语义分割网络FCN

语义分割是一种像素级的分类,输出是与输入图像大小相同的分割图,输出图像的每个像素对应输入图像每个像素的类别,每一个像素点的灰度值都是代表当前像素点属于该类的概率。
语义分割任务需要解决的是如何把定位和分类这两个问题一起解决,毕竟语义分割就是进行逐个像素点的分类,就是把where和what结合在了一起。这时候就需要物体的一些细节特征。
在传统的CNN网络中,在最后的卷积层之后会连接上若干个全连接层,将卷积层产生的特征图(feature map)映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率,如ALexNet网络最后输出一个1000维的向量表示输入图像属于每一类的概率.
而FCN是对图像进行像素级的分类(也就是每个像素点都进行分类),从而解决了语义级别的图像分割问题。与经典CNN在卷积层使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷基层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,上采样的特征图进行像素的分类。
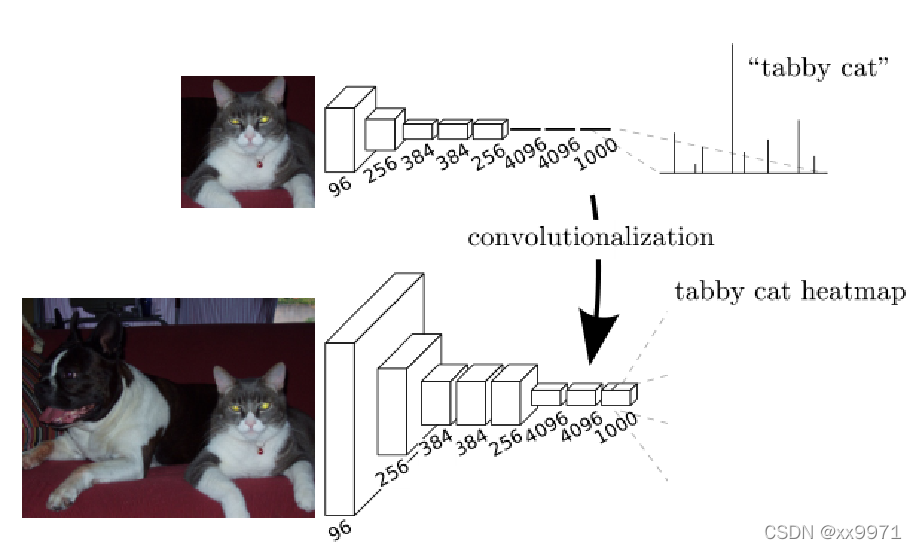
可以看出,FCN在CNN的基础上将全连接层转换为卷积层可以使分类网输出热图。添加层和空间损失产生了端到端密集学习的高效机器。
——————————————————————————————————————————
传统的图像分类会用到全连接层,但是使用全连接层的话会破坏原有的空间信息,而且使得特征不再具备局部信息,这对于图像分割这种像素级别的预测任务来说,影响非常大。
在FCN出现之前,比较常见的做法是采用滑动窗口,每个窗口从原图像上采集一小块区域,也可以叫做patchwise,作为网络的输入。虽然这样会减少全连接层所带来的对空间信息的破坏,但是它有几个比较明显的缺陷:
- 它计算量非常大,因为一张图需要滑动次数非常多,这样一来,相邻patch之间重合的部分会重复计算;
- 不同patch之间相互独立,没有利用到全局的空间信息;
- patch的设置对模型性能的影响很大,patch过小,则感受野太小,非常影响准确率,patch过大,则重复计算的区域就很多;
FCN的思想
FCN将传统CNN中的全连接层去掉,取而代之的是转化为一个个的卷积层,这样可以保持空间的位置关系。如下图所示:

整体的网络结构分为两个部分:全卷积部分和反卷积部分,丢弃了全连接层,在保持了空间信息的同时,也可以接受任意尺寸的输入图像。其中全卷积部分借用了一些经典的CNN网络,如AlexNet,VGG等等,并把最后的全连接层换成卷积,用于提取特征,形成热点图;而反卷积部分则是将小尺寸的热点图上采样得到原尺寸的语义分割图像。

输入图像经过卷积和池化之后,得到的特征图的宽高相对原图缩小了好几倍,所产生图叫做heatmap----热图,热图就是我们最重要的高维特征图图,得到高维特征之后就是最重要的一步也是最后的一步对原图像进行upsampling,也就是上采样,将图像进行放大直到到原图像的大小。
其实FCN的根本在于丢掉全连接层,保留了原本的空间信息,然后利用跳跃连接来融合特征,将定位较准的浅层信息和分类较准的深层信息结合起来。

最后的输出是类别数大小的heatmap,经过上采样恢复为原图大小的图片,为了对每个像素进行分类预测,这样才能形成最后已经进行语义分割的图像。所以在最后通过逐个像素地求其在1000张图像该像素位置的最大概率作为该像素的分类。
算法细节
FCN上采样使用的是反卷积,也叫转置卷积,文章采用了好几种上采样的结果。为了得到更好的分割效果,论文提出几种方式FCN-32s、FCN-16s、FCN-8s,如下图所示:

