linux 应用开发笔记---【标准I/O库/文件属性及目录】
一,什么是标准I/O库
标准c库当中用于文件I/O操作相关的一套库函数,实用标准I/O需要包含头文件
二,文件I/O和标准I/O之间的区别
1.标准I/O是库函数,而文件I/O是系统调用
2.标准I/O是对文件I/O的封装
3.标准I/O相对于文件I/O具有更好的可移植性,且效率高
三,FILE文件指针
FILE是一个数据结构体,标准I/O实用FILE指针作为文件句柄
FILE文件指针用于标准I/O库函数,而文件描述符则用于文件I/O系统调用,FILE数据结构定义在标准 I/O 库函数头文件 stdio.h 中
四,标准输入,标准输出和标准错误
标准输入设备:计算机系统的标准的输入设备
标准输出设备:计算机所连接的键盘
输出标准设备:计算机所连接的显示器
五,标准I/O函数
1)打开文件:fopen()
FILE *fopen(const char *path, const char *mode);path : 参数 path 指向文件路径,可以是绝对路径、也可以是相对路径。mode : 参数 mode 指定了对该文件的读写权限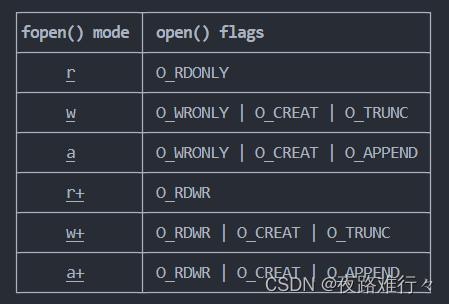
2)关闭文件:fclose()
int fclose(FILE *stream);stream 为 FILE 类型指针,也就是文件句柄,调用成功返回 0 ;失败将返回 EOF (也就是 -1 )
3)读取/写入文件:fread()/fwrite()
fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
ptr:fread()将读取到的数据存放在参数 ptr 指向的缓冲区中
size : fread() 从文件读取 nmemb 个数据项,每一个数据项的大小为 size 个字节,所以总共读取的数据大小为 nmemb * size 个字节。nmemb : 参数 nmemb 指定了读取数据项的个数。stream : FILE 指针返回项:读取或者写入的数据项的数目
写入:
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char buf[] = "hello world!";
FILE *fp = NULL;
if(NULL == (fp = fopen("./test.txt","w+")))
{
perror("open error");
return 1;
}
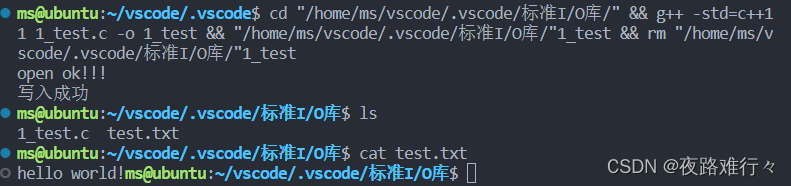
printf("open ok!!!\r\n");
if(sizeof(buf)>(fwrite(buf,1, sizeof(buf), fp)))
{
printf("fwrite error");
