".join(content_list)
print(cate_title,news_title,content)Item及 PipeLine
Item(项目)
抓取的主要目标是从非结构化源(通常是网页)中提取结构化数据。
Scrapy蜘蛛可以像Python一样返回提取的数据。
虽然方便和熟悉,但很容易在字段名称中输入拼写错误或返回不一致的数据,尤其是在具有许多蜘蛛的较大项目中。
为了定义通用输出数据格式,Scrapy提供了Item类。
Item对象是用于收集抓取数据的简单容器。
它们提供类似字典的 API,并具有用于声明其可用字段的方便语法。
====================================================================
简单来说:
上面的实战案例中,我们初步完成了数据的爬取
接下来就是要进行数据清洗、和持久化存储到数据库
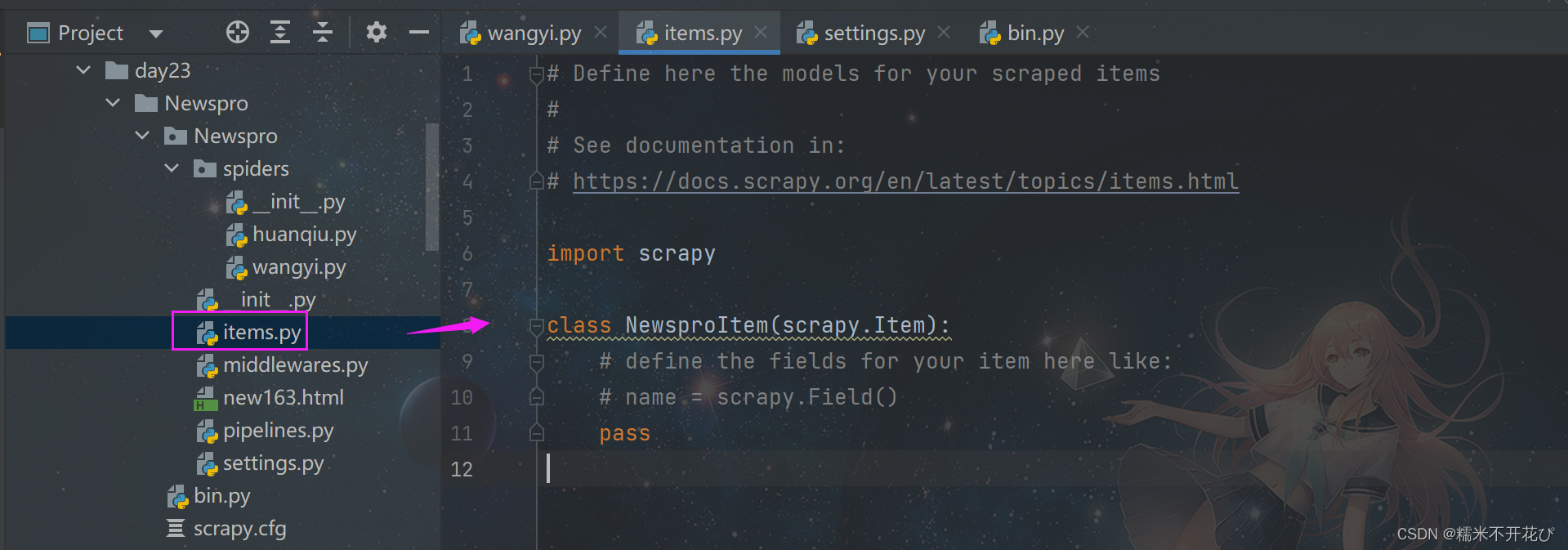
在'Newspro'的项目文件夹下,已经自动生成了一个'Item.py'的文件:
在Scrapy中,数据模型使用Item类来定义。在这个文件中,定义了一个名为NewsproItem的Item类,它继承自scrapy.Item类。
# define the fields for your item here like: # name = scrapy.Field()上面这两句话的意思是:
在这个Item类中,可以定义需要抓取的数据的字段。
每个字段都可以使用scrapy.Field()来定义,以便在抓取过程中存储相应的数据
上面"(3) 批量爬取新闻内容"最后的代码中"print(cate_title,news_title,content)",我们已经构建出来三个数据,由于没有一个统一的类来管理它们,所以输出打印结果看起来就很乱
所以我们在'Item.py'文件中使用scrapy.item来定义字段、管理它们:
import scrapy
class NewsItem(scrapy.Item):
title = scrapy.Field()
cata = scrapy.Field()
content = scrapy.Field()然后去"wangyi.py"文件中:进行封装item
import scrapy
from scrapy.http import Request
from NewsPro.items import NewsItem #记得导入tiem;NewsPro是项目根目录
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址
#建立一个tab分类名称关系映射字典:
cate_mun_map = {
"{{__i == 0}}" : "要闻" , "{{__i == 1}}": "上海",
"{{__i == 3}}" : "国内" , "{{__i == 2}}": "国际",
"{{__i == 4}}" : "独家" , "{{__i == 5}}": "军事",
# "{{__i == 6}}" : "财经" , "{{__i == 7}}": "科技",
# "{{__i == 8}}" : "体育" , "{{__i == 9}}": "娱乐",
# "{{__i == 10}}": "时尚" , "{{__i == 11}}": "汽车",
# "{{__i == 12}}": "房产" , "{{__i == 13}}": "航空",
# "{{__i == 14}}": "健康"
}
#回调函数,解析方法
