区分(GIOU、DIOU、CIOU)(正则化、归一化、标准化)
一、IOU
IoU 的全称为交并比(Intersection over Union)。IoU 计算的是 “预测的边框” 和 “真实的边框” 的交集和并集的比值。
1.GIOU:预测框(蓝框)和真实框(绿框)的最小外接矩形C。来获取预测框、真实框在闭包区域中的比重。这样子,GIOU不仅可以关注重叠区域,还可以关注其他非重合区域,能比较好的反映两个框在闭包区域中的相交情况。
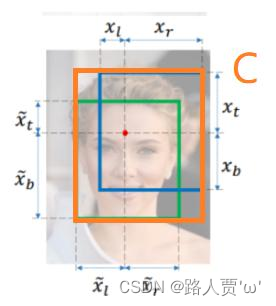
2.DIoU:计算的不是框之间的交并,而是计算的每个检测框之间的欧氏距离。DIoU考虑了重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的距离,因此DIoU收敛的更快,但并没有考虑到长宽比。如下图d。

3.CIoU就是在DIoU的基础上增加了检测框尺度的loss,增加了长和宽的loss,使得目标框回归更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。如上图c和d。
二、规范化
1.正则化:正则化是为了防止过拟合。如图绿线。
0范数,向量中非零元素的个数。
1范数,为绝对值之和。
2范数,就是通常意义上的模。


这三幅图很容易理解:
1、 图x1明显分类的有点欠缺,有很多的“男人”被分类成了“女人”。
2、 图x2虽然有两个点分类错误,但是能够理解,毕竟现实世界有噪音干扰,比如有些人男人留长发、化妆、人妖等等。
3、 图x3分类全部是正确的,但是看着这副图片,明显觉得过了,连人妖都区分的出来,可想而知,学习的时候需要更多的参数项,甚至将生殖器官的形状、喉结的大小、有没有胡须特征等都作为特征取用了,总而言之f(x)多项式的N特别的大,因为需要提供的特征多,或者提供的测试用例中我们使用到的特征非常多(一般而言,机器学习的过程中,很多特征是可以被丢弃掉的)。
2.归一化:将一列数据变化到某个固定区间([0,1])中。
3.标准化:批标准化只会选取一小批数据先缩放与平移然后训练参数, 而标准化则会选取所有的数据进行计算。
标准化之后: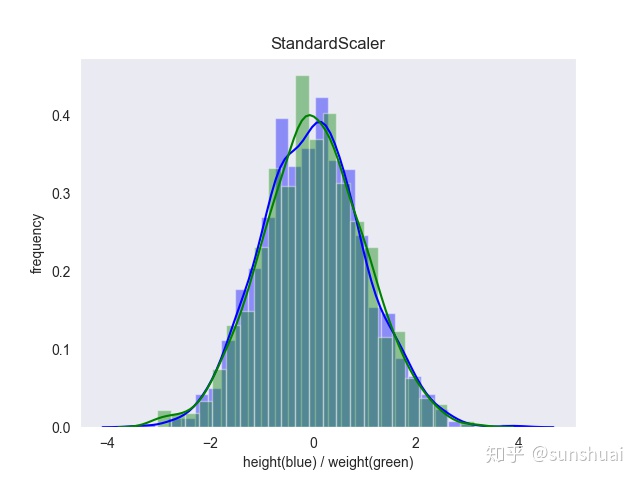
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.kler.cn/a/158719.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!