fclose(fp);
exit(-1);
}
printf("写入成功\r\n");
fclose(fp);
return 0;
}运行结果:
读取:
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char buf[20] = "0";
FILE *fp = NULL;
int size;
if(NULL == (fp = fopen("./test.txt","r")))
{
perror("open error");
return 1;
}
printf("open ok!!!\r\n");
if(12>(size = fread(buf,1, 11, fp)))
{
if(ferror(fp))
{
printf("fread error");
fclose(fp);
exit(-1);
}
}
printf("成功读取%d 个字节数据: %s\n", size, buf);
fclose(fp);
return 0;
}运行结果:

4)定位函数:fseek()
int fseek(FILE *stream, long offset, int whence);stream : FILE 指针。offset : 与 lseek() 函数的 offset 参数意义相同。whence : 与 lseek() 函数的 whence 参数意义相同
5)判断是否到达文件末尾--feof()函数
int feof(FILE *stream);6)判断是否发生了错误--ferror()函数
int ferror(FILE *stream);7)清楚标志--clearerr()函数【自己独立设置标志】
void clearerr(FILE *stream);8)格式化输入
int printf(const char *format, ...);
将程序中的字符串信息输出显示到终端
int fprintf(FILE *stream, const char *format, ...);
将格式化数据写入到由 FILE 指针指定的文件
int dprintf(int fd, const char *format, ...);
将格式化数据写入到由文件描述符 fd 指定的文件
int sprintf(char *buf, const char *format, ...);
将格式化数据存储在由参数 buf 所指定的缓冲区中
int snprintf(char *buf, size_t size, const char *format, ...);
使用参数 size 显式的指定缓冲区的大小,如果写入到缓冲区的字节数大于参数 size 指定的大
小,超出的部分将会被丢弃!如果缓冲区空间足够大,snprintf()函数就会返回写入到缓冲区的字符数,与