def parse(self, response):
#获取标题和类别
cate_mun__list = response.xpath('//*[contains(@ne-if,"{{")]/@ne-if').extract()
for cate_mun in cate_mun__list:
#判断cate_mun是否在字典映射表中,只返回有的;循环15次,只拿符合条件的
if cate_mun in self.cate_mun_map:
#需要爬取的板块:
cate_title = self.cate_mun_map.get(cate_mun)
#爬取每一个板块的新闻标题:
# response.xpath('//*[contains(@ne-if,"{{__i == 0}},{{__i == 1}}")/div/a')
#不能写死i==0,==1,所以用他对应的cate_mun来做循环:
news_selector_list = response.xpath(f'//*[contains(@ne-if,"{cate_mun}")]/div/a')
for news_selector in news_selector_list:
news_title = news_selector.xpath("text()").extract_first()
news_link = news_selector.xpath("@href").extract_first()
'''
#根据源码照猫画虎:只要yield Request请求,就会自动帮我们将请求压缩到Scheduler、Dowloader
参数为url,去重,回调解析函数
这里的url是双层for循环下的6个新闻tab分类对应的700多个url
回调函数需要自定义,用于解析内容;回调函数是下面的parse_news_detail方法
注意:callback self的时候不要加括号
'''
yield Request(url=news_link,dont_filter=True,
callback=self.parse_news_detail,
meta={"news_title":news_title,"cate_title":cate_title})
#parse_news_detail方法,相当于是框架自动来完成700多次调用和响应
def parse_news_detail(self, response):
news_title = response.meta.get("news_title")
cate_title = response.meta.get("cate_title")
#针对返回的response信息解析:
#提取content的text内容
content_list = response.xpath('//*[@id="content"]/div[@class="post_body"]/p/text()').extract()
#拼接内容:
content = "".join(content_list)
print(cate_title,news_title,content)
'''
实例化封装item对象:
目的1、统一数据
目的2、方便item调度
'''
newItem = NewsItem()
NewsItem["title"] = news_title
NewsItem["cate"] = cate_title
NewsItem["content"] = content
yield newItem结合最上面的scrapy架构图来说说,为什么要封装item?
只要yield的是item对象,引擎就会把item交给pipelines,做数据清洗和存储(对应架构图的7到8);