- 网络对原图像进行第一次卷积与下采样后原图像缩小为1/2;
- 之后对图像进行第二次卷积与下采样后图像缩小为1/4;
- 重复上面过程,接着继续对图像进行第三次相同的操作,图像缩小为原图像的1/8,此时保留这个阶段的特征图;
- 同样,在第四次后得到为原图像的1/16的特征图并保留;
- 最后对图像进行第五次操作,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成两次卷积操作,也就是conv6、conv7,但此时图像的大小还是为原图的1/32,最后生成的可以叫做heatmap了,也就是我们最终想要的结果。
最后我们可以得到1/32尺寸的heatmap,1/16尺寸的featuremap和1/8尺寸的featuremap,将1/32尺寸的heatmap进行上采样到原始尺寸,这种模型叫做FCN-32s。这种简单粗暴的方法还原了conv5中的特征,但是其中一些细节是无法恢复的,所以FCN-32s精度很差,不能够很好地还原图像原来的特征。
基于上述原因,所以自然而然的就想到将浅层网络提取的特征和深层特征相融合,这样或许能够更好地恢复其中的细节信息。于是FCN把conv4中的特征对conv7进行2倍上采样之后的特征图进行融合,然后这时候特征图的尺寸为原始图像的1/16,所以再上采样16倍就可以得到原始图像大小的特征图,这种模型叫做FCN-16s。
为了进一步恢复特征细节信息,就重复以上操作。于是乎就把pool3后的特征图对conv7上采样4倍后的特征图和对pool4进行上采样2倍的特征图进行融合,此时的特征图的大小为原始图像的1/8。融合之后再上采样8倍,就可以得到原始图像大小的特征图了,这种模型叫做FCN-8s。
代码实现
- backbone部分
class VGG(nn.Module):
def __init__(self, pretrained=True):
super(VGG, self).__init__()
# conv1 1/2
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.relu1_2 = nn.ReLU(inplace=True)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv2 1/4
self.conv2_1 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.relu2_2 = nn.ReLU(inplace=True)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv3 1/8
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.relu3_2 = nn.ReLU(inplace=True)
self.conv3_3 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.relu3_3 = nn.ReLU(inplace=True)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv4 1/16
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu4_2 = nn.ReLU(inplace=True)
self.conv4_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu4_3 = nn.ReLU(inplace=True)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv5 1/32
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu5_2 = nn.ReLU(inplace=True)
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu5_3 = nn.ReLU(inplace=True)
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)
# load pretrained params from torchvision.models.vgg16(pretrained=True)
if pretrained:
pretrained_model = vgg16(pretrained=pretrained)
pretrained_params = pretrained_model.state_dict()
keys = list(pretrained_params.keys())
new_dict = {}
for index, key in enumerate(self.state_dict().keys()):
new_dict[key] = pretrained_params[keys[index]]
self.load_state_dict(new_dict)
def forward(self, x):
x = self.relu1_1(self.conv1_1(x))
x = self.relu1_2(self.conv1_2(x))
x = self.pool1(x)
pool1 = x
x = self.relu2_1(self.conv2_1(x))
x = self.relu2_2(self.conv2_2(x))
x = self.pool2(x)
pool2 = x
x = self.relu3_1(self.conv3_1(x))
x = self.relu3_2(self.conv3_2(x))
x = self.relu3_3(self.conv3_3(x))
x = self.pool3(x)
pool3 = x
x = self.relu4_1(self.conv4_1(x))
x = self.relu4_2(self.conv4_2(x))
x = self.relu4_3(self.conv4_3(x))
x = self.pool4(x)
pool4 = x
x = self.relu5_1(self.conv5_1(x))
x = self.relu5_2(self.conv5_2(x))
x = self.relu5_3(self.conv5_3(x))
x = self.pool5(x)
pool5 = x
return pool1, pool2, pool3, pool4, pool5- FCN-8s部分
class FCNs(nn.Module):
def __init__(self, num_classes, backbone="vgg"):
super(FCNs, self).__init__()
self.num_classes = num_classes
if backbone == "vgg":
self.features = VGG()
# deconv1 1/16
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.relu1 = nn.ReLU()
# deconv1 1/8
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.relu2 = nn.ReLU()
# deconv1 1/4
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
# deconv1 1/2
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.relu4 = nn.ReLU()
# deconv1 1/1
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.relu5 = nn.ReLU()
self.classifier = nn.Conv2d(32, num_classes, kernel_size=1)
def forward(self, x):
features = self.features(x)
y = self.bn1(self.relu1(self.deconv1(features[4])) + features[3])
y = self.bn2(self.relu2(self.deconv2(y)) + features[2])
y = self.bn3(self.relu3(self.deconv3(y)))
y = self.bn4(self.relu4(self.deconv4(y)))
y = self.bn5(self.relu5(self.deconv5(y)))
y = self.classifier(y)
return y文末

图中可以看出,FCN-8s的细节特征最为丰富,分割效果良好。同时论文中也尝试了将pool2、pool1的特征图进行融合,但是效果提升不明显,所以最终效果最好的就是FCN-8s。
FCN仍有一些缺点,比如:
- 得到的效果还不够好,对细节不够敏感;
- 没有考虑像素与像素之间的关系,缺乏空间一致性等。
其实FCN最大的贡献其实是提供了用于分割的一种全新思路,相比于传统做法它更加高效,因为避免了由于使用像素块而带来的重复存储和计算卷积的问题。
之后的分割算法基本上都是基于全卷积的方式来进行改进、优化的。