sprintf()函数相同,也会在字符串末尾自动添加终止字符'\0'9)格式化输出
int scanf(const char *format, ...);
scanf()函数将用户输入(标准输入)的数据进行格式化转换并进行存储
int fscanf(FILE *stream, const char *format, ...);
从指定文件中读取数据,作为格式转换的输入数据,文件通过 FILE 指针指定
int sscanf(const char *str, const char *format, ...);
从参数 str 所指向的字符串缓冲区中读取数据,作为格式转换的输入数据六,文件I/O缓冲
1.内核缓冲
read()和write()系统调用是在进行文件读写操作的时候并不会直接访问磁盘设备,而是仅仅在用户空间缓冲区和内核缓冲区之间复制数据。调用write()函数后,会将数据保存到缓存数据区,然后等待内核在某个时刻将缓冲区的数据写入到磁盘设备中,但此时如果read()函数,会直接将数据缓存器的数据返回给应用程序。反之,同理
2.刷新文件I/O的内核缓冲区
对于一些操作,必须强制将文件I/O内核缓冲区中缓存的数据写入到磁盘设备。
fsync()函数:
int fsync(int fd);系统调用 fsync() 将参数 fd 所指文件的内容数据和元数据写入磁盘,只有在对磁盘设备的写入操作完成之后,fsync()函数才会返回,函数调用成功将返回 0 ,失败返回 -1
fdatasync()函数:
int fdatasync(int fd);系统调用 fdatasync() 与 fsync() 类似,不同之处在于 fdatasync() 仅将参数 fd 所指文件的内容数据写入磁盘,并不包括文件的元数据
sync()函数:
void sync(void);系统调用 sync() 会将所有文件 I/O 内核缓冲区中的文件内容数据和元数据全部更新到磁盘设备中,该函数没有参数、也无返回值
3.控制文件I/O内核缓冲的标志
1.O_DSYNC 标志:write()调用之后调用 fdatasync()函数【元数据不同步】进行数据同步
2.O_SYNC 标志:write()调用都会自动将文件内容数据和元数据刷新到磁盘设备中
4.直接I/O:绕过内核缓冲
在open函数调用添加O_DIRECT就可以进行调用
直接 I/O 的对齐限制 :
⚫ 应用程序中用于存放数据的缓冲区,其内存起始地址必须以块大小的整数倍进行对齐;⚫ 写文件时,文件的位置偏移量必须是块大小的整数倍;⚫ 写入到文件的数据大小必须是块大小的整数倍。
5.stdio缓冲
用户空间 的缓冲区,当应用程序中通过标准 I/O 操作磁盘文件时,为了减少调用系统调用次数,标准 I/O 函数会将用户写入或读取文件的数据缓存在 stdio 缓冲区,然后再一次性 stdio 缓冲区中缓存的数据通过调用系统调用 I/O (文件 I/O )写入到文件 I/O 内核缓冲区或者拷贝到应用程序的 buf 中