如果yield的是Request对象,相当于是压到了Scheduler(第三步),重新请求Engine(第六步),重新响应解析;
----------------->>>>>
代码到这里,由于前面数据都已经准备好了,所以不需要在重新发起请求,直接return item,即构建了700多个新闻对应的item对象;
=====================================================================
所以总的来说:解析就两步
没解析完成,就yield Request
解析完成,拿到数据,就yield item对象
PipeLine
在一个项目被scpay抓取之后,它被发送到项目管道,该项目管道通过顺序执行的几个组件处理它。
每个项目管道组件(有时简称为“项目管道”)是一个实现简单方法的Python类。他们收到一个项目并对其执行操作,同时决定该项目是否应该继续通过管道或被丢弃并且不再处理。
项目管道的典型用途是:
> - cleansing HTML data:清理HTML数据
> - validating scraped data (checking that the items contain certain fields):验证爬取的数据
> - checking for duplicates (and dropping them):检查重复数据
> - storing the scraped item in a database:存储爬取到的数据=====================================================================
每个项管道组件都是一个必须实现以下方法的Python类:
process_item(self,项目,蜘蛛)
为每个项目管道组件调用此方法:process_item()返回带数据的dict、一个Item (或任何后代类)对象,返回Twisted Deferred或引发 DropItem异常。丢弃的项目不再由其他管道组件处理。
-------------------------------------------------------------------------------------------------------------------------
此外,他们还可以实现以下方法:
open_spider(self,蜘蛛):打开蜘蛛时会调用此方法
close_spider(self,蜘蛛):当蜘蛛关闭时调用此方法。
from_crawler(cls,crawler ):如果存在,则调用此类方法以从a创建管道实例Crawler。它必须返回管道的新实例。Crawler对象提供对所有Scrapy核心组件的访问,如设置和信号; 它是管道访问它们并将其功能挂钩到Scrapy的一种方式。
上面提到,只要yield的是item对象,就会由item pipelines来接收
接下来,我们进入到项目创建时自动生成的"pipelines.py"文件中:
直接添加打印item:

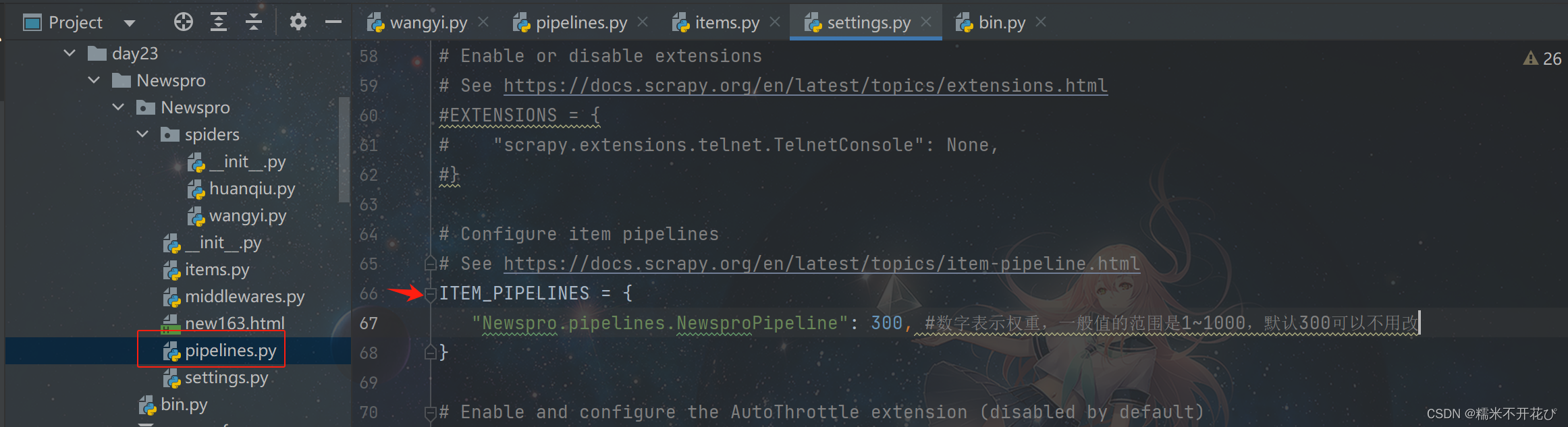
为了确保"pipelines.py"文件中的"process_item"方法会工作,需要去"settings.py"文件:
将66~68行的代码放开(默认是注释掉的),让它开启工作
Pipeline的作用: "Newspro.pipelines.NewsproPipeline"可以构建多个,每个Pipeline都可以有不同的功能比如:
写3个Pipeline,给每个Pipeline加上权重,执行的时候会依次按照从上到下的顺序:
第一个Pipeline是把数据存在文件里,执行完交给第二个Pipeline
第二个Pipeline是把数据存在mysql里,执行完交给第三个Pipeline
第三个Pipeline是把数据存在mongo里
多个Pipeline就是这样以此类推,到这里就是scrapy的最后一步闭环动作
然后在"wangyi.py"文件中,提取content的text内容时加上去空格(第60行):
import scrapy
from scrapy.http import Request
from Newspro.items import NewsItem
class WangyiSpider(scrapy.Spider):
name = "wangyi"
# allowed_domains = ["news.163.com"] #限制爬的域一定要在这个url之下,所以先注释
start_urls = ["http://news.163.com/"] #爬虫起始地址
#建立一个tab分类名称关系映射字典:
cate_mun_map = {
"{{__i == 0}}" : "要闻" , "{{__i == 1}}": "上海",
"{{__i == 3}}" : "国内" , "{{__i == 2}}": "国际",
"{{__i == 4}}" : "独家" , "{{__i == 5}}": "军事",
# "{{__i == 6}}" : "财经" , "{{__i == 7}}": "科技",
# "{{__i == 8}}" : "体育" , "{{__i == 9}}": "娱乐",
# "{{__i == 10}}": "时尚" , "{{__i == 11}}": "汽车",
# "{{__i == 12}}": "房产" , "{{__i == 13}}": "航空",
# "{{__i == 14}}": "健康"
}
#回调函数,解析方法
def parse(self, response):
#获取标题和类别
cate_mun__list = response.xpath('//*[contains(@ne-if,"{{")]/@ne-if').extract()
for cate_mun in cate_mun__list:
#判断cate_mun是否在字典映射表中,只返回有的;循环15次,只拿符合条件的
if cate_mun in self.cate_mun_map:
#需要爬取的板块:
cate_title = self.cate_mun_map.get(cate_mun)
#爬取每一个板块的新闻标题:
# response.xpath('//*[contains(@ne-if,"{{__i == 0}},{{__i == 1}}")/div/a')
#不能写死i==0,==1,所以用他对应的cate_mun来做循环:
news_selector_list = response.xpath(f'//*[contains(@ne-if,"{cate_mun}")]/div/a')
for news_selector in news_selector_list:
news_title = news_selector.xpath("text()").extract_first()
news_link = news_selector.xpath("@href").extract_first()
'''
#根据源码照猫画虎:只要yield Request请求,就会自动帮我们将请求压缩到Scheduler、Dowloader