三种缓冲类型:
⚫ _IONBF :不对 I/O 进行缓冲(无缓冲)。意味着每个标准 I/O 函数将立即调用 write() 或者 read() ,并且忽略 buf 和 size 参数,可以分别指定两个参数为 NULL 和 0 。标准错误 stderr 默认属于这一种类型,从而保证错误信息能够立即输出⚫ _IOLBF :采用行缓冲 I/O 。在这种情况下,当在输入或输出中遇到换行符 "\n" 时,标准 I/O 才会执行文件 I/O 操作。对于输出流,在输出一个换行符前将数据缓存(除非缓冲区已经被填满),当输 出换行符时,再将这一行数据通过文件 I/O write() 函数刷入到内核缓冲区中;对于输入流,每次读取一行数据。对于终端设备默认采用的就是行缓冲模式,譬如标准输入和标准输出。⚫ _IOFBF :
采用全缓冲 I/O 。在这种情况下,在填满 stdio 缓冲区后才进行文件 I/O 操作( read 、 write ),对于输出流,当 fwrite 写入文件的数据填满缓冲区时,才调用 write() 将 stdio 缓冲区中的数据刷入内核缓冲区;对于输入流,每次读取 stdio 缓冲区大小个字节数据。默认普通磁盘上的常规文件默认常用这种缓冲模式
刷新stdio缓冲区
int fflush(FILE *stream);
强制进行文件的刷新,如果参数是NULL,则刷新所有的stdio缓冲区
⚫ 调用 fflush()库函数可强制刷新指定文件的 stdio 缓冲区;
⚫ 调用 fclose()关闭文件时会自动刷新文件的 stdio 缓冲区;
⚫ 程序退出时会自动刷新 stdio 缓冲区(注意区分不同的情况)I/O缓冲小结:
应用程序调用标准 I/O 库函数将用户数据写入到 stdio 缓冲区中, stdio 缓冲区是由 stdio 库所维护的用户空间缓冲区。针对不同的缓冲模式,当满足条件时, stdio 库会调用文件 I/O (系统调用 I/O )将 stdio 缓冲区中缓存的数据写入到内核缓冲区中,内核缓冲区位于内核空间。最终由内核向磁盘设备发起读写操作,将内核缓冲区中的数据写入到磁盘(或者从磁盘设备读取数据到内核缓冲区)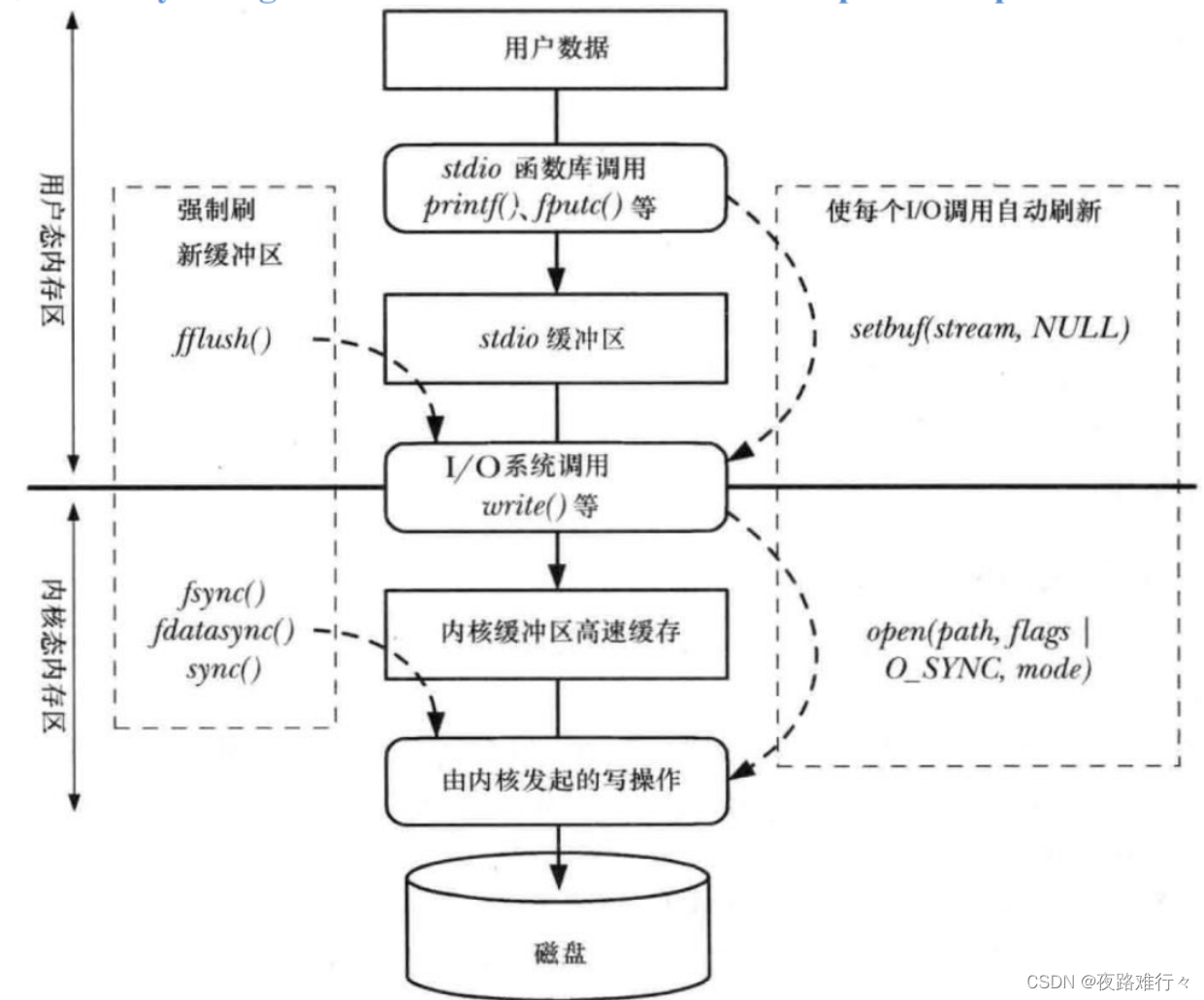
七,文件描述符和FILE指针互转
int fileno(FILE *stream);
将标准 I/O 中使用的 FILE 指针转换为文件 I/O 中所使用的文件描述符
成功:文件描述符 失败:NULL
FILE *fdopen(int fd, const char *mode);
将文件描述符转换为FILE指针
成功:文件指针 失败:NULL八,linux系统的文件类型
文本文件 :内容由文本构成
二进制文件:.o, .bin文件......
符号链接文件:指向另一个文件的路径
管道文件:进程间通信
套接字文件:不同主机的进程间通信
获取文件的属性:stat
int stat(const char *pathname, struct stat *buf);st_dev :该字段用于描述此文件所在的设备。不常用,可以不用理会。st_ino :文件的 inode 编号。st_mode:该字段用于描述文件的模式,譬如文件类型、文件权限都记录在该变量中st_nlink :该字段用于记录文件的硬链接数,也就是为该文件创建了多少个硬链接文件。链接文件可以分为软链接(符号链接)文件和硬链接文件st_uid 、 st_gid :此两个字段分别用于描述文件所有者的用户 ID 以及文件所有者的组 IDst_rdev :该字段记录了设备号,设备号只针对于设备文件,包括字符设备文件和块设备文件,不用理会。st_size :该字段记录了文件的大小(逻辑大小),以字节为单位。st_atim 、 st_mtim 、 st_ctim :此三个字段分别用于记录文件最后被访问的时间、文件内容最后被修改的时间以及文件状态最后被改变的时间,都是 struct timespec 类型变量
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
struct stat file_stat;
int ret;
ret = stat("./test.txt",&file_stat);
if(-1 == ret)
{
perror("open error");
exit(-1);
}
printf("%ld %ld\r\n",file_stat.st_size,file_stat.st_ino);
exit(0);
}运行结果: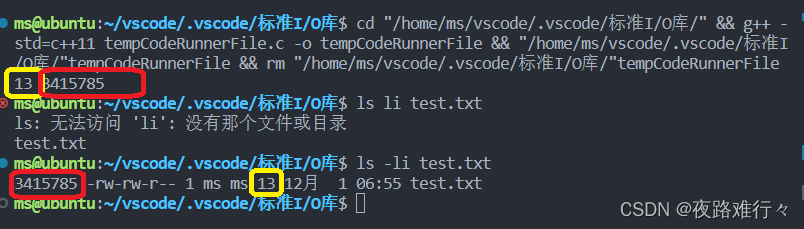
fstat:相对于stat的区别就是,fstat是从fd去获取文件的属性,而stat是从文件路径获取的
lstat()与 stat、fstat 的区别在于,对于符号链接文件,stat、fstat 查阅的是符号链接文件所指向的文件对应的文件属性信息
九,文件属主

1.有效用户ID和有效组ID
通常,绝大部分情况下,进程的有效用户等于实际用户(有效用户 ID 等于实际用户 ID),有效组等于实际组(有效组 ID 等于实际组 ID)
2.chown函数:改变文件的所属者和所属组
sudo chown root:root testApp.cint chown(const char *pathname, uid_t owner, gid_t group);
pathname:用于指定一个需要修改所有者和所属组的文件路径
owner:将文件的所有者修改为该参数指定的用户(以用户 ID 的形式描述);
group:将文件的所属组修改为该参数指定的用户组(以用户组 ID 的形式描述);
返回值:成功返回 0;失败将返回-1,兵并且会设置 errno⚫ 只有超级用户进程能更改文件的用户 ID ;⚫ 普通用户进程可以将文件的组 ID 修改为其所从属的任意附属组 ID ,前提条件是该进程的有效用户 ID 等于文件的用户 ID ;而超级用户进程可以将文件的组 ID 修改为任意值
3.普通权限和特殊权限
普通权限:

进程对文件进行操作的时候、将进行权限检查,如果文件的 set-user-ID 位权限被设置,内核会将 进程的有效 ID 设置为该文件的用户 ID (文件所有者 ID ),意味着该进程直接获取了文件所有者 的权限、以文件所有者的身份操作该文件
进程对文件进行操作的时候、将进行权限检查,如果文件的 set-group-ID 位权限被设置,内核会 将进程的有效用户组 ID 设置为该文件的用户组 ID(文件所属组 ID),意味着该进程直接获取了文件所属组成员的权限、以文件所属组成员的身份操作该文件
3.sticky权限
注:
4.检查文件的权限
int access(const char *pathname, int mode);
pathname:文件路径
mode:
⚫ F_OK:检查文件是否存在
⚫ R_OK:检查是否拥有读权限
⚫ W_OK:检查是否拥有写权限
⚫ X_OK:检查是否拥有执行权限
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int ret;
ret = access("./test.txt",F_OK);