参数为url,去重,回调解析函数
这里的url是双层for循环下的6个新闻tab分类对应的700多个url
回调函数需要自定义,用于解析内容;回调函数是下面的parse_news_detail方法
注意:callback self的时候不要加括号
'''
yield Request(url=news_link,dont_filter=True,
callback=self.parse_news_detail,
meta={"news_title":news_title,"cate_title":cate_title})
#parse_news_detail方法,相当于是框架自动来完成700多次调用和响应
def parse_news_detail(self, response):
news_title = response.meta.get("news_title")
cate_title = response.meta.get("cate_title")
#针对返回的response信息解析:
#提取content的text内容
content_list = response.xpath('//*[@id="content"]/div[@class="post_body"]/p/text()').extract()
#拼接内容、并去除空格
content = "".join([i.strip() for i in content_list])
print(cate_title,news_title,content)
'''
实例化封装item对象:
目的1、统一数据
目的2、方便item调度
'''
newItem = NewsItem()
newItem["title"] = news_title
newItem["cate"] = cate_title
newItem["content"] = content
yield newItem
重新run一下bin文件:
cate(tab分类标题)、title(新闻标题)、content(新闻内容)已经放在一起了
但是仍有一些content内容没有解析到的,这是前面遗留的第二个问题("⑶ 批量爬取新闻内容"这里),是由于"news_selector_list"这里xapth定义的解析规则不能适用所有的新闻分类导致的
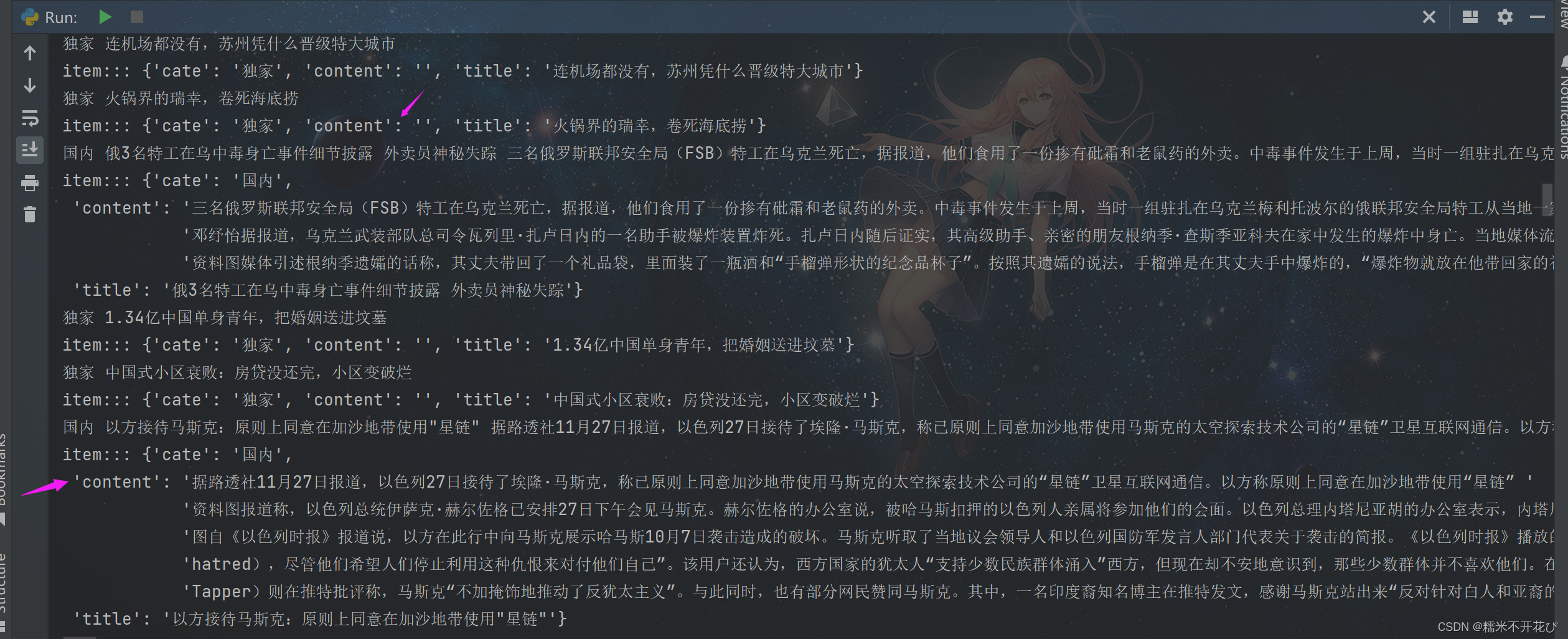
所以这里我再做下处理,先把content为空的过滤掉(在"process_item"文件里处理)
可以导入from scrapy.extensions import DropItem这个类,用来丢弃item
from scrapy.extensions import DropItem #丢弃item
class NewsproPipeline:
def process_item(self, item, spider):
#加个判断条件,content为空的不返回
if not item["content"]:
DropItem("content不能为空,丢弃!")
else:
print("item:::", item)
return item #一定要记得加return进行传递再重新run一下bin文件:在控制台搜索一下为空的content,显示0个,说明已经过滤成功了
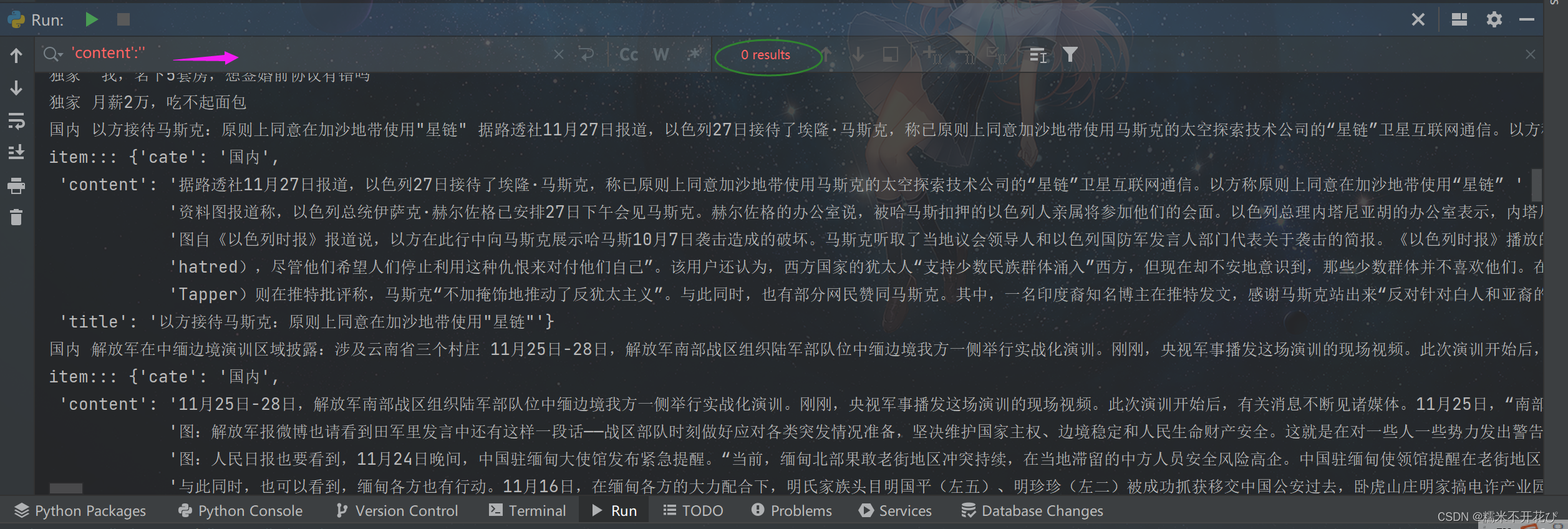
到这里,就已经使用scrapy框架完成了整个爬虫过程:请求url -> 解析数据 -> 清洗数据
下一章接着一起来学习scrapy框架的进一步学习哦~