if(-1 == ret)
{
printf("文件不存在/r/n");
exit(-1);
}
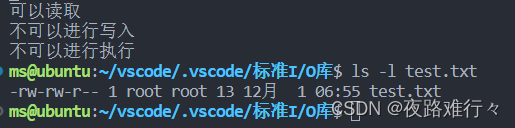
ret = access("./test.txt",R_OK);
if(!ret)
{
printf("可以读取\r\n");
}
else
{
printf("不可以进行读取\r\n");
}
ret = access("./test.txt",W_OK);
if(!ret)
{
printf("可以写入\r\n");
}
else
{
printf("不可以进行写入\r\n");
}
ret = access("./test.txt",X_OK);
if(!ret)
{
printf("不可以进行执行\r\n");
}
else
{
printf("不可以进行执行\r\n");
}
return 0;
}运行结果:
5.chmod修改文件的权限
int chmod(const char *pathname, mode_t mode);
pathname:
需要进行权限修改的文件路径,若该参数所指为符号链接,实际改变权限的文件是符号链
接所指向的文件,而不是符号链接文件本身。
mode:
该参数用于描述文件权限,与 open 函数的第三个参数一样,这里不再重述,可以直接使用八进
制数据来描述,也可以使用相应的权限宏(单个或通过位或运算符" | "组合)fchmod():根据fd进行文件权限的修改
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
int main(void)
{
int ret;
ret = chmod("./test.txt", 0777);
if(-1 == ret)
{
perror("修改失败");
exit(-1);
}
return 0;
}
6.umask函数
文件的实际权限实际上不等于我们设置的权限
mode & ~umask eg. 0777 & (~0002) = 0775
mode_t umask(mode_t mask);
返回值是旧的mask 参数是 新设定的mask 十,文件的时间属性

修改时间属性: utime(),utimes()
int utime(const char *filename, const struct utimbuf *times);
filename: 文件路径
struct utimbuf {
time_t actime; /* 访问时间 */
time_t modtime; /* 内容修改时间 */
};
int utimes(const char *filename, const struct timeval times[2]);
filename: 文件路径
struct timeval {
long tv_sec; /* 秒 */
long tv_usec; /* 微秒 */
};
相比之下:utimes的精度更高一些,可以更改到微秒级别
int futimens(int fd, const struct timespec times[2]);
fd:文件描述符。
times:将时间属性修改为该参数所指定的时间值,times 指向拥有 2 个 struct timespec 结构体类型变量
的数组,数组共有两个元素,第一个元素用于指定访问时间,第二个元素用于指定内容修改时间
#include <fcntl.h> #include <sys/stat.h> #include <unistd.h> #include <sys/types.h> #include <time.h> #include <stdio.h> #include <stdlib.h> #define MY_FILE "./test.txt" int main(void) { struct timespec tmsp_arr[2]; int ret; int fd; /* 检查文件是否存在 */ ret = access(MY_FILE, F_OK); if (-1 == ret) { printf("Error: %s file does not exist!\n", MY_FILE); exit(-1); } /* 打开文件 */ fd = open(MY_FILE, O_RDONLY); if (-1 == fd) { perror("open error"); exit(-1); } /* 修改文件时间戳 */ #if 0 ret = futimens(fd, NULL); //同时设置为当前时间 #endif #if 1 tmsp_arr[0].tv_nsec = UTIME_OMIT;//访问时间保持不变 tmsp_arr[1].tv_nsec = UTIME_NOW;//内容修改时间设置为当期时间 ret = futimens(fd, tmsp_arr); #endif }

utimensat()函数:
int utimensat(int dirfd, const char *pathname, const struct timespec times[2], int flags);
dirfd:
该参数可以是一个目录的文件描述符,也可以是特殊值 AT_FDCWD;如果 pathname 参数指定
的是文件的绝对路径,则此参数会被忽略。
pathname:
指定文件路径。如果 pathname 参数指定的是一个相对路径、并且 dirfd 参数不等于特殊值
AT_FDCWD,则实际操作的文件路径是相对于文件描述符 dirfd 指向的目录进行解析。如果 pathname 参数
指定的是一个相对路径、并且 dirfd 参数等于特殊值 AT_FDCWD,则实际操作的文件路径是相对于调用进
程的当前工作目录进行解析
times:
与 futimens()的 times 参数含义相同
flags :
此参数可以为 0 , 也可以设置为 AT_SYMLINK_NOFOLLOW , 如 果 设 置 为
AT_SYMLINK_NOFOLLOW,当 pathname 参数指定的文件是符号链接,则修改的是该符号链接的时间戳,
而不是它所指向的文件十一,符号链接()软链接和硬链接
硬链接:
ls-li 查看当前的硬链接文件个数,源文件本身也是一个硬链接文件

各个硬链接文件的inode指向的是同一个文件
ln 源文件名称 新创建文件名称 创建硬链接文件
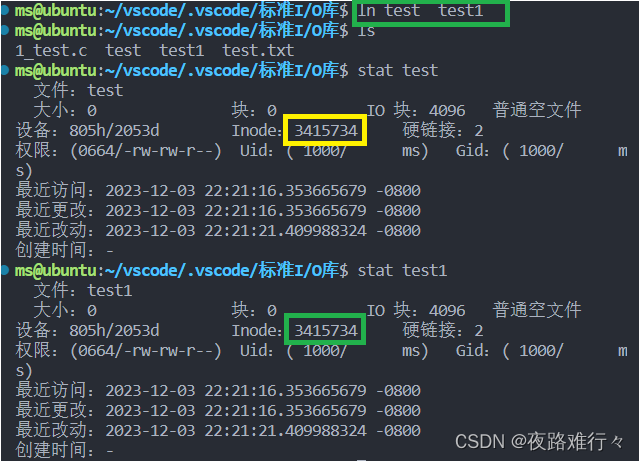
创建硬链接:
int link(const char *oldpath, const char *newpath);软链接:
ln -s 源文件名称 新创建文件名称 创建硬链接文件
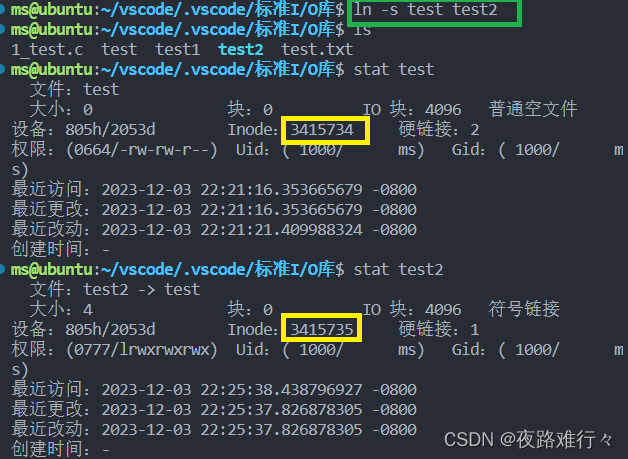
当软链接的源文件删除,其余的文件被称为“悬空链接”,原因:软链接文件类似于一种“主从” 关系,软链接内部存着源文件的路径名,当源文件被删除,则无法找到文件路径
创建软链接:
int symlink(const char *target, const char *linkpath);读取软链接:
ssize_t readlink(const char *pathname, char *buf, size_t bufsiz);
buf:存放文件缓冲区
bufsiz: 读取的链接文件的大小创建和删除目录:
int mkdir(const char *pathname, mode_t mode); int rmdir(const char *pathname);
打开,读取,关闭目录:
DIR *opendir(const char *name); struct dirent *readdir(DIR *dirp); int closedir(DIR *dirp);
删除文件:
int unlink(const char *pathname);int remove(const char *pathname);
pathname 参数指定的是一个非目录文件,那么 remove()去调用 unlink(),如果 pathname 参数指定的是
一个目录,那么 remove()去调用 rmdir()十二,文件重命名
int rename(const char *oldpath, const char *newpath);#include <stdio.h> #include <stdlib.h> int main(void) { int ret; ret = rename("./test", "./test_file"); if (-1 == ret) { perror("rename error"); exit(-1); } exit(0); }
![]()